
大模型Agent
大模型Agent一、背景知识1.会产生幻觉。2.结果并不总是真实的。3.对时事的了解有限或一无所知。4.很难应对复杂的计算。•Google搜索:获取最新信息•Python REPL:执行代码•Wolfram:进行复杂的计算•外部API:获取特定信息大模型 + 插件 + 执行流程 = Agent二、Agent框架LLM-based Agent 框架包含三个组成部分:控制端(Brain)、感知端(Pe
一、背景知识
LLM的一些缺点
1.会产生幻觉。
2.结果并不总是真实的。
3.对时事的了解有限或一无所知。
4.很难应对复杂的计算。
解决方式:加上外部工具
•Google搜索:获取最新信息
•Python REPL:执行代码
•Wolfram:进行复杂的计算
•外部API:获取特定信息
大模型 + 插件 + 执行流程 = Agent
二、Agent框架
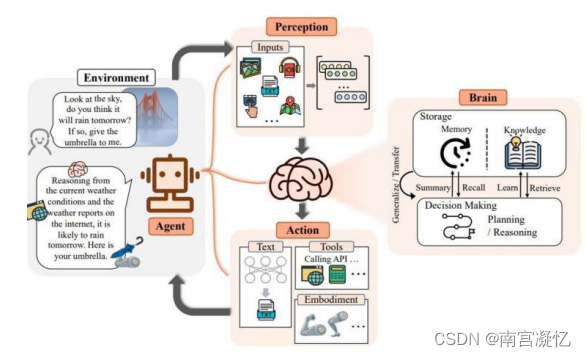
LLM-based Agent 框架包含三个组成部分:控制端(Brain)、感知端(Perception)和行动端 (Action)。
1、控制端:Brain
自然语言交互:高质量文本生成 和 言外之意的理解(chatgpt,chatglm ,llama)
知识:基于大批量语料训练的 LLMs,拥有了存储海量知识(Knowledge)的能力。除了语言知识以外, 常识知识和专业技能知识都是 LLM-based Agents 的重要组成部分。(Langchain)
记忆力:长期记忆vs短期记忆。
- 扩充记忆的方法扩展 Backbone 架构的长度限制:针对 Transformers 固有的序列长度限制问题进行改进。
- 总结记忆(Summarizing):对记忆进行摘要总结,增强代理从记忆中提取关键细节的能力。
- 压缩记忆(Compressing):通过使用向量或适当的数据结构对记忆进行压缩,可以提高记忆检索效率 特朗普时期,阿里巴巴的CTO是谁?
推理 & 规划:将复杂任务分解为更易于管理的子任务。在制定计划后,可以进行反思并评估其优劣。
迁移性 & 泛化性:
- 对未知任务的泛化
- 情景学习(In-context Learning),见人说人话,见鬼说鬼话
- 持续学习
2、感知端:大模型行的耳朵和眼睛
文本输入
视觉输入:图片->文本 图片->编码
听觉输入
其他输入
3、行动端:Action 大模型的手和脚
文本输出:LLMs 最基础的能力
计算微积分,计算泛函,
工具使用:尽管 LLMs 拥有出色的知识储备和专业能力,但在面对具体问题时,也可能会出现鲁棒 性问题、幻觉等一系列挑战。与此同时,工具作为使用者能力的扩展,可以在专业性、事实性、可 解释性等方面提供帮助。例如,可以通过使用计算器来计算数学问题、使用搜索引擎来搜寻实时信 息。
其他模型:调用语音生成、图像生成等专家模型,来获得多模态的行动方式。
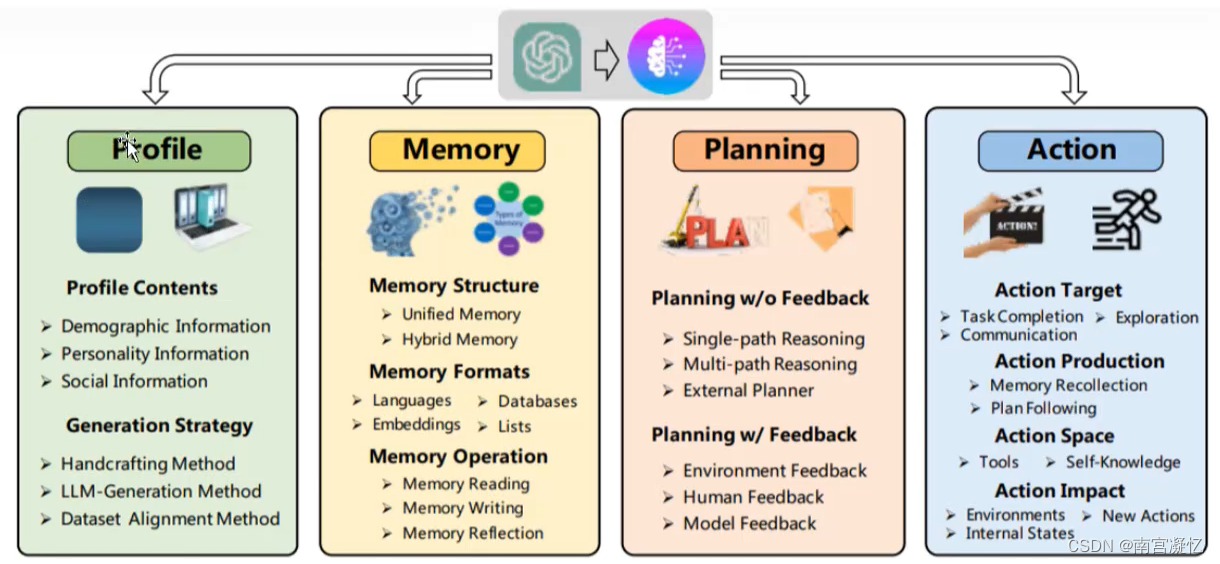
三、另一种Agent架构
人设+激励+问题拆解+行动能力
四、常见的Agent实现
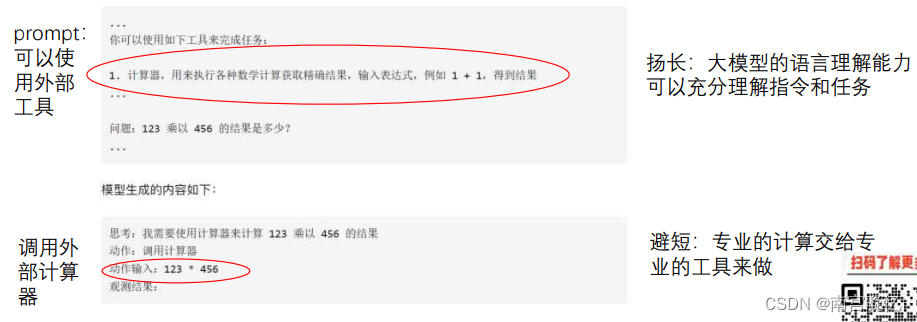
1、使用专业工具
用大模型理解任务,然后调用专业工具解决
大模型:语言理解力强,缺点:模型出现幻觉,需要精心设计prompt,需要依赖外界工具 Agent
大模型+各式各样的工具辅助
外界专业工具
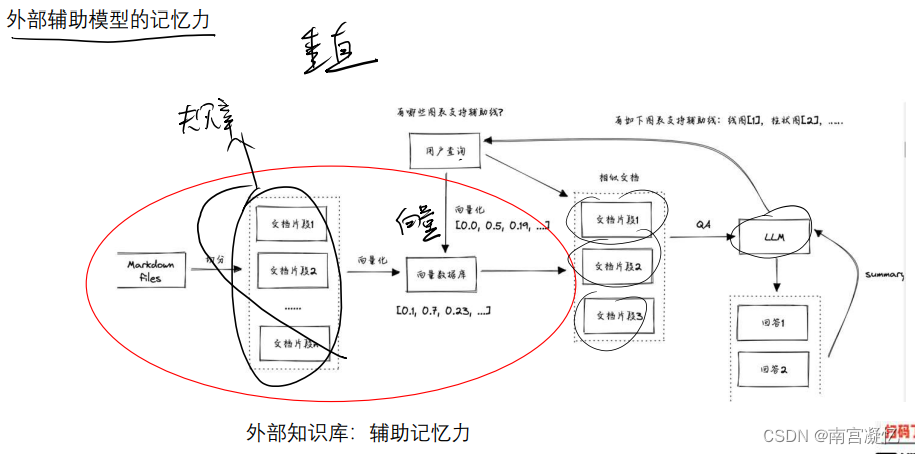
2、辅助记忆力
- 文档存储规章制度
- 根据问题检索文档
- 问题+相关文档输入大模型
常用在垂直领域搭建大模型
3、各种外部工具辅助
两种工具类型
- 辅助输入:辅助记忆,辅助实时信息
- 辅助输出:结果通过工具生成
通过外挂使大模型具备实时性和解决复杂问题的能力
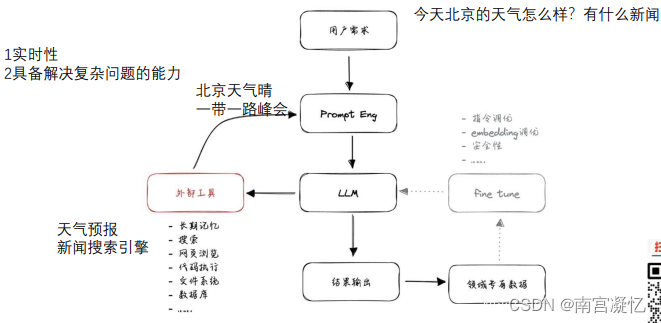
4、提示词工程 Prompt
核心仍然是大模型的理解能力,不同模型有对应不同的提示词
(1)AutoGPT

Prompt提示词包括:
- 限制和资源
- 工具
- 性能评估
- 返回格式

(2)BabyAGI
我想泡茶,应该怎么操作?
- 第一次大模型的结果:输入:我想泡茶,应该怎么操作?回答:需要做如下几步: ①.烧开水 ②.把茶叶放到杯子里 ③.把开水倒进杯子里
- 第二次大模型的结果:输入:我要烧开水 回答:把凉水放进水壶, 接通电源
- 第三次大模型行的结果: 输入:把茶叶放进杯子里 回答:从茶叶罐取得茶叶。
任务太复杂时,可以用这种方式解决,核心难点是设计这个流程。

5、HuggingGPT

任务:生成一个小女孩读书的图片,她的体态和上述图片一 样。
解决过程:
- 建模体态:图片输入体态控制模型
- 体态到图片:输入文本为A reading girl,资源为体态
- 目标检测:将小女孩框出来,图片到文本
- 语音播报:文本转语音
过程分析:
- 任务的分解: 把复杂任务按顺序进行分解
- 调用其他模型: 体态控制模型、体态生成图片模型、目标检测模型、语音播报模型 ……
缺点:链路过长,如果某一个环节出现了问题,后续都会出问题。

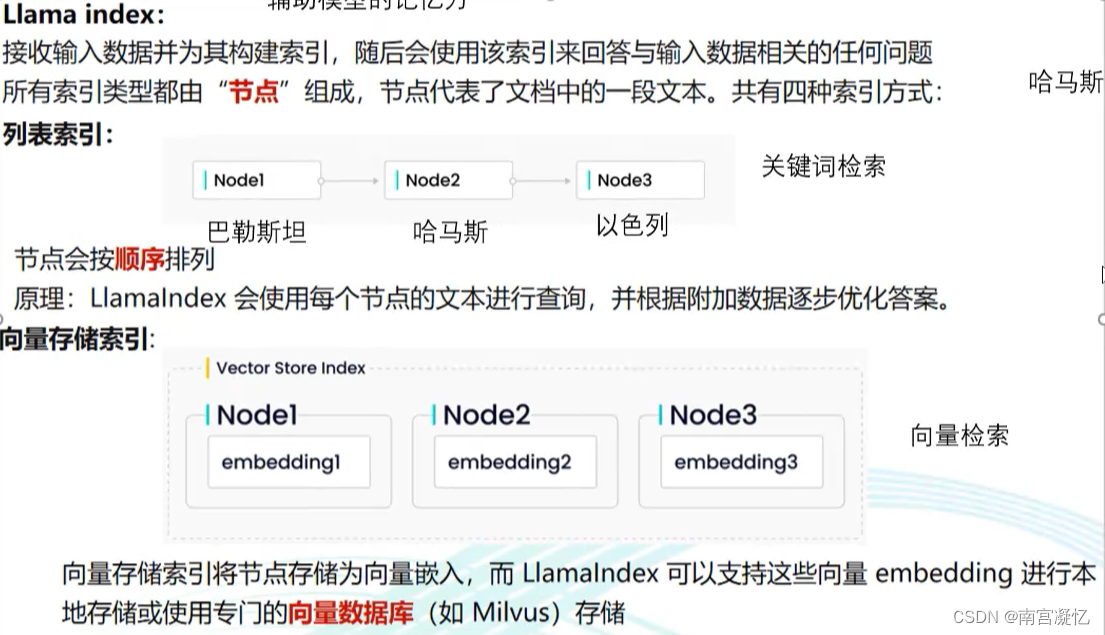
6、LLAMAIndex
辅助模型的记忆能力
- 列表索引:关键词检索。
- 向量存储索引:向量检索。
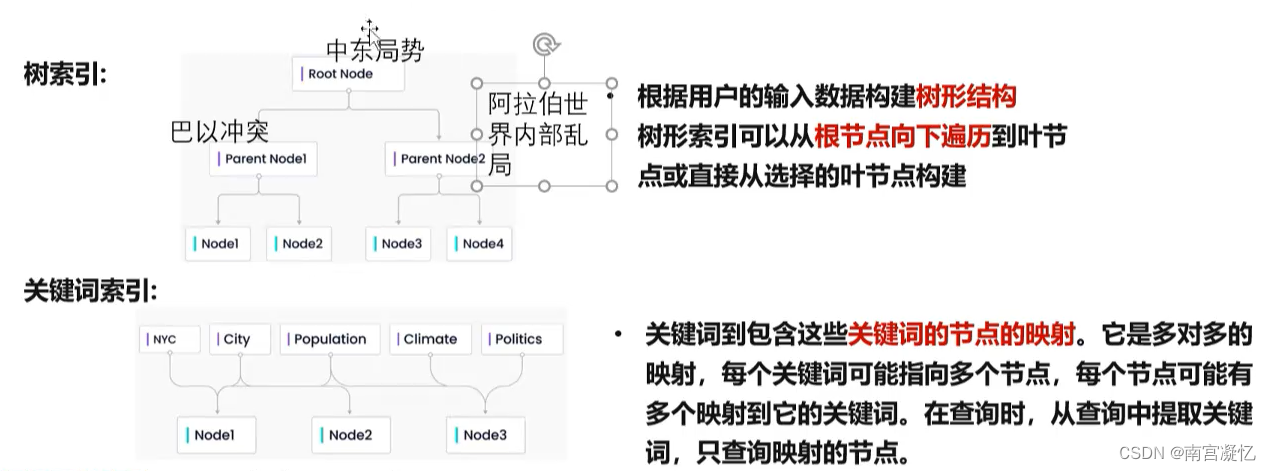
- 树索引:把数据和知识以不同的结构存储起来,然后通过不同检索方式获取知识。
- 知识图谱索引:在一组文档上提取形式为(主语、谓语、宾语)的知识三元组来构建索引。

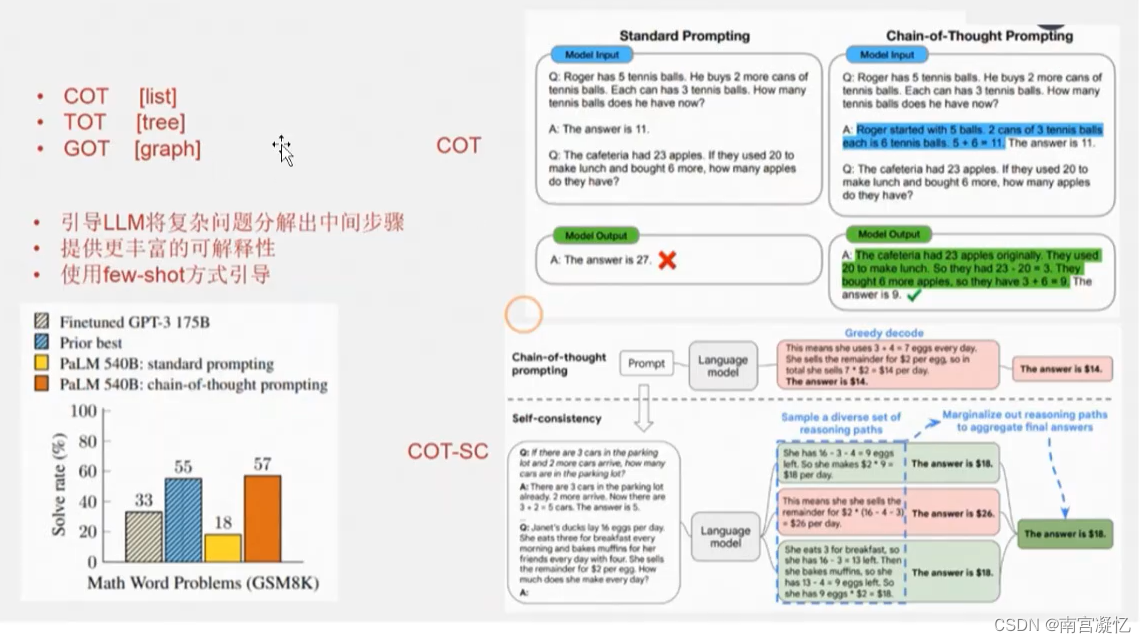
7、思维链
(1)one-shot:例子(问题+答案)+ 类似的问题让LLM回答
只告诉了答案,没有讲怎么算的答案,因此,难以泛化到复杂问题。
(2)COT:例子(问题+计算过程和答案)+ 类似的问题让LLM回答
给LLM拆解计算过程,引导它一步步计算。
(3)COT-SC:LLM输出具备随机性,选出现结果最多的作为答案,是一种投票机制。
可以一个模型问多次,输出出现次数最多的结果。
也可以问不同的模型多次,输出出现次数最多的结果。
(4)TOT:具备搜索、评估、回溯的能力。
24点游戏:让大模型对树进行递归和剪枝运算。
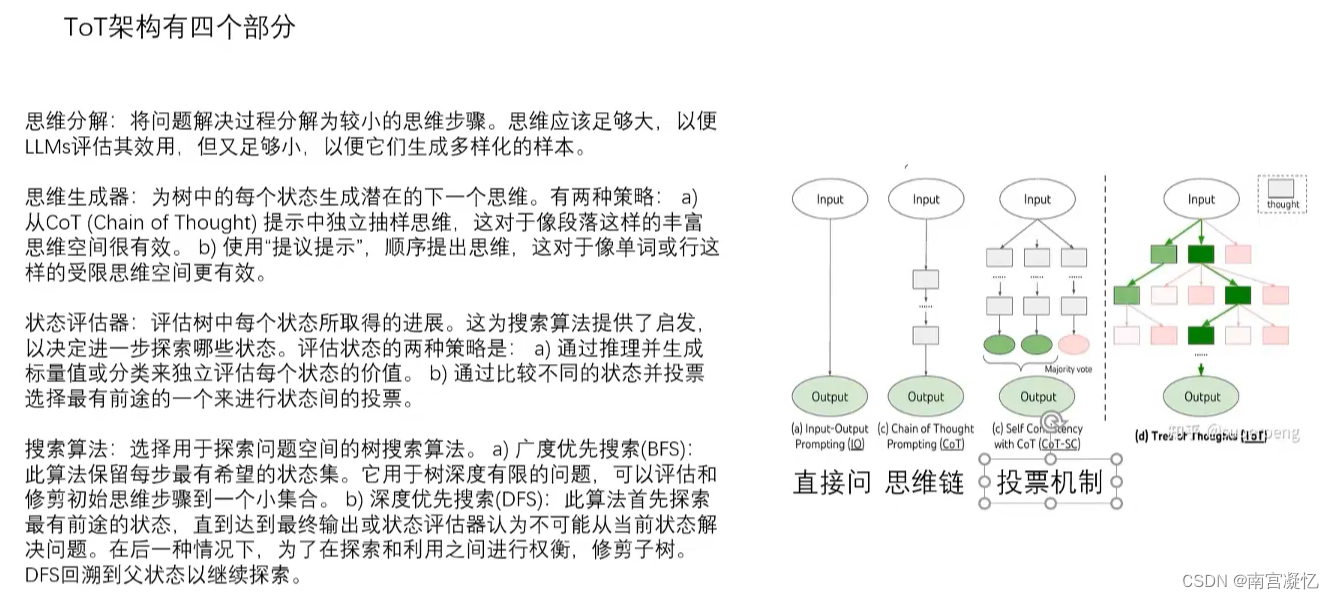
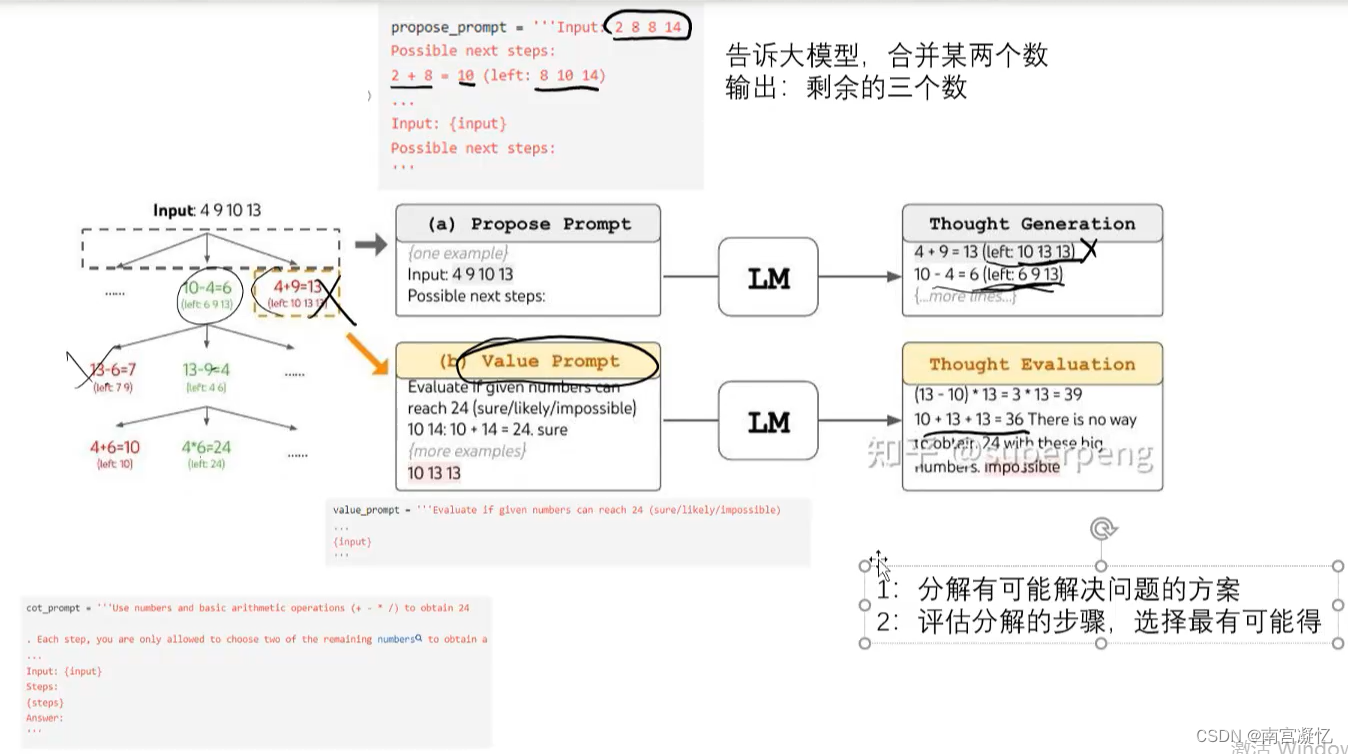

五、Agent总结
1、给大模型加外挂
(1)外挂辅助输入(今天北京的天气如何) 外部调用日历:2023-10-17
(2)外挂输出:日期:2023-10-17,目标:天气,调用工具:气象接口
2、思维链条
把复杂的问题进行拆解,不指望大模型一次回答出来,多调用几次大模型,解决复杂问题。
3、prompt 设计模式
CoT+prompt:给出指令,同时也给出执行任务过程的拆解或者样例。
(1)“自我审视”,提醒模型在产出结果之前,先自我审视一下,看看是否有更好的方案。也可以拿到结果后再调用一下模型强制审视一下。比如 AutoGPT 里的 “Constructively self-criticize your big-picture behavior constantly”。
(2)分而治之,越是具体的context 和目标,模型往往完成得越好。所以把任务拆细再来应用模型,往往比让它一次性把整个任务做完效果要好。
(3)先计划,后执行。BabyAGI,HuggingGPT 和 Generative Agents 都应用了这个模式。也可以扩展这个模式,例如在计划阶段让模型主动来提出问题,澄清目标,或者给出一些可能的方案,再由人工 review 来进行确认或者给出反馈,减少目标偏离的可能。
(4)记忆系统,包括短期记忆和长期记忆的存储、加工和提取等。这个模式同样在几乎所有的 agent 项目里都有应用,也是目前能体现一些模型的实时学习能力的方案。
六、Agent的作用
如果说大模型是电池,那么agent就是一辆电动车。
大模型是核心能力,Agent就是最终交付的产品。
最终产品 Agent的缺点:
(1)依赖大模型的核心能力,大模型本身够强才行。
(2)链路过长,某一环节出错,前功尽弃。(用多次调用选出现最多的结果规避风险)
(3)多次调用模型,效率不高。
(4)迁移能力弱,换模型需要重新写提示词。
(5)能力强弱,取决于写提示词的水平。
七、Agent的未来展望
大模型能力是有上限的
端到端虽然理想,但是复杂问题很难解决
Agent这种拆解形式,会更加流行

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)