
斯坦福 Stats60:21 世纪的统计学:第十五章到第十八章
第十五章:比较均值原文:statsthinking21.github.io/statsthinking21-core-site/comparing-means.html译者:飞龙协议:CC BY-NC-SA 4.0我们已经遇到了许多情况,我们想要询问样本均值的问题。在本章中,我们将更深入地探讨我们可以比较不同组均值的各种方法。15.1 测试单个均值的值我们可能想要询问均值是否具有特定值的最简单的问
第十五章:比较均值
原文:
statsthinking21.github.io/statsthinking21-core-site/comparing-means.html译者:飞龙
我们已经遇到了许多情况,我们想要询问样本均值的问题。在本章中,我们将更深入地探讨我们可以比较不同组均值的各种方法。
15.1 测试单个均值的值
我们可能想要询问均值是否具有特定值的最简单的问题。假设我们想要测试 NHANES 数据集中成年人的舒张压均值是否高于 80,这是根据美国心脏病学会的高血压标准。为了询问这个问题,我们从数据集中抽取了 200 名成年人;每个成年人的血压被测量了三次,我们使用这些值的平均值进行我们的检验。
测试这种差异的一种简单方法是使用称为符号检验的检验,它询问实际值与假设值之间的正差异的比例是否与我们预期的差异不同。为了做到这一点,我们取每个数据点与假设均值的差异并计算它们的符号。如果数据呈正态分布且实际均值等于假设均值,那么高于假设均值(或低于它)的值的比例应该是 0.5,这样正差异的比例也应该是 0.5。在我们的样本中,我们看到 19.0%的个体舒张压高于 80。然后我们可以使用二项检验来询问这种正差异的比例是否大于 0.5,使用我们统计软件中的二项检验函数:
##
## Exact binomial test
##
## data: npos and nrow(NHANES_sample)
## number of successes = 38, number of trials = 200, p-value = 1
## alternative hypothesis: true probability of success is greater than 0.5
## 95 percent confidence interval:
## 0.15 1.00
## sample estimates:
## probability of success
## 0.19
在零假设 p ≤ 0.5 p \le 0.5 p≤0.5下,我们看到具有正符号的个体比例并不令人惊讶,这不应该让我们感到惊讶,因为观察到的值实际上小于 0.5。
我们也可以使用学生 t 检验来询问这个问题,这是你在本书中早些时候已经遇到过的。我们将均值称为 X ˉ \bar{X} Xˉ,假设总体均值为 μ \mu μ。然后,单个均值的 t 检验为:
t = X ˉ − μ S E M t = \frac{\bar{X} - \mu}{SEM} t=SEMXˉ−μ
其中 SEM(你可能还记得抽样章节中的内容)被定义为:
S E M = σ ^ n SEM = \frac{\hat{\sigma}}{\sqrt{n}} SEM=nσ^
实质上,t 统计量询问样本均值与假设数量的偏差在均值的抽样变异性方面有多大。
我们可以使用我们的统计软件计算 NHANES 数据集的这个值:
##
## One Sample t-test
##
## data: NHANES_adult$BPDiaAve
## t = -55, df = 4593, p-value = 1
## alternative hypothesis: true mean is greater than 80
## 95 percent confidence interval:
## 69 Inf
## sample estimates:
## mean of x
## 70
这告诉我们数据集中的舒张压均值(69.5)实际上远低于 80,因此我们对它是否高于 80 的检验远非显著。
记住,大的 p 值并不能为我们提供支持零假设的证据,因为我们已经假定零假设是真实的。然而,正如我们在贝叶斯分析的章节中讨论的那样,我们可以使用贝叶斯因子来量化支持或反对零假设的证据:
ttestBF(NHANES_sample$BPDiaAve, mu=80, nullInterval=c(-Inf, 80))
## Bayes factor analysis
## --------------
## [1] Alt., r=0.707 -Inf<d<80 : 2.7e+16 ±NA%
## [2] Alt., r=0.707 !(-Inf<d<80) : NaNe-Inf ±NA%
##
## Against denominator:
## Null, mu = 80
## ---
## Bayes factor type: BFoneSample, JZS
这里列出的第一个贝叶斯因子( 2.73 ∗ 1 0 16 2.73 * 10^{16} 2.73∗1016)表示支持零假设胜过备择假设的证据非常强。
15.2 比较两个均值
统计学中经常出现的一个更常见的问题是两个不同组的均值是否有差异。假设我们想知道定期吸大麻的人是否看更多电视,我们也可以使用 NHANES 数据集来询问这个问题。我们从数据集中抽取了 200 个个体的样本,并测试每天看电视的小时数是否与定期吸大麻有关。图 15.1 的左侧面板显示了使用小提琴图展示的这些数据。
左图:小提琴图显示了通过定期使用大麻分开的电视观看分布。右图:小提琴图显示了每个组的数据,用虚线连接了每个组的预测值,这些值是基于线性模型的结果计算得出的。
图 15.1:左图:小提琴图显示了通过定期使用大麻分开的电视观看分布。右图:小提琴图显示了每个组的数据,用虚线连接了每个组的预测值,这些值是基于线性模型的结果计算得出的。
我们也可以使用学生 t 检验来测试两组独立观察的差异(正如我们在前面的章节中看到的);我们将在本章后面讨论观察不独立的情况。作为提醒,用于比较两个独立组的 t 统计量计算如下:
t = X 1 ˉ − X 2 ˉ S 1 2 n 1 + S 2 2 n 2 t = \frac{\bar{X_1} - \bar{X_2}}{\sqrt{\frac{S_1^2}{n_1} + \frac{S_2^2}{n_2}}} t=n1S12+n2S22X1ˉ−X2ˉ
其中 X ˉ 1 \bar{X}_1 Xˉ1和 X ˉ 2 \bar{X}_2 Xˉ2是两组的均值, S 1 2 S^2_1 S12和 S 2 2 S^2_2 S22是每组的方差, n 1 n_1 n1和 n 2 n_2 n2是两组的大小。在均值无差异的零假设下,这个统计量根据 t 分布分布,使用韦尔奇检验计算自由度(如前面讨论的),因为两组个体数量不同。在这种情况下,我们从具体假设开始,即吸大麻与更多的电视观看有关,因此我们将使用单尾检验。以下是我们统计软件的结果:
##
## Welch Two Sample t-test
##
## data: TVHrsNum by RegularMarij
## t = -3, df = 85, p-value = 6e-04
## alternative hypothesis: true difference in means between group No and group Yes is less than 0
## 95 percent confidence interval:
## -Inf -0.39
## sample estimates:
## mean in group No mean in group Yes
## 2.0 2.8
在这种情况下,我们看到组之间存在统计上显著的差异,且方向符合预期 - 经常吸大麻的人看更多电视。
15.3 t 检验作为线性模型
t 检验通常被呈现为比较均值的专门工具,但也可以被视为一般线性模型的应用。在这种情况下,模型如下:
T V ^ = β 1 ^ ∗ M a r i j u a n a + β 0 ^ \hat{TV} = \hat{\beta_1}*Marijuana + \hat{\beta_0} TV^=β1^∗Marijuana+β0^
由于吸烟是一个二元变量,我们将其视为前一章中讨论的虚拟变量,对于吸烟者设置为 1,对于非吸烟者设置为 0。在这种情况下, β 1 ^ \hat{\beta_1} β1^ 简单地是两组之间均值的差异, β 0 ^ \hat{\beta_0} β0^ 是编码为零的组的均值。我们可以使用统计软件中的一般线性模型函数拟合这个模型,并且可以看到它给出了与上面的 t 检验相同的 t 统计量,只是在这种情况下是正的,因为我们的软件安排了这些组的方式:
##
## Call:
## lm(formula = TVHrsNum ~ RegularMarij, data = NHANES_sample)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.2843 -1.0067 -0.0067 0.9933 2.9933
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.007 0.116 17.27 < 2e-16 ***
## RegularMarijYes 0.778 0.230 3.38 0.00087 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.4 on 198 degrees of freedom
## Multiple R-squared: 0.0546, Adjusted R-squared: 0.0498
## F-statistic: 11.4 on 1 and 198 DF, p-value: 0.000872
我们也可以以图形方式查看线性模型的结果(参见 15.1 的右面板)。在这种情况下,非吸烟者的预测值是 β 0 ^ \hat{\beta_0} β0^(2.0),吸烟者的预测值是 β 0 ^ + β 1 ^ \hat{\beta_0} +\hat{\beta_1} β0^+β1^(2.8)。
为了计算这个分析的标准误差,我们可以使用与线性回归相同的方程 - 因为这实际上只是线性回归的另一个例子。实际上,如果你比较上面 t 检验的 p 值和大麻使用变量的线性回归分析中的 p 值,你会发现线性回归分析的 p 值是 t 检验的两倍,因为线性回归分析执行的是双尾检验。
15.3.1 比较两个均值的效应大小
比较两个均值最常用的效应大小是科恩的 d,这是一个用标准差单位表示的效应大小的表达式(你可能还记得第 10 章中的内容)。对于使用上面概述的一般线性模型估计的 t 检验(即使用单个虚拟编码变量),这可以表示为:
d = β 1 ^ σ r e s i d u a l d = \frac{\hat{\beta_1}}{\sigma_{residual}} d=σresidualβ1^
我们可以从上面的分析输出中获得这些值,得到 d = 0.55,通常我们会解释为中等效应。
我们还可以为这个分析计算 R 2 R^2 R2,它告诉我们电视观看的方差有多少被大麻吸烟解释。这个值(在上面线性模型分析的摘要底部报告)为 0.05,这告诉我们,虽然效应可能在统计上显著,但它解释了相对较少的电视观看方差。
15.4 平均差异的贝叶斯因子
正如我们在贝叶斯分析的章节中讨论的那样,贝叶斯因子提供了一种更好地量化支持或反对零假设的证据的方法。我们可以对相同的数据进行这种分析:
## Bayes factor analysis
## --------------
## [1] Alt., r=0.707 0<d<Inf : 0.041 ±0%
## [2] Alt., r=0.707 !(0<d<Inf) : 61 ±0%
##
## Against denominator:
## Null, mu1-mu2 = 0
## ---
## Bayes factor type: BFindepSample, JZS
由于数据的组织方式,第二行向我们展示了这个分析的相关贝叶斯因子,为 61.4。这告诉我们,反对零假设的证据非常强。
15.5 比较配对观测
在实验研究中,我们经常使用受试者内部设计,即我们比较同一个人的多次测量。这种设计产生的测量通常被称为重复测量。例如,在 NHANES 数据集中,血压被测量了三次。假设我们有兴趣测试在样本中个体的第一次和第二次测量之间的平均收缩压是否有差异(见图 15.2)。

图 15.2:左侧:NHANES 数据集中第一次和第二次记录的收缩压的小提琴图。右侧:相同的小提琴图,显示了每个个体的两个数据点之间的连线。
我们看到第一次和第二次测量之间的平均血压没有太大的差异(大约一点)。首先让我们使用独立样本 t 检验来测试差异,忽略了数据点成对来自同一个个体的事实。
##
## Two Sample t-test
##
## data: BPsys by timepoint
## t = 0.6, df = 398, p-value = 0.5
## alternative hypothesis: true difference in means between group BPSys1 and group BPSys2 is not equal to 0
## 95 percent confidence interval:
## -2.1 4.1
## sample estimates:
## mean in group BPSys1 mean in group BPSys2
## 121 120
这个分析显示没有显著差异。然而,这个分析是不合适的,因为它假设两个样本是独立的,而实际上它们并不是,因为数据来自同一个个体。我们可以绘制每个个体的数据线来展示这一点(见图 15.2 的右侧面板)。
在这个分析中,我们真正关心的是每个人的血压在两次测量之间是否以系统的方式发生了变化,因此表示数据的另一种方式是计算每个个体两个时间点之间的差异,然后分析这些差异分数而不是分析个体测量值。在图 15.3 中,我们展示了这些差异分数的直方图,蓝线表示平均差异。

图 15.3:第一次和第二次血压测量之间差异分数的直方图。垂直线代表样本中的平均差异。
15.5.1 符号检验
一个简单的测试差异的方法是使用符号检验。为此,我们取差异并计算它们的符号,然后使用二项式检验来询问正符号的比例是否与 0.5 不同。
##
## Exact binomial test
##
## data: npos and nrow(NHANES_sample)
## number of successes = 96, number of trials = 200, p-value = 0.6
## alternative hypothesis: true probability of success is not equal to 0.5
## 95 percent confidence interval:
## 0.41 0.55
## sample estimates:
## probability of success
## 0.48
在这里,我们看到具有积极迹象的个体比例(0.48)不足以在零假设下的 p=0.5 下令人惊讶。然而,符号检验的一个问题是它丢弃了关于差异大小的信息,因此可能会漏掉一些东西。
15.5.2 配对 t 检验
更常见的策略是使用配对 t 检验,它相当于每个人的测量之间的均值差异是否为零的单样本 t 检验。我们可以使用我们的统计软件计算这个,告诉它数据点是配对的:
##
## Paired t-test
##
## data: BPsys by timepoint
## t = 3, df = 199, p-value = 0.007
## alternative hypothesis: true mean difference is not equal to 0
## 95 percent confidence interval:
## 0.29 1.75
## sample estimates:
## mean difference
## 1
通过这些分析,我们看到两次测量之间实际上存在显著差异。让我们计算贝叶斯因子,看看结果提供了多少证据:
## Bayes factor analysis
## --------------
## [1] Alt., r=0.707 : 3 ±0.01%
##
## Against denominator:
## Null, mu = 0
## ---
## Bayes factor type: BFoneSample, JZS
观察到的贝叶斯因子为 2.97 告诉我们,尽管配对 t 检验中的效应是显著的,但实际上提供了非常微弱的证据支持备择假设。
配对 t 检验也可以用线性模型来定义;有关此更多详细信息,请参阅附录。
15.6 比较两个以上的均值
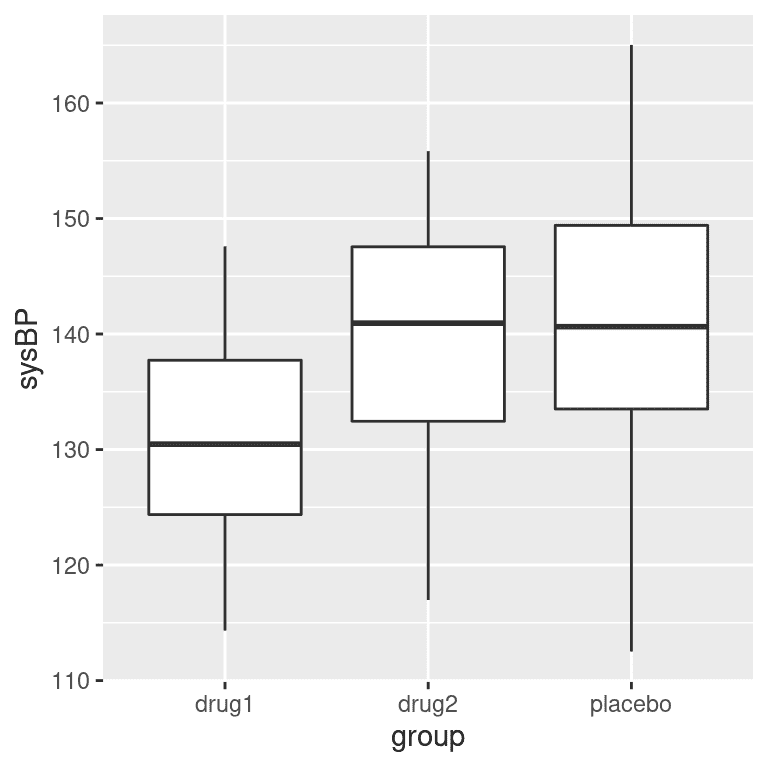
通常我们希望比较两个以上的均值,以确定它们是否彼此不同。假设我们正在分析治疗高血压的临床试验数据。在这项研究中,志愿者被随机分配到三种条件中的一种:药物 1、药物 2 或安慰剂。让我们生成一些数据并绘制它们(见图 15.4)。
图 15.4:显示我们临床试验中三个不同组的血压的箱线图。
15.6.1 方差分析
我们首先想要测试所有组的均值是否相等的零假设 - 也就是说,与安慰剂相比,治疗都没有任何效果。我们可以使用一种称为方差分析(ANOVA)的方法来做到这一点。这是心理统计学中最常用的方法之一,我们只会在这里浅尝辄止。ANOVA 的基本思想是我们在一般线性模型章节中已经讨论过的,实际上 ANOVA 只是这种模型的一个特定版本的名称。
还记得上一章我们可以将数据的总方差( S S t o t a l SS_{total} SStotal)分成模型解释的方差( S S m o d e l SS_{model} SSmodel)和未解释的方差( S S e r r o r SS_{error} SSerror)。然后我们可以通过将它们除以它们的自由度来计算每个的均方;对于误差,这是 N − p N - p N−p(其中 p p p是我们计算的均值的数量),对于模型,这是 p − 1 p - 1 p−1:
M S m o d e l = S S m o d e l d f m o d e l = S S m o d e l p − 1 MS_{model} =\frac{SS_{model}}{df_{model}}= \frac{SS_{model}}{p-1} MSmodel=dfmodelSSmodel=p−1SSmodel
M S e r r o r = S S e r r o r d f e r r o r = S S e r r o r N − p MS_{error} = \frac{SS_{error}}{df_{error}} = \frac{SS_{error}}{N - p} MSerror=dferrorSSerror=N−pSSerror
对于 ANOVA,我们想要测试模型解释的方差是否大于我们在零假设下预期的随机方差,即均值之间没有差异。而对于 t 分布,在零假设下期望值为零,但在这里情况并非如此,因为平方和始终是正数。幸运的是,还有另一个理论分布描述了在零假设下平方和的比率是如何分布的:F分布(见图 15.5)。这个分布有两个自由度,对应于分子(在这种情况下是模型)和分母(在这种情况下是误差)的自由度。
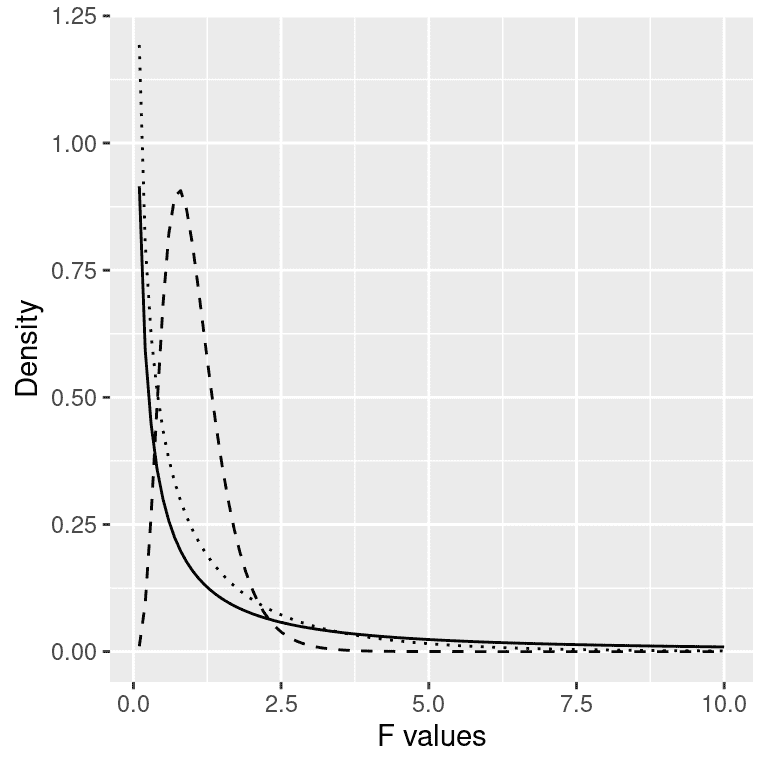
图 15.5:零假设下的 F 分布,不同自由度的值。
要创建 ANOVA 模型,我们扩展了您在上一章中遇到的“虚拟编码”的概念。请记住,对于比较两个均值的 t 检验,我们创建了一个单一的虚拟变量,该变量对于其中一个条件取值为 1,对于其他条件取值为零。在这里,我们通过创建两个虚拟变量来扩展这个想法,一个编码药物 1 条件,另一个编码药物 2 条件。就像在 t 检验中一样,我们将有一个条件(在这种情况下是安慰剂),它没有虚拟变量,因此代表了与其他条件进行比较的基线;其均值定义了模型的截距。使用药物 1 和 2 的虚拟编码,我们可以使用与上一章相同的方法拟合模型:
##
## Call:
## lm(formula = sysBP ~ d1 + d2, data = df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -29.084 -7.745 -0.098 7.687 23.431
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 141.60 1.66 85.50 < 2e-16 ***
## d1 -10.24 2.34 -4.37 2.9e-05 ***
## d2 -2.03 2.34 -0.87 0.39
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 9.9 on 105 degrees of freedom
## Multiple R-squared: 0.169, Adjusted R-squared: 0.154
## F-statistic: 10.7 on 2 and 105 DF, p-value: 5.83e-05
此命令的输出为我们提供了两件事。首先,它向我们显示了每个虚拟变量的 t 检验结果,基本上告诉我们每个条件是否与安慰剂分别不同;看起来药物 1 确实有差异,而药物 2 没有。但是,请记住,如果我们想要解释这些测试,我们需要校正 p 值,以考虑我们进行了多个假设检验的事实;我们将在下一章中看到如何做到这一点。
请记住,我们最初想要测试的假设是是否在任何条件之间存在差异;我们将这称为“总体”假设检验,这是 F 统计提供的测试。F 统计基本上告诉我们我们的模型是否比仅包括一个截距的简单模型更好。在这种情况下,我们看到 F 检验非常显著,与我们的印象一致,即似乎各组之间确实存在差异(事实上我们知道确实存在差异,因为我们创建了数据)。
15.7 学习目标
阅读完本章后,您应该能够:
-
描述标志检验背后的原理
-
描述 t 检验如何用于将单个均值与假设值进行比较
-
使用双样本 t 检验比较两个配对或非配对组的均值
-
描述方差分析如何用于测试两个以上均值之间的差异。
15.8 附录
15.8.1 配对 t 检验作为线性模型
我们还可以根据一般线性模型来定义配对 t 检验。为此,我们将每个受试者的所有测量数据作为数据点(在整洁的数据框中)。然后,在模型中包括一个变量,该变量编码每个个体的身份(在这种情况下,包含每个人的受试者 ID 的 ID 变量)。这被称为“混合模型”,因为它包括独立变量的效应以及个体的效应。标准模型拟合过程“lm()”无法做到这一点,但我们可以使用一个名为“lme4”的流行 R 包中的“lmer()”函数来实现这一点,该包专门用于估计混合模型。公式中的“(1|ID)”告诉“lmer()”估计一个单独的截距(这是“1”所指的内容)用于“ID”变量的每个值(即数据集中的每个个体),然后估计一个将时间点与 BP 相关联的公共斜率。
# compute mixed model for paired test
lmrResult <- lmer(BPsys ~ timepoint + (1 | ID),
data = NHANES_sample_tidy)
summary(lmrResult)
## Linear mixed model fit by REML. t-tests use Satterthwaite's method [
## lmerModLmerTest]
## Formula: BPsys ~ timepoint + (1 | ID)
## Data: NHANES_sample_tidy
##
## REML criterion at convergence: 2895
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -2.3843 -0.4808 0.0076 0.4221 2.1718
##
## Random effects:
## Groups Name Variance Std.Dev.
## ID (Intercept) 236.1 15.37
## Residual 13.9 3.73
## Number of obs: 400, groups: ID, 200
##
## Fixed effects:
## Estimate Std. Error df t value Pr(>|t|)
## (Intercept) 121.370 1.118 210.361 108.55 <2e-16 ***
## timepointBPSys2 -1.020 0.373 199.000 -2.74 0.0068 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Correlation of Fixed Effects:
## (Intr)
## tmpntBPSys2 -0.167
您可以看到,这向我们显示了一个 p 值,该 p 值与使用“t.test()”函数计算的配对 t 检验的结果非常接近。
第十六章:多元统计
原文:
statsthinking21.github.io/statsthinking21-core-site/multivariate.html译者:飞龙
术语多元指的是涉及多个随机变量的分析。虽然我们之前看到的模型包括多个变量(如线性回归),但在这些情况下,我们特别关注的是如何解释因变量的变化,这些变化通常由实验者而不是被测量的自变量来解释。在多元分析中,我们通常将所有变量视为平等,并试图理解它们如何作为一个群体相互关联。
本章中有许多不同种类的多元分析,但我们将重点关注两种主要方法。首先,我们可能只是想要理解和可视化数据中存在的结构,通常指的是哪些变量或观察与其他变量或观察相关。我们通常会根据一些衡量指标来定义“相关”,这些指标可以衡量跨变量值之间的距离。属于这一类别的一个重要方法被称为聚类,旨在找到在变量或观察之间相似的聚类。
其次,我们可能希望将大量变量减少到较少的变量,同时尽量保留尽可能多的信息。这被称为降维,其中“维度”指的是数据集中的变量数量。我们将讨论两种常用的降维技术,即主成分分析和因子分析。
聚类和降维通常被归类为无监督学习的形式;这与迄今为止学到的线性回归等监督学习形成对比。我们认为线性回归是“监督学习”的原因是,我们知道我们试图预测的事物的价值(即依赖变量),并且我们试图找到最佳预测这些值的模型。在无监督学习中,我们没有特定的值要预测;相反,我们试图发现数据中可能有用于理解情况的结构,这通常需要一些关于我们想要找到什么样的结构的假设。
在本章中,您将发现,虽然在监督学习中通常存在一个“正确”的答案(一旦我们已经同意如何确定“最佳”模型,例如平方误差的总和),但在无监督学习中通常没有一个一致的“正确”答案。不同的无监督学习方法可能会给出关于相同数据的非常不同的答案,通常原则上无法确定哪一个是“正确”的,因为这取决于分析的目标和对产生数据的机制愿意做出的假设。有些人会觉得这很沮丧,而其他人会觉得这很令人振奋;您将需要弄清楚自己属于哪个阵营。
16.1 多元数据:一个例子
作为多元分析的一个例子,我们将看一下由我的团队收集并由 Eisenberg 等人发布的数据集。(Eisenberg:2019um?)。这个数据集很有用,因为它收集了大量有趣的变量,并且涉及相对较多的个体,并且可以在网上免费获取,因此您可以自行探索。
进行这项研究是因为我们对了解心理功能的几个不同方面如何相互关联感兴趣,特别关注自我控制和相关概念的心理测量。参与者在一周内进行了长达十小时的认知测试和调查;在这个第一个例子中,我们将关注与自我控制的两个特定方面相关的变量。反应抑制被定义为迅速停止行动的能力,在这项研究中使用了一组称为停止信号任务的任务来衡量。这些任务的感兴趣变量是一个估计一个人停止自己所需的时间,称为停止信号反应时间(SSRT),数据集中有四种不同的测量。冲动性被定义为倾向于冲动决策,不考虑潜在后果和长期目标。研究包括了许多不同的调查来衡量冲动性,但我们将关注UPPS-P调查,该调查评估了冲动性的五个不同方面。
在为艾森伯格的研究中的 522 名参与者计算了这些分数之后,我们得到了每个个体的 9 个数字。虽然多变量数据有时可能有数千甚至数百万个变量,但首先了解这些方法如何处理少量变量是有用的。
16.2 可视化多变量数据
多变量数据的一个基本挑战是,人眼和大脑只能够可视化三维以上的数据。我们可以使用各种工具来尝试可视化多变量数据,但随着变量数量的增加,所有这些工具都会失效。一种方法是首先减少维度(如下文所述),然后可视化减少后的数据集。
16.2.1 矩阵散点图
可视化少量变量的一种有用方法是将每对变量相互绘制,有时被称为“矩阵散点图”;图 16.1 中显示了一个例子。面板中的每行/列都指代一个单一变量 - 在这种情况下是我们之前例子中的心理变量之一。图中的对角元素显示了每个变量的分布情况,即直方图。对角线以下的元素显示了每对矩阵的散点图,并叠加了描述变量关系的回归线。对角线以上的元素显示了每对变量的相关系数。当变量数量相对较少(大约 10 个或更少)时,这可以是一种有用的方式来深入了解多变量数据集。
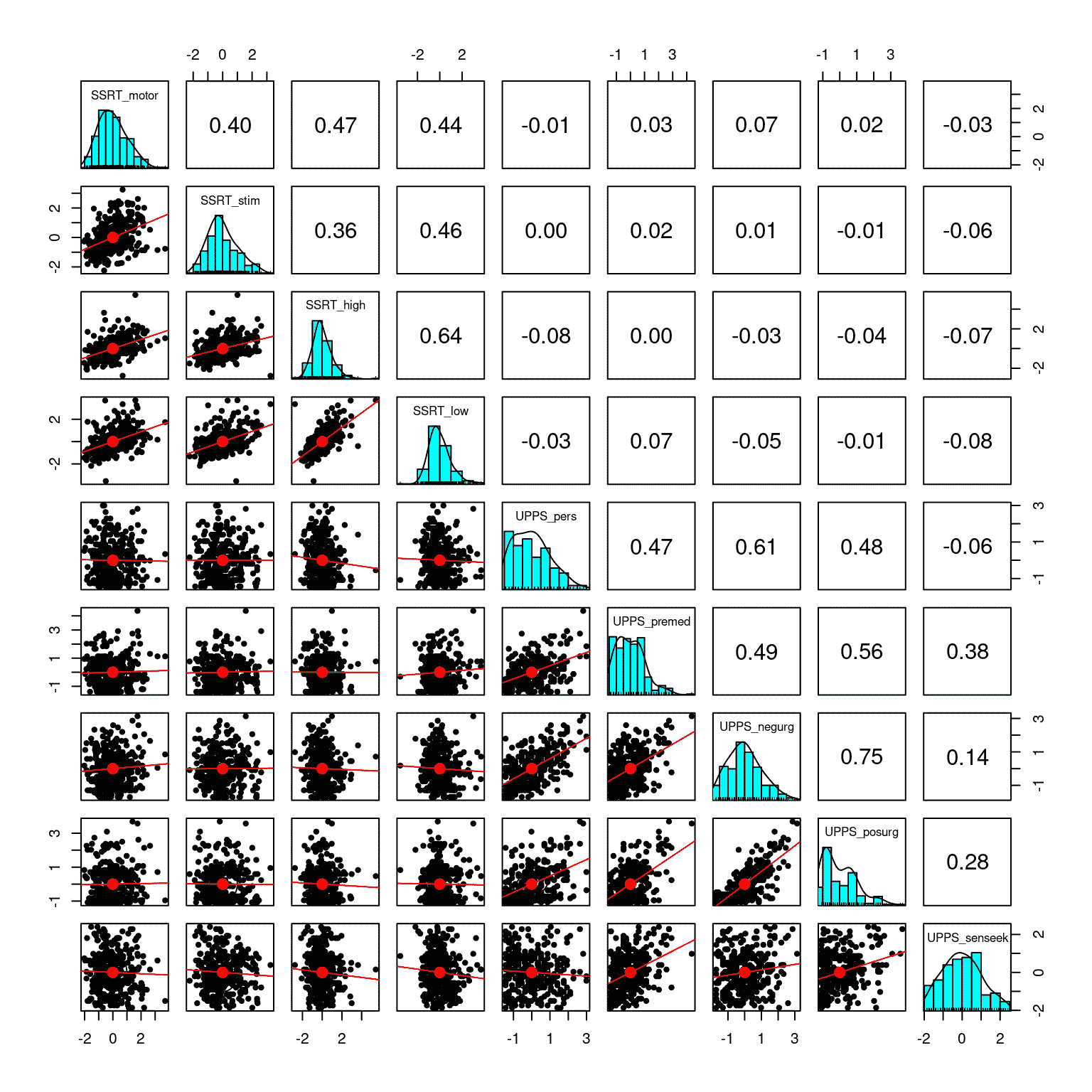
图 16.1:自我控制数据集中九个变量的矩阵散点图。矩阵中的对角元素显示了每个单独变量的直方图。左下方的面板显示了每对变量之间的关系散点图,右上方的面板显示了每对变量的相关系数。
16.2.2 热力图
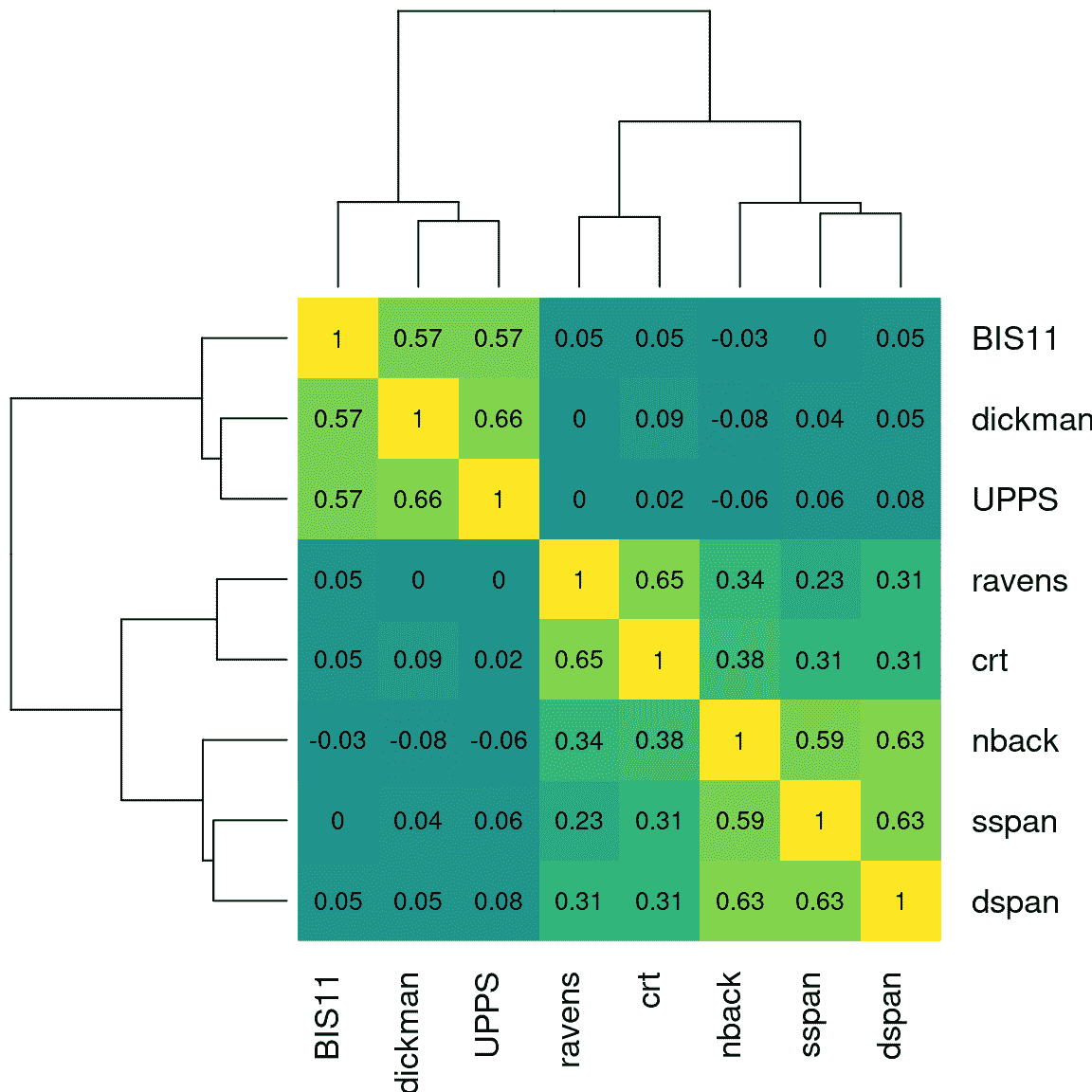
在某些情况下,我们希望一次可视化大量变量之间的关系,通常关注相关系数。这样做的一个有用方式是将相关值绘制成热图,其中地图的颜色与相关性的值相关。图 16.2 显示了一个相对较少变量的示例,使用了上面的心理学示例。在这种情况下,热图帮助我们看到数据的结构;我们看到 SSRT 变量内部和 UPPS 变量内部之间存在强相关,而两组变量之间的相关性相对较小。

图 16.2:九个自我控制变量的相关矩阵热图。左上角和右下角的较亮的黄色区域突出了两个变量子集内部的更高相关性。
热图特别适用于可视化大量变量之间的相关性。我们可以以脑成像数据为例。神经科学研究人员通常使用功能磁共振成像(fMRI)从大脑的许多位置收集关于脑功能的数据,然后评估这些位置之间的相关性,以测量区域之间的“功能连接”。例如,图 16.3 显示了一个大的相关矩阵的热图,基于单个个体(即我自己)大脑中 300 多个区域的活动。通过查看热图,数据中的清晰结构显而易见。特别是,我们看到有大量脑区域的活动彼此高度相关(在相关矩阵对角线上的大黄色块中可见),而这些块也与其他块强烈负相关(在对角线外的大蓝色块中可见)。热图是一种强大的工具,可以轻松可视化大型数据矩阵。

图 16.3:显示单个个体左半球 316 个脑区活动之间的相关系数的热图。黄色的单元格反映了强正相关,而蓝色的单元格反映了强负相关。矩阵对角线上的大块正相关对应于大脑中的主要连接网络
16.3 聚类
聚类是指一组方法,根据观测值的相似性在数据集中识别相关观测或变量的群组。通常,这种相似性将以某种多变量值的距离度量来量化。然后,聚类方法找到成员之间距离最小的一组群组。
聚类中常用的距离度量是欧氏距离,基本上是连接两个数据点的线的长度。图 16.4 显示了一个具有两个数据点和两个维度(X 和 Y)的数据集的示例。这两个点之间的欧氏距离是空间中连接点的虚线的长度。
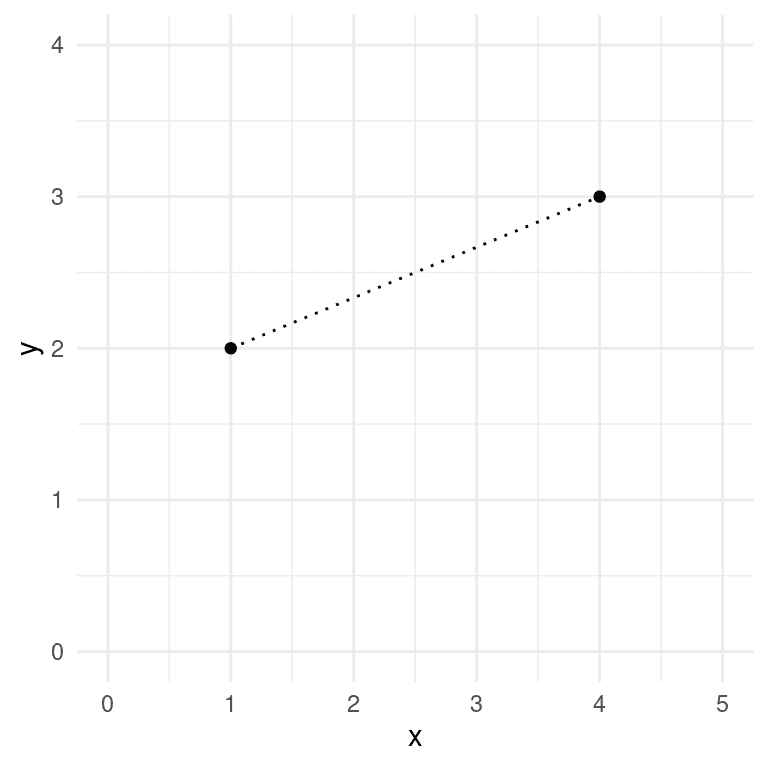
图 16.4:两点之间的欧几里德距离的描绘,(1,2)和(4,3)。这两点在 X 轴上相差 3,在 Y 轴上相差 1。
欧几里德距离是通过平方每个维度中点的位置的差异,将这些平方差异相加,然后取平方根来计算的。当有两个维度 x x x和 y y y时,这将被计算为:
d ( x , y ) = ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 d(x, y) = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2} d(x,y)=(x1−x2)2+(y1−y2)2
将我们示例数据的值代入公式:
d ( x , y ) = ( 1 − 4 ) 2 + ( 2 − 3 ) 2 = 3.16 d(x, y) = \sqrt{(1 - 4)^2 + (2 - 3)^2} = 3.16 d(x,y)=(1−4)2+(2−3)2=3.16
如果欧几里德距离的公式看起来有点熟悉,那是因为它与大多数人在几何课上学到的毕达哥拉斯定理是相同的,该定理根据两边的长度计算直角三角形的斜边长度。在这种情况下,三角形的两边的长度对应于沿着两个维度之一的点之间的距离。虽然这个例子是在两个维度上,但我们经常处理的数据的维度远远超过两个,但是相同的思想可以扩展到任意数量的维度。
欧几里德距离的一个重要特征是它对数据的整体均值和变异性敏感。在这个意义上,它不像相关系数,后者测量变量之间的线性关系,对整体均值或变异性不敏感。因此,通常在计算欧几里德距离之前对数据进行缩放,这相当于将每个变量转换为其 Z 得分版本。
16.3.1 K 均值聚类
一种常用的聚类数据的方法是K 均值聚类。这种技术识别一组聚类中心,然后将每个数据点分配给离该数据点最近的聚类(即欧几里德距离最小的聚类)。举个例子,让我们以世界各国的纬度和经度作为我们的数据点,并看看 K 均值聚类是否能有效地识别世界各大洲。
大多数统计软件包都有一个内置函数,可以使用单个命令执行 K 均值聚类,但了解它是如何一步一步工作的是很有用的。我们必须首先决定K的具体值,即要在数据中找到的聚类数。重要的是要指出,聚类数没有唯一的“正确”值;有各种技术可以尝试确定哪个解决方案是“最佳”的,但它们通常会给出不同的答案,因为它们包含不同的假设或权衡。尽管如此,聚类技术如 K 均值对于理解数据的结构是一种重要工具,特别是当它们变得高维时。
在选择我们希望找到的聚类数(K)之后,我们必须想出 K 个位置,这些位置将成为我们聚类中心的起始猜测(因为我们最初不知道中心在哪里)。一个简单的开始方法是随机选择 K 个实际数据点,并将它们用作我们的起始点,这些点被称为质心。然后,我们计算每个数据点到每个质心的欧几里德距离,并根据最接近的质心将每个点分配到一个聚类中。使用这些新的聚类分配,我们通过对分配给该聚类的所有点的位置进行平均来重新计算每个聚类的质心。然后重复这个过程,直到找到一个稳定的解决方案;我们将这称为迭代过程,因为它迭代直到答案不再改变,或者直到达到其他种类的限制,比如可能的最大迭代次数。
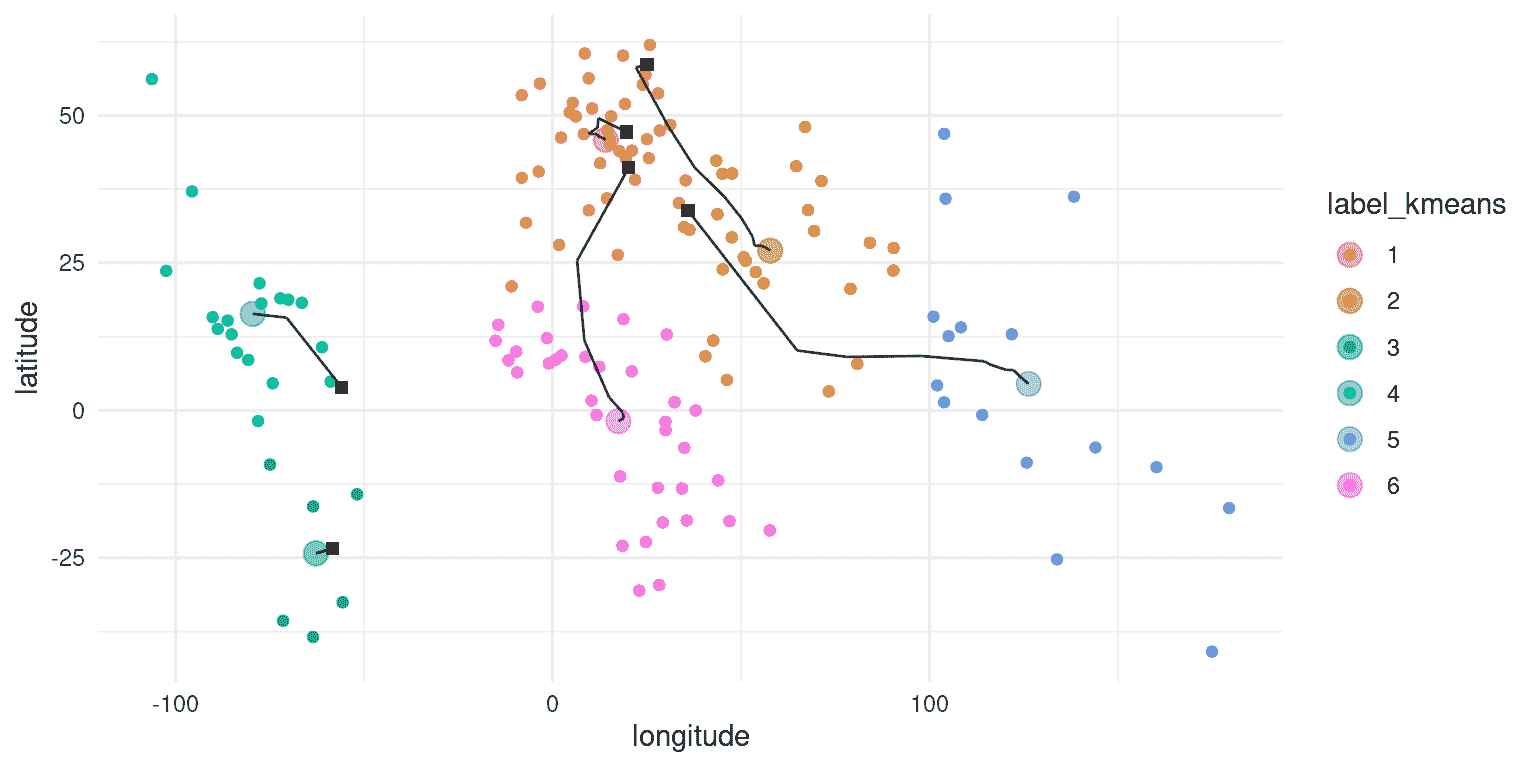
图 16.5:对世界各国的纬度和经度进行聚类的二维描述。方形黑色符号显示了每个簇的起始质心,线条显示了该簇在算法迭代中的移动。
将 K 均值聚类应用于纬度/经度数据(图 16.5),我们看到结果簇与大洲之间有合理的匹配,尽管没有一个大洲完全匹配任何一个簇。我们可以通过绘制一个表格来进一步检查这一点,该表格比较了每个国家的每个簇的成员资格与实际大洲;这种表格通常被称为混淆矩阵。
##
## labels AF AS EU NA OC SA
## 1 5 1 36 0 0 0
## 2 3 24 0 0 0 0
## 3 0 0 0 0 0 7
## 4 0 0 0 15 0 4
## 5 0 10 0 0 6 0
## 6 35 0 0 0 0 0
-
簇 1 包含所有欧洲国家,以及来自北非和亚洲的国家。
-
簇 2 包含亚洲国家以及一些非洲国家。
-
簇 3 包含南美洲南部的国家。
-
簇 4 包含所有北美国家以及南美洲北部国家。
-
簇 5 包含大洋洲以及一些亚洲国家
-
簇 6 包含所有剩余的非洲国家。
尽管在这个例子中我们知道实际的簇(也就是世界各大洲),但通常我们并不知道无监督学习问题的真实情况,所以我们只能相信聚类方法在数据中找到了有用的结构。然而,关于 K 均值聚类和迭代过程的一个重要点是,它们不能保证每次运行时都会得到相同的答案。使用随机数确定起始点意味着起始点每次可能不同,而且根据数据的不同,有时可能会导致找到不同的解决方案。对于这个例子,K 均值聚类有时会找到一个包含北美和南美的单一簇,有时会找到两个簇(就像在这里使用的特定随机种子的选择一样)。每当使用涉及迭代解决方案的方法时,重要的是使用不同的随机种子多次重新运行该方法,以确保答案在运行之间不会有太大的分歧。如果有的话,那么就不应该基于不稳定的结果得出坚定的结论。实际上,基于聚类结果得出坚定的结论可能是一个好主意;它们主要用于对可能存在于数据集中的结构有直观感觉。
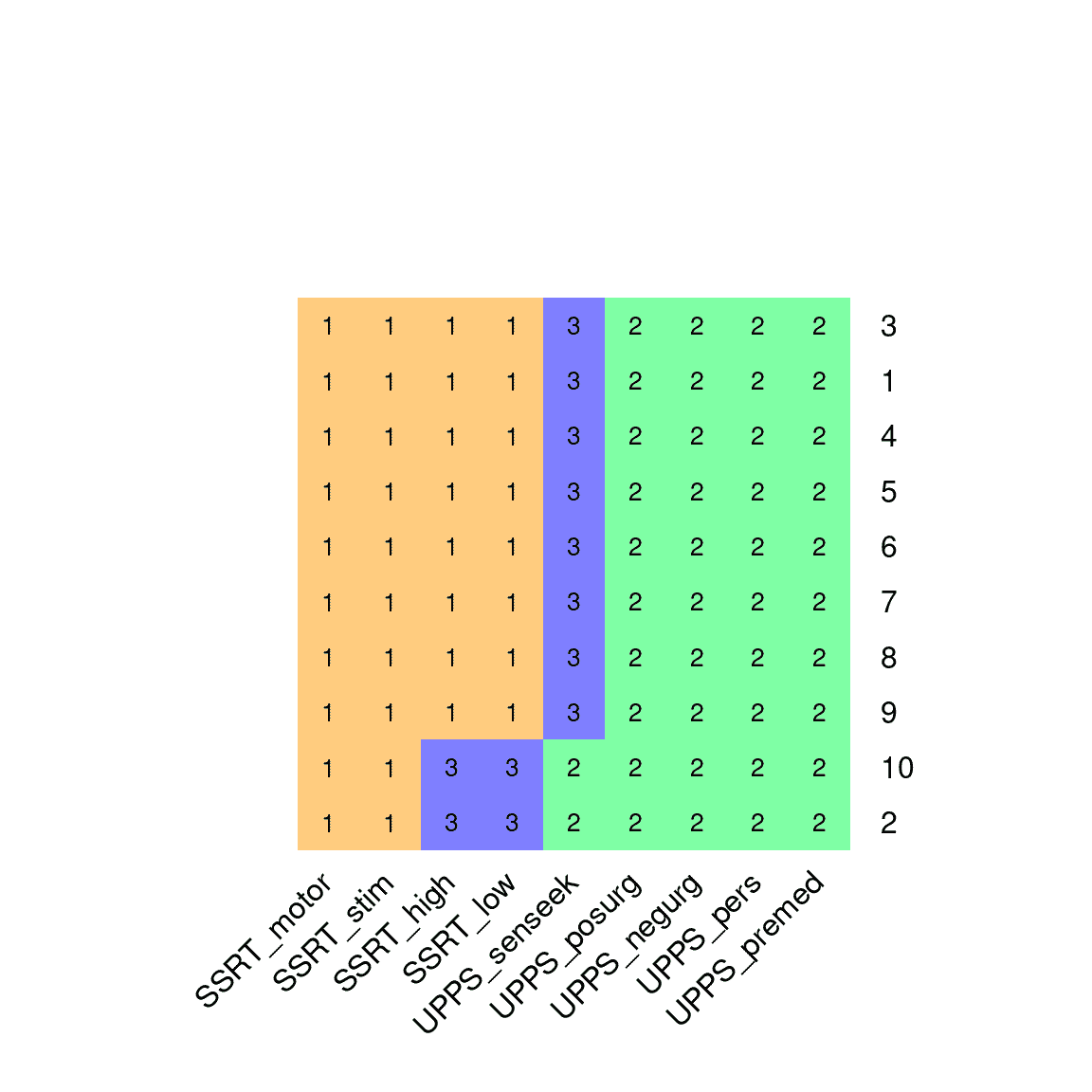
图 16.6:K=3 的 K 均值聚类算法的 10 次运行结果的可视化。图中的每一行代表聚类算法的不同运行(使用不同的随机起始点),颜色相同的变量属于同一簇。
我们可以对自我控制变量应用 K 均值聚类,以确定哪些变量彼此之间最密切相关。对于 K=2,K 均值算法始终选择包含 SSRT 变量和包含冲动性变量的一个聚类。对于较高的 K 值,结果不太一致;例如,对于 K=3,该算法有时会识别出一个仅包含 UPPS 感觉寻求变量的第三个聚类,而在其他情况下,它将 SSRT 变量分成两个单独的聚类(如图 16.6 所示)。K=2 时聚类的稳定性表明,这可能是这些数据的最稳健的聚类,但这些结果也突显了多次运行算法以确定任何特定聚类结果是否稳定的重要性。
16.3.2 层次聚类
另一种检查多元数据集结构的有用方法被称为层次聚类。这种技术也利用数据点之间的距离来确定聚类,但它还提供了一种可视化数据点之间关系的方式,即树状结构,称为树状图。
最常用的层次聚类程序被称为聚合聚类。该程序首先将每个数据点视为自己的一个聚类,然后通过合并两个距离最小的聚类来逐渐创建新的聚类。它继续这样做,直到只剩下一个单一的聚类。这需要计算聚类之间的距离,有许多方法可以做到这一点;在这个例子中,我们将使用平均链接方法,它简单地取两个聚类中每个数据点之间的所有距离的平均值。例如,我们将检查上面描述的自我控制变量之间的关系。
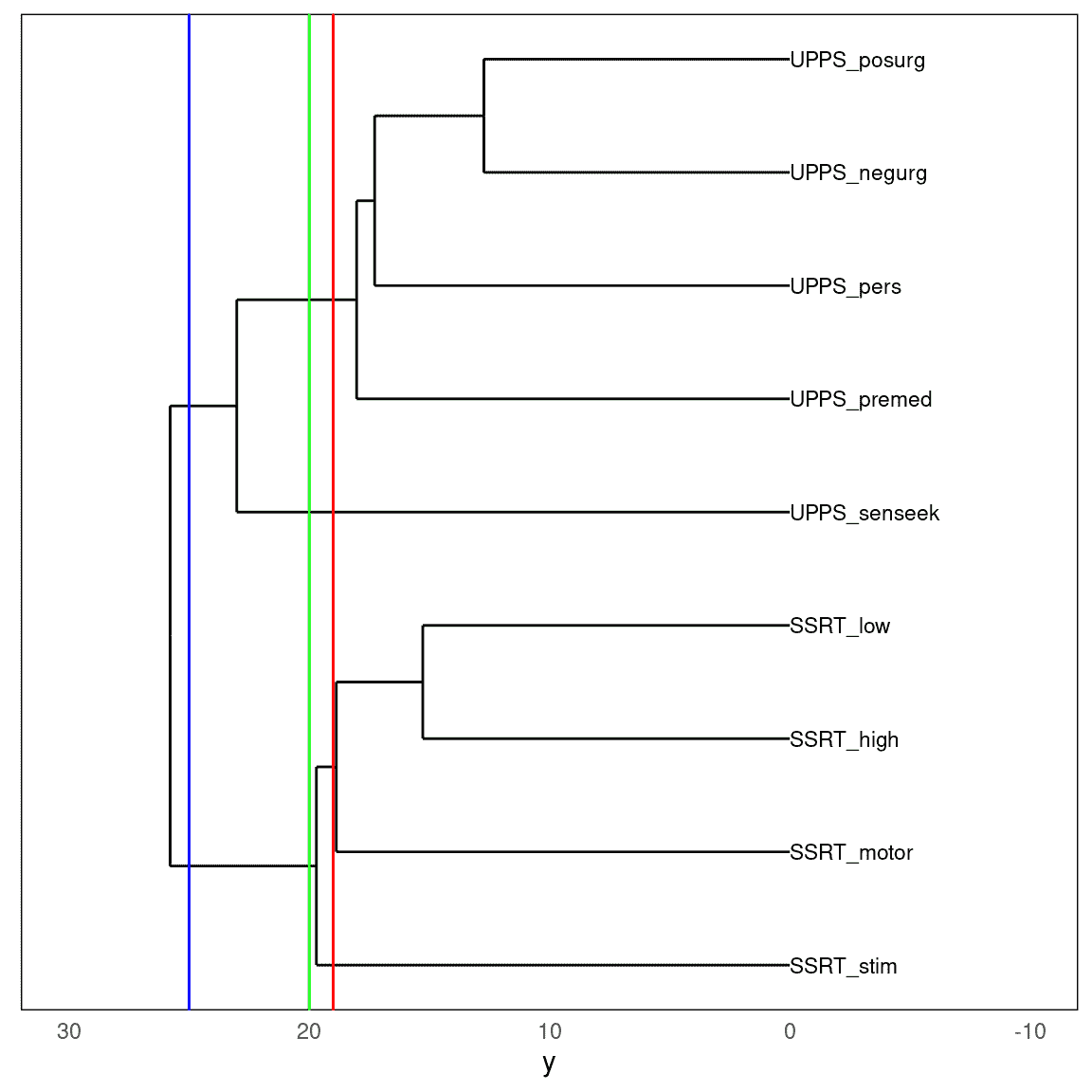
图 16.7:树状图显示了九个自我控制变量的相对相似性。三条彩色垂直线代表三个不同的截断点,分别得到两个(蓝线)、三个(绿线)或四个(红线)聚类。
图 16.7 显示了从自我调节数据集生成的树状图。在这里,我们看到变量之间的关系具有结构,可以通过“剪切”树来在不同层次上理解:如果我们在 25 处剪切树,我们得到两个聚类;如果我们在 20 处剪切,我们得到三个聚类,而在 19 处我们得到四个聚类。
有趣的是,对自我控制数据进行层次聚类分析找到的解与大多数 K 均值聚类运行找到的解相同,这令人欣慰。
我们对这个分析的解释是,每个变量集合(SSRT 和 UPPS)内部之间存在高度相似性,而与集合之间相比则相对较少。在 UPPS 变量中,似乎寻求感觉变量与其他变量有所不同,其他变量之间更相似。在 SSRT 变量中,似乎刺激选择性 SSRT 变量与其他三个变量有所不同,其他三个变量更相似。这些是可以从聚类分析中得出的结论。重要的是要指出,没有单一“正确”的聚类数量;不同的方法依赖于不同的假设或启发式方法,可能会给出不同的结果和解释。一般来说,最好以几个不同的层次呈现聚类数据,并确保这不会大幅改变数据的解释。
16.4 降维
在多变量数据中,往往许多变量之间会高度相似,它们在很大程度上测量相同的事物。一种思考方式是,虽然数据具有特定数量的变量,我们称之为维度,但实际上信息源并不像变量那么多。降维的想法是减少变量数量,以创建反映数据中潜在信号的复合变量。
16.4.1 主成分分析
主成分分析的想法是找到一组变量的低维描述,以解释完整数据集中可能的最大信息量。对主成分分析的深入理解需要对线性代数有深刻的理解,这超出了本书的范围;请参阅本章末尾的资源,了解有关此主题的有用指南。在本节中,我将概述这个概念,并希望激发您学习更多的兴趣。
我们将从一个简单的例子开始,只有两个变量,以便直观地理解它是如何工作的。首先,我们为变量 X 和 Y 生成一些合成数据,两个变量之间的相关性为 0.7。主成分分析的目标是找到数据集中观察变量的线性组合,以解释最大量的方差;这里的想法是数据中的方差是信号和噪音的组合,我们希望找到变量之间最强的共同信号。第一个主成分是解释最大方差的组合。第二个成分是解释剩余最大方差的组合,同时与第一个成分不相关。对于更多的变量,我们可以继续这个过程,获得与变量数量相同的成分(假设观察次数多于变量数量),尽管在实践中,我们通常希望找到能解释大部分方差的少数成分。
在我们的二维示例中,我们可以计算主成分并将它们绘制在数据上(图 16.8)。我们看到第一个主成分(显示为绿色)沿着最大方差的方向。这条线与线性回归线相似,尽管不完全相同;虽然线性回归解决方案最小化了每个数据点与回归线在相同 X 值(即垂直距离)的距离,但主成分最小化了数据点与表示该成分的线之间的欧几里得距离(即垂直于成分的距离)。第二个成分指向与第一个成分垂直的方向(相当于不相关)。
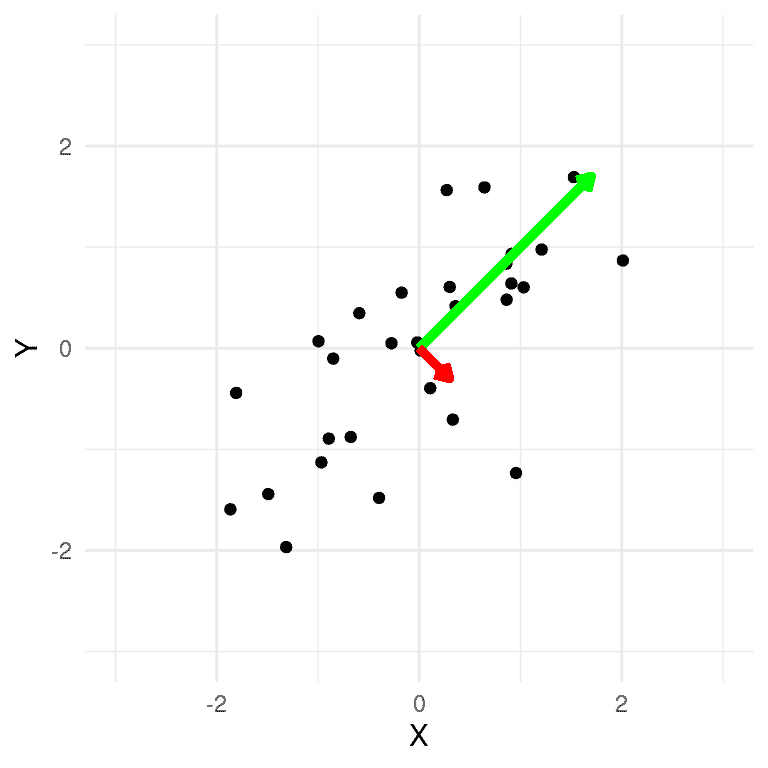
图 16.8:合成数据的绘图,第一个主成分以绿色绘制,第二个以红色绘制。
通常使用 PCA 来降低更复杂数据集的维度。例如,假设我们想知道早期数据集中所有四个停止信号任务变量的表现是否与五个冲动性调查变量相关。我们可以分别对这些数据集执行 PCA,并检查数据中多少方差由第一个主成分解释,这将作为我们对数据的摘要。
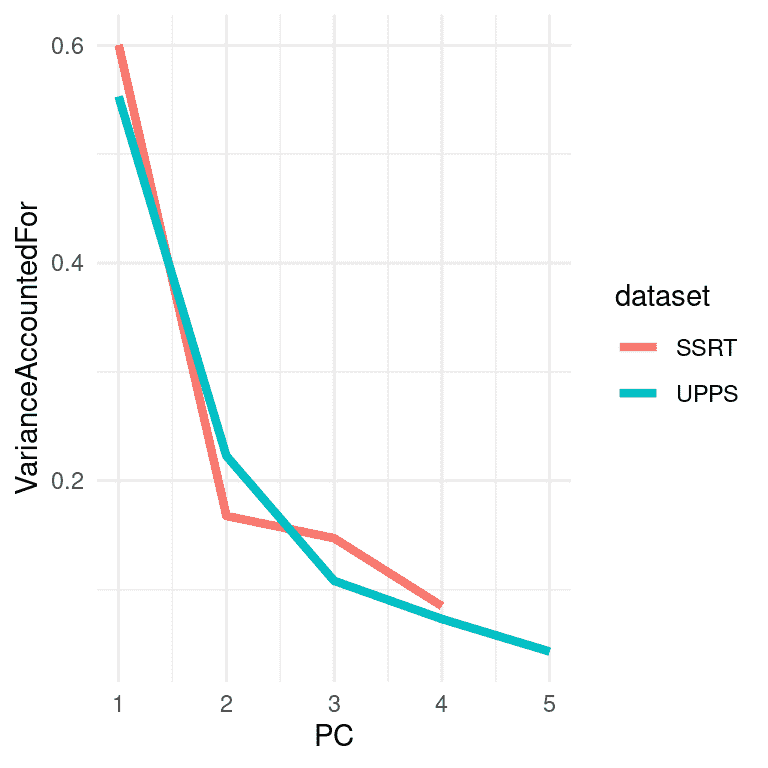
图 16.9:Eisenberg 数据集中应用 PCA 分别应用于反应抑制和冲动性变量的方差解释(或屏幕图)的绘图。
我们在图 16.9 中看到,对于停止信号变量,第一个主成分解释了数据中约 60%的方差,而对于 UPPS,它解释了约 55%的方差。然后,我们可以计算使用每组变量的第一个主成分获得的分数之间的相关性,以了解两组变量之间是否存在关系。两个摘要变量之间的-0.014 的相关性表明,在这个数据集中,反应抑制和冲动性之间没有总体关系。
##
## Pearson's product-moment correlation
##
## data: pca_df$SSRT and pca_df$UPPS
## t = -0.3, df = 327, p-value = 0.8
## alternative hypothesis: true correlation is not equal to 0
## 95 percent confidence interval:
## -0.123 0.093
## sample estimates:
## cor
## -0.015
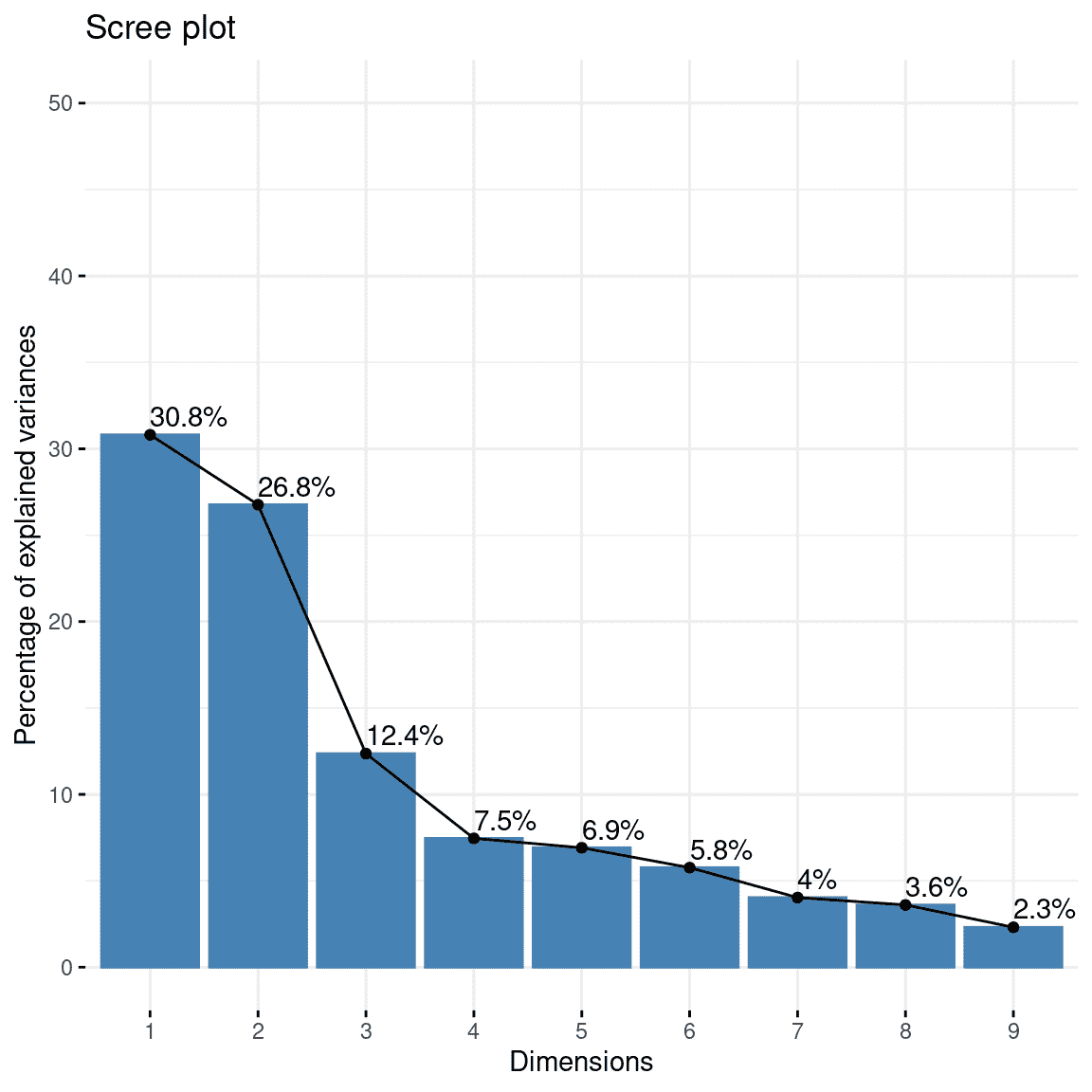
我们还可以同时对所有这些变量进行 PCA。查看图 16.7 中解释的方差的绘图(也称为屏幕图),我们可以看到前两个成分解释了数据中相当多的方差。然后,我们可以查看每个单独变量在这两个成分上的载荷,以了解每个特定变量与不同成分的关联。
(#fig:imp_pc_scree)绘制了在全套自控变量上计算的 PCA 成分解释的方差。
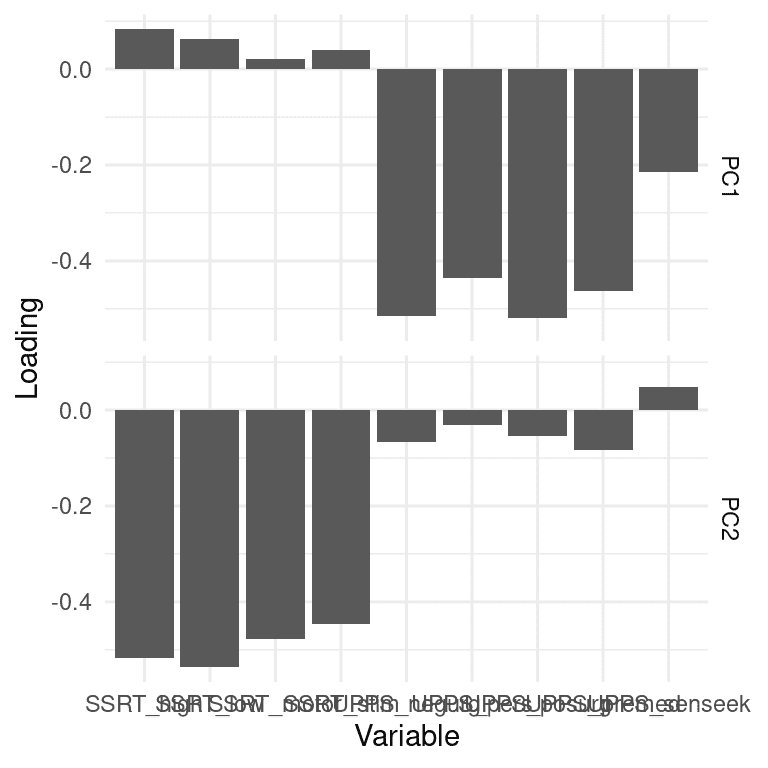
图 16.10:在包括所有自控变量的 PCA 解决方案中计算的 PCA 成分的变量载荷的绘图。每个变量都显示为其在两个成分中的载荷;分别反映在两行中。
对冲动性数据集进行这样的操作(图 16.10),我们看到第一个成分(在图的第一行)对大多数 UPPS 变量具有非零载荷,对每个 SSRT 变量几乎没有载荷,而第二主成分的情况正好相反,它主要对 SSRT 变量进行载荷。这告诉我们,第一个主成分主要捕获了与冲动性测量相关的方差,而第二个主成分主要捕获了与反应抑制测量相关的方差。您可能会注意到这些变量的载荷实际上是负的;载荷的符号是任意的,因此我们应该确保查看大的正载荷和负载荷。
16.4.2 因子分析
虽然主成分分析对于将数据集减少到较少数量的复合变量可能是有用的,但是标准的 PCA 方法有一些局限性。最重要的是,它确保组件之间不相关;虽然这有时可能是有用的,但通常存在我们希望提取可能彼此相关的维度的情况。第二个限制是 PCA 不考虑正在分析的变量中的测量误差,这可能导致难以解释结果的载荷。虽然有修改 PCA 可以解决这些问题,但在某些领域(如心理学)中更常见的是使用一种称为探索性因子分析(或 EFA)的技术来降低数据集的维度。¹
EFA 的理念是每个观察变量都是通过一组潜在变量的贡献组合而成的,即不能直接观察到的变量,以及每个变量的一定量的测量误差。因此,EFA 模型通常被称为属于一类称为潜在变量模型的统计模型。
例如,假设我们想了解几个不同变量的测量与产生这些测量的潜在因素之间的关系。我们将首先生成一个合成数据集,以展示这可能是如何工作的。我们将生成一组个体,假装我们知道几个潜在心理变量的值:冲动性、工作记忆能力和流体推理。我们假设工作记忆能力和流体推理彼此相关,但两者都与冲动性不相关。然后,我们将从这些潜在变量中为每个个体生成一组八个观察变量,这些变量只是潜在变量的线性组合,同时加入随机噪声以模拟测量误差。
我们可以通过显示与所有这些变量相关的相关矩阵的热图来进一步检查数据(图 16.7)。从中我们可以看到,有三个变量簇对应于我们的三个潜在变量,这正是应该的。
(#fig:efa_cor_hmap)显示从三个潜在潜在变量生成的变量之间的相关性的热图。
我们可以将 EFA 视为一次性估计一组线性模型的参数,其中每个模型将每个观察变量与潜在变量相关联。对于我们的示例,这些方程将如下所示。在这些方程中, β \beta β字符有两个下标,一个是指任务,另一个是指潜在变量,还有一个变量 ϵ \epsilon ϵ指的是误差。在这里,我们假设一切都有零的平均值,因此我们不需要为每个方程包括额外的截距项。
n b a c k = b e t a [ 1 , 1 ] ∗ W M + β [ 1 , 2 ] ∗ F R + β [ 1 , 3 ] ∗ I M P + ϵ d s p a n = b e t a [ 2 , 1 ] ∗ W M + β [ 2 , 2 ] ∗ F R + β [ 2 , 3 ] ∗ I M P + ϵ o s p a n = b e t a [ 3 , 1 ] ∗ W M + β [ 3 , 2 ] ∗ F R + β [ 3 , 3 ] ∗ I M P + ϵ r a v e n s = b e t a [ 4 , 1 ] ∗ W M + β [ 4 , 2 ] ∗ F R + β [ 4 , 3 ] ∗ I M P + ϵ c r t = b e t a [ 5 , 1 ] ∗ W M + β [ 5 , 2 ] ∗ F R + β [ 5 , 3 ] ∗ I M P + ϵ U P P S = b e t a [ 6 , 1 ] ∗ W M + β [ 6 , 2 ] ∗ F R + β [ 6 , 3 ] ∗ I M P + ϵ B I S 11 = b e t a [ 7 , 1 ] ∗ W M + β [ 7 , 2 ] ∗ F R + β [ 7 , 3 ] ∗ I M P + ϵ d i c k m a n = b e t a [ 8 , 1 ] ∗ W M + β [ 8 , 2 ] ∗ F R + β [ 8 , 3 ] ∗ I M P + ϵ \begin{array}{lcl} nback & = &beta_{[1, 1]} * WM + \beta_{[1, 2]} * FR + \beta_{[1, 3]} * IMP + \epsilon \\ dspan & = &beta_{[2, 1]} * WM + \beta_{[2, 2]} * FR + \beta_{[2, 3]} * IMP + \epsilon \\ ospan & = &beta_{[3, 1]} * WM + \beta_{[3, 2]} * FR + \beta_{[3, 3]} * IMP + \epsilon \\ ravens & = &beta_{[4, 1]} * WM + \beta_{[4, 2]} * FR + \beta_{[4, 3]} * IMP + \epsilon \\ crt & = &beta_{[5, 1]} * WM + \beta_{[5, 2]} * FR + \beta_{[5, 3]} * IMP + \epsilon \\ UPPS & = &beta_{[6, 1]} * WM + \beta_{[6, 2]} * FR + \beta_{[6, 3]} * IMP + \epsilon \\ BIS11 & = &beta_{[7, 1]} * WM + \beta_{[7, 2]} * FR + \beta_{[7, 3]} * IMP + \epsilon \\ dickman & = &beta_{[8, 1]} * WM + \beta_{[8, 2]} * FR + \beta_{[8, 3]} * IMP + \epsilon \\ \end{array} nbackdspanospanravenscrtUPPSBIS11dickman========beta[1,1]∗WM+β[1,2]∗FR+β[1,3]∗IMP+ϵbeta[2,1]∗WM+β[2,2]∗FR+β[2,3]∗IMP+ϵbeta[3,1]∗WM+β[3,2]∗FR+β[3,3]∗IMP+ϵbeta[4,1]∗WM+β[4,2]∗FR+β[4,3]∗IMP+ϵbeta[5,1]∗WM+β[5,2]∗FR+β[5,3]∗IMP+ϵbeta[6,1]∗WM+β[6,2]∗FR+β[6,3]∗IMP+ϵbeta[7,1]∗WM+β[7,2]∗FR+β[7,3]∗IMP+ϵbeta[8,1]∗WM+β[8,2]∗FR+β[8,3]∗IMP+ϵ
实际上,我们使用 EFA 想要做的是估计将潜在变量映射到观察变量的系数(beta)矩阵。对于我们生成的数据,我们知道这个矩阵中的大多数 beta 都是零,因为我们是这样创建的;对于每个任务,只有一个权重被设置为 1,这意味着每个任务是单个潜在变量的嘈杂测量。
我们可以将 EFA 应用于我们的合成数据集以估计这些参数。我们不会详细介绍 EFA 是如何实际执行的,只是提到一个重要的点。本书中大多数先前的分析都依赖于试图最小化观察数据值与模型预测值之间的差异的方法。用于估计 EFA 参数的方法反而试图最小化观察变量之间的协方差与模型参数暗示的协方差之间的差异。因此,这些方法通常被称为协方差结构模型。
让我们将探索性因子分析应用到我们的合成数据上。与聚类方法一样,我们首先需要确定我们的模型中要包含多少个潜在因子。在这种情况下,我们知道有三个因子,所以让我们从这个开始;稍后我们将研究直接从数据中估计因子数量的方法。这是我们统计软件对这个模型的输出:
##
## Factor analysis with Call: fa(r = observed_df, nfactors = 3)
##
## Test of the hypothesis that 3 factors are sufficient.
## The degrees of freedom for the model is 7 and the objective function was 0.04
## The number of observations was 200 with Chi Square = 8 with prob < 0.34
##
## The root mean square of the residuals (RMSA) is 0.01
## The df corrected root mean square of the residuals is 0.03
##
## Tucker Lewis Index of factoring reliability = 0.99
## RMSEA index = 0.026 and the 10 % confidence intervals are 0 0.094
## BIC = -29
## With factor correlations of
## MR1 MR2 MR3
## MR1 1.00 0.03 0.47
## MR2 0.03 1.00 0.03
## MR3 0.47 0.03 1.00
我们想要问的一个问题是我们的模型实际上对数据拟合得有多好。没有单一的方法来回答这个问题;相反,研究人员已经开发了许多不同的方法,这些方法可以提供一些关于模型对数据拟合程度的见解。例如,一个常用的标准是基于均方根逼近误差(RMSEA)统计量,它量化了预测的协方差与实际协方差之间的距离;RMSEA 小于 0.08 的值通常被认为反映了一个适当拟合的模型。在这个例子中,RMSEA 值为 0.026,这表明模型拟合得相当好。
我们还可以检查参数估计,以查看模型是否适当地识别了数据中的结构。通常将这个作为图表,用箭头从潜在变量(表示为椭圆)指向观察变量(表示为矩形),其中箭头表示观察变量对潜在变量的实质性载荷;这种图通常被称为路径图,因为它反映了变量之间的路径关系。这在图 16.11 中显示。在这种情况下,EFA 过程正确地识别了数据中存在的结构,无论是哪些观察变量与每个潜在变量相关,还是潜在变量之间的相关性。
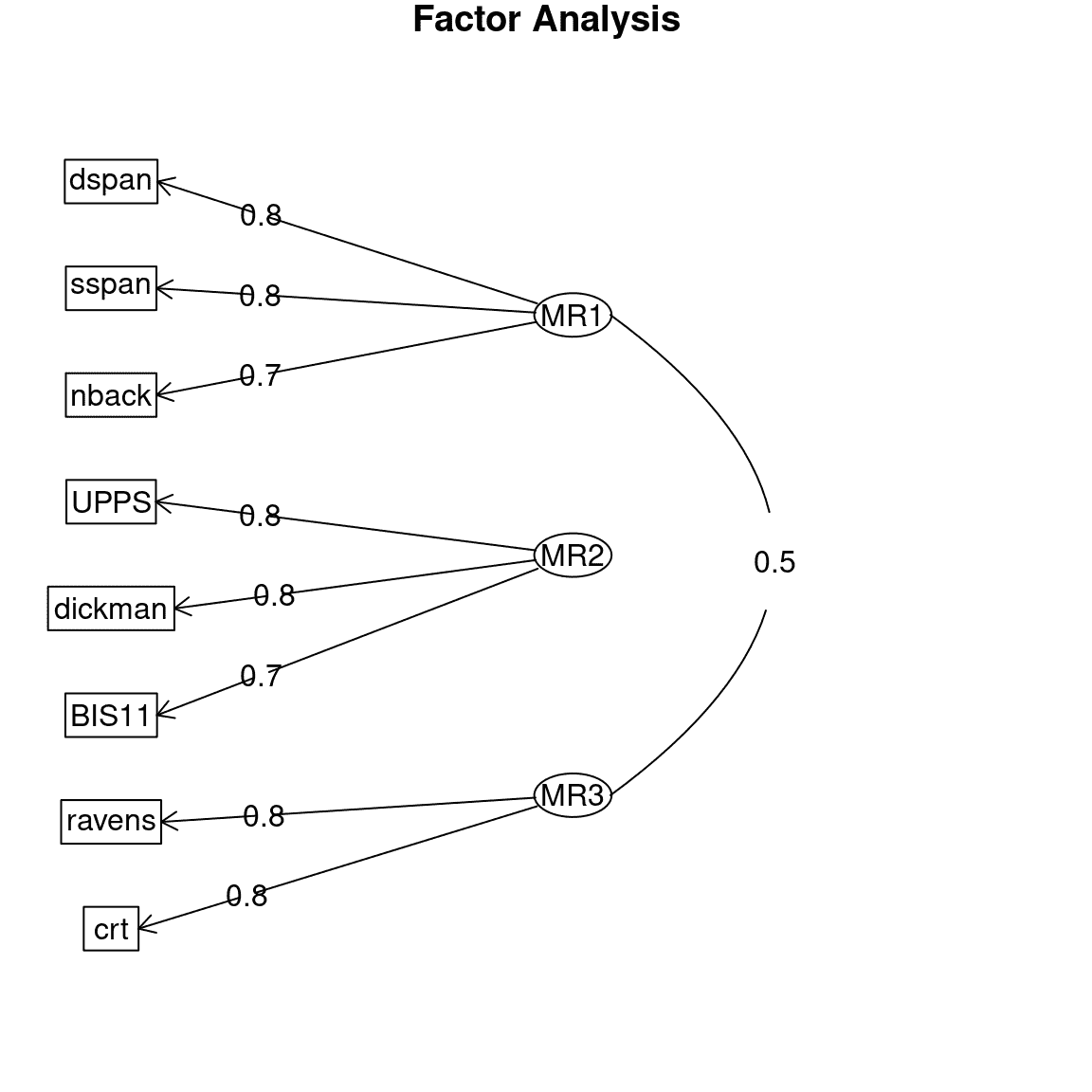
图 16.11:探索性因子分析模型的路径图。
16.4.3 确定因子的数量
应用 EFA 的主要挑战之一是确定因子的数量。一个常见的做法是在改变因子数量的同时检查模型的拟合情况,然后选择给出最佳拟合的模型。这并不是绝对可靠的,有多种方法来量化模型的拟合程度,有时会得出不同的答案。
有人可能会认为我们可以简单地看模型拟合得有多好,然后选择最拟合的因素数量,但这不起作用,因为更复杂的模型总是会更好地拟合数据(正如我们在之前关于过度拟合的讨论中看到的)。因此,我们需要使用一个惩罚模型参数数量的模型拟合度量。在这个例子中,我们将选择一种常见的量化模型拟合度的方法,即样本大小调整的贝叶斯信息准则(或SABIC)。这个度量量化了模型对数据的拟合程度,同时还考虑了模型中的参数数量(在这种情况下与因素数量有关)以及样本大小。虽然 SABIC 的绝对值是不可解释的,但是当使用相同的数据和相同类型的模型时,我们可以使用 SABIC 来比较模型,以确定哪个对数据最合适。关于 SABIC 和其他类似的度量(称为信息准则)的一个重要事实是,较低的值代表模型拟合得更好,因此在这种情况下,我们希望找到具有最低 SABIC 的因素数量。在图 16.12 中,我们看到具有最低 SABIC 的模型有三个因素,这表明这种方法能够准确确定用于生成数据的因素数量。
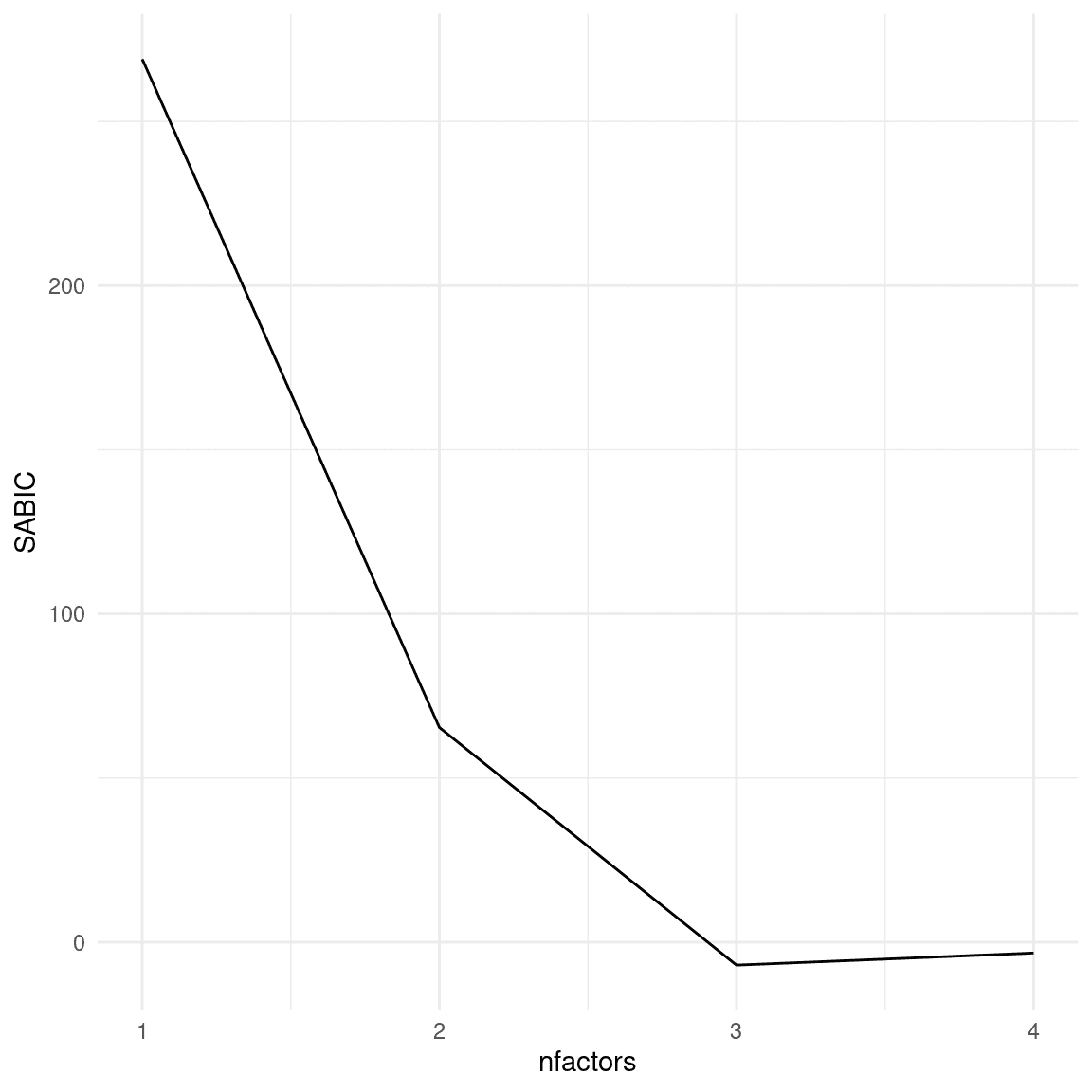
图 16.12:不同因素数量的 SABIC 图。
现在让我们看看当我们将这个模型应用到 Eisenberg 等人数据集的真实数据时会发生什么,该数据集包含了上面示例中模拟的所有八个变量的测量值。三因素模型在这些真实数据中的 SABIC 也是最低的。
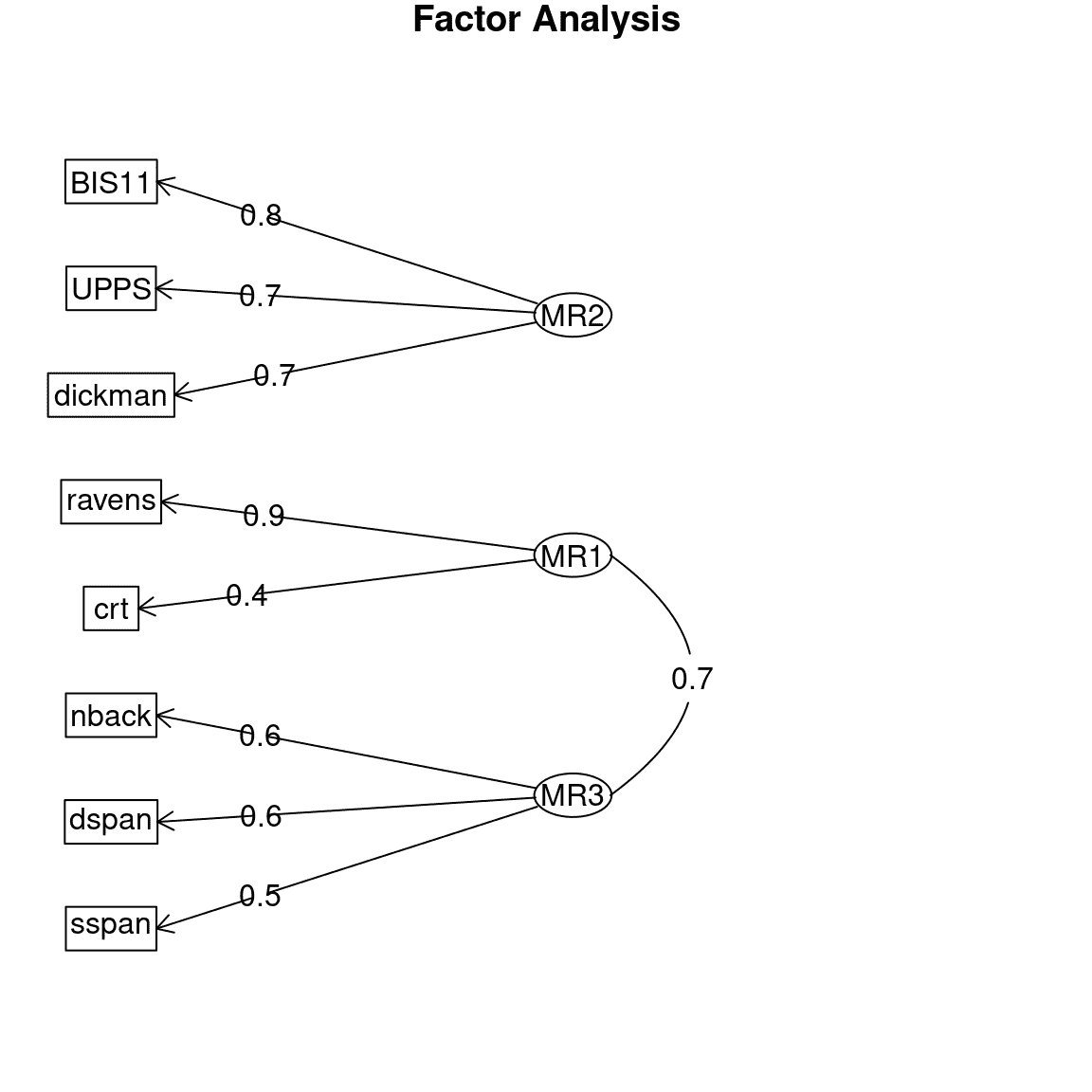
图 16.13:Eisenberg 等人数据上三因素模型的路径图。
绘制路径图(图 16.13),我们看到真实数据展示了一个与我们在模拟数据中看到的非常相似的因素结构。这并不奇怪,因为模拟数据是基于对这些不同任务的知识生成的,但是知道人类行为是有系统性的,我们可以可靠地识别这些关系是令人欣慰的。主要的区别是工作记忆因素(MR3)和流体推理因素(MR1)之间的相关性甚至比模拟数据中更高。这个结果在科学上是有用的,因为它向我们展示了,虽然工作记忆和流体推理密切相关,但分别对它们进行建模是有用的。
16.5 学习目标
阅读完本章后,您应该能够:
-
描述监督学习和无监督学习之间的区别。
-
使用可视化技术,包括热图,来可视化多变量数据的结构。
-
了解聚类的概念以及如何用它来识别数据中的结构。
-
理解降维的概念。
-
描述主成分分析和因素分析如何用于进行降维。
16.6 建议阅读
-
多元统计的几何学,Thomas Wickens
-
线性代数的无废话指南,Ivan Savov
- 还有另一种因素分析的应用,称为验证性因素分析(或 CFA),我们在这里不讨论;在实践中,它的应用可能存在问题,最近的研究已经开始转向修改 EFA 以回答通常使用 CFA 解决的问题。(Marsh:2014th?)↩︎
第十七章:实际统计建模
原文:
statsthinking21.github.io/statsthinking21-core-site/practical-example.html译者:飞龙
在本章中,我们将通过将我们所学到的一切应用到一个实际例子中来汇总一切。 2007 年,斯坦福大学的克里斯托弗·加德纳和同事在《美国医学会杂志》上发表了一篇题为“阿特金斯,区域,奥尼什和学习饮食对超重绝经前妇女体重和相关危险因素变化的比较 - A TO Z 减肥研究:随机试验”的研究(Gardner et al. 2007)。 我们将使用这项研究来展示如何从头到尾分析实验数据。
17.1 统计建模的过程
当我们想要使用我们的统计模型来测试科学假设时,通常会经历一系列步骤:
-
指定您感兴趣的问题
-
确定或收集适当的数据
-
为分析准备数据
-
确定适当的模型
-
将模型拟合到数据
-
批评模型以确保其适当拟合
-
测试假设并量化效应大小
17.1.1 1: 指定您感兴趣的问题
根据作者的说法,他们研究的目标是:
比较代表低至高碳水化合物摄入谱的 4 种减肥饮食对体重减轻和相关代谢变量的影响。
17.1.2 2: 确定或收集适当的数据
为了回答他们的问题,调查人员随机分配了 311 名超重/肥胖妇女中的每一位到四种不同的饮食(阿特金斯,区域,奥尼什或学习),并随着时间测量了她们的体重以及许多其他健康指标。 作者记录了大量变量,但对于感兴趣的主要问题,让我们专注于一个单一变量:身体质量指数(BMI)。 此外,由于我们的目标是测量 BMI 的持久变化,我们只会关注饮食开始后 12 个月的测量。
17.1.3 3: 为分析准备数据
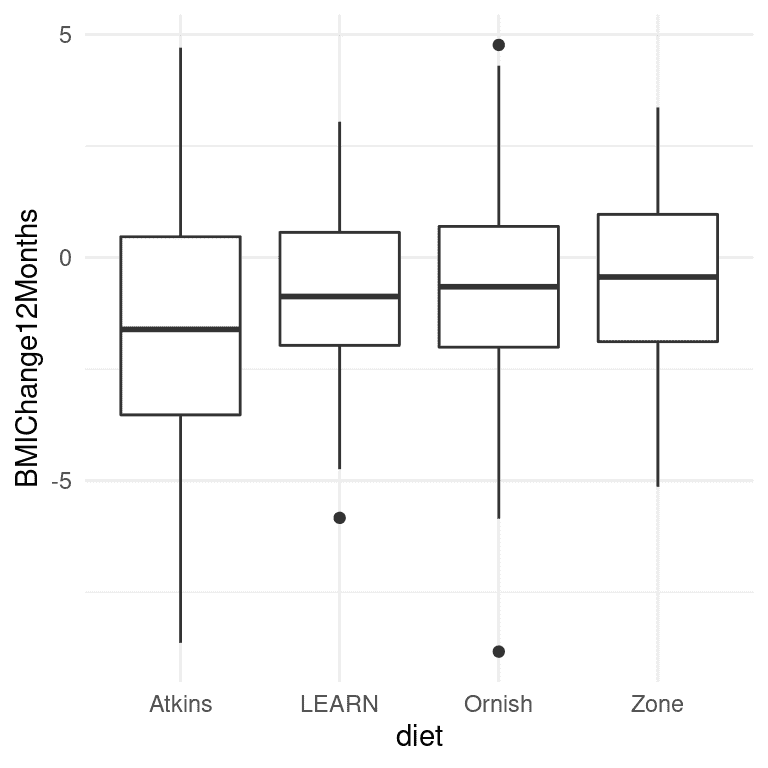
图 17.1:每个条件的箱线图,每组的第 50 百分位数(即中位数)显示为黑线。
A 到 Z 研究的实际数据并不是公开的,因此我们将使用他们的论文中报告的摘要数据来生成一些大致符合其研究中获得的数据的合成数据,每组的均值和标准差相同。 一旦我们有了数据,我们可以将它们可视化,以确保没有异常值。 箱线图对于查看分布的形状很有用,如图 17.1 所示。 这些数据看起来相当合理-在各个组内有一些异常值(由箱线图外的点表示),但它们似乎不会在其他组方面极端。 我们还可以看到,这些分布在方差上似乎有些不同,阿特金斯的变异性略大于其他饮食。 这意味着任何假设方差在各组之间相等的分析可能是不合适的。 幸运的是,我们计划使用的 ANOVA 模型对此相当健壮。
17.1.4 4. 确定适当的模型
为了确定我们分析的适当统计模型,我们需要提出几个问题。
-
什么样的因变量?
-
BMI:连续,大致正态分布
-
我们在比较什么?
-
四种饮食组的平均 BMI
-
ANOVA 是合适的
-
观察是否独立?
-
随机分配应确保独立性的假设是适当的
-
使用差异分数(在本例中是起始体重和 12 个月后体重之间的差异)在某种程度上是有争议的,特别是当不同组之间的起始点不同时。在这种情况下,各组的起始体重非常相似,因此我们将使用差异分数,但一般来说,在将这样的模型应用于真实数据之前,人们会希望咨询统计学家。
17.1.5 5. 将模型拟合到数据
让我们对 BMI 变化进行一项方差分析,比较四种饮食之间的差异。大多数统计软件会自动将名义变量转换为一组虚拟变量。使用公式表示法是指定统计模型的常见方式,其中模型使用以下形式的公式进行指定:
因变量 ∼ 自变量 \text{因变量} \sim \text{自变量} 因变量∼自变量
在这种情况下,我们希望查看 BMI 的变化(存储在一个名为BMIChange12Months的变量中)作为饮食(存储在一个名为diet的变量中)的函数,因此我们使用以下公式:
B M I C h a n g e 12 M o n t h s ∼ d i e t BMIChange12Months \sim diet BMIChange12Months∼diet
大多数统计软件(包括 R)在模型包含名义变量(例如包含每个人所接受的饮食名称的diet变量)时会自动生成一组虚拟变量。以下是拟合到我们数据的这个模型的结果:
##
## Call:
## lm(formula = BMIChange12Months ~ diet, data = dietDf)
##
## Residuals:
## Min 1Q Median 3Q Max
## -8.14 -1.37 0.07 1.50 6.33
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.622 0.251 -6.47 3.8e-10 ***
## dietLEARN 0.772 0.352 2.19 0.0292 *
## dietOrnish 0.932 0.356 2.62 0.0092 **
## dietZone 1.050 0.352 2.98 0.0031 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.2 on 307 degrees of freedom
## Multiple R-squared: 0.0338, Adjusted R-squared: 0.0243
## F-statistic: 3.58 on 3 and 307 DF, p-value: 0.0143
请注意,软件自动生成了对应于四种饮食中三种的虚拟变量,使得阿特金斯饮食没有虚拟变量。这意味着截距代表了阿特金斯饮食组的均值,其他三个变量则模拟了这些饮食的均值与阿特金斯饮食均值之间的差异。阿特金斯饮食被选择为未建模的基线变量,仅仅是因为它在字母顺序中排在第一位。
17.1.6 6. 批评模型以确保其适当
我们首先要做的是批评模型,确保它是适当的。我们可以做的一件事是查看模型的残差。在图 17.2 中,我们按饮食对每个个体的残差进行了绘制。在不同条件下残差的分布没有明显的差异,我们可以继续进行分析。
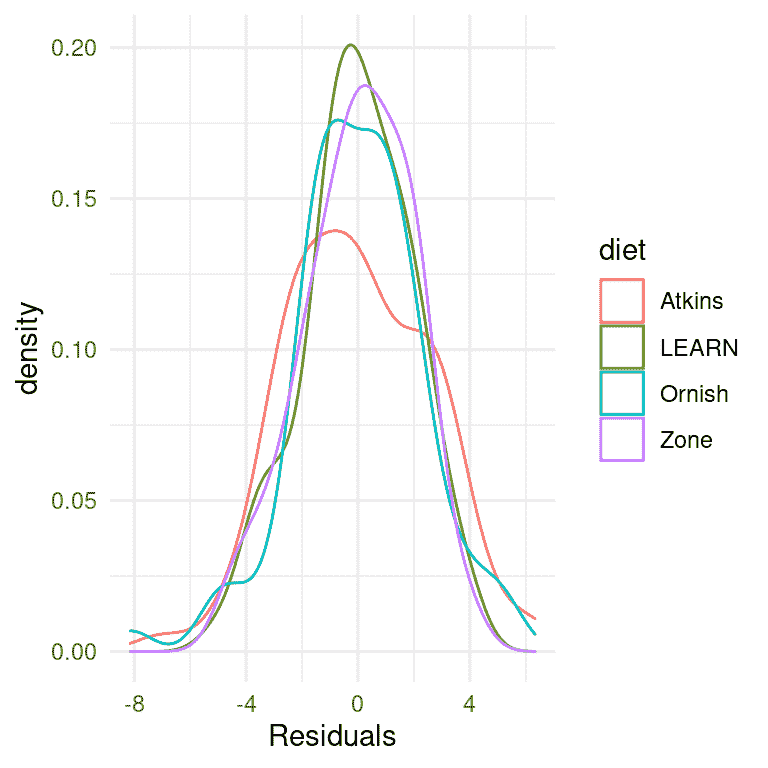
图 17.2: 每个条件下残差的分布
我们应用于线性模型的统计检验的另一个重要假设是模型的残差呈正态分布。人们普遍错误地认为线性模型要求数据呈正态分布,但事实并非如此;正确的统计要求只是残差误差呈正态分布。图 17.3 的右侧显示了一个 Q-Q(分位数-分位数)图,它将残差值根据正态分布中的分位数与其期望值进行了对比。如果残差呈正态分布,那么数据点应该沿着虚线分布 — 在这种情况下看起来相当不错,除了在底部明显的一些离群值。由于这个模型对正态性的违反也相对健壮,并且这些违反相当小,我们将继续使用这些结果。
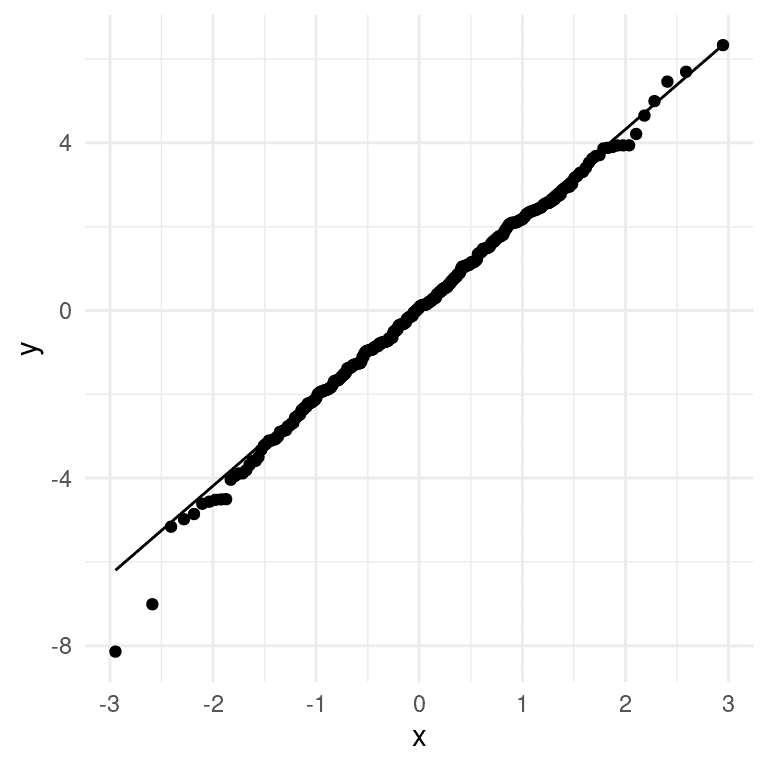
图 17.3: 实际残差值与理论残差值的 Q-Q 图
17.1.7 7. 测试假设并量化效应大小
首先让我们回顾一下上面第 5 步中 ANOVA 的结果摘要。显著的 F 检验告诉我们饮食之间存在显著差异,但我们还应该注意到模型实际上并没有解释数据的很多变异;R 平方值只有 0.03,表明模型只解释了体重减轻变异的几个百分点。因此,我们不希望过分解释这个结果。
在整体 F 检验中的显著结果也没有告诉我们哪些饮食与其他饮食有差异。我们可以通过比较不同条件下的均值来了解更多信息。因为我们进行了几次比较,所以需要对这些比较进行校正,这是通过一种称为 Tukey 方法的程序来实现的,该方法由我们的统计软件实现:
## diet emmean SE df lower.CL upper.CL .group
## Atkins -1.62 0.251 307 -2.11 -1.13 a
## LEARN -0.85 0.247 307 -1.34 -0.36 ab
## Ornish -0.69 0.252 307 -1.19 -0.19 b
## Zone -0.57 0.247 307 -1.06 -0.08 b
##
## Confidence level used: 0.95
## P value adjustment: tukey method for comparing a family of 4 estimates
## significance level used: alpha = 0.05
## NOTE: Compact letter displays can be misleading
## because they show NON-findings rather than findings.
## Consider using 'pairs()', 'pwpp()', or 'pwpm()' instead.
右侧列中的字母告诉我们哪些组彼此不同,使用一种调整进行比较的方法;共享一个字母的条件彼此之间没有显著差异。这表明 Atkins 和 LEARN 饮食彼此没有差异(因为它们共享字母 a),LEARN、Ornish 和 Zone 饮食彼此没有差异(因为它们共享字母 b),但 Atkins 饮食与 Ornish 和 Zone 饮食有差异(因为它们没有共享字母)。
17.1.8 可能的混杂因素是什么?
如果我们更仔细地查看 Gardner 的论文,我们会发现他们还报告了每组中被诊断为代谢综合征的个体数量的统计数据,代谢综合征的特征是高血压、高血糖、腰部多余脂肪和异常的胆固醇水平,与心血管问题的风险增加有关。Gardner 的数据在表 17.1 中呈现。
表 17.1:AtoZ 研究中每个组中代谢综合征的存在。
| 饮食 | N | P(代谢综合征) |
|---|---|---|
| Atkins | 77 | 0.29 |
| LEARN | 79 | 0.25 |
| Ornish | 76 | 0.38 |
| Zone | 79 | 0.34 |
从数据来看,各组之间的比例略有不同,Ornish 和 Zone 饮食中代谢综合征病例更多,而这两种饮食的结果也较差。假设我们有兴趣测试代谢综合征的发病率在各组之间是否存在显著差异,因为这可能使我们担心这些差异可能影响了饮食结果。
17.1.8.1 确定适当的模型
-
什么样的因变量?
-
比例
-
我们在比较什么?
-
四种饮食组中代谢综合征的比例
-
对拟合优度的卡方检验适用于没有差异的零假设
让我们首先使用统计软件中的卡方检验函数计算该统计量:
##
## Pearson's Chi-squared test
##
## data: contTable
## X-squared = 4, df = 3, p-value = 0.3
这个检验表明均值之间没有显著差异。然而,它并没有告诉我们有多大把握确定没有差异;请记住,在 NHST 下,我们总是假设零假设成立,除非数据给出足够的证据使我们拒绝零假设。
如果我们想要量化支持或反对零假设的证据怎么办?我们可以使用贝叶斯因子来做到这一点。
## Bayes factor analysis
## --------------
## [1] Non-indep. (a=1) : 0.058 ±0%
##
## Against denominator:
## Null, independence, a = 1
## ---
## Bayes factor type: BFcontingencyTable, independent multinomial
这告诉我们,备择假设比零假设更可能 0.058 倍,这意味着在这些数据给出的情况下,零假设比备择假设更可能 1/0.058 ~ 17 倍。这是相当强大的,即使不是完全压倒性的,支持零假设的证据。
17.2 寻求帮助
在分析真实数据时,最好与经过训练的统计学家核对分析计划,因为真实数据可能会出现许多潜在问题。事实上,最好在项目开始之前就与统计学家交谈,因为他们关于研究设计或实施方面的建议可能会在未来避免给你带来重大麻烦。大多数大学都设有统计咨询办公室,为大学社区成员提供免费帮助。理解本书的内容并不会阻止你在某个时候需要他们的帮助,但它将帮助你与他们进行更加明智的对话,并更好地理解他们提供的建议。
参考资料
Gardner, Christopher D, Alexandre Kiazand, Sofiya Alhassan, Soowon Kim, Randall S Stafford, Raymond R Balise, Helena C Kraemer, and Abby C King. 2007. “Comparison of the Atkins, Zone, Ornish, and LEARN Diets for Change in Weight and Related Risk Factors Among Overweight Premenopausal Women: The a TO z Weight Loss Study: A Randomized Trial.” JAMA 297 (9): 969–77. https://doi.org/10.1001/jama.297.9.969.
第十八章:进行可重复研究
原文:
statsthinking21.github.io/statsthinking21-core-site/doing-reproducible-research.html译者:飞龙
大多数人认为科学是回答世界问题的可靠方法。当我们的医生开处方时,我们相信它已经通过研究证明是有效的,我们也同样相信我们乘坐的飞机不会从天上掉下来。然而,自 2005 年以来,人们越来越担心科学可能并不总是像我们长期以来认为的那样有效。在本章中,我们将讨论关于科学研究可重复性的这些担忧,并概述可以采取的步骤,以确保我们的统计结果尽可能具有可重复性。
18.1 我们认为科学应该如何工作
假设我们对一个关于儿童选择吃什么的研究项目感兴趣。这是著名饮食研究员布莱恩·万辛克及其同事在 2012 年的一项研究中提出的问题。标准(并且,正如我们将看到的,有些天真)观点大致如下:
-
你从一个假设开始
-
使用受欢迎角色的品牌可能会导致孩子更频繁地选择“健康”的食物
-
你收集一些数据
-
给孩子提供选择,要么是带有 Elmo 品牌贴纸的饼干和苹果,要么是带有控制贴纸的饼干和苹果,并记录他们的选择
-
你做统计来检验零假设
-
预先计划的比较显示,带有 Elmo 品牌的苹果与饼干相比,儿童选择苹果的比例从 20.7%增加到 33.8%( χ 2 \chi^2 χ2=5.158; P=.02)(Wansink, Just, and Payne 2012)
-
你根据数据得出结论
-
“这项研究表明,品牌或有吸引力的品牌角色的使用可能对更健康的食物产生更多好处,而不是对放纵、更加加工的食物产生好处。正如已经证明有吸引力的名称可以增加学校午餐室中更健康食物的选择一样,品牌和卡通角色也可以在年幼儿童中产生同样的效果。”(Wansink, Just, and Payne 2012)
18.2 科学(有时)实际上是如何工作的
布莱恩·万辛克以他的《无意识进食》一书而闻名,他的企业演讲费曾一度高达数万美元。2017 年,一组研究人员开始审查他发表的一些研究,首先是一组关于人们在自助餐厅吃了多少比萨的论文。研究人员要求万辛克分享研究数据,但他拒绝了,所以他们深入研究了他发表的论文,并在论文中发现了大量的不一致和统计问题。围绕这一分析的公开报道引起了其他许多人对万辛克过去的关注,包括获取万辛克和他的合作者之间的电子邮件。正如 Buzzfeed 的 Stephanie Lee 报道的那样,这些电子邮件显示了万辛克的实际研究实践与天真模型有多么不同:
……回到 2008 年 9 月,当 Payne 在数据收集后不久查看数据时,他并没有发现明显的苹果和艾尔莫之间的联系——至少目前还没有。……“我在这封邮件中附上了儿童研究的一些初步结果,供您的报告使用,”Payne 写道。 “不要绝望。看起来水果上的贴纸可能有效(需要更多的魔法)。 ”……Wansink 在准备提交论文时也承认了论文的薄弱之处。P 值为 0.06,刚好低于 0.05 的黄金标准。正如他在 2012 年 1 月 7 日的一封电子邮件中所说的那样,这是一个“瓶颈”。……“在我看来,它应该更低,”他在附上一份草案的时候写道。“你想看看它,看看你的想法。如果你能得到数据,并且需要一些调整,那么将这个值降低到 0.05 以下将是很好的。”……2012 年晚些时候,这项研究发表在著名的《JAMA 儿科学》,0.06 的 P 值保持不变。但在 2017 年 9 月,它被撤回,并以一个列出 P 值为 0.02 的版本取而代之。一个月后,它因为完全不同的原因再次被撤回:Wansink 承认实验并不是在 8 至 11 岁的孩子身上进行的,正如他最初所声称的那样,而是在学龄前儿童身上进行的。
这种行为最终让 Wansink 受到了惩罚;他的 15 项研究被撤回,并且在 2018 年,他辞去了康奈尔大学的教职。
18.3 科学中的可重复性危机
虽然我们认为 Wansink 案中出现的欺诈行为相对罕见,但越来越清楚的是,科学中的可重复性问题比以前想象的要普遍得多。这在 2015 年变得特别明显,当时一大群研究人员在《科学》杂志上发表了一篇题为“估计心理科学可重复性”的研究(Open Science Collaboration 2015)。在这篇论文中,研究人员选取了 100 篇心理学领域的已发表研究,并试图重现这些论文中最初报告的结果。他们的发现令人震惊:原始论文中有 97%报告了统计显著的发现,但在复制研究中,只有 37%的效应在统计上是显著的。尽管心理学中存在这些问题已经引起了很多关注,但似乎几乎每个科学领域都存在这些问题,从癌症生物学(Errington et al. 2014)和化学(Baker 2017)到经济学(Christensen and Miguel 2016)和社会科学(Camerer et al. 2018)。
2010 年后出现的可重复性危机实际上是由斯坦福大学的医生约翰·约阿尼迪斯预测的,他在 2005 年写了一篇名为“为什么大多数发表的研究结果是错误的”(Ioannidis 2005)的论文。在这篇文章中,约阿尼迪斯认为,在现代科学背景下使用零假设统计检验必然会导致高水平的错误结果。
18.3.1 阳性预测值和统计显著性
Ioannidis 的分析集中在一个称为“阳性预测值”的概念上,它被定义为阳性结果(通常翻译为“统计显著的发现”)中真实的比例:
P P V = p ( t r u e p o s i t i v e r e s u l t ) p ( t r u e p o s i t i v e r e s u l t ) + p ( f a l s e p o s i t i v e r e s u l t ) PPV = \frac{p(true\ positive\ result)}{p(true\ positive\ result) + p(false\ positive\ result)} PPV=p(true positive result)+p(false positive result)p(true positive result)
假设我们知道假设为真的概率 ( p ( h I s T r u e ) p(hIsTrue) p(hIsTrue)),那么真正阳性结果的概率就是 p ( h I s T r u e ) p(hIsTrue) p(hIsTrue) 乘以研究的统计功效。
p ( t r u e p o s i t i v e r e s u l t ) = p ( h I s T r u e ) ∗ ( 1 − β ) p(true\ positive\ result) = p(hIsTrue) * (1 - \beta) p(true positive result)=p(hIsTrue)∗(1−β)
其中 β \beta β 是假阴性率。假阳性结果的概率由 p ( h I s T r u e ) p(hIsTrue) p(hIsTrue) 和假阳性率 α \alpha α 决定:
p ( f a l s e p o s i t i v e r e s u l t ) = ( 1 − p ( h I s T r u e ) ) ∗ α p(false\ positive\ result) = (1 - p(hIsTrue)) * \alpha p(false positive result)=(1−p(hIsTrue))∗α
PPV 的定义如下:
P P V = p ( h I s T r u e ) ∗ ( 1 − β ) p ( h I s T r u e ) ∗ ( 1 − β ) + ( 1 − p ( h I s T r u e ) ) ∗ α PPV = \frac{p(hIsTrue) * (1 - \beta)}{p(hIsTrue) * (1 - \beta) + (1 - p(hIsTrue)) * \alpha} PPV=p(hIsTrue)∗(1−β)+(1−p(hIsTrue))∗αp(hIsTrue)∗(1−β)
让我们首先举一个概率假设为真的概率很高的例子,比如说 0.8 - 尽管一般来说我们实际上无法知道这个概率。假设我们进行了一项研究,使用标准值 α = 0.05 \alpha=0.05 α=0.05和 β = 0.2 \beta=0.2 β=0.2。我们可以计算 PPV 如下:
P P V = 0.8 ∗ ( 1 − 0.2 ) 0.8 ∗ ( 1 − 0.2 ) + ( 1 − 0.8 ) ∗ 0.05 = 0.98 PPV = \frac{0.8 * (1 - 0.2)}{0.8 * (1 - 0.2) + (1 - 0.8) * 0.05} = 0.98 PPV=0.8∗(1−0.2)+(1−0.8)∗0.050.8∗(1−0.2)=0.98
这意味着如果我们在假设可能为真且功效高的研究中发现了积极的结果,那么它的真实性很高。然而,请注意,假设一个研究领域的假设有如此高的真实可能性可能并不是一个非常有趣的研究领域;当研究告诉我们一些意外的事情时,研究是最重要的!
让我们对 p ( h I s T r u e ) = 0.1 p(hIsTrue)=0.1 p(hIsTrue)=0.1的领域进行相同的分析 - 也就是说,大多数被测试的假设都是错误的。在这种情况下,PPV 是:
P P V = 0.1 ∗ ( 1 − 0.2 ) 0.1 ∗ ( 1 − 0.2 ) + ( 1 − 0.1 ) ∗ 0.05 = 0.307 PPV = \frac{0.1 * (1 - 0.2)}{0.1 * (1 - 0.2) + (1 - 0.1) * 0.05} = 0.307 PPV=0.1∗(1−0.2)+(1−0.1)∗0.050.1∗(1−0.2)=0.307
这意味着在一个大部分假设可能是错误的领域(也就是说,一个有趣的科学领域,研究人员正在测试冒险的假设),即使我们发现了积极的结果,它更可能是假的而不是真的!事实上,这只是我们在假设检验的背景下讨论的基本率效应的另一个例子 - 当结果不太可能时,几乎可以肯定大多数积极的结果都是假阳性。
我们可以模拟这一点,展示 PPV 如何与统计功效和假设真实的先验概率相关(见图 18.1)。
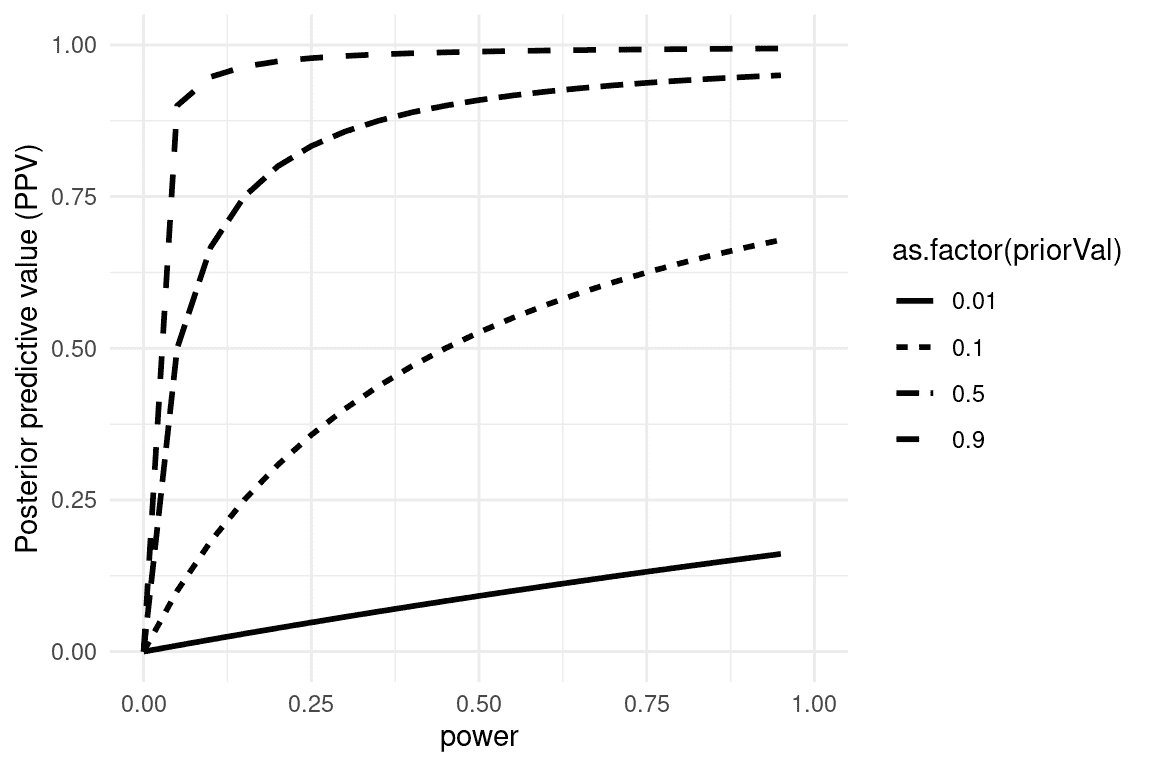
图 18.1:后验预测值的模拟,作为统计功效的函数(绘制在 x 轴上),以及假设真实的先验概率(作为单独的线绘制)。
不幸的是,在许多科学领域,统计功效仍然很低(Smaldino and McElreath 2016),这表明许多发表的研究结果是错误的。
一个有趣的例子是乔纳森·肖恩菲尔德和约翰·约阿尼迪斯的一篇论文,题为“我们吃的一切都与癌症有关吗?系统的食谱评论”(Schoenfeld and Ioannidis 2013)。他们检查了大量评估不同食物与癌症风险关系的论文,发现 80%的成分与增加或减少癌症风险有关。在大多数情况下,统计证据很弱,当结果在研究中结合时,结果为零。
18.3.2 胜者诅咒
当统计功效低时,还会发生另一种错误:我们对效应大小的估计会被夸大。这种现象通常被称为“胜者诅咒”,这个术语来自经济学,在那里它指的是对于某些类型的拍卖(其中价值对每个人都是相同的,比如一罐季度,出价是私人的),获胜者保证要支付比商品价值更多的钱。在科学上,胜者诅咒指的是从显著结果(即获胜者)中估计的效应大小几乎总是真实效应大小的夸大。
我们可以模拟这个,以查看显著结果的估计效应大小与实际基础效应大小的关系。让我们生成一个真实效应大小为 d = 0.2 的数据,并估计检测到显著效应的结果的效应大小。图 18.2 的左面板显示,当功效低时,显著结果的估计效应大小可能与实际效应大小相比高度膨胀。
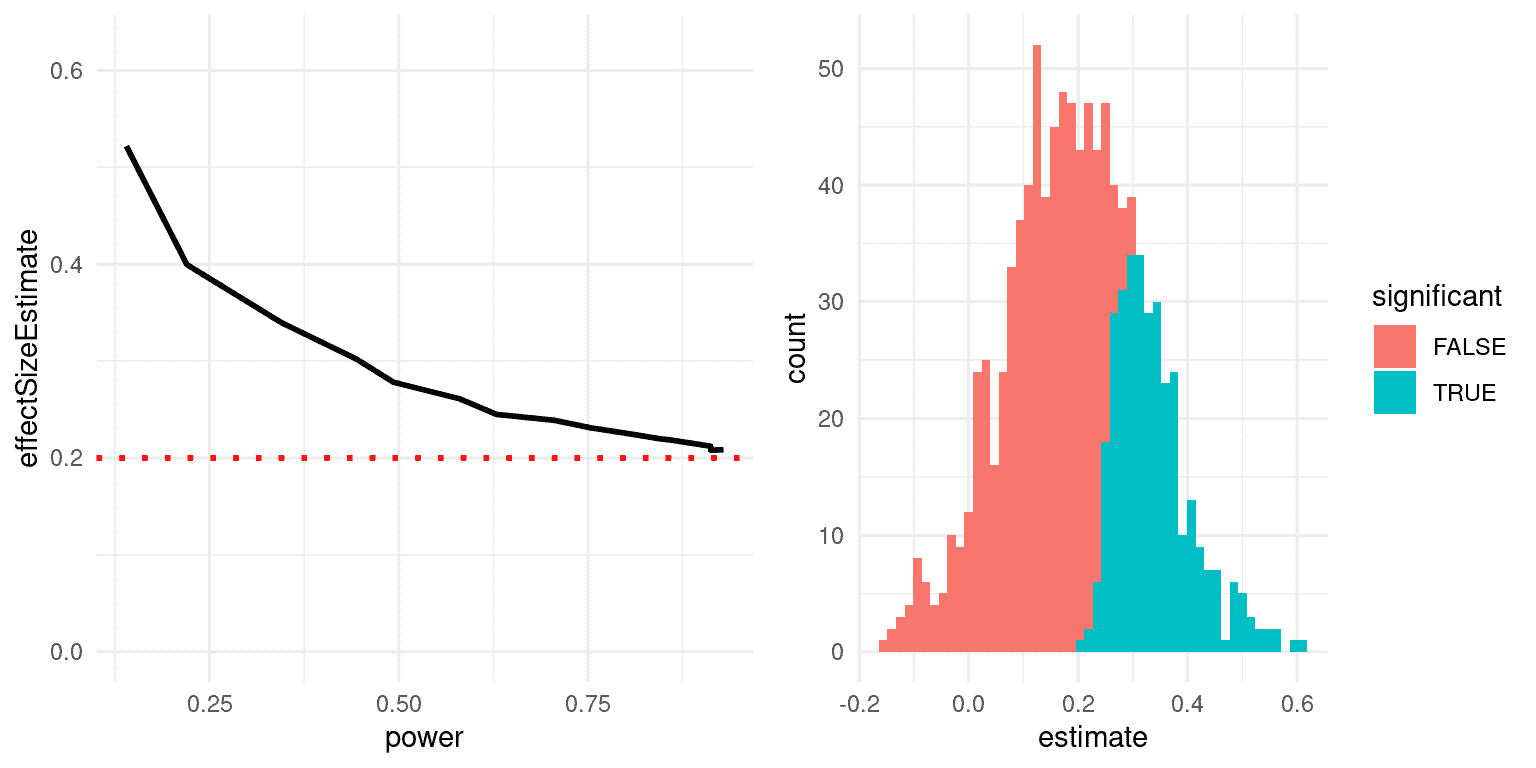
图 18.2:左:赢家诅咒的模拟,作为统计功效的函数(x 轴)。实线显示估计的效应大小,虚线显示实际效应大小。右:直方图显示了来自数据集的多个样本的效应大小估计,显著结果显示为蓝色,非显著结果显示为红色。
我们可以看一个单独的模拟来看为什么会出现这种情况。在图 18.2 的右面板中,您可以看到 1000 个样本的估计效应大小的直方图,根据检验是否具有统计显著性进行分隔。从图中应该清楚,如果我们仅基于显著结果来估计效应大小,那么我们的估计将会被夸大;只有当大多数结果是显著的(即功效高且效应相对较大)时,我们的估计才会接近实际效应大小。
18.4 可疑的研究行为
美国心理学协会出版的一本名为《The Compleat Academic: A Career Guide》的畅销书(Darley, Zanna, and Roediger 2004)旨在为有抱负的研究人员提供如何建立职业生涯的指导。社会心理学家达里尔·贝姆在一章中提到了“撰写实证期刊文章”,他提供了一些建议关于如何写一篇研究论文。不幸的是,他提出的做法存在严重问题,已经被称为可疑的研究行为(QRPs)。
你应该写哪篇文章?有两篇可能的文章可以写:(1)你在设计研究时计划写的文章,或者(2)你已经看到结果后现在最有意义的文章。它们很少相同,正确答案是(2)。
Bem 在这里建议的是HARKing(在结果已知后进行假设)(Kerr 1998)。这可能看起来无害,但是有问题,因为它允许研究人员重新构建事后结论(我们应该持保留态度)作为先验预测(我们会更有信心)。实质上,它允许研究人员根据事实重写他们的理论,而不是使用理论进行预测,然后进行测试——类似于移动球门,使其最终停在任何地方。因此,非常难以证伪不正确的想法,因为球门总是可以移动以匹配数据。Bem 继续说道:
分析数据 从各个角度检查它们。分别分析性别。制作新的综合指数。如果一个数据表明一个新的假设,试着在数据的其他地方找到进一步的证据。如果你看到有趣模式的微弱痕迹,试着重新组织数据以使它们更加醒目。如果有你不喜欢的参与者,或者试验、观察者或采访者给你异常结果,暂时放弃它们。进行一次钓鱼远征,寻找一些有趣的东西。不,这不是不道德的。
Bem 在这里提出的是p-hacking,这意味着尝试许多不同的分析,直到找到一个显着的结果。 Bem 正确地指出,如果报告数据上进行的每一项分析,那么这种方法就不会“不道德”。然而,很少看到一篇论文讨论对数据集执行的所有分析; 相反,论文通常只呈现有效的分析 - 这通常意味着他们找到了统计上显着的结果。有许多不同的方法可以进行 p-hack:
-
在每个受试者之后分析数据,并在 p <.05 时停止收集数据
-
分析许多不同的变量,但只报告那些 p <.05 的变量
-
收集许多不同的实验条件,但只报告那些 p <.05 的条件
-
排除参与者以获得 p <.05
-
转换数据以获得 p <.05
Simmons,Nelson 和 Simonsohn(2011)发表的一篇著名论文表明,使用这些 p-hacking 策略可以大大增加实际的假阳性率,导致大量的假阳性结果。
18.4.1 ESP 或 QRP?
2011 年,同样是 Daryl Bem 发表了一篇文章(Bem 2011),声称已经找到了超感知的科学证据。文章中指出:
本文报告了 9 个实验,涉及 1000 多名参与者,测试了通过“时间逆转”已经建立的心理效应来测试超前影响。 …所有 9 个实验中的超感知表现的平均效应大小(d)为 0.22,除一个实验外,所有实验都产生了统计上显着的结果。
当研究人员开始检查 Bem 的文章时,很明显他已经参与了上面讨论的所有 QRPs。正如 Tal Yarkoni 在一篇审查该文章的博客文章中指出的那样:
-
样本大小在研究中有所不同
-
不同的研究似乎已经被合并在一起或分开
-
这些研究允许许多不同的假设,目前尚不清楚事先计划了哪些假设
-
Bem 在没有明确有方向性预测的情况下使用单尾检验(因此α实际上为 0.1)
-
大多数 p 值非常接近 0.05
-
目前尚不清楚有多少其他研究进行了但没有报告
18.5 进行可重复研究
自可重复性危机爆发以来,已经出现了一个强大的运动,旨在开发工具,以帮助保护科学研究的可重复性。
18.5.1 预注册
最受欢迎的想法之一是预注册,其中将研究的详细描述(包括所有数据分析)提交给受信任的存储库(例如Open Science Framework或AsPredicted.org)。通过在分析数据之前详细说明计划,预注册提供了更大的信心,使分析不会受到 p-hacking 或其他可疑的研究实践的影响。
在医学临床试验中,预先注册的影响是显著的。2000 年,国家心脏,肺部和血液研究所(NHLBI)开始要求所有临床试验在临床试验.gov上进行预先注册。这提供了一个自然实验来观察研究预先注册的影响。当 Kaplan 和 Irvin(2015)在一段时间内检查临床试验结果时,他们发现 2000 年之后临床试验的积极结果数量大大减少,与之前相比。虽然有许多可能的原因,但似乎在研究注册之前,研究人员能够改变他们的方法或假设以找到积极的结果,而在注册后这变得更加困难。
18.5.2 可重复的实践
Simmons, Nelson 和 Simonsohn(2011)提出了一套建议的实践,使研究更具可重复性,所有这些实践都应该成为研究人员的标准:
作者必须在数据收集开始之前决定终止数据收集的规则,并在文章中报告这个规则。
作者必须每个单元收集至少 20 个观察结果,否则必须提供令人信服的数据收集成本的理由。
作者必须列出研究中收集的所有变量。
作者必须报告所有实验条件,包括失败的操作。
如果观察结果被排除,作者必须报告如果包括这些观察结果,统计结果是什么。
如果分析包括一个协变量,作者必须报告没有协变量的分析的统计结果。
18.5.3 复制
科学的一个标志是复制的概念-也就是说,其他研究人员应该能够进行相同的研究并获得相同的结果。不幸的是,正如我们在之前讨论的复制项目的结果中看到的那样,许多发现是不可复制的。确保研究的可复制性的最佳方法是首先在自己身上复制它;对于一些研究来说,这可能是不可能的,但每当可能时,应确保自己的发现在新样本中成立。新样本应具有足够的功效来发现感兴趣的效应大小;在许多情况下,这实际上将需要比原始样本更大的样本。
在复制方面,有几件事情很重要。首先,复制尝试失败并不一定意味着原始发现是错误的;请记住,以 80%的功效水平,即使存在真实效应,结果仍有五分之一的机会是不显著的。因此,我们通常希望在决定是否相信某个重要发现之前看到多次复制。不幸的是,包括心理学在内的许多领域过去未能遵循这一建议,导致“教科书”上的发现最终被证明是错误的。关于 Daryl Bem 对超感知的研究,一个包括 7 个研究的大型复制尝试未能复制他的发现(Galak 等人,2012)。
其次,要记住 p 值并不能提供给我们一个发现复制的可能性的度量。正如我们之前讨论过的,p 值是关于特定零假设下数据的可能性的陈述;它并不能告诉我们关于发现实际上是真实的概率(正如我们在贝叶斯分析的章节中学到的)。为了知道复制的可能性,我们需要知道发现是真实的概率,而这通常是我们不知道的。
18.6 进行可重复的数据分析
到目前为止,我们已经专注于在新实验中复制其他研究人员的发现的能力,但可再现性的另一个重要方面是能够在其自己的数据上重现某人的分析,我们称之为计算可再现性。这要求研究人员分享他们的数据和分析代码,以便其他研究人员既可以尝试重现结果,也可以在相同数据上测试不同的分析方法。心理学领域越来越倾向于公开分享代码和数据;例如,《心理科学》杂志现在为分享研究材料、数据和代码以及预注册的论文提供“徽章”。
能够重现分析是我们强烈主张使用脚本分析(如使用 R 语言)而不是使用“点与点击”软件包的原因之一。这也是我们主张使用免费开源软件(如 R)而不是商业软件包的原因,后者需要其他人购买软件才能重现任何分析。
有许多分享代码和数据的方式。分享代码的常见方式是通过支持软件版本控制的网站,例如Github。小型数据集也可以通过这些网站分享;较大的数据集可以通过数据共享门户网站(如Zenodo)或专门用于特定类型数据的门户网站(如OpenNeuro)进行分享。
18.7 结论:做更好的科学
每个科学家都有责任改进他们的研究实践,以增加其研究的可再现性。必须记住,研究的目标不是找到显著结果,而是以最真实的方式提出和回答关于自然的问题。我们的大部分假设都会是错误的,我们应该对此感到舒适,这样当我们找到一个正确的假设时,我们会更加对其真实性有信心。
18.8 学习目标
-
描述 P-值操纵的概念及其对科学实践的影响
-
描述阳性预测值的概念及其与统计功效的关系
-
描述预注册的概念以及它如何帮助防止可疑的研究实践
18.9 建议阅读
-
改善您的统计推断 - 一门关于如何进行更好的统计分析的在线课程,包括本章提出的许多要点。
参考资料
Baker, Monya. 2017. “Reproducibility: Check Your Chemistry.” Nature 548 (7668): 485–88. https://doi.org/10.1038/548485a.
Bem, Daryl J. 2011. “Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect.” J Pers Soc Psychol 100 (3): 407–25. https://doi.org/10.1037/a0021524.
Camerer, Colin F., Anna Dreber, Felix Holzmeister, Teck-Hua Ho, Jürgen Huber, Magnus Johannesson, Michael Kirchler, et al. 2018. “Evaluating the Replicability of Social Science Experiments in Nature and Science Between 2010 and 2015.” Nature Human Behaviour 2: 637–44.
Christensen, Garret S, and Edward Miguel. 2016. “Transparency, Reproducibility, and the Credibility of Economics Research.” Working Paper 22989. Working Paper Series. National Bureau of Economic Research. https://doi.org/10.3386/w22989.
Darley, John M, Mark P Zanna, and Henry L Roediger. 2004. The Compleat Academic: A Career Guide. 2nd ed. Washington, DC: American Psychological Association. http://www.loc.gov/catdir/toc/fy037/2003041830.html.
Errington, Timothy M, Elizabeth Iorns, William Gunn, Fraser Elisabeth Tan, Joelle Lomax, and Brian A Nosek. 2014. “An Open Investigation of the Reproducibility of Cancer Biology Research.” Elife 3 (December). https://doi.org/10.7554/eLife.04333.
Galak, Jeff, Robyn A LeBoeuf, Leif D Nelson, and Joseph P Simmons. 2012. “Correcting the Past: Failures to Replicate Psi.” J Pers Soc Psychol 103 (6): 933–48. https://doi.org/10.1037/a0029709.
Ioannidis, John P A. 2005. “Why Most Published Research Findings Are False.” PLoS Med 2 (8): e124. https://doi.org/10.1371/journal.pmed.0020124.
Kaplan, Robert M, and Veronica L Irvin. 2015. “Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time.” PLoS One 10 (8): e0132382. https://doi.org/10.1371/journal.pone.0132382.
Kerr, N L. 1998. “HARKing: Hypothesizing After the Results Are Known.” Pers Soc Psychol Rev 2 (3): 196–217. https://doi.org/10.1207/s15327957pspr0203_4.
Open Science Collaboration. 2015. “PSYCHOLOGY. Estimating the Reproducibility of Psychological Science.” Science 349 (6251): aac4716. https://doi.org/10.1126/science.aac4716.
Schoenfeld, Jonathan D, and John P A Ioannidis. 2013. “Is Everything We Eat Associated with Cancer? A Systematic Cookbook Review.” Am J Clin Nutr 97 (1): 127–34. https://doi.org/10.3945/ajcn.112.047142.
Simmons, Joseph P, Leif D Nelson, and Uri Simonsohn. 2011. “False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant.” Psychol Sci 22 (11): 1359–66. https://doi.org/10.1177/0956797611417632.
Smaldino, Paul E, and Richard McElreath. 2016. “The Natural Selection of Bad Science.” R Soc Open Sci 3 (9): 160384. https://doi.org/10.1098/rsos.160384.
Wansink, Brian, David R Just, and Collin R Payne. 2012. “Can Branding Improve School Lunches?” Arch Pediatr Adolesc Med 166 (10): 1–2. https://doi.org/10.1001/archpediatrics.2012.999.
参考资料
原文:
statsthinking21.github.io/statsthinking21-core-site/references.html译者:飞龙
Baker, Monya. 2017. “Reproducibility: Check Your Chemistry.” Nature 548 (7668): 485–88. https://doi.org/10.1038/548485a.
Bem, Daryl J. 2011. “Feeling the Future: Experimental Evidence for Anomalous Retroactive Influences on Cognition and Affect.” J Pers Soc Psychol 100 (3): 407–25. https://doi.org/10.1037/a0021524.
Breiman, Leo. 2001. “Statistical Modeling: The Two Cultures (with Comments and a Rejoinder by the Author).” Statist. Sci. 16 (3): 199–231. https://doi.org/10.1214/ss/1009213726.
Camerer, Colin F., Anna Dreber, Felix Holzmeister, Teck-Hua Ho, Jürgen Huber, Magnus Johannesson, Michael Kirchler, et al. 2018. “Evaluating the Replicability of Social Science Experiments in Nature and Science Between 2010 and 2015.” Nature Human Behaviour 2: 637–44.
Christensen, Garret S, and Edward Miguel. 2016. “Transparency, Reproducibility, and the Credibility of Economics Research.” Working Paper 22989. Working Paper Series. National Bureau of Economic Research. https://doi.org/10.3386/w22989.
Copas, J. B. 1983. “Regression, Prediction and Shrinkage (with Discussion).” Journal of the Royal Statistical Society, Series B: Methodological 45: 311–54.
Darley, John M, Mark P Zanna, and Henry L Roediger. 2004. The Compleat Academic: A Career Guide. 2nd ed. Washington, DC: American Psychological Association. http://www.loc.gov/catdir/toc/fy037/2003041830.html.
Dehghan, Mahshid, Andrew Mente, Xiaohe Zhang, Sumathi Swaminathan, Wei Li, Viswanathan Mohan, Romaina Iqbal, et al. 2017. “Associations of Fats and Carbohydrate Intake with Cardiovascular Disease and Mortality in 18 Countries from Five Continents (PURE): A Prospective Cohort Study.” Lancet 390 (10107): 2050–62. https://doi.org/10.1016/S0140-6736(17)32252-3.
Efron, Bradley. 1998. “R. A. Fisher in the 21st Century (Invited Paper Presented at the 1996 r. A. Fisher Lecture).” Statist. Sci. 13 (2): 95–122. https://doi.org/10.1214/ss/1028905930.
Errington, Timothy M, Elizabeth Iorns, William Gunn, Fraser Elisabeth Tan, Joelle Lomax, and Brian A Nosek. 2014. “An Open Investigation of the Reproducibility of Cancer Biology Research.” Elife 3 (December). https://doi.org/10.7554/eLife.04333.
Fisher, R. A. 1925. Statistical Methods for Research Workers. Edinburgh Oliver & Boyd.
Fisher, Ronald Aylmer. 1956. Statistical Methods and Scientific Inference. New York: Hafner Pub. Co.
Galak, Jeff, Robyn A LeBoeuf, Leif D Nelson, and Joseph P Simmons. 2012. “Correcting the Past: Failures to Replicate Psi.” J Pers Soc Psychol 103 (6): 933–48. https://doi.org/10.1037/a0029709.
Gardner, Christopher D, Alexandre Kiazand, Sofiya Alhassan, Soowon Kim, Randall S Stafford, Raymond R Balise, Helena C Kraemer, and Abby C King. 2007. “Comparison of the Atkins, Zone, Ornish, and LEARN Diets for Change in Weight and Related Risk Factors Among Overweight Premenopausal Women: The a TO z Weight Loss Study: A Randomized Trial.” JAMA 297 (9): 969–77. https://doi.org/10.1001/jama.297.9.969.
Ioannidis, John P A. 2005. “Why Most Published Research Findings Are False.” PLoS Med 2 (8): e124. https://doi.org/10.1371/journal.pmed.0020124.
Kaplan, Robert M, and Veronica L Irvin. 2015. “Likelihood of Null Effects of Large NHLBI Clinical Trials Has Increased over Time.” PLoS One 10 (8): e0132382. https://doi.org/10.1371/journal.pone.0132382.
Kerr, N L. 1998. “HARKing: Hypothesizing After the Results Are Known.” Pers Soc Psychol Rev 2 (3): 196–217. https://doi.org/10.1207/s15327957pspr0203_4.
Neyman, J. 1937. “Outline of a Theory of Statistical Estimation Based on the Classical Theory of Probability.” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences 236 (767): 333–80. https://doi.org/10.1098/rsta.1937.0005.
Neyman, J., and K. Pearson. 1933. “On the Problem of the Most Efficient Tests of Statistical Hypotheses.” Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences 231 (694-706): 289–337. https://doi.org/10.1098/rsta.1933.0009.
Open Science Collaboration. 2015. “PSYCHOLOGY. Estimating the Reproducibility of Psychological Science.” Science 349 (6251): aac4716. https://doi.org/10.1126/science.aac4716.
Pesch, Beate, Benjamin Kendzia, Per Gustavsson, Karl-Heinz Jöckel, Georg Johnen, Hermann Pohlabeln, Ann Olsson, et al. 2012. “Cigarette Smoking and Lung Cancer–Relative Risk Estimates for the Major Histological Types from a Pooled Analysis of Case-Control Studies.” Int J Cancer 131 (5): 1210–19. https://doi.org/10.1002/ijc.27339.
Schenker, Nathaniel, and Jane F. Gentleman. 2001. “On Judging the Significance of Differences by Examining the Overlap Between Confidence Intervals.” The American Statistician 55 (3): 182–86. http://www.jstor.org/stable/2685796.
Schoenfeld, Jonathan D, and John P A Ioannidis. 2013. “Is Everything We Eat Associated with Cancer? A Systematic Cookbook Review.” Am J Clin Nutr 97 (1): 127–34. https://doi.org/10.3945/ajcn.112.047142.
Simmons, Joseph P, Leif D Nelson, and Uri Simonsohn. 2011. “False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant.” Psychol Sci 22 (11): 1359–66. https://doi.org/10.1177/0956797611417632.
Smaldino, Paul E, and Richard McElreath. 2016. “The Natural Selection of Bad Science.” R Soc Open Sci 3 (9): 160384. https://doi.org/10.1098/rsos.160384.
Stigler, Stephen M. 2016. The Seven Pillars of Statistical Wisdom. Harvard University Press.
Sullivan, Gail M, and Richard Feinn. 2012. “Using Effect Size-or Why the p Value Is Not Enough.” J Grad Med Educ 4 (3): 279–82. https://doi.org/10.4300/JGME-D-12-00156.1.
Teicholz, Nina. 2014. The Big Fat Surprise. Simon & Schuster.
Wakefield, A J. 1999. “MMR Vaccination and Autism.” Lancet 354 (9182): 949–50. https://doi.org/10.1016/S0140-6736(05)75696-8.
Wansink, Brian, David R Just, and Collin R Payne. 2012. “Can Branding Improve School Lunches?” Arch Pediatr Adolesc Med 166 (10): 1–2. https://doi.org/10.1001/archpediatrics.2012.999.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 16
16 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)