
开源开放 | 蚂蚁集团联合上海仁济医院泌尿科发布国内首个临床专科推理数据集:RJUA-QA...
OpenKG地址:http://openkg.cn/dataset/rjua-qadatasets开放许可协议:CC BY-SA 4.0 (署名相似共享)贡献者:上海交通大学医学院附属仁济医院(迟辰斐、吕向国、张明、李方舟、马硝惟、薛蔚、黄翼然),蚂蚁数字医疗健康团队(徐晓莉、陈志攀、陈子潇、甄帅)、蚂蚁医疗大模型团队(蔡鸿博、石磊、吕世伟、杨晓燕、赵登、申月、陶东杰、顾进杰、张志强、梁磊)摘要本
OpenKG地址:http://openkg.cn/dataset/rjua-qadatasets
开放许可协议:CC BY-SA 4.0 (署名相似共享)
贡献者:上海交通大学医学院附属仁济医院(迟辰斐、吕向国、张明、李方舟、马硝惟、薛蔚、黄翼然),蚂蚁数字医疗健康团队(徐晓莉、陈志攀、陈子潇、甄帅)、蚂蚁医疗大模型团队(蔡鸿博、石磊、吕世伟、杨晓燕、赵登、申月、陶东杰、顾进杰、张志强、梁磊)
摘要
本文介绍一个基于临床医学泌尿外科知识体系构造的QA推理数据集,由蚂蚁集团医疗大模型团队(AntGroup Medical LLM)与上海交通大学医学院附属仁济医院泌尿科(Department of Urology, Shanghai Jiao Tong University School of Medicine Affiliated Renji Hospital)专家团队合作研发,简称为RJUA-QA Datasets,数据来源于医生参考临床经验中真实患者情况,改写的虚拟患者临床数据,不涉及任何医患隐私数据,经AI模型和专家团队处理校验,构建为问答对(Q-context-A)。本数据集旨在提高大型语言模型在医疗诊断推理方面的能力,并作为在严肃可控场景下应用的评测基准。我们将详细介绍数据集的构建过程、特点及统计分析,并全面评测了行业和通用大模型在该数据集上的性能,后续团队将持续优化数据集,为人工智能在医疗领域的研究与应用提供有力支持。
1、前言
自大型语言模型(LLM)问世以来,其在医疗服务领域的应用持续推动着行业的进步。近年来,随着互联网医疗服务的普及,患者对在线问诊和咨询的需求也呈现出不断上升的趋势。如今,远程医疗服务成为患者寻求便捷、高效医疗支持的首选。在这种背景下,大型语言模型所具备的丰富知识和自然语言交互优势,为智能医疗助手的广泛应用带来了巨大的潜力。
然而,这些模型在实际应用中仍面临诸多挑战,在医疗问诊过程中,复杂的情境要求个人助手具备丰富的医学知识,以便通过多轮对话了解患者需求并给出专业、详尽的解答。然而,通用型语言模型在应对医疗问诊时,常常因为缺乏足够领域知识而导致回避问题或回答不相关;另外,由于大模型的幻觉问题和推理不足,在实际应用上无法保证可控性和正确性。最关键的问题是,当前高质量的中文医学专科数据集相对稀缺,这对训练出色的医疗领域语言模型提出了挑战。
为了克服这些难题,蚂蚁与上海仁济医院泌尿科专家团队联合研发,基于医生团队临床经验改写的虚拟患者诊疗数据,构建了一个医疗泌尿专科问答推理数据集。据我们所知,该数据集是国内首个结合临床经验的医疗专科QA数据集,具有非常重要的科研和应用研究价值。该数据集的目标是提高大型模型在逻辑推理方面的能力,并为实际应用提供评估标准。我们期待这个数据集能为医疗领域的大型模型研究提供有价值的支持。

图1. RJUA-QA Datasets构建流程
2、数据集构建及特点
2.1 数据来源
本数据集来源于仁济泌尿医生团队参考临床经验中真实患者情况,改写的虚拟患者临床数据,不涉及医患隐私。数据集由上海仁济医院泌尿科医生团队参与构建,确保医疗领域专科数据的真实性、精准度和可靠性。
虚拟患者的临床参考数据覆盖2019-2023连续5年的时间跨度,且来源广泛,包括门诊诊疗、急诊抢救、住院手术和操作、以及日常科普等多形式的资源,以考察测试多种临床应用场景(图2)。
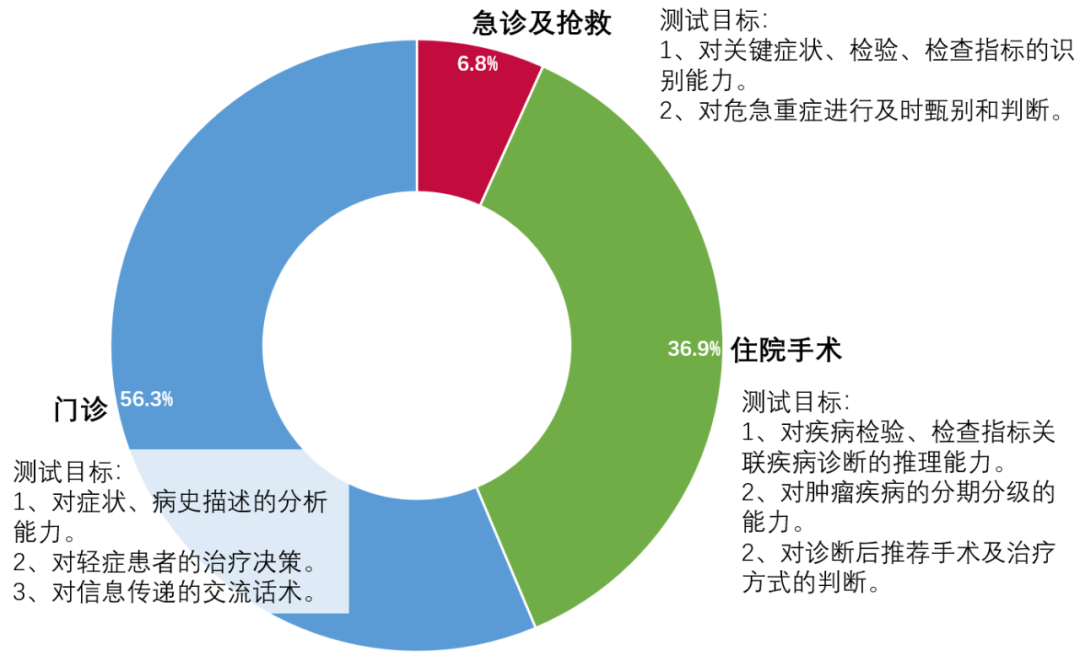
图2 RJUA-QADatasets的数据来源和类型分类及测试目标
本数据集病种涵盖泌尿系肿瘤、泌尿系结石、前列腺增生、男性、尿控、泌尿道整复、小儿泌尿、肾移植等10个亚专业。病种覆盖率占泌尿科就诊患者的97.6%(图3)。
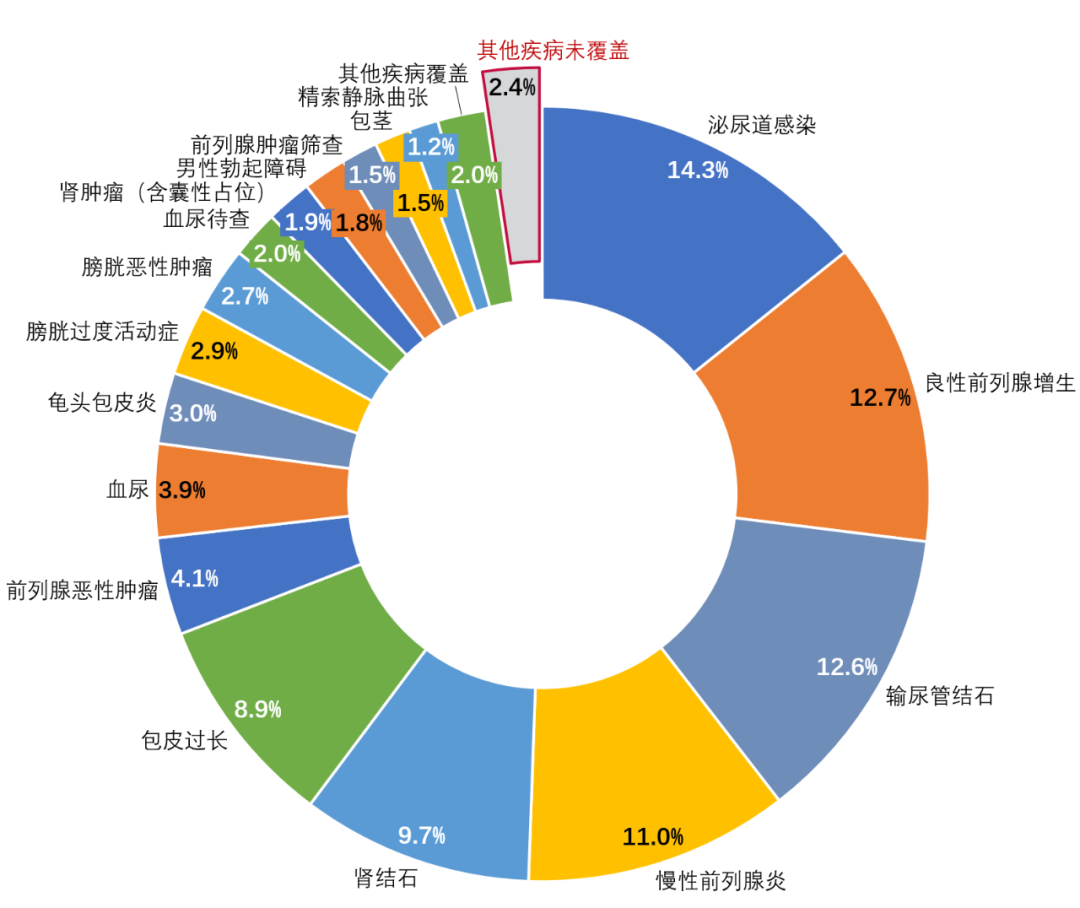
图3 2019-2023上海仁济医院泌尿科相关主诊断占比与RJUA-QADatasets病种覆盖率
2.2 数据集构建过程
1.数据预处理:对虚拟患者临床数据进行清洗、去重、结构化抽取等预处理操作,保证格式化后的数据的高质量和可用性,作为QA问答对构建的输入。
2.大模型构建问答对:对预处理后的数据,利用LLM的结构化抽取能力,构建问答对。由于数据来源的差异性,泌尿外科专家根据临床数据提出了一系列具有挑战性的问答对,涵盖了病因、检验检查、症状、诊断、治疗等多方面。
3.问答对匹配专科文献:针对问答对,匹配专科文献中相关的上下文context,用于后续推理过程的专科参考依据。
4.专家校准:针对每个问答对(Q-context-A),进行三轮人工校准与验收,分别由医学背景标注团队、仁济泌尿专家团队、质检验收专员进行标注,该过程需要校对专科术语正确性、问答合理性、context相关性、context是否为关键证据、答案推理过程、诊断正确性共六大维度。
5.推理评测:将问题、答案和推理过程整理成结构化的数据格式,设计推理评测指标,便于后续LLM推理性能评测、大模型微调样本和专科知识库的研究和应用。
2.3 数据集特点
本数据集具有以下特点:
真实临床背景:虚拟患者的临床参考数据覆盖2019-2023连续5年的时间跨度,且包含门诊诊疗、急诊抢救、住院手术操作,具有很高的现实意义和应用价值。
多样性:问题涵盖了泌尿科的多器官、多亚专科和多疾病,疾病覆盖占比泌尿科就诊患者的95%以上,有助于提升模型应用的泛化能力。
可解释性:提供详细并且权威的专科证据和推理过程,有助于分析模型的推理逻辑,提高可解释性。
精准性和科学性:疾病轻重缓急,诊断逻辑,检查检验和治疗原则符合临床实践,对多病共存患者精准识别最首要的疾病,并给出科学化的建议。
3、数据集概况
3.1 数据来源
本数据集包含2132个QA问答对,并对应约25000余条诊疗依据和临床数据。包含67个泌尿系统常见疾病(见表2),病种覆盖人群超过泌尿科就医人群的97.6%。
综合各疾病的发病率、临床发现和处置的紧迫性,对不同疾病的数量占比进行了调整(图4)。另外模仿真实患者对同一个疾病产生的多样性主观描述,也是本数据集的特色,更加真实的复刻泌尿专科医生的真实诊疗场景。
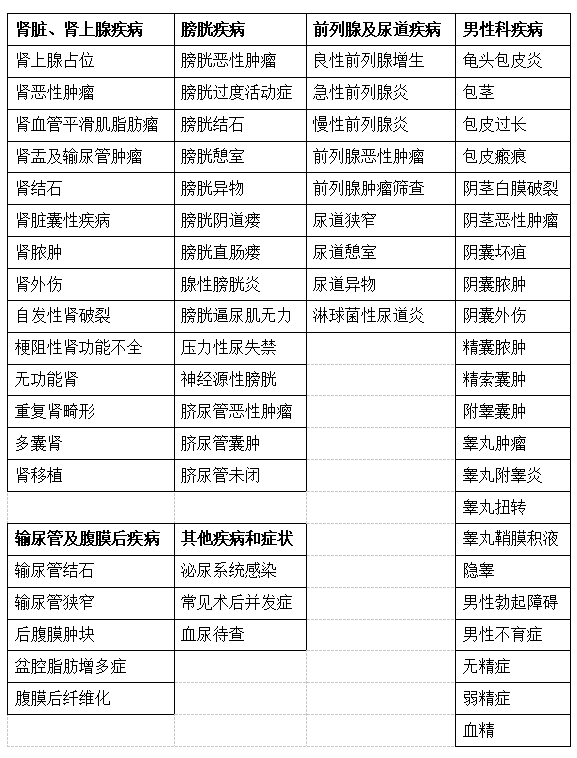
表2 RJUA-QA Datasets疾病清单
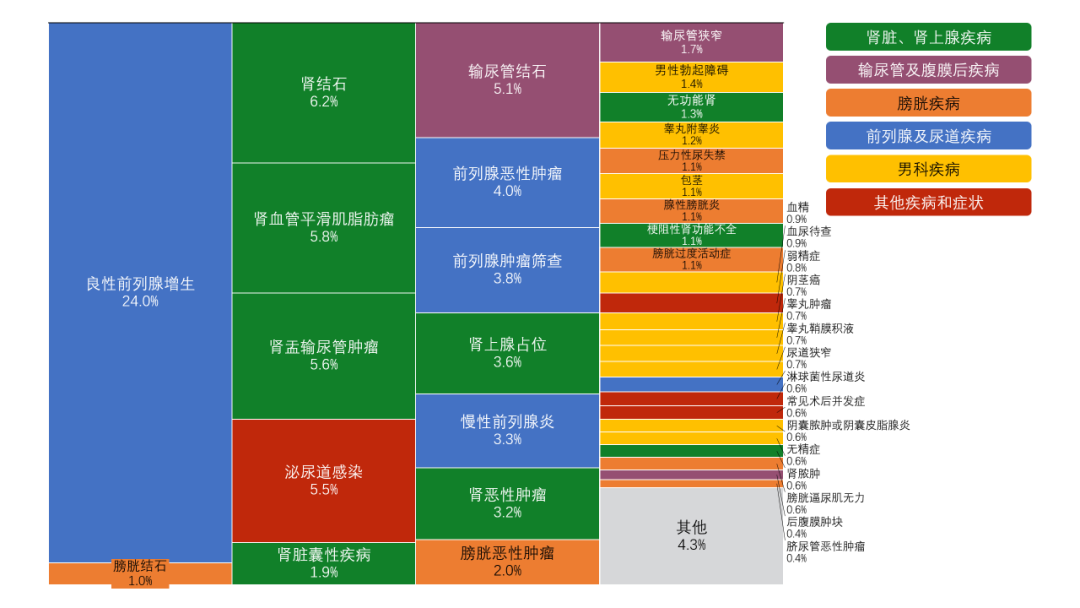
图4 RJUA-QA Datasets各类疾病的占比
由于考虑到真实的临床患者常见多发疾病,包括由于原发疾病导致的并发症,以及合并症,因此本数据集中80%以上的患者存在多诊断的情况,为了适当降低专科判断的难度,大多数非泌尿系统合并症在Question中会直接给出。有24.95%(532/2132)例患者存在泌尿科的双诊断,需要通过Context的推理得到。3.99%(83/2132)例患者存在三个及以上泌尿科的诊断,这些患者往往需要判断的这些疾病主次或者因果关系,并需要给出综合性诊疗意见。(图5)
本数据集同时提供推理参考的context,这些文本来自于《中国泌尿外科和男科疾病诊断治疗指南(2022版)》、泌尿外科主要教材、PubMed可检索的专业文献、以及从业10年以上临床医生的经验。
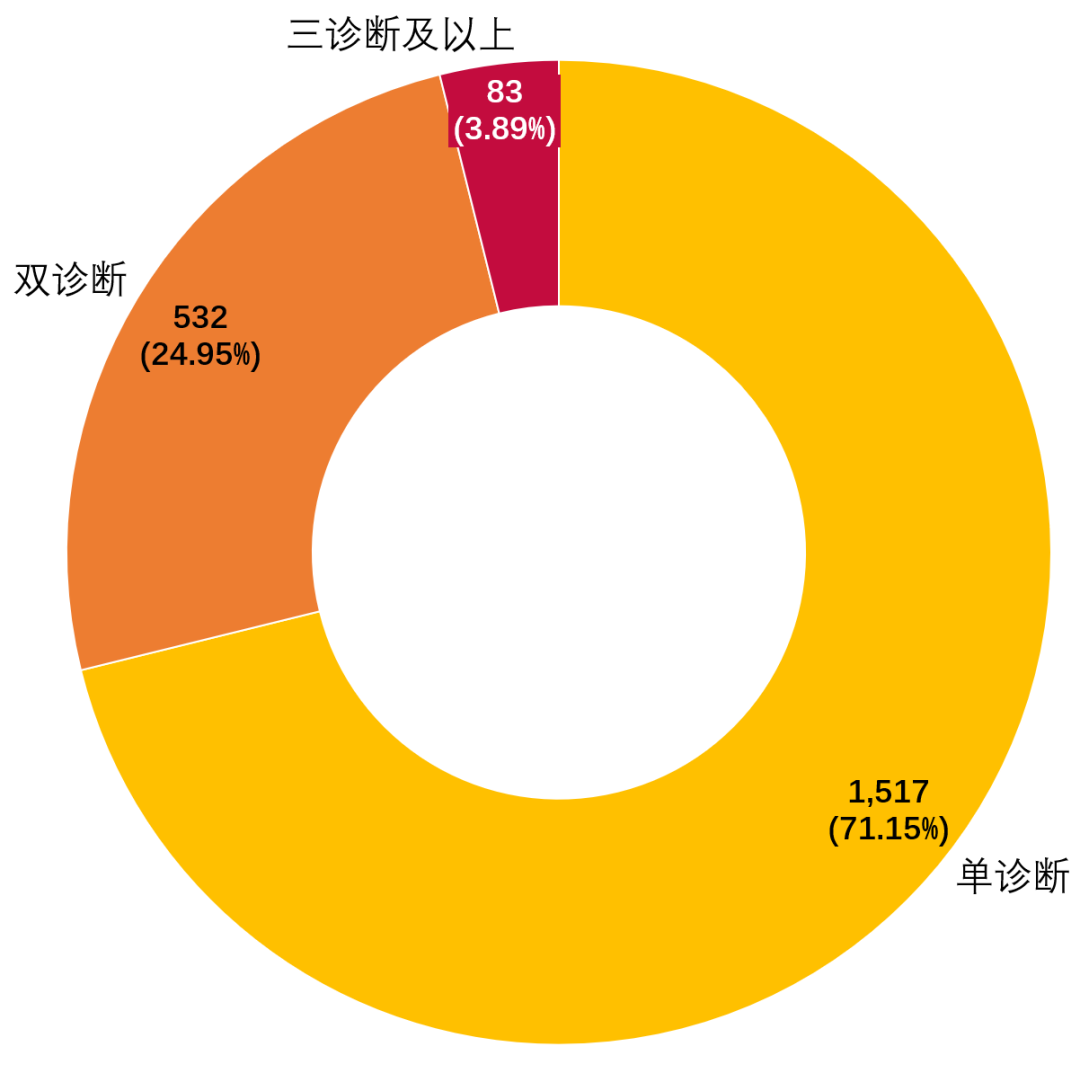
图5 RJUA-QADatasets各条QA的泌尿科诊断分布
3.2 使用说明
数据集下载
下载地址:http://openkg.cn/dataset/rjua-qadatasets
数据格式
问题、文档和答案均以纯文本形式存储,以JSON格式提供。
数据集中划分为3个文件,其中训练集和验证集用于模型训练和验证,测试集用于模型推理指标评测。
·train:训练集
·valid: 验证集
·test: 测试集
每个文件的具体字段包括:
·数据标号:id
·question: 问题
·context: 参考文本
·answer: 答案
·disease:诊断疾病
·advice:诊疗建议
数据示例

4、评测方案
本数据集旨在提高大型语言模型在医疗逻辑推理方面的能力,并作为在严肃可控场景下应用的评测基准。本评测方案设计从两方面来评测模型回复结果:
1. 诊断建议的准确程度:通过计算F1分数来评估疾病诊断及治疗方案的准确程度
·对于单条样本,分别计算TP、TN、FP、FN
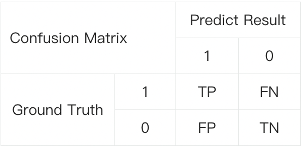
·精确率:P=TP/(TP+FP)
·召回率:R=TP/(TP+FN)
·F1 = 2*P*R/(P+R)
·说明:该公式可以计算得到两个F1指标:F1_诊断、F1_建议。将两个F1以2:1的权重加权得到:F1 = (2*F1_诊断 + F1_建议)/3。最终的Macro F1分数是通过计算各个样本F1分数的算术平均值得到的。
2. 对话回复的整体质量:通过计算Rouge-L来评估对话回复整体和医生回复的一致程度,其计算公式如下:
·P = LCS(S1, S2)/len(S1)
·R = LCS(S1, S2)/len(S2)
·Rouge-L = 2PR/(P+R)
·说明:其中S1为模型输出回复文本,S2为数据集中医生回复文本,LCS为S1和S2的最长公共子序列,len(S)为S的长度。
5、行业大模型评估
我们选取了5个行业大模型在本数据集上进行评测,分别是华佗、GPT3.5、百川、ChatGLM和通义千问。我们使用RougeL和F1指标来衡量模型的推理正确性。评测结果如下表所示:
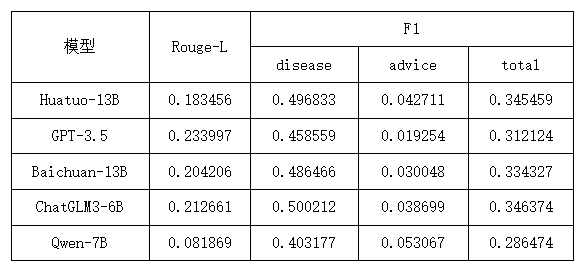
从结果上看:GPT3.5的Rouge-L指标得分最高,主要原因是GPT3.5的模型参数最大,语言能力较好,生成的句式更接近人的表达。在疾病诊断和治疗建议指标上,得分最高的分别是ChatGLM3和千问,这里可能是因为模型对于医学领域尤其是学术词汇的知识学习比较充分。此外,千问模型的Rouge-L较低,主要是因为千问模型生成的句子长度过长,导致准确率较低,因此控制模型输出长度,保证尽量输出有效信息是比较重要的。
6、总结
本文详细介绍了一个基于医疗泌尿专科临床经验构建的QA推理数据集。该数据集具有真实临床背景、多样性和可解释性等特点,旨在提升大模型在逻辑推理能力,并作为医疗专科模型应用的评测准则。我们希望这个数据集能为医疗领域的大模型研究提供有力支持,推动人工智能在医疗领域的应用和发展。
7、展望
未来,我们团队计划持续迭代和优化医疗问答RJUA-QADatasets数据集,包括纳入更多真实世界的临床经验数据,增加更大的疾病数据库覆盖少见病和罕见病,并丰富更多的就诊场景、对话方式、情绪诉求等。另外,我们也将更加贴合实际,开发多轮QA数据集,更贴近于实际医疗问诊中的多轮对话场景。以便为研究人员提供更丰富、更具挑战性的数据资源。此外,我们还将关注大模型在推理能力和实际医疗场景应用方面的评测基准,探索新的方法和技术,以提高模型在严肃可控场景中的落地能力。
我们希望通过不断努力,为医疗领域的人工智能研究和应用贡献力量,推动智能医疗助手的发展,使其更好地服务于患者和医疗专业人士,提高医疗服务的质量和效率。最终,我们期望实现人工智能与医疗领域的深度融合,为人类健康事业创造更多价值。
致谢
感谢上海仁济医院黄翼然、迟辰斐医生团队、蚂蚁医疗服务陈子潇标注团队、蚂蚁医疗大模型团队的辛勤、专业、细致的付出!
其他说明
如果你觉得我们的工作有帮助的话,使用了我们的数据集,请引用下列说明,后续我们会持续优化数据集,并更新可引用的arxiv论文:
@datasets{ title={RJUA-QA Datasets: QA Reasoning Dataset Constructed from Specialized Urological Medical Knowledge},author={RJU},datasets url={http://openkg.cn/dataset/rjua-qadatasets},journal={arXiv preprint arXiv: update later},year={2023} }
如有任何关于数据集的问题或建议,请通过以下方式与我们联系:
chichenfei@renji.com,huangyiran@renji.com,zijing@antgroup.com,zhanying@antgroup.com
注意:本数据使用说明供参考,在使用数据集时,请确保遵循相关法律法规和数据隐私政策。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)