
编译原理实验(词法分析器+语法分析器)
编译原理实验内容及其代码实现
编译原理实验(词法分析+语法分析)
实验内容
请根据给定的文法设计并实现语法分析程序,能基于上次作业的词法分析程序所识别出的单词,识别出各类语法成分。输入输出及处理要求如下:
(1)需按文法规则,用递归子程序法对文法中定义的语法成分进行分析;
(2)为了方便进行自动评测,输入的被编译源文件统一命名为testfile.txt(注意不要写错文件名);输出的结果文件统一命名为output.txt(注意不要写错文件名);结果文件中包含如下两种信息:
输入输出要求:
1)按词法分析识别单词的顺序,按行输出每个单词的信息(要求同词法分析作业,对于预读的情况不能输出)。
2)在文法中出现(除了, , 之外)的语法分析成分分析结束前,另起一行输出当前语法成分的名字,形如“”(注:未要求输出的语法成分仍需要进行分析,但无需输出)
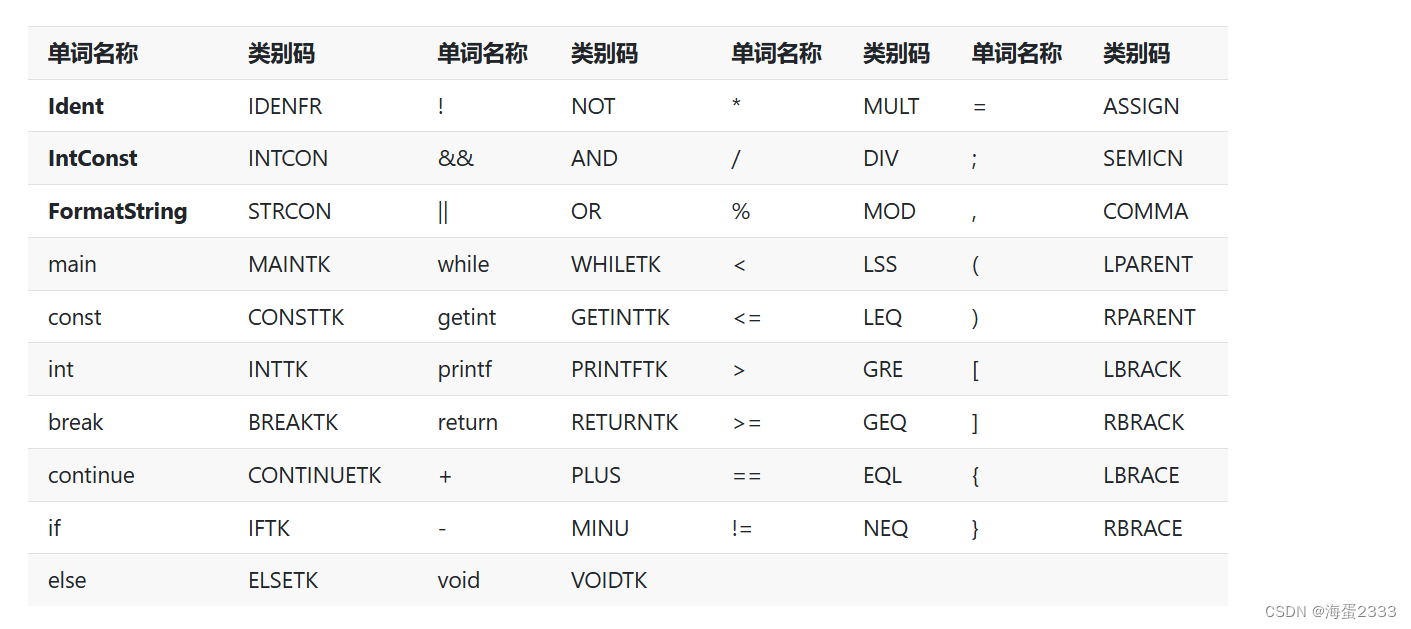
词法要求
文法要求:
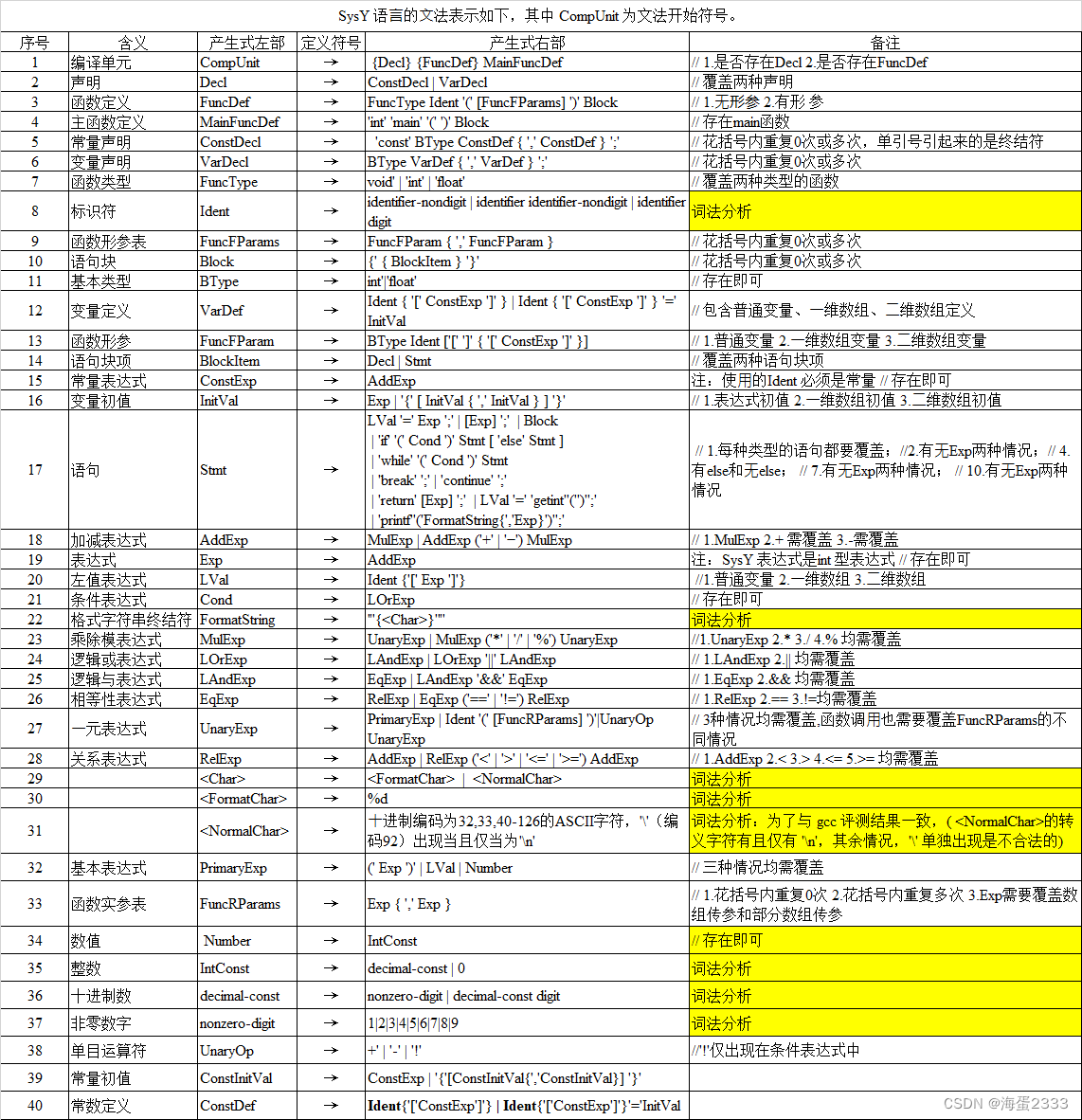
- 编译单元 CompUnit → {Decl} {FuncDef} MainFuncDef // 1.是否存在Decl 2.是否存在FuncDef
- 声明 Decl → ConstDecl | VarDecl // 覆盖两种声明
- 常量声明 ConstDecl → ‘const’ BType ConstDef { ‘,’ ConstDef } ‘;’ // 1.花括号内重复0次 2.花括号内重复多次
- 基本类型 BType → ‘int’ // 存在即可
- 常数定义 ConstDef → Ident { ‘[’ ConstExp ‘]’ } ‘=’ ConstInitVal // 包含普通变量、⼀维数组、⼆维数组共三种情况
- 常量初值 ConstInitVal → ConstExp | ‘{’ [ ConstInitVal { ‘,’ ConstInitVal } ] ‘}’ // 1.常表达式初值 2.⼀维数组初值 3.⼆维数组初值
- 变量声明 VarDecl → BType VarDef { ‘,’ VarDef } ‘;’ // 1.花括号内重复0次 2.花括号内重复多次
- 变量定义 VarDef → Ident { ‘[’ ConstExp ‘]’ } // 包含普通变量、⼀维数组、⼆维数组定义 | Ident { ‘[’ ConstExp ‘]’ } ‘=’ InitVal
- 变量初值 InitVal → Exp | ‘{’ [ InitVal { ‘,’ InitVal } ] ‘}’// 1.表达式初值 2.⼀维数组初值 3.⼆维数组初值
- 函数定义 FuncDef → FuncType Ident ‘(’ [FuncFParams] ‘)’ Block // 1.⽆形参 2.有形参
- 主函数定义 MainFuncDef → ‘int’ ‘main’ ‘(’ ‘)’ Block // 存在main函数
- 函数类型 FuncType → ‘void’ | ‘int’ // 覆盖两种类型的函数
- 函数形参表 FuncFParams → FuncFParam { ‘,’ FuncFParam } // 1.花括号内重复0次 2.花括号内重复多次
- 函数形参 FuncFParam → BType Ident [‘[’ ‘]’ { ‘[’ ConstExp ‘]’ }] // 1.普通变量 2.⼀维数组变量 3.⼆维数组变量
- 语句块 Block → ‘{’ { BlockItem } ‘}’ // 1.花括号内重复0次 2.花括号内重复多次
- 语句块项 BlockItem → Decl | Stmt // 覆盖两种语句块项
- 语句 Stmt → LVal ‘=’ Exp ‘;’ // 每种类型的语句都要覆盖
| [Exp] ‘;’ //有⽆Exp两种情况
| Block
| ‘if’ ‘(’ Cond ‘)’ Stmt [ ‘else’ Stmt ] // 1.有else 2.⽆else
| ‘while’ ‘(’ Cond ‘)’ Stmt
| ‘break’ ‘;’ | ‘continue’ ‘;’
| ‘return’ [Exp] ‘;’ // 1.有Exp 2.⽆Exp
| LVal ‘=’ ‘getint’‘(’‘)’‘;’
| ‘printf’‘(‘FormatString{’,‘Exp}’)’‘;’ // 1.有Exp 2.⽆Exp - 表达式 Exp → AddExp 注:SysY 表达式是int 型表达式 // 存在即可
- 条件表达式 Cond → LOrExp // 存在即可
- 左值表达式 LVal → Ident {‘[’ Exp ‘]’} //1.普通变量 2.⼀维数组 3.⼆维数组
- 基本表达式 PrimaryExp → ‘(’ Exp ‘)’ | LVal | Number // 三种情况均需覆盖
- 数值 Number → IntConst // 存在即可
- ⼀元表达式 UnaryExp → PrimaryExp | Ident ‘(’ [FuncRParams] ‘)’ // 3种情况均需覆盖,函数调⽤也需要覆盖FuncRParams的不同情况| UnaryOp UnaryExp // 存在即可
- 单⽬运算符 UnaryOp → ‘+’ | ‘−’ | ‘!’ 注:'!'仅出现在条件表达式中 // 三种均需覆盖
- 函数实参表 FuncRParams → Exp { ‘,’ Exp } // 1.花括号内重复0次 2.花括号内重复多次 3.Exp需要覆盖数组传参和部分数组传参
- 乘除模表达式 MulExp → UnaryExp | MulExp (’ | ‘/’ | ‘%’) UnaryExp //1.UnaryExp 2. 3./ 4.% 均需覆盖
- 加减表达式 AddExp → MulExp | AddExp (‘+’ | ‘−’) MulExp // 1.MulExp 2.+ 需覆盖 3.-需覆盖
- 关系表达式 RelExp → AddExp | RelExp (‘<’ | ‘>’ | ‘<=’ | ‘>=’) AddExp // 1.AddExp 2.< 3.> 4.<= 5.>= 均需覆盖
- 相等性表达式 EqExp → RelExp | EqExp ('’ | ‘!=’) RelExp // 1.RelExp 2. 3.!=均需覆盖
- 逻辑与表达式 LAndExp → EqExp | LAndExp ‘&&’ EqExp // 1.EqExp 2.&& 均需覆盖
- 逻辑或表达式 LOrExp → LAndExp | LOrExp ‘||’ LAndExp // 1.LAndExp 2.|| 均需覆盖
- 常量表达式 ConstExp → AddExp 注:使⽤的Ident 必须是常量 // 存在即可
其中,标识符Ident、格式字符串终结符FormatString、、、、数值Number、整数IntConst、十进制数decimal-const、非零数字nonzero-digit均在词法分析程序中完成分析。
符号[…]表示方括号内包含的为可选项
符号{…}表示花括号内包含的为可重复 0 次或多次的项
终结符或者是由单引号括起的串,或者是 Ident、InstConst 这样的记号
【输入形式】testfile.txt中的符合文法要求的测试程序。
【输出形式】按如上要求将语法分析结果输出至output.txt中。
【特别提醒】
(1)本次作业只考核对正确程序的处理,但需要为今后可能出现的错误情况预留接口。
(2)当前要求的输出只是为了便于评测,完成编译器中无需出现这些信息,请设计为方便打开/关闭这些输出的方案。
实验样例输入输出
【样例输入】
int main(){
int c;
c= getint();
printf("%d",c);
return c;
}
【样例输出】
INTTK int
MAINTK main
LPARENT (
RPARENT )
LBRACE {
INTTK int
IDENFR c
<VarDef>
SEMICN ;
<VarDecl>
IDENFR c
<LVal>
ASSIGN =
GETINTTK getint
LPARENT (
RPARENT )
SEMICN ;
<Stmt>
PRINTFTK printf
LPARENT (
STRCON "%d"
COMMA ,
IDENFR c
<LVal>
<PrimaryExp>
<UnaryExp>
<MulExp>
<AddExp>
<Exp>
RPARENT )
SEMICN ;
<Stmt>
RETURNTK return
IDENFR c
<LVal>
<PrimaryExp>
<UnaryExp>
<MulExp>
<AddExp>
<Exp>
SEMICN ;
<Stmt>
RBRACE }
<Block>
<MainFuncDef>
<CompUnit>
实验实现
1.递归下降子程序实现
本程序根据 SysY 语言的文法,利用自顶向下的递归下降法编写了相应的的 C++递归下降子程序。在实验 1(即词法分析模块) 中编写的词法分析程序中,程序扫描 testfile 文件实现了源程序的词法分析,并将对应的词法 token 存入了vectortoken 这一数据结构中。随后,程序开始进行递归下降的语法分析,从语法单元 MatchComUnit() 开始编译原理递归调用其文法产生式编译原理右部对应的子程序,并在每个子程序递归返回前将产生式左部的信息输出至 output.txt中。最终,实现了整个源程序的语法分析。
本程序根据 SysY 语言的文法,实现了一个基于递归下降法的词法分析器和语法分析器。程序的结构包括词法分析部分和语法分析部分。其中,词法分析部分在实验一中已经完成,语法分析部分包括了如 MatchComUnit()、**MatchDecl()**等产生式左部非终结符对应的子程序,同时,语法分析由这些程序的递归调用实现。
void MatchCompUnit()
{
// 编译单元 CompUnit → {Decl} {FuncDef} MainFuncDef // 1.是否存在Decl 2.是否存在FuncDef
// 常量声明
while ((token[q] == "INTTK" || token[q] == "CHARTK")
&& token[q + 2] != "LPARENT" || token[q] == "CONSTTK")
{
MatchDecl();
}
// 函数定义
while ((token[q] == "INTTK" || token[q] == "CHARTK" || token[q] == "VOIDTK")
&& token[q + 1] == "IDENFR" && token[q + 2] == "LPARENT")
{
MatchFuncDef();
}
// 主函数
if (token[q] == "INTTK" && token[q + 1] == "MAINTK")
{
MatchMainFuncDef();
}
output << "<CompUnit>\n";
}
2.消除左递归
本实验基于给定的 SysY 语言文法进行代码编写。然而,文法中的某些产生式存在“左递归”,如左部为MatchAddExp()和左部为MatchMulExp() 的产生式。如果不消除文法的左递归,编写的代码在进行递归下降调用时会出现死循环的现象。故在文法的处理阶段我们需要消除文法的左递归。 例如形如 A->Aa|b 要改写为 A->bA’,A’->aA’| ε,所以要构造等价的 LL(1)文法,例如多写一个 **MatchAddExp2()**函数来实现改写。
void MatchAddExp()
{
// 加减表达式 AddExp → MulExp | AddExp ('+' | '−') MulExp
// 形式:A → Aa|b
// 改写为:A → bA’ ,A’→ aA’|ε
MatchMulExp();
MatchAddExp2();
}
void MatchAddExp2()
{
output << "<AddExp>\n";
if (token[q] == "PLUS" || token[q] == "MINU")
{
if (token[q] == "PLUS")
MatchToken("PLUS");
else if (token[q] == "MINU")
MatchToken("MINU");
MatchMulExp();
MatchAddExp2();
}
}
词法分析模块
#pragma region 词法分析模块
bool IsDigit(char c)
{
return isdigit(c);
}
bool IsLetter(char c)
{
if (isalpha(c) || (c == '_'))
return true;
return false;
}
map<string, string> category;
int length = 0;
char in[MAXN];
// vector<char> inn;
int num = 0;
vector<string> token;
vector<string> val;
void read()
{
category["const"] = "CONSTTK";
category["int"] = "INTTK";
category["char"] = "CHARTK";
category["void"] = "VOIDTK";
category["main"] = "MAINTK";
category["if"] = "IFTK";
category["else"] = "ELSETK";
category["do"] = "DOTK";
category["while"] = "WHILETK";
category["for"] = "FORTK";
category["continue"] = "CONTINUETK";
category["break"] = "BREAKTK";
category["getint"] = "GETINTTK";
category["printf"] = "PRINTFTK";
category["return"] = "RETURNTK";
category["+"] = "PLUS";
category["-"] = "MINU";
category["*"] = "MULT";
category["/"] = "DIV";
category["%"] = "MOD";
category["&&"] = "AND";
category["||"] = "OR";
category[","] = "COMMA";
category[";"] = "SEMICN";
category["("] = "LPARENT";
category[")"] = "RPARENT";
category["["] = "LBRACK";
category["]"] = "RBRACK";
category["{"] = "LBRACE";
category["}"] = "RBRACE";
// 读取文件转存in数组
ifstream input("testfile.txt", ios::in);
if (!input)
{
cout << "open testfile.txt error!" << endl;
exit(1);
}
input.unsetf(ios::skipws);
while (input.peek() != EOF)
{
char c = input.get();
in[length++] = c;
// inn.push_back(c);
}
input.close();
// cout<<length<<endl;
// for(int i=0;i<length;i++) cout<<i<<" "<<inn[i]<<endl;
}
void WordAnalysis()
{
int p = 0;
while (p < length)
{
while (in[p] == ' ' || in[p] == '\n')
p++;
if (IsLetter(in[p]) || in[p] == '_') // 变量
{
string s = "";
while (IsLetter(in[p]) || IsDigit(in[p]) || in[p] == '_')
{
s += in[p++];
}
if (category[s] != "") // 已经存在
{
token.push_back(category[s]);
}
else
{
token.push_back("IDENFR"); // 定义变量
}
val.push_back(s);
num++;
}
else if (IsDigit(in[p])) // 数字
{
string s = "";
int number = 0;
while (IsDigit(in[p]))
{
number = number * 10 + (in[p] - '0');
s += in[p++];
}
token.push_back("INTCON");
val.push_back(s);
num++;
}
else if (in[p] == '+' || in[p] == '-' || in[p] == '*' || in[p] == '/' || in[p] == '%'
|| in[p] == ';' || in[p] == ',' || in[p] == '(' || in[p] == ')' || in[p] == '['
|| in[p] == ']' || in[p] == '{' || in[p] == '}')
{
// 处理注释
if (in[p] == '/' && in[p + 1] == '/')
{
p = p + 2;
while (in[p] != '\n')
p++;
continue;
}
else if (in[p] == '/' && in[p + 1] == '*')
{
p = p + 2;
while (in[p] != '*' || in[p + 1] != '/')
p++;
p = p + 2;
continue;
}
string s = "";
s += in[p];
p++;
token.push_back(category[s]);
val.push_back(s);
num++;
}
else if (in[p] == '&' || in[p] == '|')
{
string s = "";
s += in[p];
s += in[p + 1];
token.push_back(category[s]);
val.push_back(s);
p += 2;
}
else if (in[p] == '=')
{
if (in[p + 1] == '=') // 双等号
{
token.push_back("EQL");
val.push_back("==");
num++;
p += 2;
}
else
{
token.push_back("ASSIGN");
val.push_back("=");
num++;
p++;
}
}
else if (in[p] == 39) // 单引号
{
p++;
string s = "";
s += in[p];
p++;
if (in[p] == 39)
p++;
token.push_back("CHARCON");
val.push_back(s);
num++;
}
else if (in[p] == '"')
{
string s;
p++;
while (in[p] != '"')
{
s += in[p];
p++;
}
p++;
token.push_back("STRCON");
val.push_back('"' + s + '"');
num++;
}
else if (in[p] == '<')
{
if (in[p + 1] == '=') // 小于等于号
{
token.push_back("LEQ");
val.push_back("<=");
num++;
p += 2;
}
else
{
token.push_back("LSS");
val.push_back("<");
num++;
p++;
}
}
else if (in[p] == '>')
{
if (in[p + 1] == '=') // 大于等于号
{
token.push_back("GEQ");
val.push_back(">=");
num++;
p += 2;
}
else
{
token.push_back("GRE");
val.push_back(">");
num++;
p++;
}
}
else if (in[p] == '!')
{
if (in[p + 1] == '=') // 不等于号
{
token.push_back("NEQ");
val.push_back("!=");
num++;
p += 2;
}
else
{
token.push_back("NOT");
val.push_back("!");
num++;
p++;
}
}
else
p++;
}
return;
}
#pragma endregion
语法分析模块
#pragma region 语法分析模块
int q; // token[q]==lookahead
map<string, int> VoidFunction;
ofstream output;
void MatchToken(string expected);
void MatchCompUnit();
void MatchDecl();
void MatchConstDecl();
void MatchIntConst();
void MatchNumber();
void MatchBType();
void MatchConstDef();
void MatchConstInitVal();
void MatchVarDecl();
void MatchVarDef();
void MatchInitVal();
void MatchFuncDef();
void MatchMainFuncDef();
void MatchFuncType();
void MatchFuncFParams();
void MatchFuncFParam();
void MatchBlock();
void MatchBlockItem();
void MatchStmt();
void MatchExp();
void MatchCond();
void MatchLVal();
void MatchPrimaryExp();
void MatchUnaryOp();
void MatchFuncRParams();
void MatchMulExp();
void MatchMulExp2();
void MatchUnaryExp();
void MatchAddExp();
void MatchAddExp2();
void MatchRelExp();
void MatchRelExp2();
void MatchEqExp();
void MatchEqExp2();
void MatchLAndExp();
void MatchLAndExp2();
void MatchLOrExp();
void MatchLOrExp2();
void MatchConstExp();
void MatchPrint();
void MatchGetint();
void MatchReturn();
void GrammarAnalysis()
{
q = 0;
MatchCompUnit();
output.close();
return;
}
void MatchCompUnit()
{
// 编译单元 CompUnit → {Decl} {FuncDef} MainFuncDef // 1.是否存在Decl 2.是否存在FuncDef
// 常量声明
while ((token[q] == "INTTK" || token[q] == "CHARTK")
&& token[q + 2] != "LPARENT" || token[q] == "CONSTTK")
{
MatchDecl();
}
// 函数定义
while ((token[q] == "INTTK" || token[q] == "CHARTK" || token[q] == "VOIDTK")
&& token[q + 1] == "IDENFR" && token[q + 2] == "LPARENT")
{
MatchFuncDef();
}
// 主函数
if (token[q] == "INTTK" && token[q + 1] == "MAINTK")
{
MatchMainFuncDef();
}
output << "<CompUnit>\n";
}
void MatchDecl()
{
// 声明Decl → ConstDecl | VarDecl // 覆盖两种声明
if (token[q] == "CONSTTK")
{
MatchConstDecl();
}
else
{
MatchVarDecl();
}
// output << "<Decl>\n";
}
void MatchConstDecl()
{
// 常量声明 ConstDecl → 'const' BType ConstDef { ',' ConstDef } ';' // 1.花括号内重复0次 2.花括号内重复多次
MatchToken("CONSTTK");
MatchBType();
MatchConstDef();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchConstDef();
}
MatchToken("SEMICN");
output << "<ConstDecl>\n";
}
void MatchIntConst()
{
if (val[q][0] == '0' && val[q].length() > 1)
{
printf("error");
exit(0);
}
else
MatchToken("INTCON");
// printf("<无符号整数>\n");
output << "<Number>\n";
}
void MatchNumber()
{
// 数值 Number → IntConst
if (token[q] == "PLUS")
MatchToken("PLUS");
else if (token[q] == "MINU")
MatchToken("MINU");
MatchIntConst();
// printf("<整数>\n");
// output << "<整数>\n";
}
void MatchBType()
{
// 基本类型 BType → 'int' // 存在即可
if (token[q] == "INTTK")
MatchToken("INTTK");
else if (token[q] == "CHARTK")
MatchToken("CHARTK");
}
void MatchConstDef()
{
// 常数定义 ConstDef → Ident { '[' ConstExp ']' } '=' ConstInitVal // 包含普通变量、⼀维数组、⼆维数组共三种情况
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
MatchToken("ASSIGN");
MatchConstInitVal();
output << "<ConstDef>\n";
}
void MatchConstInitVal()
{
// 常量初值 ConstInitVal → ConstExp | '{' [ ConstInitVal { ',' ConstInitVal } ] '}' // 1.常表达式初值 2.⼀维数组初值 3.⼆维数组初值
if (token[q] != "LBRACE")
{
MatchConstExp();
}
else
{
MatchToken("LBRACE");
if (token[q] != "RBRACE")
{
MatchConstInitVal();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchConstInitVal();
}
}
MatchToken("RBRACE");
}
output << "<ConstInitVal>\n";
}
void MatchVarDecl()
{
// 变量声明 VarDecl → BType VarDef { ',' VarDef } ';' // 1.花括号内重复0次 2.花括号内重复多次
MatchBType();
MatchVarDef();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchVarDef();
}
MatchToken("SEMICN");
output << "<VarDecl>\n";
}
void MatchVarDef()
{
// 变量定义 VarDef → Ident { '[' ConstExp ']' } | Ident { '[' ConstExp ']' } '=' InitVal
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
if (token[q] == "ASSIGN")
{
MatchToken("ASSIGN");
MatchInitVal();
}
output << "<VarDef>\n";
}
void MatchInitVal()
{
// 变量初值 InitVal → Exp | '{' [ InitVal { ',' InitVal } ] '}'// 1.表达式初值 2.⼀维数组初值 3.⼆维数组初值
if (token[q] != "LBRACE")
{
MatchExp();
}
else
{
MatchToken("LBRACE");
if (token[q] != "RBRACE")
{
MatchInitVal();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchInitVal();
}
}
MatchToken("RBRACE");
}
output << "<InitVal>\n";
}
void MatchFuncDef()
{
// 函数定义 FuncDef → FuncType Ident '(' [FuncFParams] ')' Block // 1.⽆形参 2.有形参
MatchFuncType();
MatchToken("IDENFR");
MatchToken("LPARENT");
if (token[q] != "RPARENT")
MatchFuncFParams();
MatchToken("RPARENT");
MatchBlock();
output << "<FuncDef>\n";
}
void MatchMainFuncDef()
{
// 主函数定义 MainFuncDef → 'int' 'main' '(' ')' Block // 存在main函数
MatchToken("INTTK");
MatchToken("MAINTK");
MatchToken("LPARENT");
MatchToken("RPARENT");
MatchBlock();
// printf("<MainFuncDef>\n");
output << "<MainFuncDef>\n";
}
void MatchFuncType()
{
// 函数类型 FuncType → 'void' | 'int' // 覆盖两种类型的函数
if (token[q] == "INTTK")
MatchToken("INTTK");
else if (token[q] == "VOIDTK")
MatchToken("VOIDTK");
output << "<FuncType>\n";
}
void MatchFuncFParams()
{
// 函数形参表 FuncFParams → FuncFParam { ',' FuncFParam } // 1.花括号内重复0次 2.花括号内重复多次
MatchFuncFParam();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchFuncFParam();
}
output << "<FuncFParams>\n";
}
void MatchFuncFParam()
{
// 函数形参 FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }] // 1.普通变量 2.⼀维数组变量 3.⼆维数组变量
MatchBType();
MatchToken("IDENFR");
// 数组
if (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchToken("RBRACK");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
}
output << "<FuncFParam>\n";
}
void MatchBlock()
{
// 语句块 Block → '{' { BlockItem } '}' // 1.花括号内重复0次 2.花括号内重复多次
MatchToken("LBRACE");
while (token[q] != "RBRACE")
MatchBlockItem();
MatchToken("RBRACE");
// printf("<Block>\n");
output << "<Block>\n";
}
void MatchBlockItem()
{
// 语句块项 BlockItem → Decl | Stmt // 覆盖两种语句块项
if (token[q] == "INTTK" || token[q] == "CHARTK" || token[q] == "CONSTTK")
{
MatchDecl();
}
else
{
MatchStmt();
}
// output << "<BlockItem>\n";
}
void MatchStmt()
{
// 语句 Stmt → LVal '=' Exp ';' // 每种类型的语句都要覆盖
// | [Exp] ';' //有⽆Exp两种情况
// | Block
// | 'if' '(' Cond ')' Stmt [ 'else' Stmt ] // 1.有else 2.⽆else
// | 'while' '(' Cond ')' Stmt
// | 'break' ';' | 'continue' ';'
// | 'return' [Exp] ';' // 1.有Exp 2.⽆Exp
// | LVal '=' 'getint''('')'';'
// | 'printf''('FormatString{','Exp}')'';' // 1.有Exp 2.⽆Exp
if (token[q] == "IDENFR")
{
// result[k]=1;的情况
// a[1] - a[1];
// a[2] = -+a[1] * a[0] / 1;
// temp[0][2] = 4;
if (((token[q + 1] == "LBRACK" && token[q + 4] == "LBRACK" && token[q + 7] == "ASSIGN"))
|| (token[q + 1] == "LBRACK" && token[q + 4] == "ASSIGN")
|| token[q + 1] == "ASSIGN")
{
MatchLVal();
MatchToken("ASSIGN");
if (token[q] == "GETINTTK")
{
MatchGetint();
}
else
MatchExp();
}
else
{
MatchExp();
}
MatchToken("SEMICN");
}
else if (token[q] == "LBRACE")
{
MatchBlock();
}
else if (token[q] == "IFTK")
{
MatchToken("IFTK");
MatchToken("LPARENT");
MatchCond();
MatchToken("RPARENT");
MatchStmt();
if (token[q] == "ELSETK")
{
MatchToken("ELSETK");
MatchStmt();
}
}
else if (token[q] == "WHILETK")
{
MatchToken("WHILETK");
MatchToken("LPARENT");
MatchCond();
MatchToken("RPARENT");
MatchStmt();
}
else if (token[q] == "BREAKTK" || token[q] == "CONTINUETK")
{
MatchToken(token[q]);
MatchToken("SEMICN");
}
else if (token[q] == "RETURNTK")
{
MatchReturn();
MatchToken("SEMICN");
}
else if (token[q] == "PRINTFTK")
{
MatchPrint();
MatchToken("SEMICN");
}
else if (token[q] == "SEMICN")
MatchToken("SEMICN");
// printf("<Stmt>\n");
output << "<Stmt>\n";
}
void MatchExp()
{
// 表达式 Exp → AddExp
MatchAddExp();
// printf("<Exp>\n");
output << "<Exp>\n";
}
void MatchCond()
{
// 条件表达式 Cond → LOrExp
MatchLOrExp();
output << "<Cond>\n";
}
void MatchLVal()
{
// 左值表达式 LVal → Ident {'[' Exp ']'}
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchExp();
MatchToken("RBRACK");
}
output << "<LVal>\n";
}
void MatchPrimaryExp()
{
// 基本表达式 PrimaryExp → '(' Exp ')' | LVal | Number
if (token[q] == "LPARENT")
{
MatchToken("LPARENT");
MatchExp();
MatchToken("RPARENT");
}
else if (token[q] == "IDENFR")
{
MatchLVal();
}
else if (token[q] == "INTCON" || token[q] == "PLUS" || token[q] == "MINU")
MatchNumber();
output << "<PrimaryExp>\n";
}
void MatchUnaryOp()
{
// 单⽬运算符 UnaryOp → '+' | '−' | '!' 注:'!'仅出现在条件表达式中 // 三种均需覆盖
if (token[q] == "PLUS" || token[q] == "MINU" || token[q] == "NOT")
{
MatchToken(token[q]);
}
output << "<UnaryOp>\n";
}
void MatchFuncRParams()
{
// 函数实参表 FuncRParams → Exp { ',' Exp }
MatchExp();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchExp();
}
output << "<FuncRParams>\n";
}
void MatchMulExp()
{
// 乘除模表达式 MulExp → UnaryExp | MulExp (*' | '/' | '%') UnaryExp
MatchUnaryExp();
MatchMulExp2();
}
void MatchMulExp2()
{
output << "<MulExp>\n";
if (token[q] == "MULT" || token[q] == "DIV" || token[q] == "MOD")
{
if (token[q] == "MULT")
MatchToken("MULT");
else if (token[q] == "DIV")
MatchToken("DIV");
else if (token[q] == "MOD")
MatchToken("MOD");
MatchUnaryExp();
MatchMulExp2();
}
}
void MatchUnaryExp()
{
// ⼀元表达式 UnaryExp → PrimaryExp | Ident '(' [FuncRParams] ')' | UnaryOp UnaryExp
// 首位带符号
if (token[q] == "PLUS" || token[q] == "MINU" || token[q] == "NOT")
{
MatchUnaryOp();
MatchUnaryExp();
}
// 函数调用
else if (token[q + 1] == "LPARENT")
{
MatchToken("IDENFR");
MatchToken("LPARENT");
if (token[q] != "RPARENT")
MatchFuncRParams();
MatchToken("RPARENT");
}
else
{
MatchPrimaryExp();
}
output << "<UnaryExp>\n";
}
void MatchAddExp()
{
// 加减表达式 AddExp → MulExp | AddExp ('+' | '−') MulExp
// 形式:A → Aa|b
// 改写为:A → bA’ ,A’→ aA’|ε
// if (token[q] == "PLUS")MatchToken("PLUS");
// else if (token[q] == "MINU")MatchToken("MINU");
// x+y;
MatchMulExp();
MatchAddExp2();
}
void MatchAddExp2()
{
output << "<AddExp>\n";
if (token[q] == "PLUS" || token[q] == "MINU")
{
if (token[q] == "PLUS")
MatchToken("PLUS");
else if (token[q] == "MINU")
MatchToken("MINU");
MatchMulExp();
MatchAddExp2();
}
}
void MatchRelExp()
{
// 关系表达式 RelExp → AddExp | RelExp ('<' | '>' | '<=' | '>=') AddExp
if (token[q] == "LSS")
MatchToken("LSS");
else if (token[q] == "LEQ")
MatchToken("LEQ");
else if (token[q] == "GRE")
MatchToken("GRE");
else if (token[q] == "GEQ")
MatchToken("GEQ");
MatchAddExp();
MatchRelExp2();
}
void MatchRelExp2()
{
output << "<RelExp>\n";
if (token[q] == "LSS" || token[q] == "LEQ" || token[q] == "GRE" || token[q] == "GEQ")
{
if (token[q] == "LSS")
MatchToken("LSS");
else if (token[q] == "LEQ")
MatchToken("LEQ");
else if (token[q] == "GRE")
MatchToken("GRE");
else if (token[q] == "GEQ")
MatchToken("GEQ");
MatchAddExp();
MatchRelExp2();
}
}
void MatchEqExp()
{
// 相等性表达式 EqExp → RelExp | EqExp ('==' | '!=') RelExp
if (token[q] == "EQL")
MatchToken("EQL");
else if (token[q] == "NEQ")
MatchToken("NEQ");
MatchRelExp();
MatchEqExp2();
}
void MatchEqExp2()
{
output << "<EqExp>\n";
if (token[q] == "EQL" || token[q] == "NEQ")
{
if (token[q] == "EQL")
MatchToken("EQL");
else if (token[q] == "NEQ")
MatchToken("NEQ");
MatchRelExp();
MatchEqExp2();
}
}
void MatchLAndExp()
{
// 逻辑与表达式 LAndExp → EqExp | LAndExp '&&' EqExp
if (token[q] == "AND")
MatchToken("AND");
MatchEqExp();
MatchLAndExp2();
}
void MatchLAndExp2()
{
output << "<LAndExp>\n";
if (token[q] == "AND")
{
if (token[q] == "AND")
MatchToken("AND");
MatchEqExp();
MatchLAndExp2();
}
}
void MatchLOrExp()
{
// 逻辑或表达式 LOrExp → LAndExp | LOrExp '||' LAndExp
if (token[q] == "OR")
MatchToken("OR");
MatchLAndExp();
MatchLOrExp2();
}
void MatchLOrExp2()
{
output << "<LOrExp>\n";
if (token[q] == "OR")
{
if (token[q] == "OR")
MatchToken("OR");
MatchLAndExp();
MatchLOrExp2();
}
}
void MatchConstExp()
{
MatchAddExp();
output << "<ConstExp>\n";
}
void MatchPrint()
{
//'printf''('FormatString{','Exp}')'';' // 1.有Exp 2.⽆Exp
MatchToken("PRINTFTK");
MatchToken("LPARENT");
if (token[q] == "STRCON")
MatchToken("STRCON");
else
MatchExp();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchExp();
}
MatchToken("RPARENT");
}
void MatchGetint()
{
// LVal '=' 'getint''('')'';'
MatchToken("GETINTTK");
MatchToken("LPARENT");
MatchToken("RPARENT");
}
void MatchReturn()
{
// 'return' [Exp] ';' // 1.有Exp 2.⽆Exp
MatchToken("RETURNTK");
// 有返回值
if (token[q] != "SEMICN")
MatchExp();
}
void MatchToken(string expected)
{
if (token[q] == expected)
{
// cout << token[q] << " " << val[q] << endl;
output << token[q] << " " << val[q] << endl;
q++;
}
else
{
cout << token[q] << " " << expected << endl;
printf("shitbrofuckingerror_tm");
exit(0);
}
}
#pragma endregion
完整代码程序test.cpp
#include <iostream>
#include <fstream>
#include <sstream>
#include <string>
#include <vector>
#include <stdlib.h>
#include <queue>
#include <utility>
#include <stdio.h>
#include <map>
using namespace std;
const int MAXN = 100000;
#pragma region 词法分析模块
bool IsDigit(char c)
{
return isdigit(c);
}
bool IsLetter(char c)
{
if (isalpha(c) || (c == '_'))
return true;
return false;
}
map<string, string> category;
int length = 0;
char in[MAXN];
// vector<char> inn;
int num = 0;
vector<string> token;
vector<string> val;
void read()
{
category["const"] = "CONSTTK";
category["int"] = "INTTK";
category["char"] = "CHARTK";
category["void"] = "VOIDTK";
category["main"] = "MAINTK";
category["if"] = "IFTK";
category["else"] = "ELSETK";
category["do"] = "DOTK";
category["while"] = "WHILETK";
category["for"] = "FORTK";
category["continue"] = "CONTINUETK";
category["break"] = "BREAKTK";
category["getint"] = "GETINTTK";
category["printf"] = "PRINTFTK";
category["return"] = "RETURNTK";
category["+"] = "PLUS";
category["-"] = "MINU";
category["*"] = "MULT";
category["/"] = "DIV";
category["%"] = "MOD";
category["&&"] = "AND";
category["||"] = "OR";
category[","] = "COMMA";
category[";"] = "SEMICN";
category["("] = "LPARENT";
category[")"] = "RPARENT";
category["["] = "LBRACK";
category["]"] = "RBRACK";
category["{"] = "LBRACE";
category["}"] = "RBRACE";
// 读取文件转存in数组
ifstream input("testfile.txt", ios::in);
if (!input)
{
cout << "open testfile.txt error!" << endl;
exit(1);
}
input.unsetf(ios::skipws);
while (input.peek() != EOF)
{
char c = input.get();
in[length++] = c;
// inn.push_back(c);
}
input.close();
// cout<<length<<endl;
// for(int i=0;i<length;i++) cout<<i<<" "<<inn[i]<<endl;
}
void WordAnalysis()
{
int p = 0;
while (p < length)
{
while (in[p] == ' ' || in[p] == '\n')
p++;
if (IsLetter(in[p]) || in[p] == '_') // 变量
{
string s = "";
while (IsLetter(in[p]) || IsDigit(in[p]) || in[p] == '_')
{
s += in[p++];
}
if (category[s] != "") // 已经存在
{
token.push_back(category[s]);
}
else
{
token.push_back("IDENFR"); // 定义变量
}
val.push_back(s);
num++;
}
else if (IsDigit(in[p])) // 数字
{
string s = "";
int number = 0;
while (IsDigit(in[p]))
{
number = number * 10 + (in[p] - '0');
s += in[p++];
}
token.push_back("INTCON");
val.push_back(s);
num++;
}
else if (in[p] == '+' || in[p] == '-' || in[p] == '*' || in[p] == '/' || in[p] == '%'
|| in[p] == ';' || in[p] == ',' || in[p] == '(' || in[p] == ')' || in[p] == '['
|| in[p] == ']' || in[p] == '{' || in[p] == '}')
{
// 处理注释
if (in[p] == '/' && in[p + 1] == '/')
{
p = p + 2;
while (in[p] != '\n')
p++;
continue;
}
else if (in[p] == '/' && in[p + 1] == '*')
{
p = p + 2;
while (in[p] != '*' || in[p + 1] != '/')
p++;
p = p + 2;
continue;
}
string s = "";
s += in[p];
p++;
token.push_back(category[s]);
val.push_back(s);
num++;
}
else if (in[p] == '&' || in[p] == '|')
{
string s = "";
s += in[p];
s += in[p + 1];
token.push_back(category[s]);
val.push_back(s);
p += 2;
}
else if (in[p] == '=')
{
if (in[p + 1] == '=') // 双等号
{
token.push_back("EQL");
val.push_back("==");
num++;
p += 2;
}
else
{
token.push_back("ASSIGN");
val.push_back("=");
num++;
p++;
}
}
else if (in[p] == 39) // 单引号
{
p++;
string s = "";
s += in[p];
p++;
if (in[p] == 39)
p++;
token.push_back("CHARCON");
val.push_back(s);
num++;
}
else if (in[p] == '"')
{
string s;
p++;
while (in[p] != '"')
{
s += in[p];
p++;
}
p++;
token.push_back("STRCON");
val.push_back('"' + s + '"');
num++;
}
else if (in[p] == '<')
{
if (in[p + 1] == '=') // 小于等于号
{
token.push_back("LEQ");
val.push_back("<=");
num++;
p += 2;
}
else
{
token.push_back("LSS");
val.push_back("<");
num++;
p++;
}
}
else if (in[p] == '>')
{
if (in[p + 1] == '=') // 大于等于号
{
token.push_back("GEQ");
val.push_back(">=");
num++;
p += 2;
}
else
{
token.push_back("GRE");
val.push_back(">");
num++;
p++;
}
}
else if (in[p] == '!')
{
if (in[p + 1] == '=') // 不等于号
{
token.push_back("NEQ");
val.push_back("!=");
num++;
p += 2;
}
else
{
token.push_back("NOT");
val.push_back("!");
num++;
p++;
}
}
else
p++;
}
return;
}
#pragma endregion
#pragma region 语法分析模块
int q; // token[q]==lookahead
map<string, int> VoidFunction;
ofstream output;
void MatchToken(string expected);
void MatchCompUnit();
void MatchDecl();
void MatchConstDecl();
void MatchIntConst();
void MatchNumber();
void MatchBType();
void MatchConstDef();
void MatchConstInitVal();
void MatchVarDecl();
void MatchVarDef();
void MatchInitVal();
void MatchFuncDef();
void MatchMainFuncDef();
void MatchFuncType();
void MatchFuncFParams();
void MatchFuncFParam();
void MatchBlock();
void MatchBlockItem();
void MatchStmt();
void MatchExp();
void MatchCond();
void MatchLVal();
void MatchPrimaryExp();
void MatchUnaryOp();
void MatchFuncRParams();
void MatchMulExp();
void MatchMulExp2();
void MatchUnaryExp();
void MatchAddExp();
void MatchAddExp2();
void MatchRelExp();
void MatchRelExp2();
void MatchEqExp();
void MatchEqExp2();
void MatchLAndExp();
void MatchLAndExp2();
void MatchLOrExp();
void MatchLOrExp2();
void MatchConstExp();
void MatchPrint();
void MatchGetint();
void MatchReturn();
void GrammarAnalysis()
{
q = 0;
MatchCompUnit();
output.close();
return;
}
void MatchCompUnit()
{
// 编译单元 CompUnit → {Decl} {FuncDef} MainFuncDef // 1.是否存在Decl 2.是否存在FuncDef
// 常量声明
while ((token[q] == "INTTK" || token[q] == "CHARTK")
&& token[q + 2] != "LPARENT" || token[q] == "CONSTTK")
{
MatchDecl();
}
// 函数定义
while ((token[q] == "INTTK" || token[q] == "CHARTK" || token[q] == "VOIDTK")
&& token[q + 1] == "IDENFR" && token[q + 2] == "LPARENT")
{
MatchFuncDef();
}
// 主函数
if (token[q] == "INTTK" && token[q + 1] == "MAINTK")
{
MatchMainFuncDef();
}
output << "<CompUnit>\n";
}
void MatchDecl()
{
// 声明Decl → ConstDecl | VarDecl // 覆盖两种声明
if (token[q] == "CONSTTK")
{
MatchConstDecl();
}
else
{
MatchVarDecl();
}
// output << "<Decl>\n";
}
void MatchConstDecl()
{
// 常量声明 ConstDecl → 'const' BType ConstDef { ',' ConstDef } ';' // 1.花括号内重复0次 2.花括号内重复多次
MatchToken("CONSTTK");
MatchBType();
MatchConstDef();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchConstDef();
}
MatchToken("SEMICN");
output << "<ConstDecl>\n";
}
void MatchIntConst()
{
if (val[q][0] == '0' && val[q].length() > 1)
{
printf("error");
exit(0);
}
else
MatchToken("INTCON");
// printf("<无符号整数>\n");
output << "<Number>\n";
}
void MatchNumber()
{
// 数值 Number → IntConst
if (token[q] == "PLUS")
MatchToken("PLUS");
else if (token[q] == "MINU")
MatchToken("MINU");
MatchIntConst();
// printf("<整数>\n");
// output << "<整数>\n";
}
void MatchBType()
{
// 基本类型 BType → 'int' // 存在即可
if (token[q] == "INTTK")
MatchToken("INTTK");
else if (token[q] == "CHARTK")
MatchToken("CHARTK");
}
void MatchConstDef()
{
// 常数定义 ConstDef → Ident { '[' ConstExp ']' } '=' ConstInitVal // 包含普通变量、⼀维数组、⼆维数组共三种情况
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
MatchToken("ASSIGN");
MatchConstInitVal();
output << "<ConstDef>\n";
}
void MatchConstInitVal()
{
// 常量初值 ConstInitVal → ConstExp | '{' [ ConstInitVal { ',' ConstInitVal } ] '}' // 1.常表达式初值 2.⼀维数组初值 3.⼆维数组初值
if (token[q] != "LBRACE")
{
MatchConstExp();
}
else
{
MatchToken("LBRACE");
if (token[q] != "RBRACE")
{
MatchConstInitVal();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchConstInitVal();
}
}
MatchToken("RBRACE");
}
output << "<ConstInitVal>\n";
}
void MatchVarDecl()
{
// 变量声明 VarDecl → BType VarDef { ',' VarDef } ';' // 1.花括号内重复0次 2.花括号内重复多次
MatchBType();
MatchVarDef();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchVarDef();
}
MatchToken("SEMICN");
output << "<VarDecl>\n";
}
void MatchVarDef()
{
// 变量定义 VarDef → Ident { '[' ConstExp ']' } | Ident { '[' ConstExp ']' } '=' InitVal
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
if (token[q] == "ASSIGN")
{
MatchToken("ASSIGN");
MatchInitVal();
}
output << "<VarDef>\n";
}
void MatchInitVal()
{
// 变量初值 InitVal → Exp | '{' [ InitVal { ',' InitVal } ] '}'// 1.表达式初值 2.⼀维数组初值 3.⼆维数组初值
if (token[q] != "LBRACE")
{
MatchExp();
}
else
{
MatchToken("LBRACE");
if (token[q] != "RBRACE")
{
MatchInitVal();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchInitVal();
}
}
MatchToken("RBRACE");
}
output << "<InitVal>\n";
}
void MatchFuncDef()
{
// 函数定义 FuncDef → FuncType Ident '(' [FuncFParams] ')' Block // 1.⽆形参 2.有形参
MatchFuncType();
MatchToken("IDENFR");
MatchToken("LPARENT");
if (token[q] != "RPARENT")
MatchFuncFParams();
MatchToken("RPARENT");
MatchBlock();
output << "<FuncDef>\n";
}
void MatchMainFuncDef()
{
// 主函数定义 MainFuncDef → 'int' 'main' '(' ')' Block // 存在main函数
MatchToken("INTTK");
MatchToken("MAINTK");
MatchToken("LPARENT");
MatchToken("RPARENT");
MatchBlock();
// printf("<MainFuncDef>\n");
output << "<MainFuncDef>\n";
}
void MatchFuncType()
{
// 函数类型 FuncType → 'void' | 'int' // 覆盖两种类型的函数
if (token[q] == "INTTK")
MatchToken("INTTK");
else if (token[q] == "VOIDTK")
MatchToken("VOIDTK");
output << "<FuncType>\n";
}
void MatchFuncFParams()
{
// 函数形参表 FuncFParams → FuncFParam { ',' FuncFParam } // 1.花括号内重复0次 2.花括号内重复多次
MatchFuncFParam();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchFuncFParam();
}
output << "<FuncFParams>\n";
}
void MatchFuncFParam()
{
// 函数形参 FuncFParam → BType Ident ['[' ']' { '[' ConstExp ']' }] // 1.普通变量 2.⼀维数组变量 3.⼆维数组变量
MatchBType();
MatchToken("IDENFR");
// 数组
if (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchToken("RBRACK");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchConstExp();
MatchToken("RBRACK");
}
}
output << "<FuncFParam>\n";
}
void MatchBlock()
{
// 语句块 Block → '{' { BlockItem } '}' // 1.花括号内重复0次 2.花括号内重复多次
MatchToken("LBRACE");
while (token[q] != "RBRACE")
MatchBlockItem();
MatchToken("RBRACE");
// printf("<Block>\n");
output << "<Block>\n";
}
void MatchBlockItem()
{
// 语句块项 BlockItem → Decl | Stmt // 覆盖两种语句块项
if (token[q] == "INTTK" || token[q] == "CHARTK" || token[q] == "CONSTTK")
{
MatchDecl();
}
else
{
MatchStmt();
}
// output << "<BlockItem>\n";
}
void MatchStmt()
{
// 语句 Stmt → LVal '=' Exp ';' // 每种类型的语句都要覆盖
// | [Exp] ';' //有⽆Exp两种情况
// | Block
// | 'if' '(' Cond ')' Stmt [ 'else' Stmt ] // 1.有else 2.⽆else
// | 'while' '(' Cond ')' Stmt
// | 'break' ';' | 'continue' ';'
// | 'return' [Exp] ';' // 1.有Exp 2.⽆Exp
// | LVal '=' 'getint''('')'';'
// | 'printf''('FormatString{','Exp}')'';' // 1.有Exp 2.⽆Exp
if (token[q] == "IDENFR")
{
// result[k]=1;的情况
// a[1] - a[1];
// a[2] = -+a[1] * a[0] / 1;
// temp[0][2] = 4;
if (((token[q + 1] == "LBRACK" && token[q + 4] == "LBRACK" && token[q + 7] == "ASSIGN"))
|| (token[q + 1] == "LBRACK" && token[q + 4] == "ASSIGN")
|| token[q + 1] == "ASSIGN")
{
MatchLVal();
MatchToken("ASSIGN");
if (token[q] == "GETINTTK")
{
MatchGetint();
}
else
MatchExp();
}
else
{
MatchExp();
}
MatchToken("SEMICN");
}
else if (token[q] == "LBRACE")
{
MatchBlock();
}
else if (token[q] == "IFTK")
{
MatchToken("IFTK");
MatchToken("LPARENT");
MatchCond();
MatchToken("RPARENT");
MatchStmt();
if (token[q] == "ELSETK")
{
MatchToken("ELSETK");
MatchStmt();
}
}
else if (token[q] == "WHILETK")
{
MatchToken("WHILETK");
MatchToken("LPARENT");
MatchCond();
MatchToken("RPARENT");
MatchStmt();
}
else if (token[q] == "BREAKTK" || token[q] == "CONTINUETK")
{
MatchToken(token[q]);
MatchToken("SEMICN");
}
else if (token[q] == "RETURNTK")
{
MatchReturn();
MatchToken("SEMICN");
}
else if (token[q] == "PRINTFTK")
{
MatchPrint();
MatchToken("SEMICN");
}
else if (token[q] == "SEMICN")
MatchToken("SEMICN");
// printf("<Stmt>\n");
output << "<Stmt>\n";
}
void MatchExp()
{
// 表达式 Exp → AddExp
MatchAddExp();
// printf("<Exp>\n");
output << "<Exp>\n";
}
void MatchCond()
{
// 条件表达式 Cond → LOrExp
MatchLOrExp();
output << "<Cond>\n";
}
void MatchLVal()
{
// 左值表达式 LVal → Ident {'[' Exp ']'}
MatchToken("IDENFR");
while (token[q] == "LBRACK")
{
MatchToken("LBRACK");
MatchExp();
MatchToken("RBRACK");
}
output << "<LVal>\n";
}
void MatchPrimaryExp()
{
// 基本表达式 PrimaryExp → '(' Exp ')' | LVal | Number
if (token[q] == "LPARENT")
{
MatchToken("LPARENT");
MatchExp();
MatchToken("RPARENT");
}
else if (token[q] == "IDENFR")
{
MatchLVal();
}
else if (token[q] == "INTCON" || token[q] == "PLUS" || token[q] == "MINU")
MatchNumber();
output << "<PrimaryExp>\n";
}
void MatchUnaryOp()
{
// 单⽬运算符 UnaryOp → '+' | '−' | '!' 注:'!'仅出现在条件表达式中 // 三种均需覆盖
if (token[q] == "PLUS" || token[q] == "MINU" || token[q] == "NOT")
{
MatchToken(token[q]);
}
output << "<UnaryOp>\n";
}
void MatchFuncRParams()
{
// 函数实参表 FuncRParams → Exp { ',' Exp }
MatchExp();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchExp();
}
output << "<FuncRParams>\n";
}
void MatchMulExp()
{
// 乘除模表达式 MulExp → UnaryExp | MulExp (*' | '/' | '%') UnaryExp
MatchUnaryExp();
MatchMulExp2();
}
void MatchMulExp2()
{
output << "<MulExp>\n";
if (token[q] == "MULT" || token[q] == "DIV" || token[q] == "MOD")
{
if (token[q] == "MULT")
MatchToken("MULT");
else if (token[q] == "DIV")
MatchToken("DIV");
else if (token[q] == "MOD")
MatchToken("MOD");
MatchUnaryExp();
MatchMulExp2();
}
}
void MatchUnaryExp()
{
// ⼀元表达式 UnaryExp → PrimaryExp | Ident '(' [FuncRParams] ')' | UnaryOp UnaryExp
// 首位带符号
if (token[q] == "PLUS" || token[q] == "MINU" || token[q] == "NOT")
{
MatchUnaryOp();
MatchUnaryExp();
}
// 函数调用
else if (token[q + 1] == "LPARENT")
{
MatchToken("IDENFR");
MatchToken("LPARENT");
if (token[q] != "RPARENT")
MatchFuncRParams();
MatchToken("RPARENT");
}
else
{
MatchPrimaryExp();
}
output << "<UnaryExp>\n";
}
void MatchAddExp()
{
// 加减表达式 AddExp → MulExp | AddExp ('+' | '−') MulExp
// 形式:A → Aa|b
// 改写为:A → bA’ ,A’→ aA’|ε
// if (token[q] == "PLUS")MatchToken("PLUS");
// else if (token[q] == "MINU")MatchToken("MINU");
// x+y;
MatchMulExp();
MatchAddExp2();
}
void MatchAddExp2()
{
output << "<AddExp>\n";
if (token[q] == "PLUS" || token[q] == "MINU")
{
if (token[q] == "PLUS")
MatchToken("PLUS");
else if (token[q] == "MINU")
MatchToken("MINU");
MatchMulExp();
MatchAddExp2();
}
}
void MatchRelExp()
{
// 关系表达式 RelExp → AddExp | RelExp ('<' | '>' | '<=' | '>=') AddExp
if (token[q] == "LSS")
MatchToken("LSS");
else if (token[q] == "LEQ")
MatchToken("LEQ");
else if (token[q] == "GRE")
MatchToken("GRE");
else if (token[q] == "GEQ")
MatchToken("GEQ");
MatchAddExp();
MatchRelExp2();
}
void MatchRelExp2()
{
output << "<RelExp>\n";
if (token[q] == "LSS" || token[q] == "LEQ" || token[q] == "GRE" || token[q] == "GEQ")
{
if (token[q] == "LSS")
MatchToken("LSS");
else if (token[q] == "LEQ")
MatchToken("LEQ");
else if (token[q] == "GRE")
MatchToken("GRE");
else if (token[q] == "GEQ")
MatchToken("GEQ");
MatchAddExp();
MatchRelExp2();
}
}
void MatchEqExp()
{
// 相等性表达式 EqExp → RelExp | EqExp ('==' | '!=') RelExp
if (token[q] == "EQL")
MatchToken("EQL");
else if (token[q] == "NEQ")
MatchToken("NEQ");
MatchRelExp();
MatchEqExp2();
}
void MatchEqExp2()
{
output << "<EqExp>\n";
if (token[q] == "EQL" || token[q] == "NEQ")
{
if (token[q] == "EQL")
MatchToken("EQL");
else if (token[q] == "NEQ")
MatchToken("NEQ");
MatchRelExp();
MatchEqExp2();
}
}
void MatchLAndExp()
{
// 逻辑与表达式 LAndExp → EqExp | LAndExp '&&' EqExp
if (token[q] == "AND")
MatchToken("AND");
MatchEqExp();
MatchLAndExp2();
}
void MatchLAndExp2()
{
output << "<LAndExp>\n";
if (token[q] == "AND")
{
if (token[q] == "AND")
MatchToken("AND");
MatchEqExp();
MatchLAndExp2();
}
}
void MatchLOrExp()
{
// 逻辑或表达式 LOrExp → LAndExp | LOrExp '||' LAndExp
if (token[q] == "OR")
MatchToken("OR");
MatchLAndExp();
MatchLOrExp2();
}
void MatchLOrExp2()
{
output << "<LOrExp>\n";
if (token[q] == "OR")
{
if (token[q] == "OR")
MatchToken("OR");
MatchLAndExp();
MatchLOrExp2();
}
}
void MatchConstExp()
{
MatchAddExp();
output << "<ConstExp>\n";
}
void MatchPrint()
{
//'printf''('FormatString{','Exp}')'';' // 1.有Exp 2.⽆Exp
MatchToken("PRINTFTK");
MatchToken("LPARENT");
if (token[q] == "STRCON")
MatchToken("STRCON");
else
MatchExp();
while (token[q] == "COMMA")
{
MatchToken("COMMA");
MatchExp();
}
MatchToken("RPARENT");
}
void MatchGetint()
{
// LVal '=' 'getint''('')'';'
MatchToken("GETINTTK");
MatchToken("LPARENT");
MatchToken("RPARENT");
}
void MatchReturn()
{
// 'return' [Exp] ';' // 1.有Exp 2.⽆Exp
MatchToken("RETURNTK");
// 有返回值
if (token[q] != "SEMICN")
MatchExp();
}
void MatchToken(string expected)
{
if (token[q] == expected)
{
// cout << token[q] << " " << val[q] << endl;
output << token[q] << " " << val[q] << endl;
q++;
}
else
{
cout << token[q] << " " << expected << endl;
printf("shitbrofuckingerror_tm");
exit(0);
}
}
#pragma endregion
// 预处理文件
void Init()
{
// 清空输出文件
fstream file("output.txt", ios::out);
output.open("output.txt", ios::out);
}
// 输出词法
void PrintWords()
{
ofstream output("output.txt",ios::out);
for(int i=0;i<num;i++)
{
output<<token[i]<<" "<<val[i]<<endl;
}
output.close();
}
int main()
{
Init();
read();
WordAnalysis();
// PrintWords();
GrammarAnalysis();
return 0;
}

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)