
信息管理系统评价——层次分析法(入门)
层次分析法由美国决策科学领域专家T.L.Saaty教授于20世纪70年代提出,其对各指标权重的量化分析具有较强的逻辑性,加上数学处理,可信度较好。使用了更先进的软硬件,意味着投资更多,那么经济效益就会下降。并且,它们之间的比较往往无法用定量的方式描述,此时需要将半定性、半定量的问题转化为定量计算问题。层次分析法是解决这类问题的行之有效的方法。层次分析法将复杂的决策系统层次化,通过逐层比较各种关联因
一、背景概述
管理信息系统,特别是一些复杂、大型的管理信息系统,其开发是是一项系统工程,需要花费大量的资金、人力、物力和时间,因而无论对于开发者还是使用者,在系统建成后,都希望了解系统对组织的贡献有多大,系统运行的效果如何,系统的性能怎样,是否达到了系统设计的目标,还存在哪些不足,等等。要回答这样一些问题,必须进行系统评价工作。
系统评价的目的
系统评价的目的具体为:检查系统目标、功能及各项指标是否达到了设计要求;检查系统的质量,如正确性、可使用性、可扩展性是否达到要求:检查系统中各种资源的利用程度;检查系统的使用效果,找出系统的薄弱环节,提出改进意见。
评价本身不是目的,评价的最终目标是为了决策。
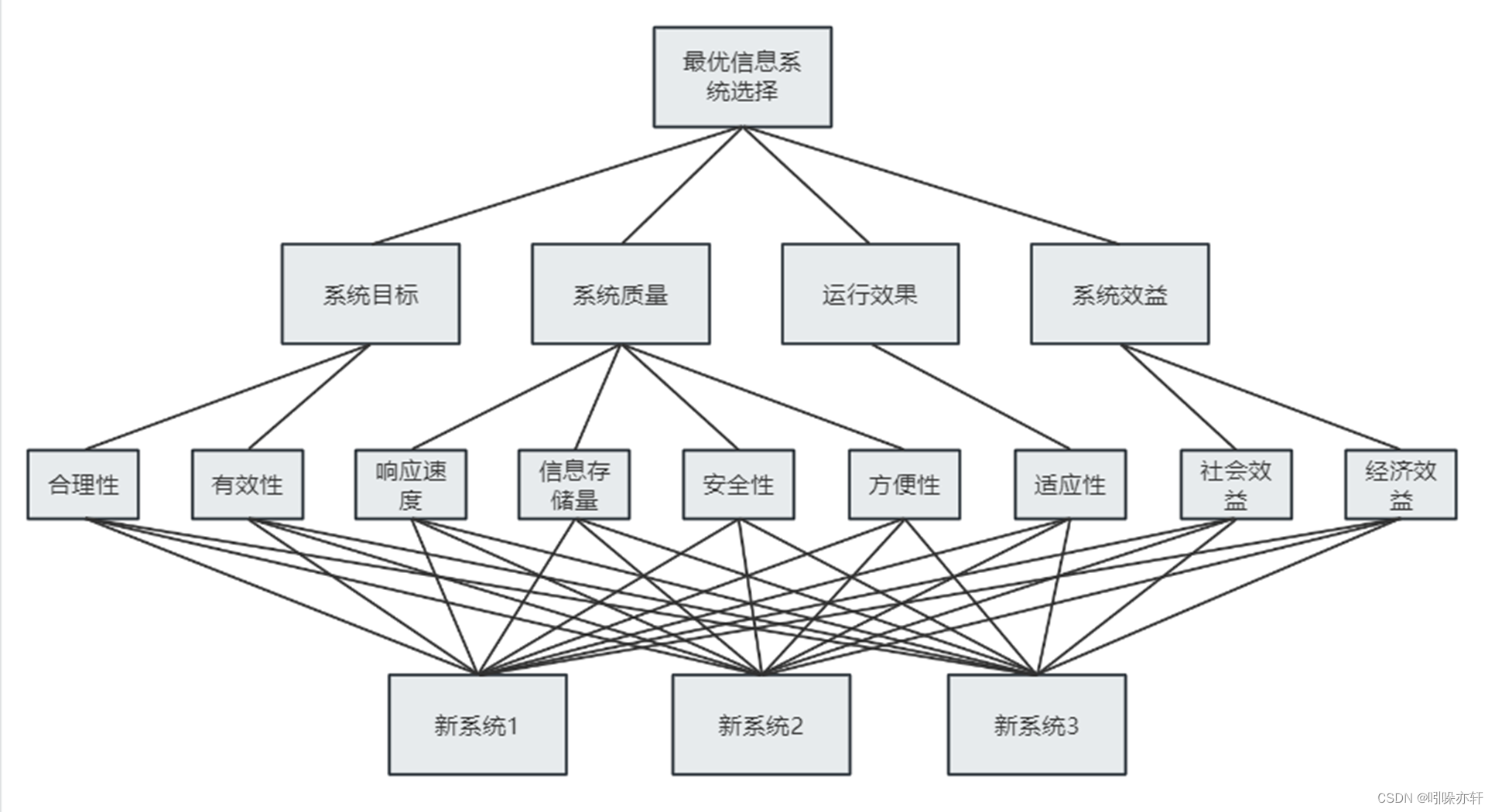
系统评价的指标体系
- 系统目标:目标的合理性和有效性。
- 系统质量:从性能上,响应速度、信息存储量;从安全上,安全性、可靠性;从维护上,维护的方便性;从用户上,用户满意度、人机交互友好性。
- 运行效果:软硬件的适应性和运行效率。
- 系统效益:经济效益和社会效益
二、方法概述
层次分析法由美国决策科学领域专家T.L.Saaty教授于20世纪70年代提出,其对各指标权重的量化分析具有较强的逻辑性,加上数学处理,可信度较好。
在评价管理信息系统时有诸多指标,我们将其看为影响系统评分的因素,这些因素是相互制约、相互影响的,如:使用了更先进的软硬件,意味着投资更多,那么经济效益就会下降。并且,它们之间的比较往往无法用定量的方式描述,此时需要将半定性、半定量的问题转化为定量计算问题。
层次分析法是解决这类问题的行之有效的方法。层次分析法将复杂的决策系统层次化,通过逐层比较各种关联因素的重要性来为分析以及最终的决策提供定量的依据。
三、方法实施步骤
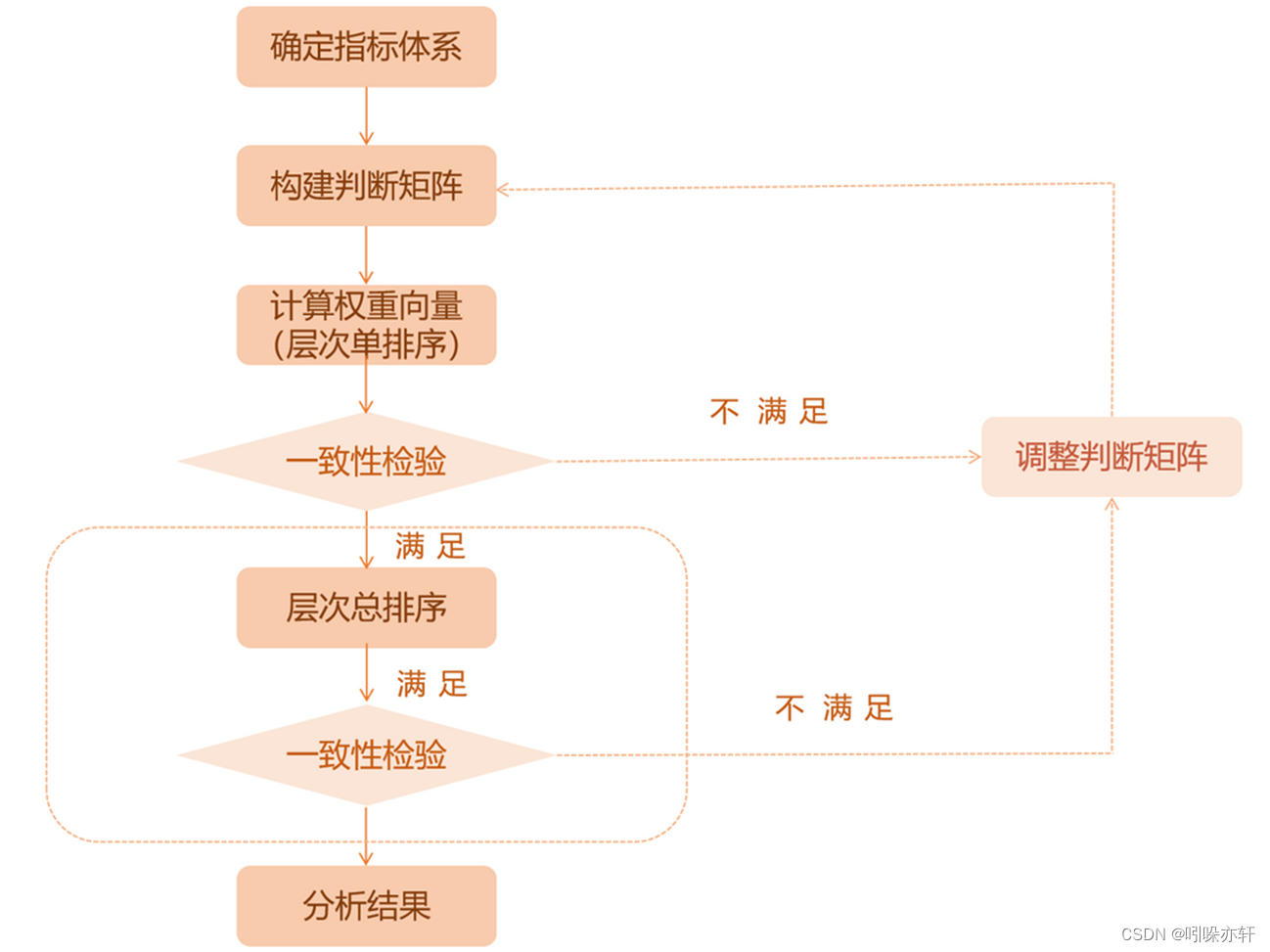
确定指标体系
划分为目标层、准则层、(子准则层)、方案层。
构建判断矩阵
构造判断矩阵就是通过各要素之间相互两两比较,并确定各准则层对目标层的权重。
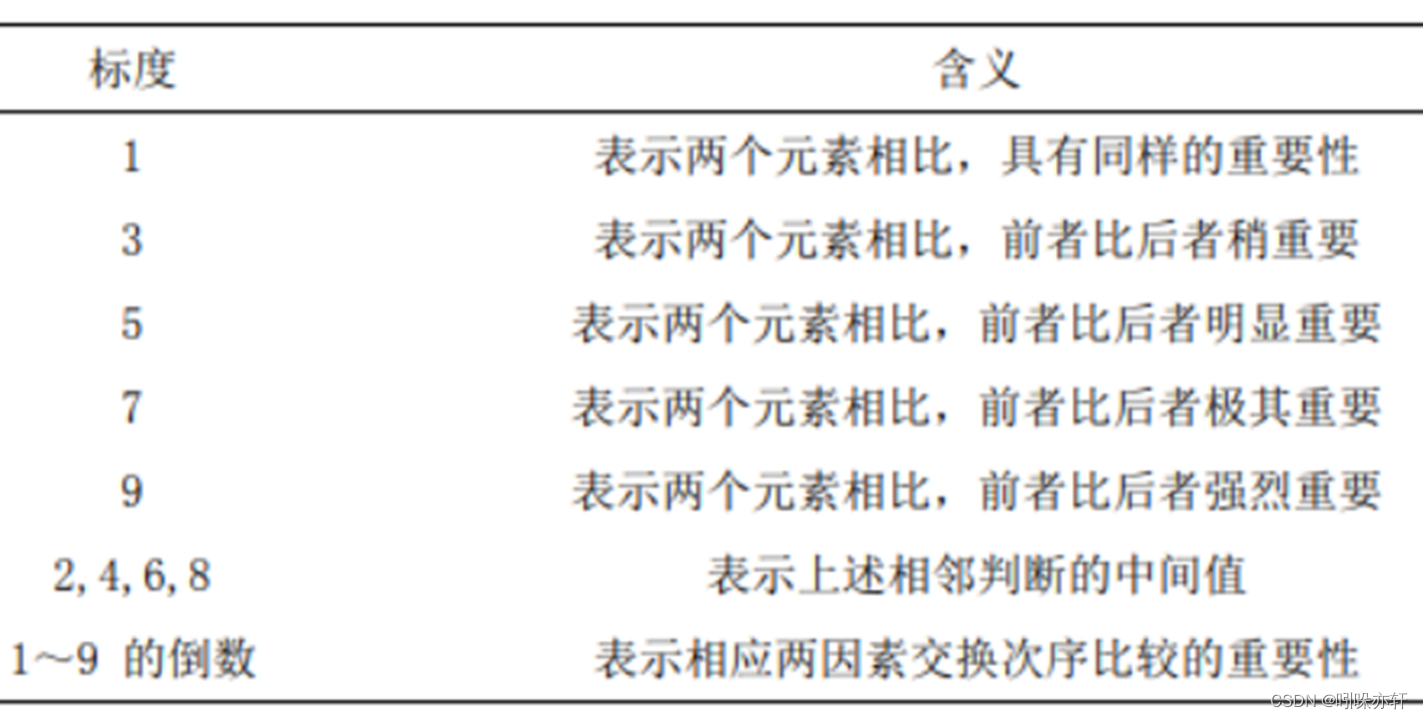
简单地说,就是把准则层的指标进行两两判断,通常我们使用Santy的1-9标度方法给出。
Santy的1-9标度方法
对于准则层A,我们可以构建一个判断矩阵:

在本案例中,判断矩阵如下:
| 指标 | 系统目标 | 系统质量 | 运行效果 | 系统效益 |
| 系统目标 | 1 | 5 | 4 | 3 |
| 系统质量 | 0.2 | 1 | 0.333 | 0.2 |
| 运行效果 | 0.25 | 3 | 1 | 0.333 |
| 系统效益 | 0.333 | 5 | 3 | 1 |
其中元素满足: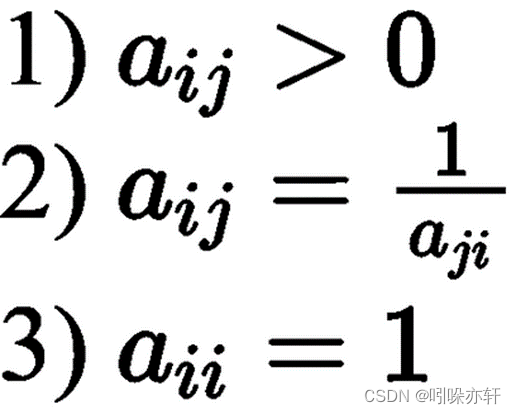
层次单排序
 翻译成比较通俗易懂的语言就是:
翻译成比较通俗易懂的语言就是:
根据我们构成的判断矩阵,求解各个指标的权重。
- 计算权重的方法有三种:①算数平均法(和法)
- ②几何平均法(方根法)
- ③特征值法
接下来,我们来依次介绍:
算术平均法
算数平均法共有三个步骤,数学公式如图所示,我们将用简单易懂的方法逐步求解出各元素的权重。
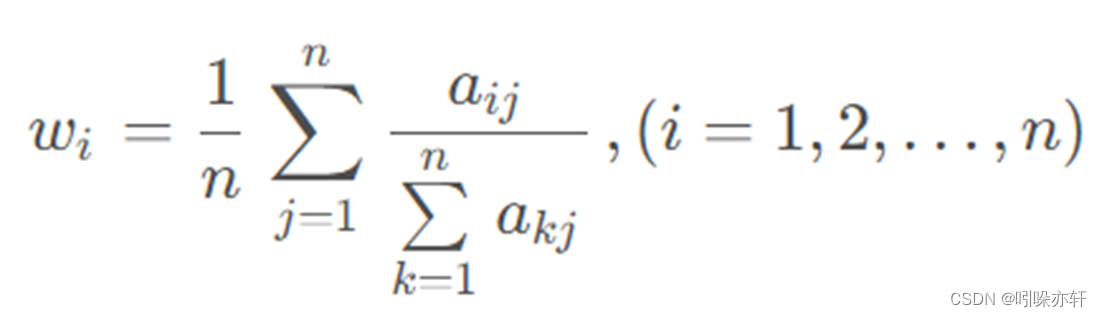
首先,重申一遍,构建的判断矩阵如下:
| 指标 | 系统目标 | 系统质量 | 运行效果 | 系统效益 |
| 系统目标 | 1 | 5 | 4 | 3 |
| 系统质量 | 0.2 | 1 | 0.333 | 0.2 |
| 运行效果 | 0.25 | 3 | 1 | 0.333 |
| 系统效益 | 0.333 | 5 | 3 | 1 |
step1:先将矩阵的每列进行标准化(取列向量的算术平均)
如第一个格子中的0.56=1÷(1+0.2+0.25+0.333)
| 指标 | 系统目标 | 系统质量 | 运行效果 | 系统效益 |
| 系统目标 | 0.56 | 0.35714 | 0.48 | 0.66176 |
| 系统质量 | 0.11215 | 0.07143 | 0.04 | 0.04412 |
| 运行效果 | 0.14019 | 0.21429 | 0.12 | 0.07353 |
| 系统效益 | 0.18691 | 0.35714 | 0.36 | 0.22059 |
step2:将标准化后的各元素按行求和
| 指标 | |
| 系统目标 | 0.56+0.35714+0.48+0.66176=2.0589 |
| 系统质量 | 0.268 |
| 运行效果 | 0.548 |
| 系统效益 | 1.125 |
step3:将求和结果进行标准化
51.491%=2.0589÷(2.0589+0.268+0.548+1.125)
| 指标 | 权重 |
| 系统目标 | 51.491% |
| 系统质量 | 6.692% |
| 运行效果 | 13.7% |
| 系统效益 | 28.116% |
几何平均法
几何平均法共有两个步骤,数学公式如图所示,我们将用简单易懂的方法逐步求解出各元素的权重。

step1:计算每行乘积的m次方根,得到一个m维向量
| 指标 | 系统目标 | 系统质量 | 运行效果 | 系统效益 | |
| 系统目标 | 1 | 5 | 4 | 3 |
|
| 系统质量 | 0.2 | 1 | 0.333 | 0.2 | 0.34 |
| 运行效果 | 0.25 | 3 | 1 | 0.333 | 0.707 |
| 系统效益 | 0.333 | 5 | 3 | 1 | 1.495 |
step2:将向量标准化即为权重向量,即得到权重
| 指标 | 权重 |
| 系统目标 | 52.263% |
| 系统质量 | 6.385% |
| 运行效果 | 13.277% |
| 系统效益 | 28.075% |
特征值法
step1:求出判断矩阵的最大特征值及其对应的特征向量
特征向量与特征值的概念如下:

求特征值的方法如下(令下列矩阵=0,计算):
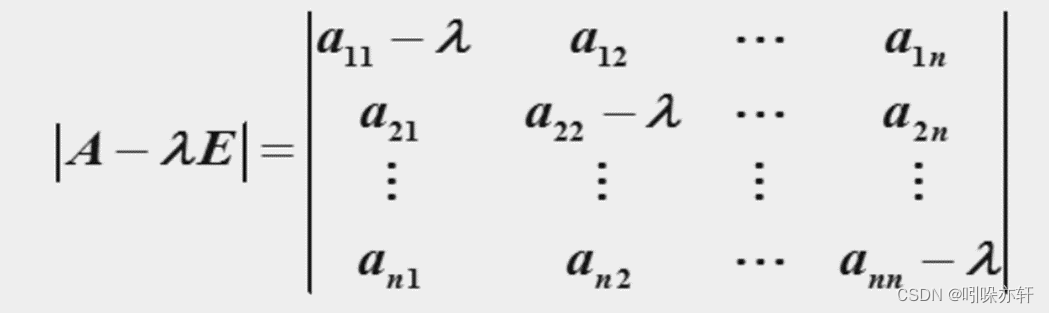
计算得出的特征根如下:
| 最大特征根 |
| 4.189 |
step2:求出特征向量进行归一化,即可得到我们的权重
| 指标 | 权重 |
| 系统目标 | 52.262% |
| 系统质量 | 6.381% |
| 运行效果 | 13.278% |
| 系统效益 | 28.079% |
一致性检验
一致性检验的含义用于确定构建的判断矩阵是否存在逻辑问题,例如以吃饭、睡觉和玩手机构建判断矩阵,判断哪个是当代大学生最喜欢的娱乐活动,若判定‘吃饭’相当于‘睡觉’为3(‘吃饭’比‘睡觉’稍微重要),‘吃饭’相当于‘玩手机’为1/3,那么在判断‘睡觉’和‘玩手机’时,理应玩手机比睡觉重要,因为我们经常上床之后又玩了两三个小时的手机。
若我们在构建判断矩阵时,错误填写为‘睡觉’比‘玩手机’重要,那么就犯了逻辑错误;
公式如下:
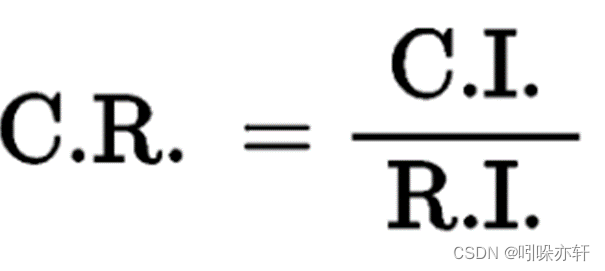
CI (一致性指标)
是度量判断矩阵一致性的指标。它等于(最大特征根-n)/(n-1),其中n是判断矩阵的阶数。
RI (平均随机一致性指标)
是一种用于比较不同阶数的判断矩阵的一致性的指标。它是基于随机生成的判断矩阵的一致性期望值。RI的值可以通过查找RI表(一个标准的参考表)来获取,它根据不同的矩阵阶数给出了RI的值。
CR (一致性比率)
是判断矩阵是否具有满意一致性的指标。如果CR<0.1,则认为判断矩阵的一致性是可以接受的。
如果前面使用了算术平均法和几何平均法,怎么计算得出最大特征根?
其中A指的是判断矩阵
W指的是权重向量:
指标
系统目标
系统质量
运行效果
系统效益
系统目标
1
5
4
3
系统质量
0.2
1
0.333
0.2
运行效果
0.25
3
1
0.333
系统效益
0.333
5
3
1
将相同颜色的相乘得到A*W
指标
权重(W)
系统目标
51.491%
系统质量
6.692%
运行效果
13.7%
系统效益
28.116%
所以AW(按行求和)为:
指标
系统目标
系统质量
运行效果
系统效益
系统目标
0.515
0.335
0.548
0.843
系统质量
0.103
0.067
0.027
0.056
运行效果
0.129
0.201
0.137
0.094
系统效益
0.171
0.335
0.411
0.281
依据公式,最大特征根为: (4.352+3.751+4.095+4.261)/4=4.115
指标
AW
AW/W
系统目标
2.241
4.352
系统质量
0.253
3.751
运行效果
0.561
4.095
系统效益
1.198
4.261
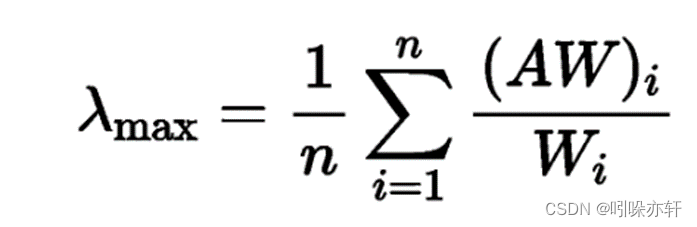
那么,在本案例中:
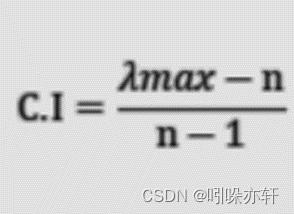
CI=(4.115-4)/3=0.03833333333
RI值通过查表可以得知,这个是SATTY 模拟 1000 次得到的随机一致性指标 R.I.取值表

N=4,取RI为0.90
根据公式:![]()
CR=0.0383333/0.9=0.043<0.1
层次总排序与一致性检验
文献中的说明:
计算某一层次所有因素对于最高层(目标层)相对重要性的权值,称为层次总排 序。该过程是从最高层次向最低层次依次进行:
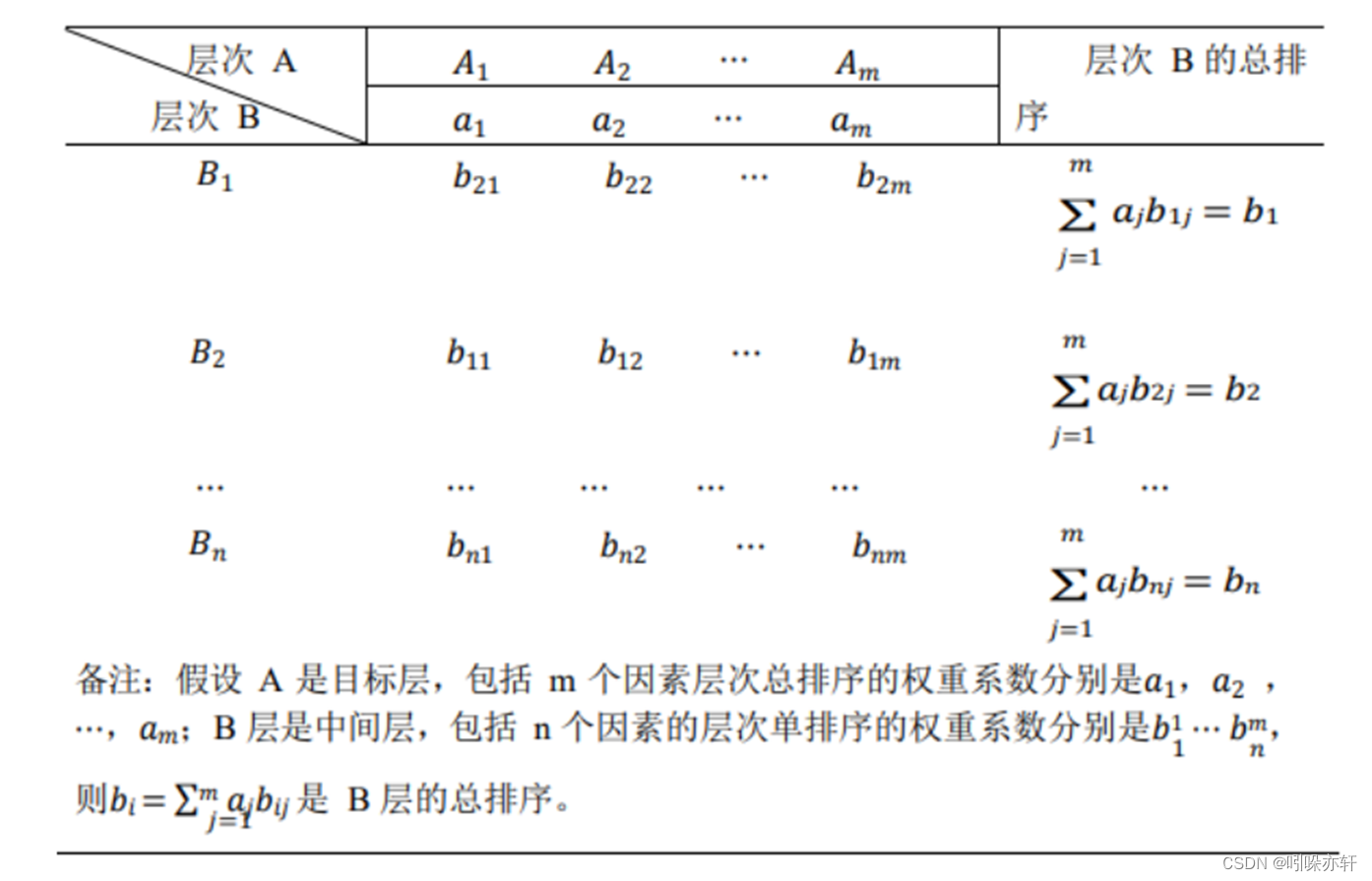
我认为层次总排序就是通过类似层次单排序的方法来给方案打分(为了讲述方便,这里忽略子准则层)。

现在我想要计算新系统1的得分,但是我们并不知道新系统1在系统目标上的得分为多少,那该怎么办呢?
类似先前的层次单排序,对于系统目标等因素,我们可以构建3*3的矩阵,同样用19标度法进行打分。
| 系统目标 | 新系统1 | 新系统2 | 新系统3 |
| 新系统1 | 1 | 2 | 5 |
| 新系统2 | 0.5 | 1 | 2 |
| 新系统3 | 0.2 | 0.5 | 1 |
| 系统质量 | 新系统1 | 新系统2 | 新系统3 |
| 新系统1 | 1 | 0.3333 | 0.125 |
| 新系统2 | 3 | 1 | 0.3333 |
| 新系统3 | 8 | 3 | 1 |
| 运行效果 | 新系统1 | 新系统2 | 新系统3 |
| 新系统1 | 1 | 1 | 3 |
| 新系统2 | 1 | 1 | 3 |
| 新系统3 | 0.3333 | 0.3333 | 1 |
| 系统效益 | 新系统1 | 新系统2 | 新系统3 |
| 新系统1 | 1 | 3 | 4 |
| 新系统2 | 0.3333 | 1 | 1 |
| 新系统3 | 0.25 | 1 | 1 |
模仿层次单排序,计算权重与是否通过一致性检验,过程省略,结果如下:
| 新系统1 | 新系统2 | 新系统3 | CR值 | 一致性检验 | |
| 系统目标 | 0.595 | 0.276 | 0.128 | 0.005 | 通过 |
| 系统质量 | 0.082 | 0.236 | 0.682 | 0.001 | 通过 |
| 运行效果 | 0.429 | 0.429 | 0.143 | 0 | 通过 |
| 系统效益 | 0.634 | 0.192 | 0.174 | 0.009 | 通过 |
准则层的层次单排序如下:

所以最后:
新系统1在系统目标上的得分*系统目标的权重
+新系统1在系统质量上的得分*系统质量的权重
+新系统1在运行效果上的得分*运行效果的权重
+新系统1在系统效益上的得分*系统效益的权重
=新系统1的最终评分
四、总结
优点
缺点
参考:

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)