探索LLM(GPT)、Transformer、LangChain之间的概念及关系“
有时候一下子看到很多专业名称会比较懵,不理解其意义更不理解其相互之间的关系。在刚开始了解的时候就会比较困惑,LLM是什么?Transformers是什么?他们之间是怎样的联系?GPT和LLM的关系又是什么?本文将用通俗易懂的语言帮助业务人员理解其概念及联系通常认为参数量超过10B的模型为大语言模型。这些是通过大量文本数据训练的复杂人工智能模型。它们能理解和生成自然语言,可以用于回答问题、撰写文本、
有时候一下子看到很多专业名称会比较懵,不理解其意义更不理解其相互之间的关系。在刚开始了解的时候就会比较困惑,LLM是什么?Transformers是什么?他们之间是怎样的联系?GPT和LLM的关系又是什么?本文将用通俗易懂的语言帮助业务人员理解其概念及联系
什么是LLM?
通常认为参数量超过10B的模型为大语言模型。这些是通过大量文本数据训练的复杂人工智能模型。它们能理解和生成自然语言,可以用于回答问题、撰写文本、翻译语言等。GPT(生成式预训练变换器)就是一个著名的LLM例子。
LLM的结构?
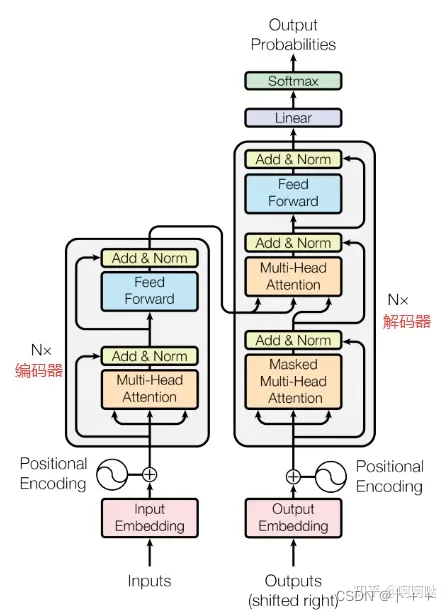
LLM本身基于transformer架构。
大型语言模型(LLM)的结构是相当复杂的,但我我们尝试以简化的方式来解释其核心组成部分。这些模型通常基于一种被称为“Transformer”的神经网络架构。以下是LLM的关键结构要素:
- 输入层:这是模型接收文本数据的部分。文本首先被分割成更小的单元,通常是词或子词(subwords),这些单元被转换成数字形式(通常称为“词嵌入”或“token embeddings”),以便模型可以处理它们。
- Transformer架构:LLM的核心是基于Transformer模型,这是一种专为处理序列数据(例如文本)设计的神经网络。Transformer架构的关键特性包括:
- 自注意力机制(Self-Attention Mechanism):这使得模型能够在处理一个词时,同时考虑到句子中的其他词。这是理解上下文和语言流的关键。
- 多头注意力(Multi-Head Attention):模型在不同的“注意力头”上同时处理信息,每个头关注不同的信息部分。这增强了模型处理复杂语言结构的能力。
- 前馈神经网络:这些网络负责在每个Transformer层中处理数据,提供非线性处理能力,使模型能够学习复杂的语言模式。
- 层堆叠:在Transformer模型中,多个这样的层被堆叠在一起。每一层都包含自注意力和前馈网络,层数越多,模型越能处理复杂的语言结构和含义。
- 输出层:在处理完输入数据之后,模型通过输出层生成文本。在生成任务中,模型通常使用称为“softmax”层的东西,这可以生成下一个最可能的词或词组。
- 参数和训练:LLM拥有极其庞大的参数数量(例如,GPT-3拥有1750亿个参数)。这些参数在训练期间通过大量的文本数据进行调整,以学习语言的结构和用法。
总的来说,LLM的结构允许它学习和理解复杂的语言模式,并在各种任务(如文本生成、翻译、摘要等)中生成高质量的语言输出。
LLM与Transformers之间的关系
现在,用一个通俗的例子来解释LLM和Transformers之间的联系:
- 想象你正在制作一部电影。在这个比喻中,Transformers就像是电影的基本剧本。它规定了故事的基本结构、角色和情节发展,但还没有详细到具体的对话或场景。
- 而LLM(如GPT)就像是根据这个基本剧本制作出来的完整电影。这部电影不仅有了详细的对话、背景音乐、特效和演员的演绎,还融入了导演的独特视角和创意,使得基本的剧本变成了观众可以观看和欣赏的完整作品。
在这个比喻中,Transformers提供了处理和理解语言的基础框架,就像电影的剧本;而LLM则是在这个框架上增加细节和深度,最终创造出能够与人类自然交流的AI,就像将剧本转化为一部精彩的电影。
GPT与LLM之间的关系
LLM是一个广泛的分类,涵盖了所有使用大量数据进行训练的、能够处理和生成自然语言的复杂AI模型。而GPT是这一类模型中的一个特定例子,它使用Transformer架构,并通过大规模的预训练学习语言的模式和结构。
为了更好地理解LLM(大型语言模型)、GPT(Generative Pre-trained Transformer)和Transformer之间的关系,我们可以将它们比作建筑的不同部分。
- Transformer架构:基础结构
- 想象Transformer架构像是建筑的基础结构,比如一座大楼的框架。它提供了基本的支撑和形状,决定了建筑的整体设计和功能。在技术上,Transformer是一种神经网络架构,专为处理序列化数据(如文本)而设计,特别擅长捕捉数据中的长距离依赖关系。
- LLM:整体建筑
- LLM则可以看作是建立在这个框架上的整座建筑。这些建筑不仅有坚固的框架(即Transformer架构),还包括了房间、电梯、装饰等,使得建筑完整、功能丰富。类似地,LLM是使用Transformer架构构建的,通过大量的数据训练,这使得它们能够处理复杂的语言任务,比如文本生成、理解、翻译等。
- GPT:特定类型的建筑
- GPT可以被视为这些大型建筑中的一种特定类型,如一座特别的摩天大楼。它不仅使用了Transformer架构(即基础框架),而且通过特定的方式进行了设计和优化(即大规模的预训练),以实现特定的功能,如高效的文本生成和语言理解。
总结起来,Transformer是基础架构,LLM是建立在这种架构上的一类复杂系统,而GPT是LLM中的一种特定实现,使用了Transformer架构,并通过大量的预训练获得了强大的语言处理能力。这种关系像是建筑基础、整体建筑和特定类型建筑之间的关系。
LLM与LangChain之间的关系
LangChain是一个开源库,用于构建和运行基于语言模型的应用程序。它是由语言模型(如GPT)的用户和开发者设计的,旨在简化大型语言模型(LLM)的使用和集成过程。LangChain的目标是让开发者能够更容易地将语言模型的能力集成到各种应用中,无论是聊天机器人、自动内容生成工具还是其他类型的NLP应用。
LangChain与GPT和其他LLM之间的关系可以用以下方式来理解:
- 工具和应用程序构建:LangChain不是一个独立的语言模型,而是一个工具集,使得开发者可以更容易地构建和部署基于LLM的应用程序。它提供了一系列的功能,如对话管理、信息检索、内容生成等,以利用LLM的能力。
- 中间层:可以将LangChain看作是LLM(如GPT)和最终应用之间的中间层。它帮助处理用户输入,调用合适的语言模型,处理模型输出,使其适用于特定的应用场景。
- 简化集成:LangChain的存在简化了将语言模型如GPT集成到各种应用中的过程。它为开发者提供了一种高效、灵活的方式来利用LLM的强大功能,而无需深入了解其底层的复杂性。
综上所述,LangChain是一个工具和框架,用于促进和简化GPT和其他大型语言模型在各种应用中的使用和集成。它作为一个中间层,允许开发者更容易地利用LLM的强大能力,创建多样化和复杂的NLP应用。
参考文档:LLM学习系列1:大模型架构要点总结

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)