

ELK日志分析系统
ELK是由 ElasticSearch、Logstash 和 Kiabana 三个开源工具所组成, 完成更强大的用户对日志的查询、排序、统计需求。
目录
一、ELK概述
ELK的组成
ELK是由 ElasticSearch、Logstash 和 Kiabana 三个开源工具所组成, 完成更强大的用户对日志的查询、排序、统计需求。
1、ElasticSearch
作用:存储日志数据,创建索引,方便全文检索
elasticsearch是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。
ElasticSearch是使用java开发的,可通过RESTful Web接口,让用户可以通过浏览器与ElasticSearch通信
Elasticsearch是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大容量的日志数据,也可用于搜索许多不同类型的文档。
2、Logstash
作用:负责收集日志数据,通过模块对数据进行过滤、格式化处理,再输出
logstash作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 Elasticsearch。
Logstash 由 Ruby 语言编写,运行在 Java 虚拟机(JVM)上,是一款强大的数据处理工具, 可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
可以添加的其它组件:
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进行解析,或是直接发给 Elasticsearch 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。
filebeat 结合 logstash 带来好处:
1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻 Elasticsearch 持续写入数据的压力
2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
4)使用条件数据流逻辑组成更复杂的处理管道
缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
Fluentd:是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业欢迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。 它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
Logstash配置文件由三部分组成
1)input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等 (file beats kafka redis stdin)
格式如下:
input { #指定两个日志来源
file { path =>"/var/log/messages" type =>"syslog"} #日志来源为syslog
file { path =>"/var/log/httpd/access.log" type =>"apache"} #日志来源apache服务
}
2)filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式。(可选,根据需要选择使用)
filter中的插件有:grok、date、mutate、mutiline
grok:对若干个大文本字段进行再分割成一些小字段
(?<字段名>正则表达式) 字段名: 正则表达式匹配到的内容
mutate:对一些无用的字段进行剔除,或增加字段
mutiline:对多行数据进行统一编排,多行合并或拆分(将多行数据合并在一行显示)
data:对数据中的事件格式化进行统一和格式化
3)output:表示将logstash收集的数据经由过滤器处理之后输出道ElasticSearch。
3、Kiabana
作用:负责从elasticsearch中提取数据,并在web页面进行数据展示
Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
完整日志采集系统基本特征
收集:能够采集多种来源的日志数据
传输:能够稳定的把日志数据解析过滤并传输到存储系统
存储:存储日志数据
分析:支持 UI 分析
警告:能够提供错误报告,监控机制
ELK的工作原理
(1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
(2)Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
(3)Elasticsearch 对格式化后的数据进行索引和存储。
(4)Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示
二、ELK部署
| 主机名 | IP地址 | 部署的应用 |
| node01 | 192.168.30.203 | ElasticSearch、kibana |
| node02 | 192.168.30.104 | ElasticSearch |
| apache | 192.168.30.106 | Logstash、Apache |
环境准备
关闭防火墙和selinux,安装java环境(所有节点上都要做)



node01

node02
![]()
apache

部署ElasticSearch软件
安装elasticsearch—rpm包
将node01软件包传输到node02 opt上 并解压
node01

 node02
node02

修改elasticsearch主配置文件、性能调优并重启生效需重启生效(node01、node02)
node01













node02
![]()









优化elasticsearch用户拥有的内存权限
node01



node02


启动elasticsearch是否成功开启
systemctl start elasticsearch.service
systemctl enable elasticsearch.service
netstat -antp | grep 9200
node01

node02

浏览器访问查看节点信息




安装 Elasticsearch-head 插件
编译安装 node
上传软件包 node-v8.2.1.tar.gz 到/opt
ElasticSearch-head插件部署在node01节点或node02节点任意一个节点上即可
node01


安装 phantomjs 、 Elasticsearch-head 数据可视化工具


修改 Elasticsearch 主配置文件
![]()

启动 elasticsearch-head 服务



通过 Elasticsearch-head 查看 Elasticsearch 信息

插入索引
#通过命令插入一个测试索引,索引为 index-demo,类型为 test。
curl -X PUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
输出结果如下:


Logstash 部署在 Apache 服务器上,用于收集 Apache 服务器的日志信息并发送到 Elasticsearch。
安装Apahce服务(httpd)、Java环境 、logstash





测试 Logstash 定义输入和输出流
logstash -e 'input { stdin{} } output { stdout{} }' 只会在屏幕上输出


使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.30.203:9200"] } }'



修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。(apache服务器)
![]()
![]()




安装 Kiabana(任选一个服务器,这里选择apache服务器)

设置 Kibana 的主配置文件




创建日志文件,启动 Kibana 服务
![]()

验证 Kibana
浏览器访问 http://192.168.30.106:5601
第一次登录需要添加一个 Elasticsearch 索引:
Management -> Index Pattern -> Create index pattern
Index pattern 输入:system-* #在索引名中输入之前配置的 Output 前缀“system”Next step -> Time Filter field name 选择 @timestamp -> Create index pattern
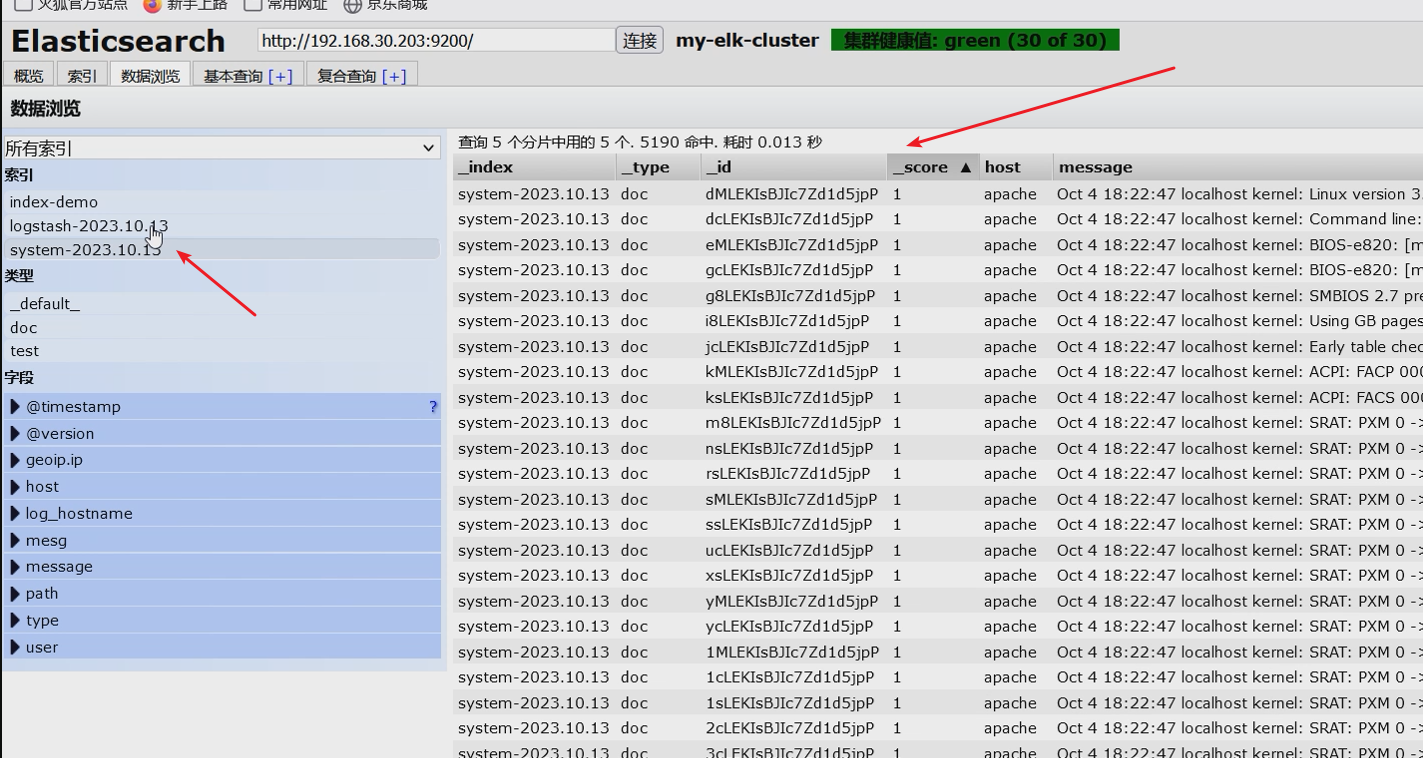
单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果






将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
![]()

cd /etc/logstash/conf.d/
logstash -f apache_log.conf




三、Filebeat+ELK部署
基于上方的ELK的部署,另起一台部署Filebeat 192.168.30.200
安装 Filebeat

设置 filebeat 的主配置文件
![]()


启动 filebeat

在 Logstash 组件所在节点上新建一个 Logstash 配置文件(node01)


启动 logstash
![]()
浏览器访问 http://192.168.30.106:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。




改中文
vim kibana.yml
最后一行改为zh-CN

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)