openGauss学习—— parser.cpp 源码解读
函数的内部逻辑大致为:跳过查询语句前的空格和注释部分(注意注释后也可能有空格,所以需要再次去除空格),若此时查询语句的开头为一个分号,那么判断此为一句空查询,返回true,否则返回false。通过观察注释和具体的代码行为,我们不难理解这个函数的作用:对于多个查询语句所组成的查询语句块,指定位置顺序,取出对应顺序的单个查询语句。接下来循环体的作用是获取多个查询语句组成的语句块中由*stmt_num指
引言
在之前几篇博客中我进行了有关SQL parser词法解析部分内容的学习与总结,并对相关的源文件进行了解析。现在回到原始解析主函数所在的文件parser.cpp,对这一文件的内容进行解析。
文件路径
src\common\backend\parser\parser.cpp
文件内容
先来看文件头部注释:
/* -------------------------------------------------------------------------
*
* parser.cpp
* Main entry point/driver for openGauss grammar
*
* Note that the grammar is not allowed to perform any table access
* (since we need to be able to do basic parsing even while inside an
* aborted transaction). Therefore, the data structures returned by
* the grammar are "raw" parsetrees that still need to be analyzed by
* analyze.c and related files.
*
* 注意在语法解析过程中是不允许获取任何表的访问权限的(因为即便是被
* 中止或废弃的事务也需要进行语法解析过程)。因此,返回的表示查询
* 语法的数据结构是"原始"的语法树,它还需要经过analyze.c以及相关文
* 件的分析。
*
* ……
*
* -------------------------------------------------------------------------
*/文件主要完成了四个函数的定义,下面对他们进行逐一解析。
List* raw_parser(const char* str, List** query_string_locationlist)
static bool is_empty_query(char* query_string)
int base_yylex(YYSTYPE* lvalp, YYLTYPE* llocp, core_yyscan_t yyscanner)
char** get_next_snippet(char** query_string_single, const char* query_string, List* query_string_locationlist, int* stmt_num)
raw_parser()
函数功能:原始(词法和语法)解析过程的主函数。对输入的查询语句进行原始解析,生成对应的语法树并返回。
入口参数:用户发送的查询语句以及查询语句的位置列表。
出口参数:经过原始解析后生成的语法树(raw parse_tree)。
/*
* raw_parser
* 原始解析器
* Given a query in string form, do lexical and grammatical analysis.
* 输入查询字符串,做词法和语法分析
* Returns a list of raw (un-analyzed) parse trees.
* 返回原始语法解析树列表
*/
List* raw_parser(const char* str, List** query_string_locationlist)
{
core_yyscan_t yyscanner; // 定义一个scanner
base_yy_extra_type yyextra; // 与返回的语法树相关
int yyresult; // base_yyparse返回的解析结果
resetOperatorPlusFlag();
resetIsTimeCapsuleFlag();
resetCreateFuncFlag();
/* 初始化 flex scanner */
yyscanner = scanner_init(str, &yyextra.core_yy_extra, ScanKeywords, NumScanKeywords);
yyextra.lookahead_num = 0;
/* 初始化 bison parser */
parser_init(&yyextra);
/* 调用base_yyparse进行解析 */
yyresult = base_yyparse(yyscanner);
/* 清理释放内存*/
scanner_finish(yyscanner);
if (yyresult) { /* 解析产生了错误结果,返回NIL。 */
return NIL;
}
/* 通过lex获取多个查询的位置列表(查询语句终止符的位置)。 */
if (query_string_locationlist != NULL) {
*query_string_locationlist = yyextra.core_yy_extra.query_string_locationlist;
/* 处理用户发出的查询语句结尾处没有分号的情况。 */
if (PointerIsValid(*query_string_locationlist) &&
(size_t)lfirst_int(list_tail(*query_string_locationlist)) < (strlen(str) - 1)) {
*query_string_locationlist = lappend_int(*query_string_locationlist, strlen(str));
}
}
/* 返回经过原始解析产生的语法树 */
return yyextra.parsetree;
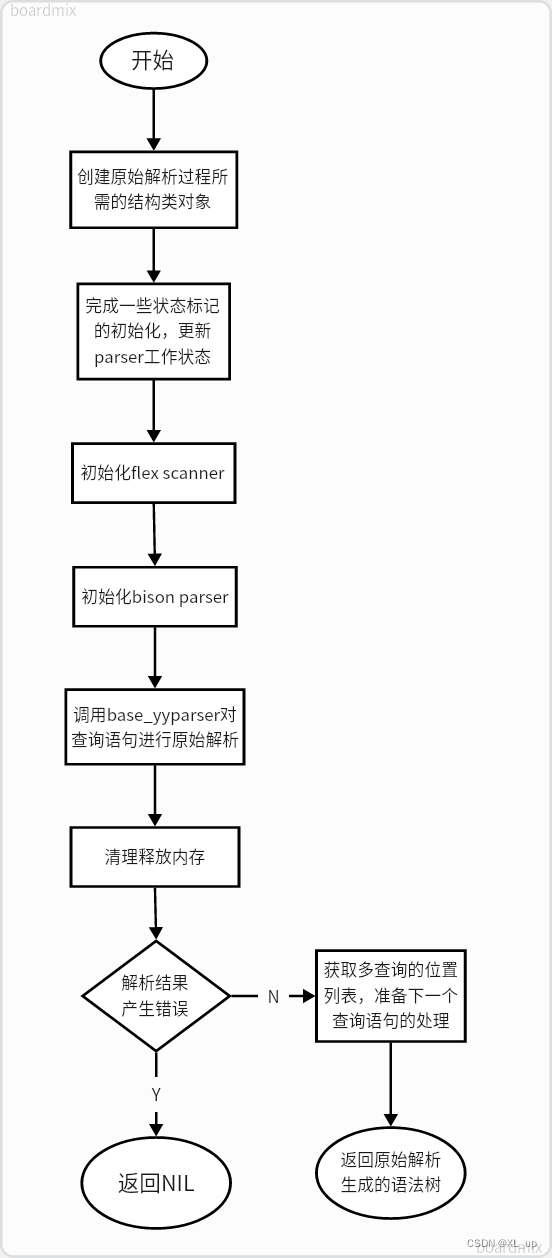
}函数运行流程详解:
- 创建词法、语法解析所必须的结构类对象,这些对象与scanner及原始解析的结果相关;
- 将若干状态bool标记的值置为false,完成raw_parser数据初始化;
- 初始化flex scanner;
- 初始化bison parser;
- 调用base_yyparser对用户发出的查询语句进行解析。base_yyparser会利用flex&bison工具对查询语句进行词法及语法的分析(原始解析)。
- 解析过程结束后,清理释放内存;
- 如果解析失败(即输入的语句存在词法或语法错误),返回NIL值将错误信号报告给调用者;
- 若解析成功,raw_parser为下一条查询语句的原始解析做准备,这需要获取用户发出的多个查询语句的位置列表。同时此处也会完成对用户发送的查询语句不以分号结尾的情况的处理。
- 上述步骤完成后,返回原始解析所生成的查询语句对应的语法树。语法树仍需通过analyze.cpp等相关文件对其进行语义分析。
函数的运行流程图绘制如下:
is_empty_query()
/*
* @Description: Check whether its a empty query with only comments and semicolon.
* @Param[IN] query_string: the query need check.
* @return:the bool value of the check result.
*/
static bool is_empty_query(char* query_string)
{
char begin_comment[3] = "/*";
char end_comment[3] = "*/";
char empty_query[2] = ";";
char* end_comment_postion = NULL;
/* Trim all the spaces at the begin of the string. */
/* 删除查询语句前的无效空格。 */
while (isspace((unsigned char)*query_string)) {
query_string++;
}
/* Trim all the comments of the query_string from the front. */
/* 删除查询语句前的注释。 */
while (strncmp(query_string, begin_comment, 2) == 0) {
/*
* As query_string have been through parser, whenever it contain the begin_comment
* it will comtain the end_comment and end_comment_postion can't be null here.
* 既然查询语句已经通过语法检查,那么若其有注释开头就必然有注释结尾。
* 那么注释结尾处的位置就不可能是空值null。
*/
end_comment_postion = strstr(query_string, end_comment);
query_string = end_comment_postion + 2;
while (isspace((unsigned char)*query_string)) {
/* 去除注释后的空格。 */
query_string++;
}
}
/* Check whether query_string is a empty query. */
/* 删除查询语句前的空格和注释后,如果其仅包含一个分号则说明为空的查询语句。 */
if (strcmp(query_string, empty_query) == 0) {
return true;
} else {
return false;
}
}函数的功能和结构十分简单,即针对一条查询语句判断其是否为空查询。函数的内部逻辑大致为:跳过查询语句前的空格和注释部分(注意注释后也可能有空格,所以需要再次去除空格),若此时查询语句的开头为一个分号,那么判断此为一句空查询,返回true,否则返回false。
函数 get_next_snippet()
功能描述:从多个查询语句组成的查询语句块中取出单个的查询语句。
入口参数: query_string_single:若干单个的查询语句。数据类型为char**。 query_string:初始的包含多个语句的查询语句块。
query_string_locationList:记录单个查询语句的终止符-分号的位置。 stmt_num:需要获取的查询语句在语句块中的位置顺序。
出口参数: query_string_single:记录每个查询语句的起点位置。
函数源码及注释如下:
/*
* @Description: split the query_string to distinct single querys.
* @Param [IN] query_string_single: store the splited single querys.
* @Param [IN] query_string: initial query string which contain multi statements.
* @Param [IN] query_string_locationList: record single query terminator-semicolon locations which get from lexer.
* @Param [IN] stmt_num: show this is the n-ths single query of the multi query.
* @return [IN/OUT] query_string_single: store the point arrary of single query.
* @NOTICE:The caller is responsible for freeing the storage palloced here.
*
* @功能描述:从多个查询语句组成的查询语句块中取出单个的查询语句。
* @入口参数:
* query_string_single:若干单个的查询语句。数据类型为char**。
* query_string:初始的包含多个语句的查询语句块。
* query_string_locationList:记录单个查询语句的终止符-分号的位置。
* stmt_num:需要获取的查询语句在语句块中的位置顺序。
* @出口参数:
* query_string_single:记录每个查询语句的起点位置。
*
*/
char** get_next_snippet(
char** query_string_single, const char* query_string, List* query_string_locationlist, int* stmt_num)
{
int query_string_location_start = 0; // 查询语句的起始位置
int query_string_location_end = -1; // 查询语句终止位置
char* query_string_single_p = NULL; // 用以拷贝字符串的中间变量
int single_query_string_len = 0; // 查询语句的长度
/* 计算查询语句的个数 */
int stmt_count = list_length(query_string_locationlist);
/* Malloc memory for single query here just for the first time. */
/* 为返回指针(char类型二维数组存储的查询语句)动态分配内存。 */
if (query_string_single == NULL) {
query_string_single = (char**)palloc0(sizeof(char*) * stmt_count);
}
/*
* Get the snippet of multi_query until we get a non-empty query as the empty query string
* needn't be dealed with.
* 获取多个查询语句组成的语句块中由*stmt_num指定的那一条查询语句,同时空的查询语句不需处理。
* 由is_empty_query()来实现空查询判断逻辑。
*/
for (; *stmt_num < stmt_count;) {
/*
* Notice : The locationlist only store the end postion of each single query but not any
* start postion.
* 注意:位置列表locationlist中仅存放每个查询语句的结束位置而不记录其开始位置。
*/
/* 计算指定查询语句的起始位置 */
if (*stmt_num == 0) {
query_string_location_start = 0;
} else {
query_string_location_start = list_nth_int(query_string_locationlist, *stmt_num - 1) + 1;
}
/* 获取指定查询语句的结束位置 */
query_string_location_end = list_nth_int(query_string_locationlist, (*stmt_num)++);
/* Malloc memory for each single query string. */
/* 为返回结果中的单个查询语句(二维数组的行向量)动态分配内存。 */
single_query_string_len = query_string_location_end - query_string_location_start + 1;
query_string_single[*stmt_num - 1] = (char*)palloc0(sizeof(char) * (single_query_string_len + 1));
/* Copy the query_string between location_start and location_end to query_string_single. */
/* 获取指定的查询语句串,拷贝到返回结果中。 */
query_string_single_p = query_string_single[*stmt_num - 1];
while (query_string_location_start <= query_string_location_end) {
*query_string_single_p = *(query_string + query_string_location_start);
query_string_location_start++;
query_string_single_p++;
}
/*
* If query_string_single is empty query which only contain comments or null strings,
* we will skip it.
* 如果获取到的查询语句是空查询语句,则放弃本次拷贝结果,获取其之后的一条查询语句。
*/
if (is_empty_query(query_string_single[*stmt_num - 1])) {
continue;
} else { // 获取到的查询语句不为空查询,退出循环,返回这条语句。
break;
}
}
return query_string_single;
}函数的逻辑结构是较为简单的。通过观察注释和具体的代码行为,我们不难理解这个函数的作用:对于多个查询语句所组成的查询语句块,指定位置顺序,取出对应顺序的单个查询语句。本函数应当配合调用者完成对用户输入的连续多个查询请求进行分隔和逐一执行的任务。
函数定义了5个局部变量,依次分别起到如下作用:query_string_location_start记录一条查询语句的起始位置,query_string_location_end 记录查询语句的终止位置; query_string_single_p 是一个char类型指针变量,其指向的内存区域用以参与字符串的拷贝工作;single_query_string_len表示查询语句的长度。stmt_count用以计算查询语句块中单个查询语句的总数量。
获取到的单个查询语句存放在二维指针query_string_single所指向的内存区域中,因此当获取工作结束后进行字符串拷贝工作之前,应当先为相应的指针申请开辟内存空间。
接下来循环体的作用是获取多个查询语句组成的语句块中由*stmt_num指定的那一条查询语句,如果获取成功,进行拷贝工作。另外如果获取到的查询语句为空语句,则舍弃本次获取结果,重新进入循环体以获取其后的一条查询语句。
对于查询语句是否为空查询的判断工作由is_empty_query()函数来实现。
base_yylex()
/*
* Intermediate filter between parser and core lexer (core_yylex in scan.l).
* 介于parser和核心lexer之间的语法过滤器。
*
* The filter is needed because in some cases the standard SQL grammar
* requires more than one token lookahead. We reduce these cases to one-token
* lookahead by combining tokens here, in order to keep the grammar LALR(1).
* 在某些情况下标准SQL语法包含了多于一个的前缀token,因此filter的设置是必要的
* 通过过滤器对多个token进行结合分析可以将多前缀token转化为只有单个前缀的token。
*
* Using a filter is simpler than trying to recognize multiword tokens
* directly in scan.l, because we'd have to allow for comments between the
* words. Furthermore it's not clear how to do it without re-introducing
* scanner backtrack, which would cost more performance than this filter
* layer does.
* 使用filter比直接在scan.l中识别多个前缀的tokens更加简便,这是因为
* 在连续的词语之间可能存在注释。不仅如此,如何在不重新引入scanner的情
* 况下进行回溯也是不明晰的,这也许会造成更大的性能开销。
*
* The filter also provides a convenient place to translate between
* the core_YYSTYPE and YYSTYPE representations (which are really the
* same thing anyway, but notationally they're different).
*/
int base_yylex(YYSTYPE* lvalp, YYLTYPE* llocp, core_yyscan_t yyscanner)
{
/* 数据的声明和初始化 */
//……
/* 获取下一个token的值 */
if (yyextra->lookahead_num != 0) {
//……
} else {
cur_token = core_yylex(&(lvalp->core_yystype), llocp, yyscanner);
}
/* 分析所有需要处理的token的情况。 */
switch (cur_token) {
case NULLS_P:
/*
* NULLS FIRST and NULLS LAST must be reduced to one token
*/
GET_NEXT_TOKEN();
switch (next_token) {
case FIRST_P:
cur_token = NULLS_FIRST;
break;
case LAST_P:
cur_token = NULLS_LAST;
break;
default:
/* save the lookahead token for next time */
SET_LOOKAHEAD_TOKEN();
/* and back up the output info to cur_token */
lvalp->core_yystype = cur_yylval;
*llocp = cur_yylloc;
break;
}
break;
//……
default:
break;
}
return cur_token;
}函数的内部细节较为复杂,但他所实现的逻辑功能是十分明晰的。通过阅读注释和代码行为我们可以得知,函数是介于parser和核心lexer之间的一个“语法过滤器”;
在SQL语法解析过程中,有些关键字当他们组合在一起的时候,如果仅由gram.y来负责解析,是会导致gram.y程序行为异常,解析出错的情况。因此,当这些关键字连续出现时,将他们合并成一个关键字是必要的(尽管在用户发送请求时仍按照原先的形式发送)。另外,将多个关键字组合成一个新的关键字一定程度上也可以减轻语法分析器的负担。
例如,声明游标的语句declare cursor……,尽管在用户使用此语句进行查询时declare和cursor是连续的两个关键字,但在语法解析过程中可以将其视为declare_cursor一个关键字,这样就完成了token的合并。再比如,如果查询语句中包含了…NULLS <关键字>…这样的内容,就可以根据关键字的值将其与NULLS进行合并为一个关键字,例如NULLS FIRST合并为NULLS_FIRST,NULLS LAST合并为NULLS_LAST,这样就不需要对NULLS和FIRST/LAST分别做解析以匹配相应的功能。
NULLS FIRST/LAST语句用于指定查询结果的排序(order by)顺序,默认为”NULLS LAST”,即空值默认排在结果的尾部。通过指定NULLS FIRST也可使空值排在结果的头部。
简单总结来说,函数的功能就是使得连续几个关键字的 token简化成一个,构成一个新的关键字,但这个关键字对于用户是不可视的。通过这样的处理,可以规避gram.y在语法解析过程中可能出现的错误行为,同时关键字的减少也可以为语法解析器的工作减轻负担。

鲲鹏展翅 立根铸魂 深耕行业数字化
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)