
偏度系数和峰度系数——三/四阶中心矩
是指一组数据的第三阶矩与均值的立方之差,用于衡量数据的偏斜程度。计算三阶中心矩的公式为:其中,xi是数据中的每一个值,μ是数据的均值,n是数据的数量。例如,假设有一组数据:2, 4, 6, 8, 10,可以计算其三阶中心矩:计算均值:μ = (2 + 4 + 6 + 8 + 10) / 5 = 6计算每个值与均值的差的立方:(2 - 6)^3 = -64, (4 - 6)^3 = -8, (6 -
三阶中心矩
是指一组数据的第三阶矩与均值的立方之差,用于衡量数据的偏斜程度。
计算三阶中心矩的公式为:
M3 = Σ(xi - μ)^3 / n
其中,xi是数据中的每一个值,μ是数据的均值,n是数据的数量。
例如,假设有一组数据:2, 4, 6, 8, 10,可以计算其三阶中心矩:
计算均值:μ = (2 + 4 + 6 + 8 + 10) / 5 = 6
计算每个值与均值的差的立方:(2 - 6)^3 = -64, (4 - 6)^3 = -8, (6 - 6)^3 = 0, (8 - 6)^3 = 8, (10 - 6)^3 = 64
计算三阶中心矩:M3 = (-64 - 8 + 0 + 8 + 64) / 5 = 0
因此,这组数据的三阶中心矩为0。
偏度系数(skewness)
- 偏度定义中包括:
正态分布(偏度=0)、
右偏(尾巴右偏)分布(也叫正偏分布,偏度>0),
左偏(尾巴左偏)分布(也叫负偏分布,其偏度<0)。
偏度系数是描述数据偏斜程度的统计量,是分布的不对称度量值,可以通过三阶中心矩计算。
计算偏度系数的公式为:
偏度系数 = 三阶中心矩 / 标准差的立方,
其中,三阶中心矩的计算公式为:
三阶中心矩 = Σ(xi - μ)^3 / n
其中,xi是数据中的每一个值,μ是数据的均值,n是数据的数量。
因此,计算偏度系数的完整公式为:
偏度系数 = Σ(xi - μ)^3 / (n * σ^3),其中,σ是数据的标准差。

纠误★
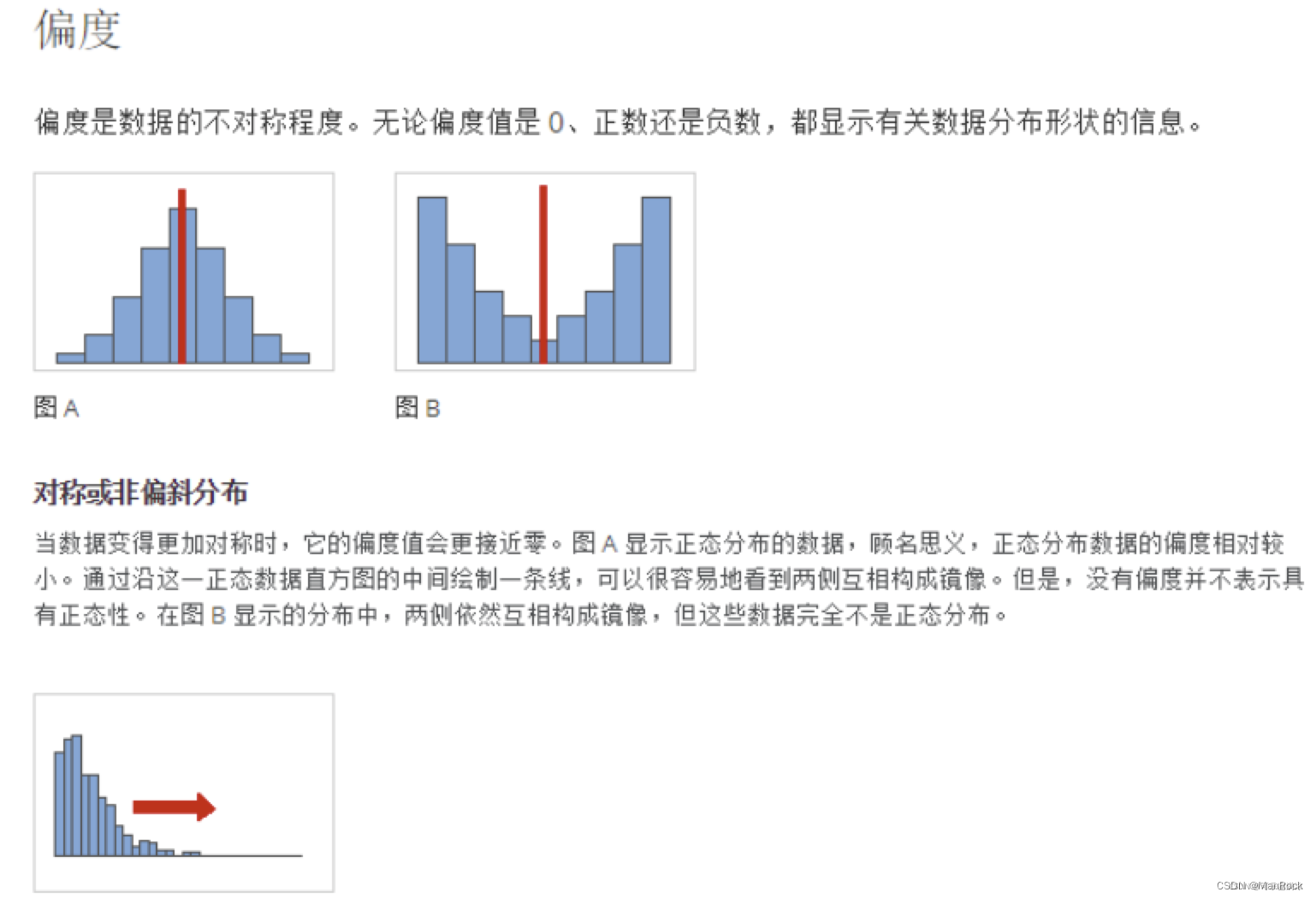
下图1 给出的是样本容量均为100 的2 组样本的频数直方图.从直观上看,图1b 的分布较图1a 在众数两边似乎更为偏斜,但图1a 和图1b 的样本偏度值分别为2.420 2 和0.729 0,即图1a 的偏度明显大于图1b 的偏度,其原因就在于前者的分布较后者在右方向的尾部有更明显的拉长趋势.本例也说明了将偏度理解为反映分布在众数两边的对称偏斜性的一个量是欠妥当的.
实际上,
分布在众数两边的对称偏斜性对偏度值的影响是比较有限的,对偏度值影响较大的倒是分布在其中一个方向上的尾部有拉长趋势的程度。
因此,正( 负) 偏度往往更多反映的是分布在右( 左) 方向的尾部比在左( 右) 方向的尾部有拉长的趋势。
峰度系数(kurtosis)
峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度 。样本的峰度是和正态分布相比较而言统计量,如果峰度大于三,峰的形状比较尖,比正态分布峰要陡峭。反之亦然。——来自百度百科
峰度系数 = (四阶中心矩 / 方差的平方)- 3
所以取值范围是[-3, +∞)
随机变量X 的峰度,度量了分布尾部相对于正态分布而言的重轻(厚薄).
若 > 0,则说明X 的分布的尾部比正态分布的尾部重;
若 < 0,则说明X 的尾部比正态分布轻.
峰度常被学生理解为是描述一个分布相对于正态分布陡峭程度的量.事实上,这种理解是不正确的.
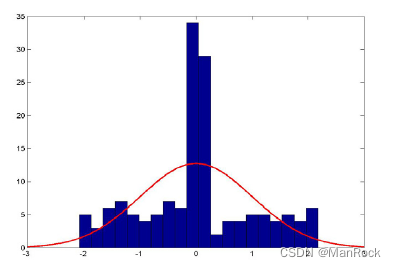
图2 是容量为150 的样本数据经标准化后所得的频数直方图,同时也给出了拟合的正态曲线图.
从图2 中可以看出,分布在众数附近“峰”的陡峭程度要远高于正态分布.
但是,经计算样本的峰度值为κˆ = − 0.232 0,小于正态分布的峰度值0.
这里κˆ < 0是因为这组数据的两侧尾部比正态分布轻.
https://youtu.be/TM033GCU-SY
Key Insights 关键见解
- 📈 Kurtosis was traditionally defined as the “peakedness” of a distribution, but recent research shows that it is more about the thickness of the tails and the presence of outliers.
- 📈 峰度传统上被定义为分布的“峰值”,但最近的研究表明,它更多地与尾部的厚度和异常值的存在有关。
This challenges the common understanding of kurtosis. - 📊 The calculation of kurtosis involves the fourth standardized moment, which measures the difference from the mean to the power of four, divided by the standard deviation to the power of four.
这挑战了对峰度的普遍理解。 - 📊 峰度的计算涉及第四个标准化矩,它测量从平均值到四的幂的差,除以标准差到四的幂。
Adjustments are made for sample data. - 📉 Kurtosis ranges from 1 to infinity, with a normal distribution having a kurtosis of 3. Distributions with higher kurtosis have thicker tails and potentially more outliers, while distributions with lower kurtosis have flatter peaks and shorter tails.
- ❗️ The controversy surrounding kurtosis arises from the misconception that peakedness directly affects kurtosis.
对样本数据进行调整。 - 📉 峰度范围从 1 到无穷大,峰度为 3 的正态分布。峰度较高的分布具有较厚的尾部和可能更多的异常值,而峰度较低的分布具有更平坦的峰值和较短的尾部。
- ❗️ 围绕峰度的争议源于峰值直接影响峰度的误解。
In reality, the presence of outliers and the thickness of the tails play a more significant role in determining kurtosis. - 📐 While the calculation of kurtosis can provide information about the distribution, it is important to understand that it does not solely indicate peakedness.
实际上,异常值的存在和尾巴的厚度在确定峰度方面起着更重要的作用。 - 📐 虽然峰度的计算可以提供有关分布的信息,但重要的是要了解它并不仅仅表示峰值。
The idea of peakedness is more related to the common characteristics of distributions rather than the calculation of kurtosis itself.
峰值的概念更多地与分布的共同特征有关,而不是峰度本身的计算。
总结
Kurtosis is a statistical measure that traditionally measures the “peakedness” of a distribution, but recent research shows that it is more about the thickness of the tails and the presence of outliers.
峰度是一种统计度量,传统上衡量分布的“峰值”,
峰度是衡量数据相对于正态分布是重尾还是轻尾的度量。
也就是说,
具有高峰度的数据集往往具有较重的尾部或异常值。
峰度较低的数据集往往有轻微的尾部,或者缺乏异常值。
它★★★更多的是关于尾巴的①厚度和②异常值的存在★★★。
The calculation of kurtosis can help differentiate between different distributions, but it does not necessarily indicate the peakedness of a distribution.
峰度的计算可以帮助区分不同的分布,但它并不一定表明分布的峰值。
调用
scipy或pandas
另外,pandas可以通过rolling直接计算滚动偏度系数和风度系数
纠误
差异是由于不同的归一化造成的。默认情况下,Scipy 不会纠正偏见,而 pandas 会。
可以通过传递参数来告诉 scipy 纠正偏差:bias=False
在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/33109107/
Skewness and Kurtosis : the two summary stats they never taught you
概要
统计学中的平均值只能告诉我们分布的中心,但无法提供更丰富的信息。
标准差可以告诉我们数据的离散程度,帮助我们了解平均值的不确定性。
偏度可以告诉我们分布的偏斜程度,即数据分布的不对称性。
峰度可以告诉我们分布的尾部厚度,即数据分布的尾部异常情况。
亮点
📈 平均值
只能提供有限的信息,标准差、偏度和峰度可以提供更全面的数据分布情况。
标准差帮助我们了解数据的离散程度,偏度和峰度帮助我们了解分布的偏斜和尾部异常情况。
📊 标准差
标准差可以告诉我们数据的离散程度,帮助我们了解平均值的不确定性。
📈 偏度
偏度可以告诉我们分布的偏斜程度,即数据分布的不对称性。
📉 峰度
峰度可以告诉我们分布的尾部厚度,即数据分布的尾部异常情况。
参考文献
1、偏度和峰度概念的认识误区_王学民
2、关于数理统计中若干基本概念的理解_何道江
3、https://www.scribbr.com/statistics/kurtosis/

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)