
中介效应的原理与检验
中介效应检验
原理
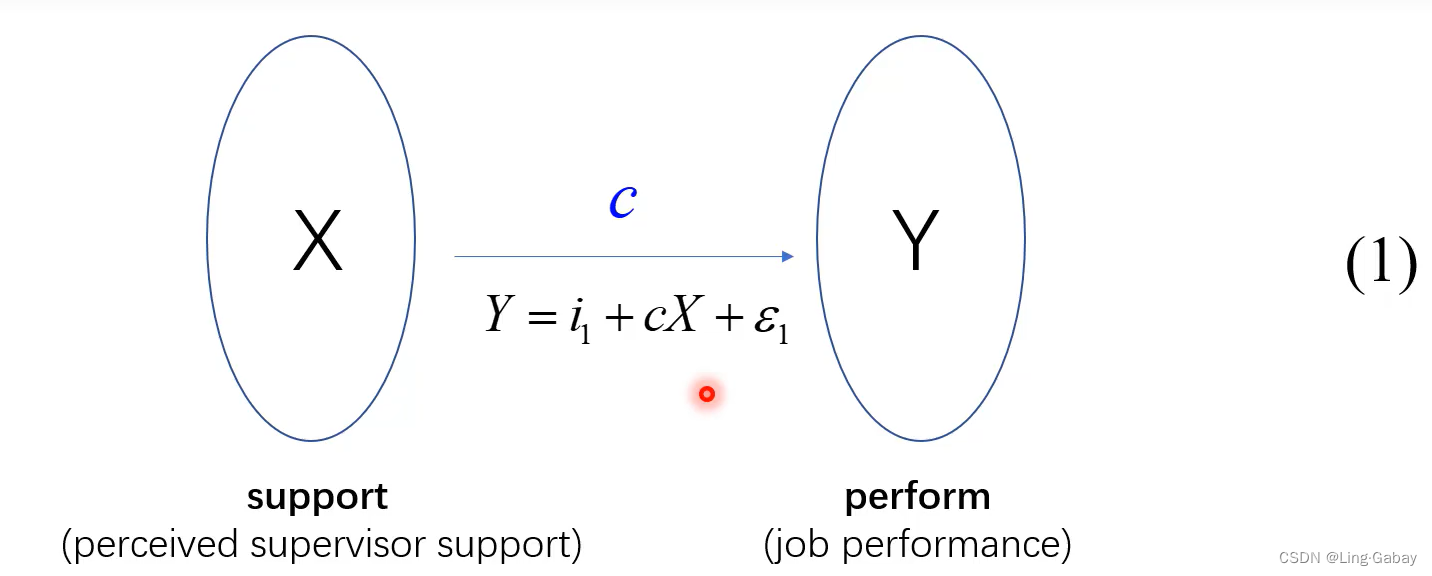
总效应:当什么中介变量的不放(控制变量可以放),直接研究X对Y的影响:
经济学一般称中介效应(心理学上提出)为“机制分析”或“机制检验” 。在经济学中,通常需要检验X对Y的因果作用,如果X影响Y的因果链条比较长,这时候就需要做机制分析,验证X是通过什么传导机制(哪些中介变量)来影响Y,以增强因果关系的可信度。
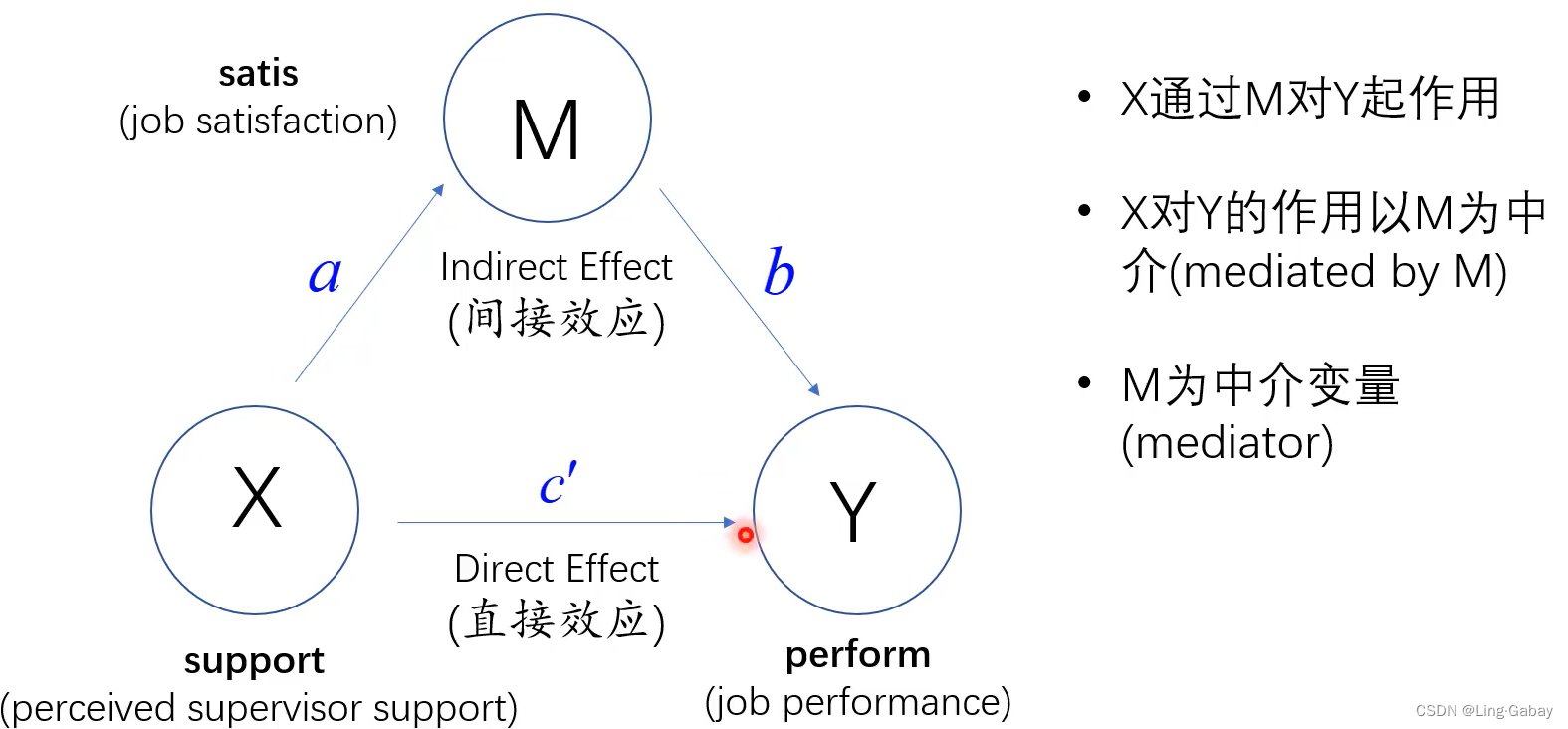
这时候就建立起X到M的因果链条,M到Y的因果链条。
检验方法
1.逐步因果法(casual steps approach)
2.系数差异法(difference of coefficients method)
3.系数乘积法(product of coefficients method,Sobel test)
逐步因果法
操作
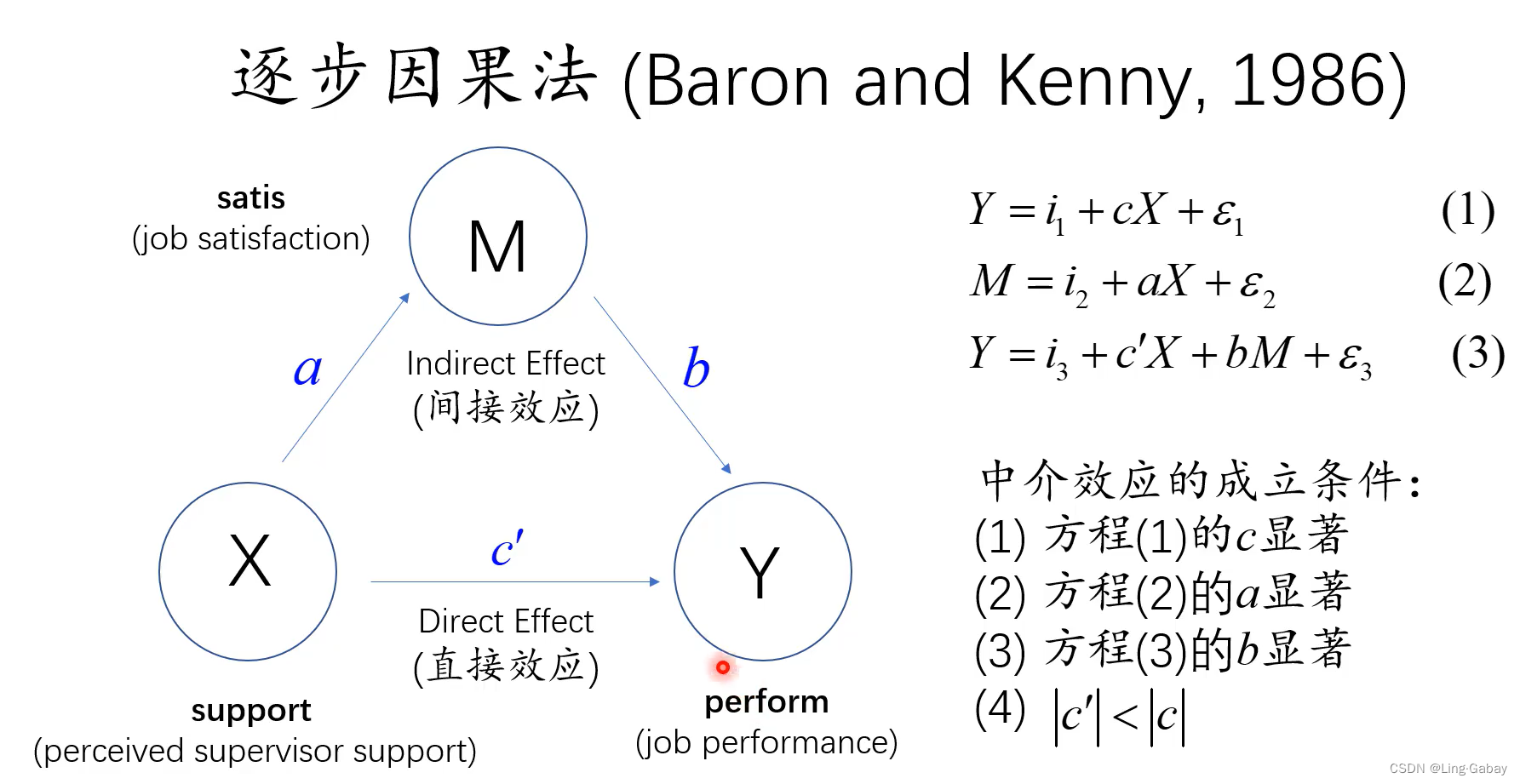
第一个回归:首先单独将Y对X做回归,不放入任何中介变量(可以放控制变量),得到X对Y的总效应 。
第二个回归:接着将中介变量M对X做回归,因为如果中介效应成立,那么X必然显著地影响到M,得到回归系数。
第三个回归:最后将Y同时对解释变量X和中介变量M做回归,X前的系数就是将M的间接作用控制后X对Y的直接效应,M前的系数
就是中介变量对Y的影响。
检验
(1)第一个回归中的显著,如果总效应都不显著,那么探讨X对Y的中介效应意义不大。后来学者提出可能直接效应和间接效应的方向相反,或者可能有多个中介变量,不同的变量同时起作用,而且作用的方向相反则可能会抵消,如果抵消得足够多,则总效应也会不显著。故第一个条件不那么重要。
(2)第二个回归中的显著,即X到M的链条必须存在。
(3)第三个回归中的显著,即M到Y得链条必须存在。
(4),即直接效应作为总效应的一部分,数值上会小于总效用的数值。
分类
(1)如果(直接效应为0),则称为“完全中介”(complete mediation)。
(2)如果(直接效应不为0),则称为“部分中介”(partial mediation)。
Q:总效应方程(1)是否有遗漏变量偏差?
A:只要方程(2)和方程(3)没有遗漏变量,得到的是一致估计,则方程(1)就能够得到一致估计。可以将方程(2)带入方程(3),可以得到:

只要方程(2)中和X无关,方程(3)中
和X无关,那么带入后新的扰动项也会和X无瓜,则方程(1)也是一致的。
系数差异法
如果中介效应存在,则(3)中的应该只是(1)中
的一部分,如果两个完全相等,则这个中介效应不起作用,因次可以通过
和
之间的差别来判断是否存在中介效应。
原假设:(不存在中介效应)
构造统计量:
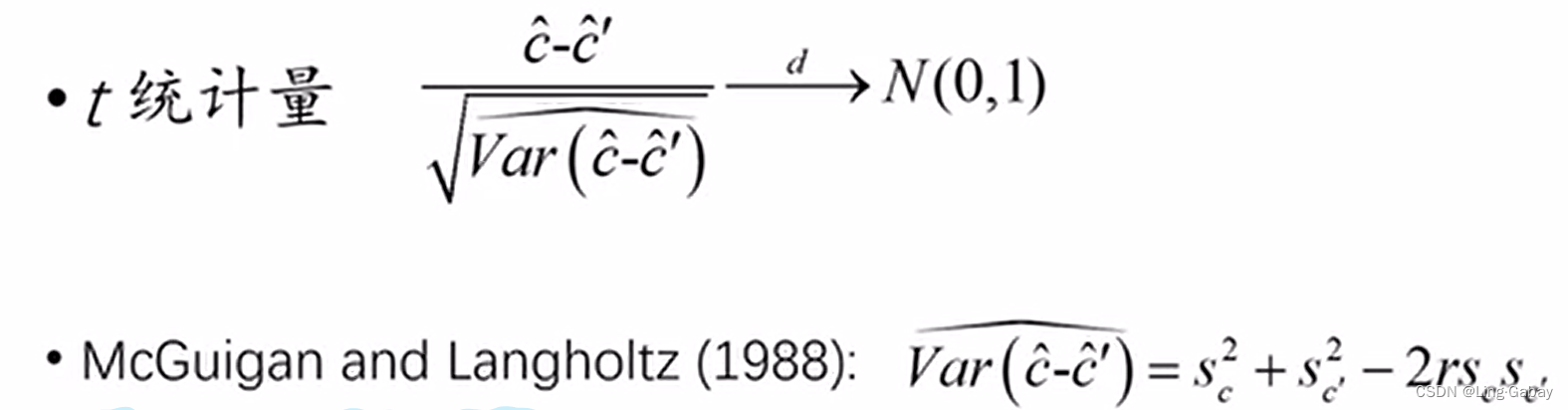
分母为和
之差的标准差,同样做以上(1)和(3)回归,得到两个系数的标准差,
为两者的相关系数。最后构造出来的
统计量服从正态分布,然后查看正态分布的临界值,看是否通过
检验。
系数乘积法
如果要判断中介效应是否存在,则上述和
需要同时不为0才可以。


 最后得到的
最后得到的可以用样本方差替代,
可以用
(拟合值)替代。

大样本情况下,上述统计量都一致,样本小的情况下用自助法。

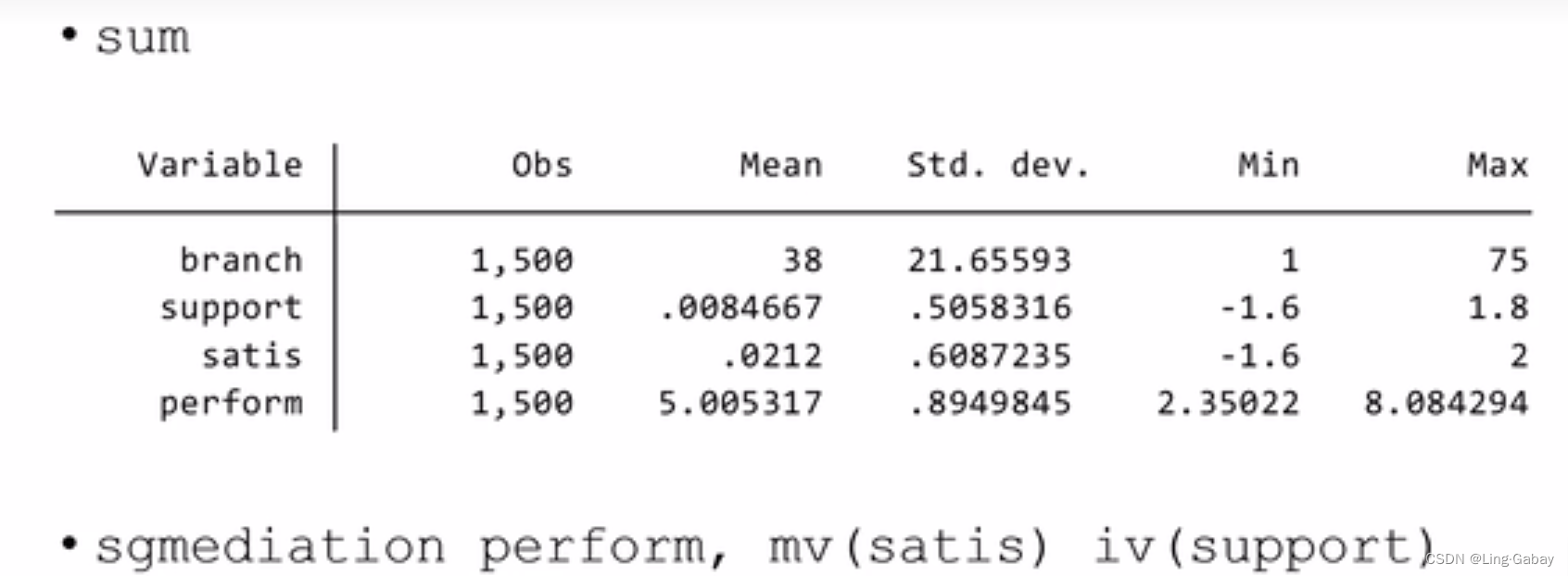
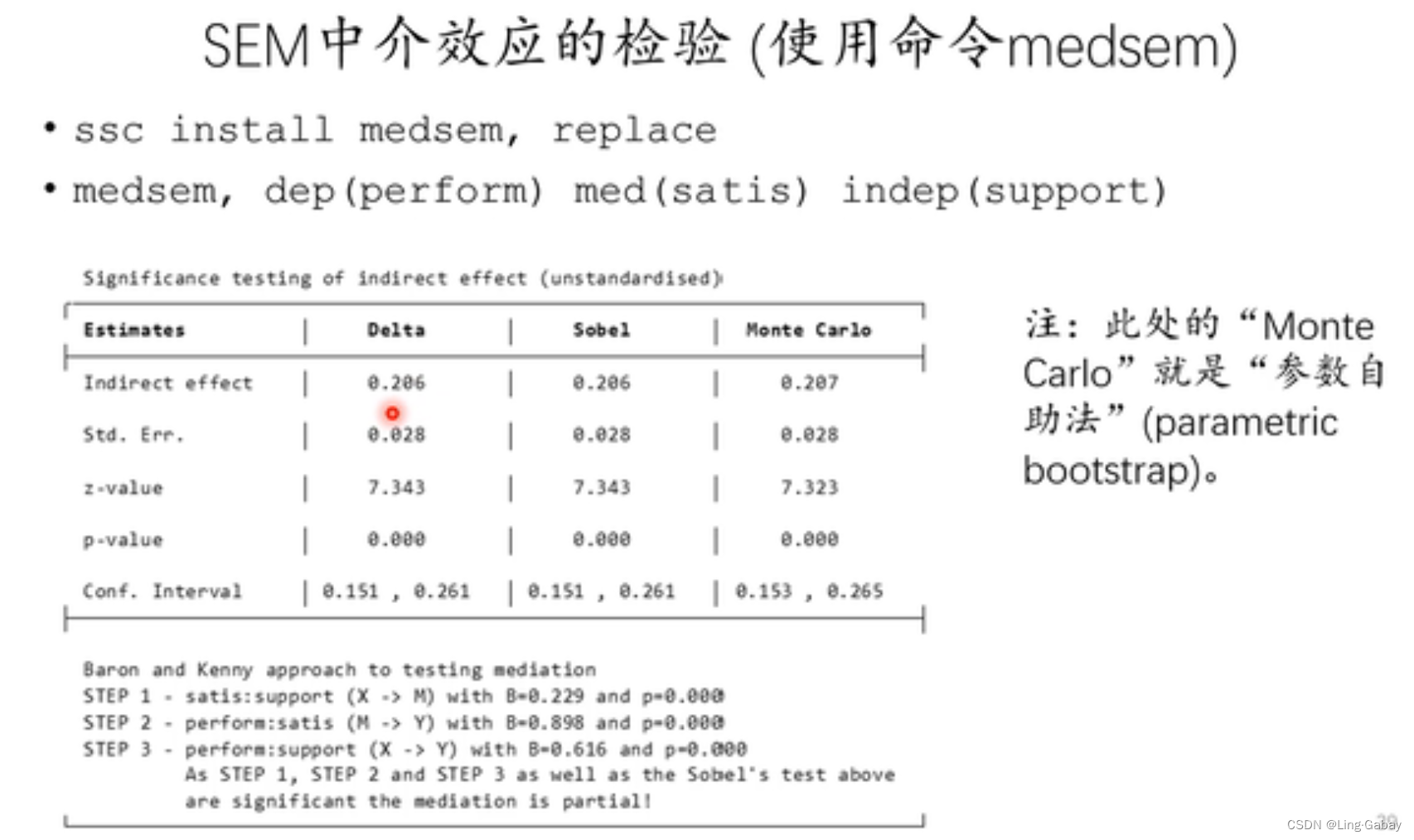
Stata操作
sgmediation

iv为解释变量,cv为控制变量,mv为中介变量。

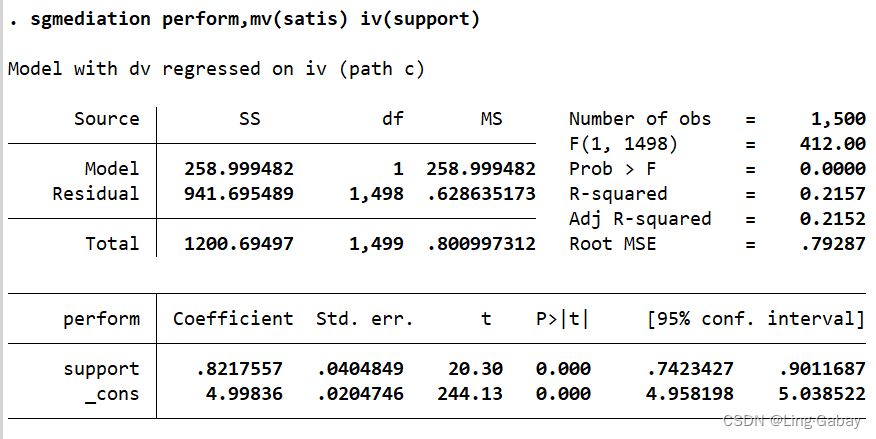
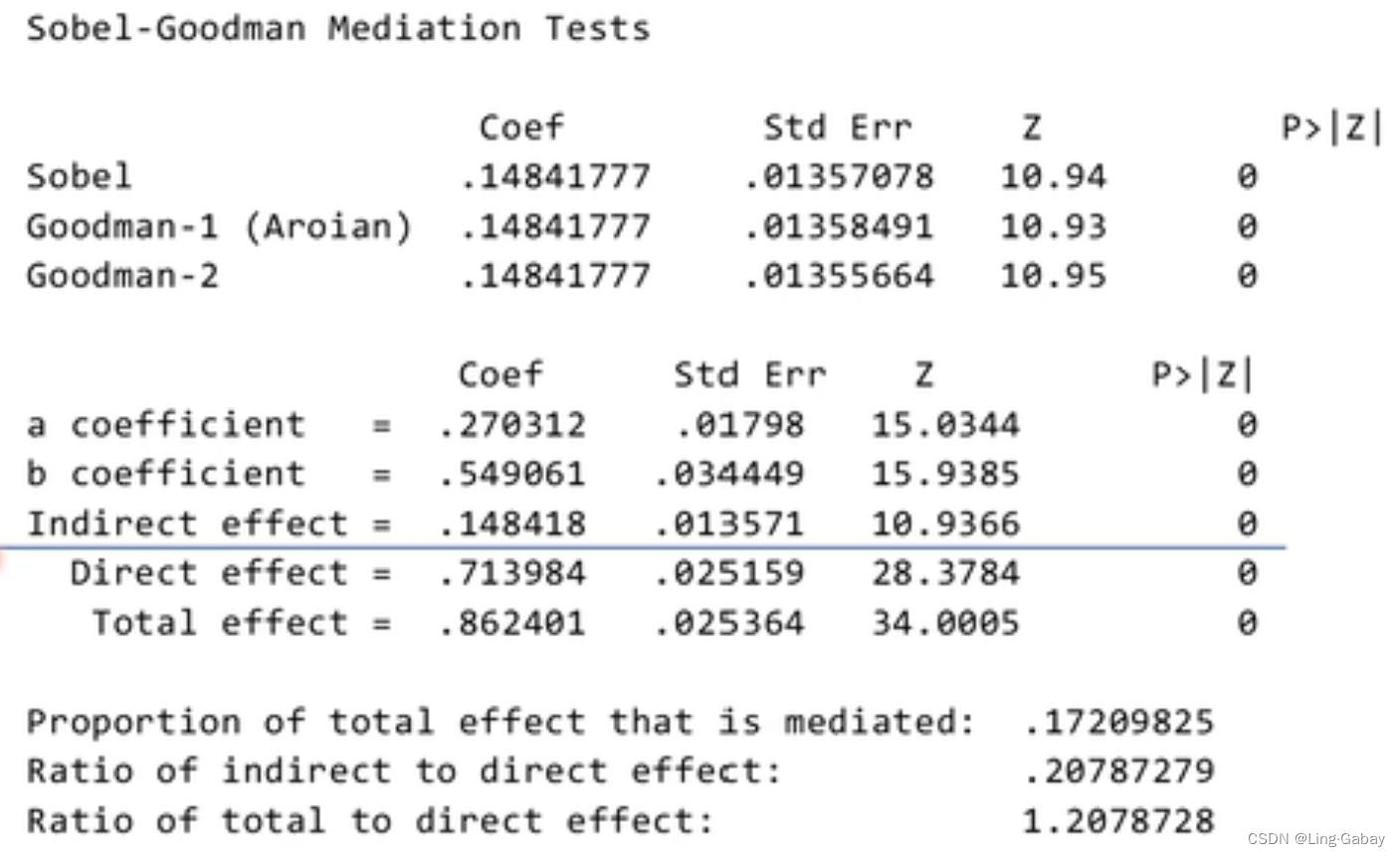
上述结果为总效应,即X(support)对Y(perform)的影响,可以看到系数为0.82176,值为0.000,结果是非常显著的。
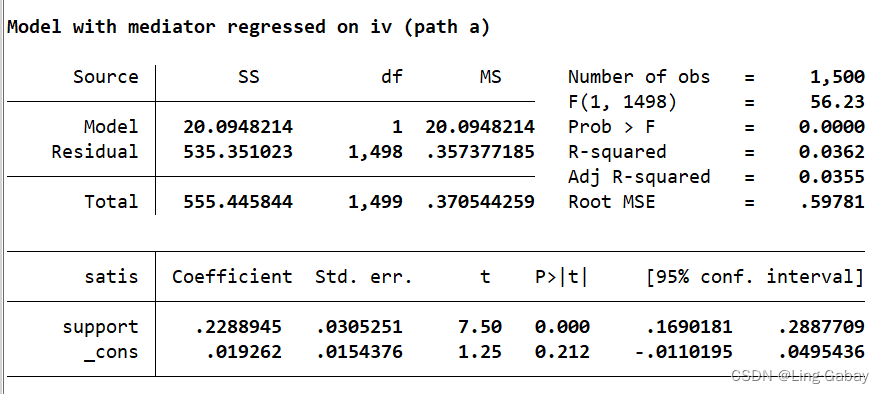 第二个结果为中介变量M(satis)对解释变量X(support)回归,系数为0.22889,
第二个结果为中介变量M(satis)对解释变量X(support)回归,系数为0.22889,值为0.000,结果是非常显著的。
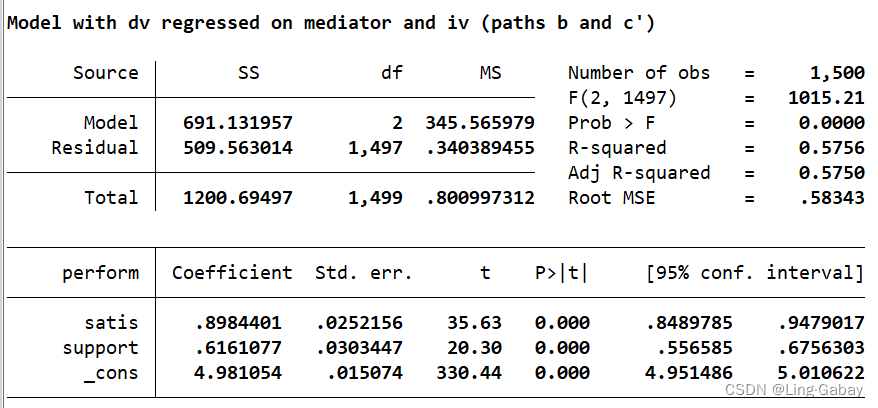
第三个结果展示了直接效应和间接效应,也就是上述第三个回归,可以看出结果也是非常显著。
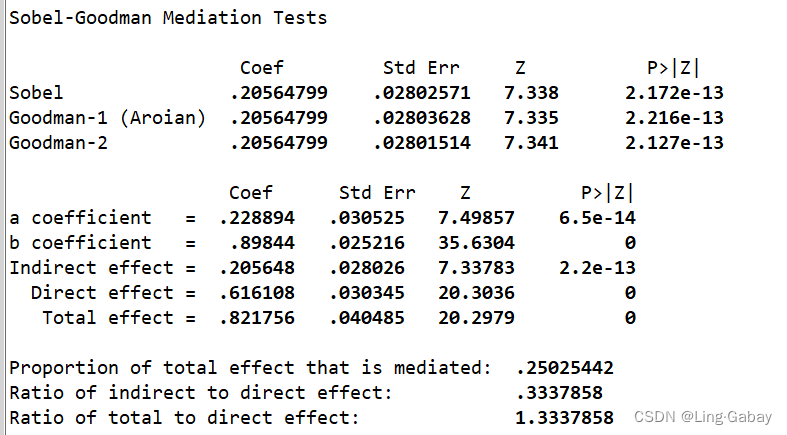
最后一个结果展示的是Sobel-Goodman test,上面三行对应上述介绍的三种标准误的计算方法,对应的Coef系数为。接下来汇报了a,b,间接效应,直接效用,总效用的参数,以及 间接效用在直接效用的比重等。


Case Bootstrap


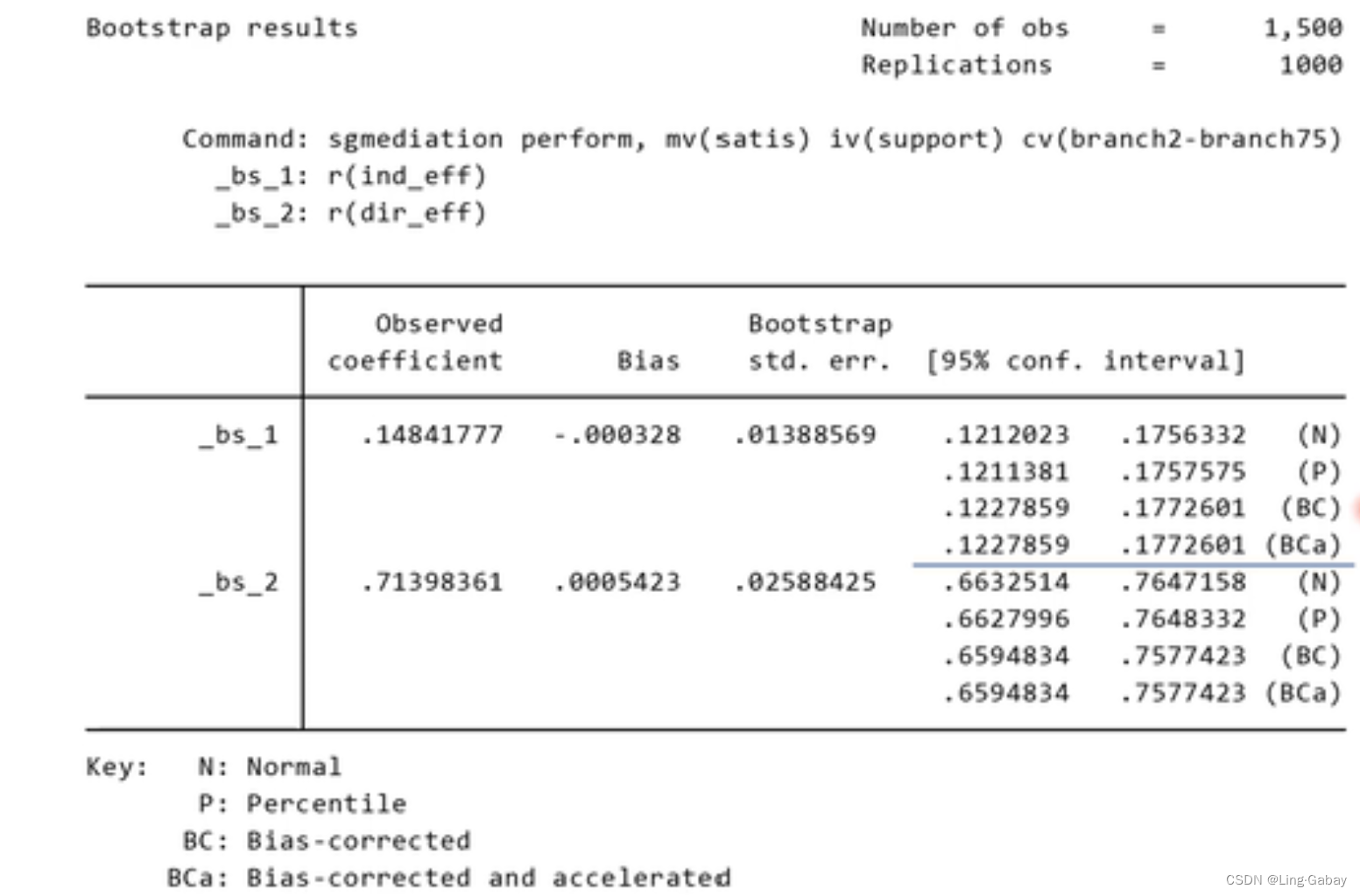
1000次自助抽样的命令,首先得到一个自助样本,然后用冒号后的命令(sgmediation)去做直接效应和间接效应的回归分析,然后通过r(ind_eff)和r(dir_eff)提取,重复1000次就可以得到1000个直接效应和间接效应的样本观测值,然后可以构造相应的置信区间。
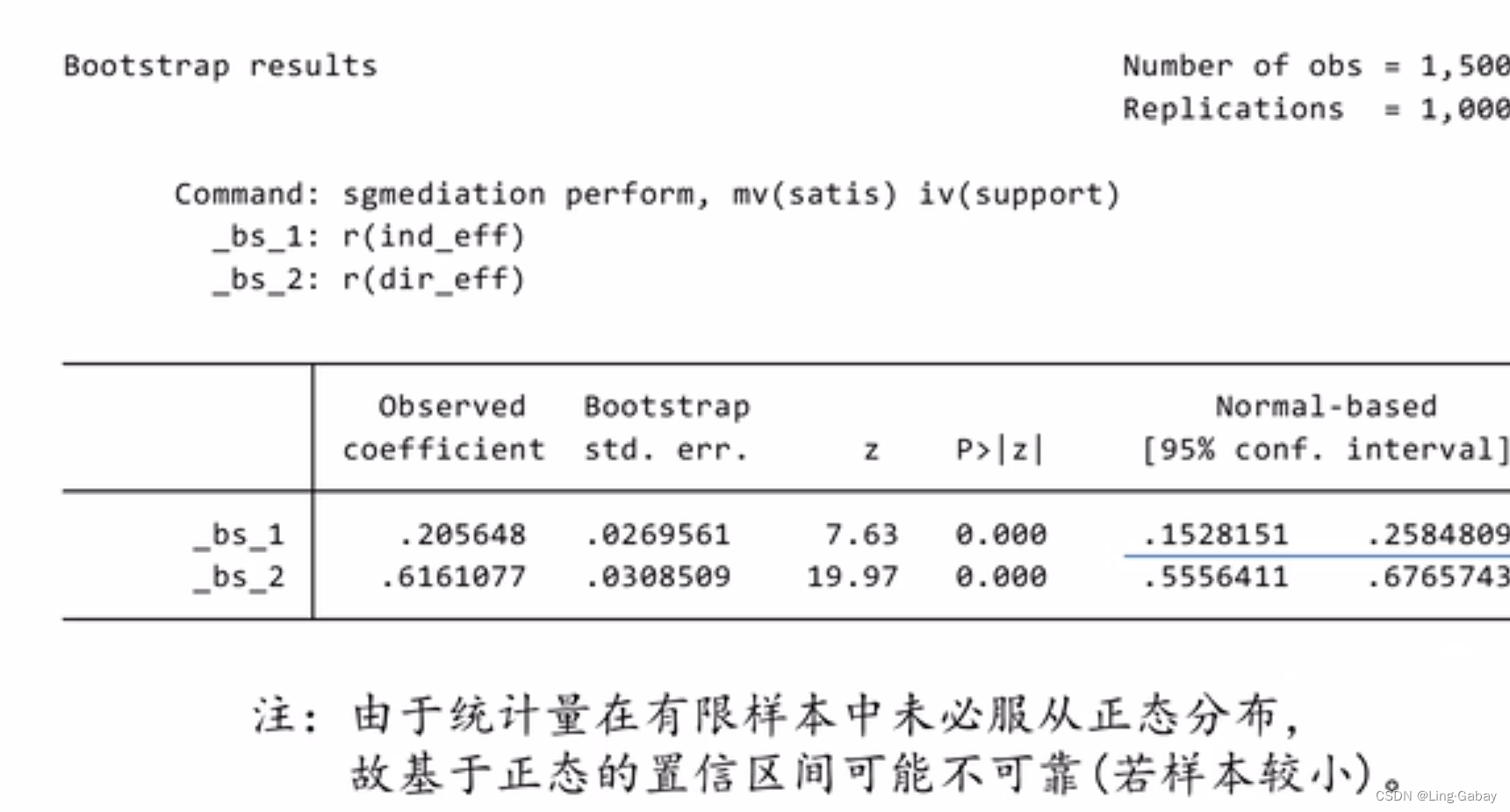
直接汇报的这个结果并不是非常可靠,因为它是一个normal based置信区间。它是用和
的1000个观测值,可以计算样本标准差,假设
和
服从正态分布,就可以得到
和
的置信区间。而我们之所以使用自助法,是因为我们不太相信统计量在有限样本下服从正态分布,只是这个计算方便,所以Stata会马上汇报这个结果。因此需要追加一条命令:

Percentile把的样本观测值从小到大排列,然后找到它的2.5%和97.5%的置信区间,但是会有偏差,BC就是把偏差校正。因为自助法是把样本看成总体,然后不断从中抽样,但样本终究不是总体,如果总体在两侧有很长的尾巴,则在尾部抽到的概率非常小,样本中不会出现这种“尾巴”。BCa的方法偏差收敛到0的速度达到
。
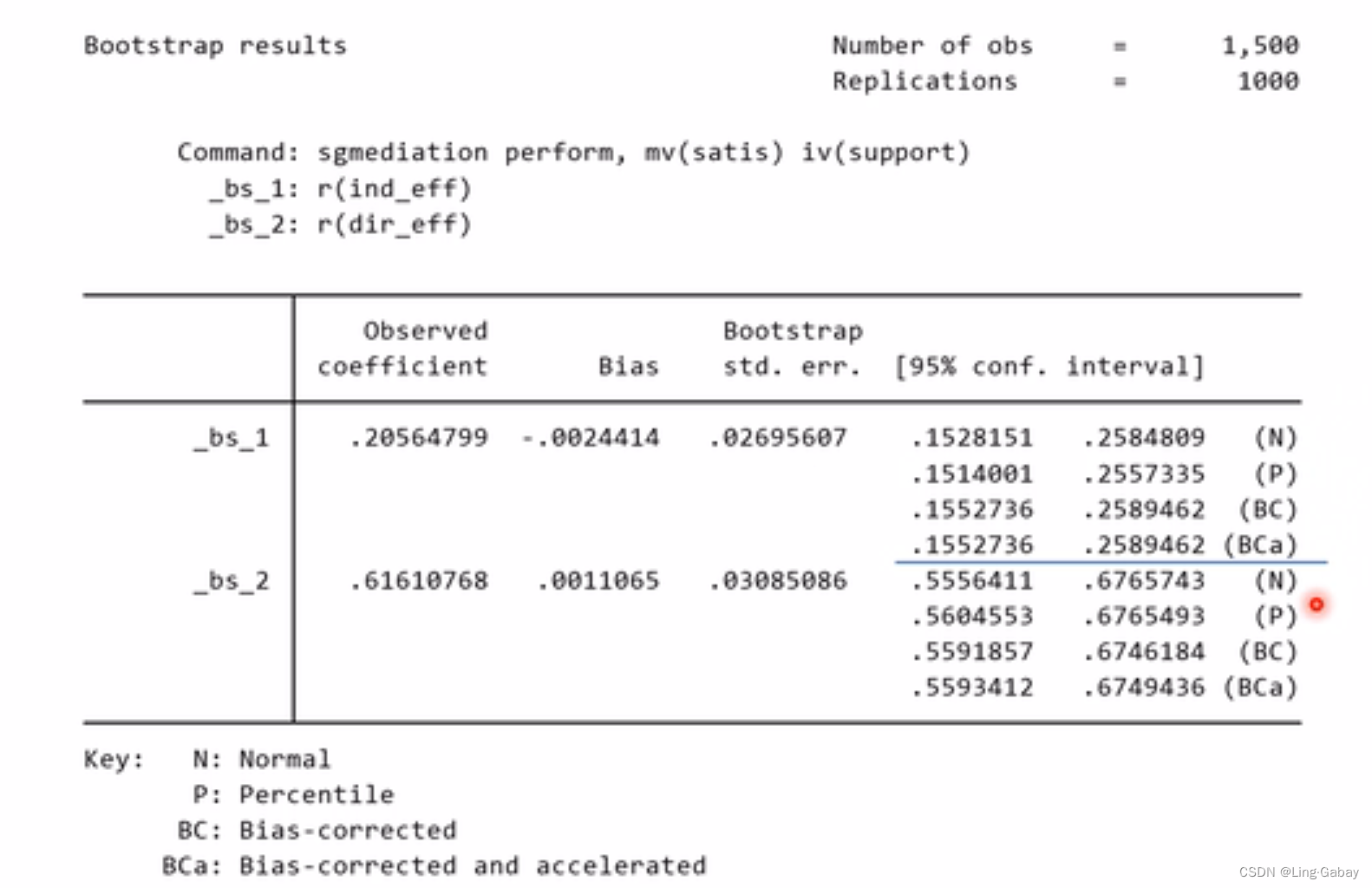
上述方法得到置信区间差别不到,是因为我们的样本有1500,样本比较大。
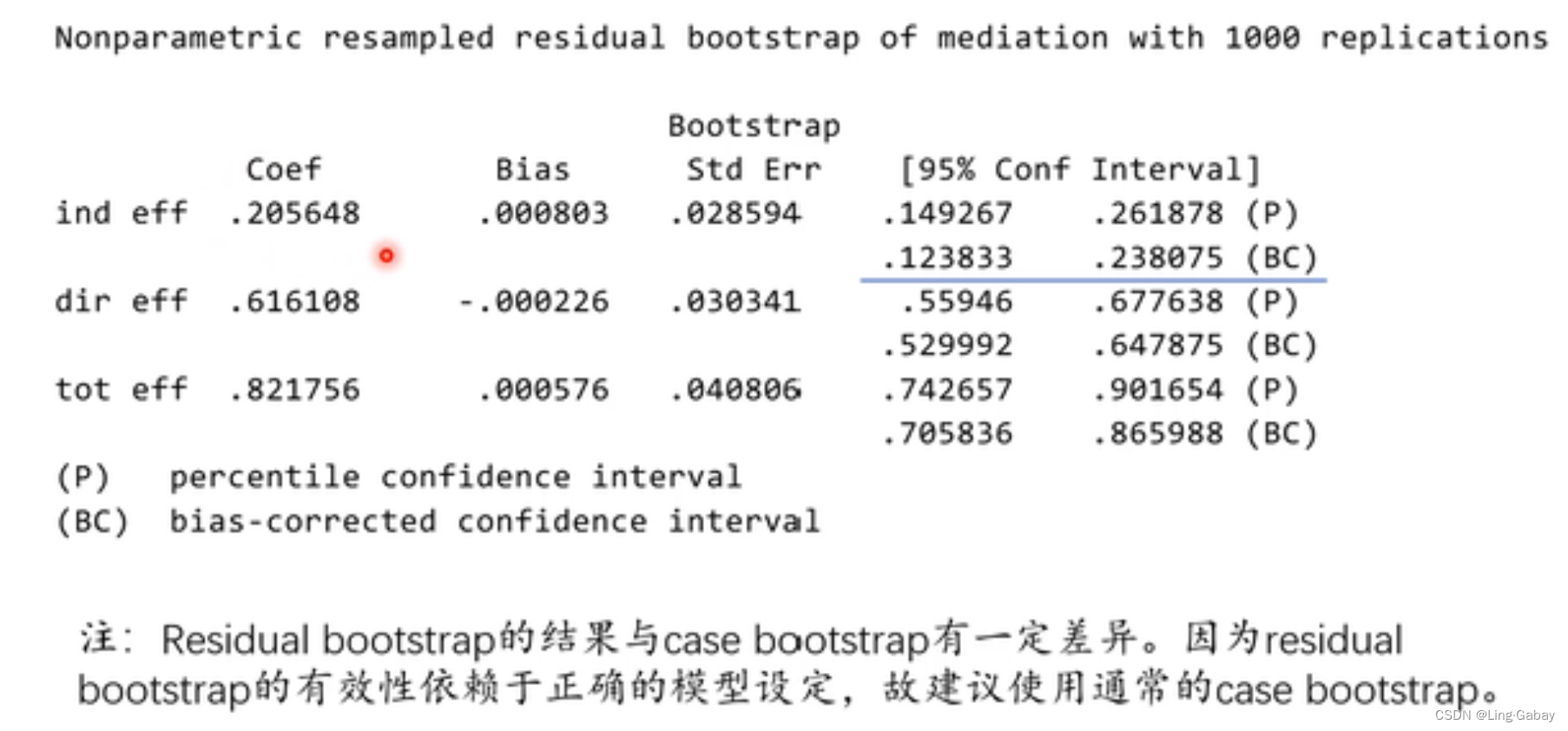
残差自助法

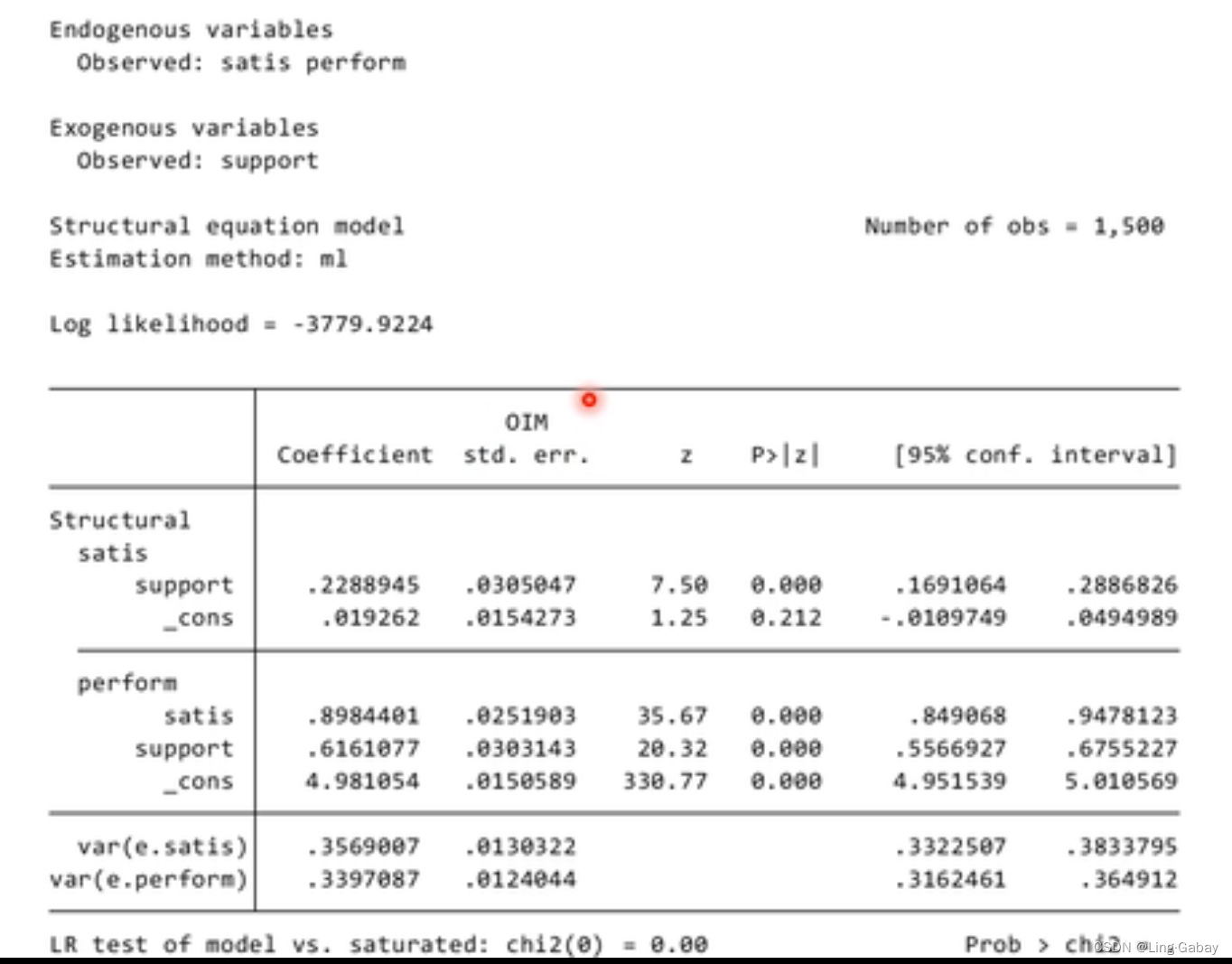
带协变量的中介效应检验
这个branch可以看成一家公司在每个地方都有分店,可以根据branch生成一系列以branch开头的虚拟变量


结构方程模型


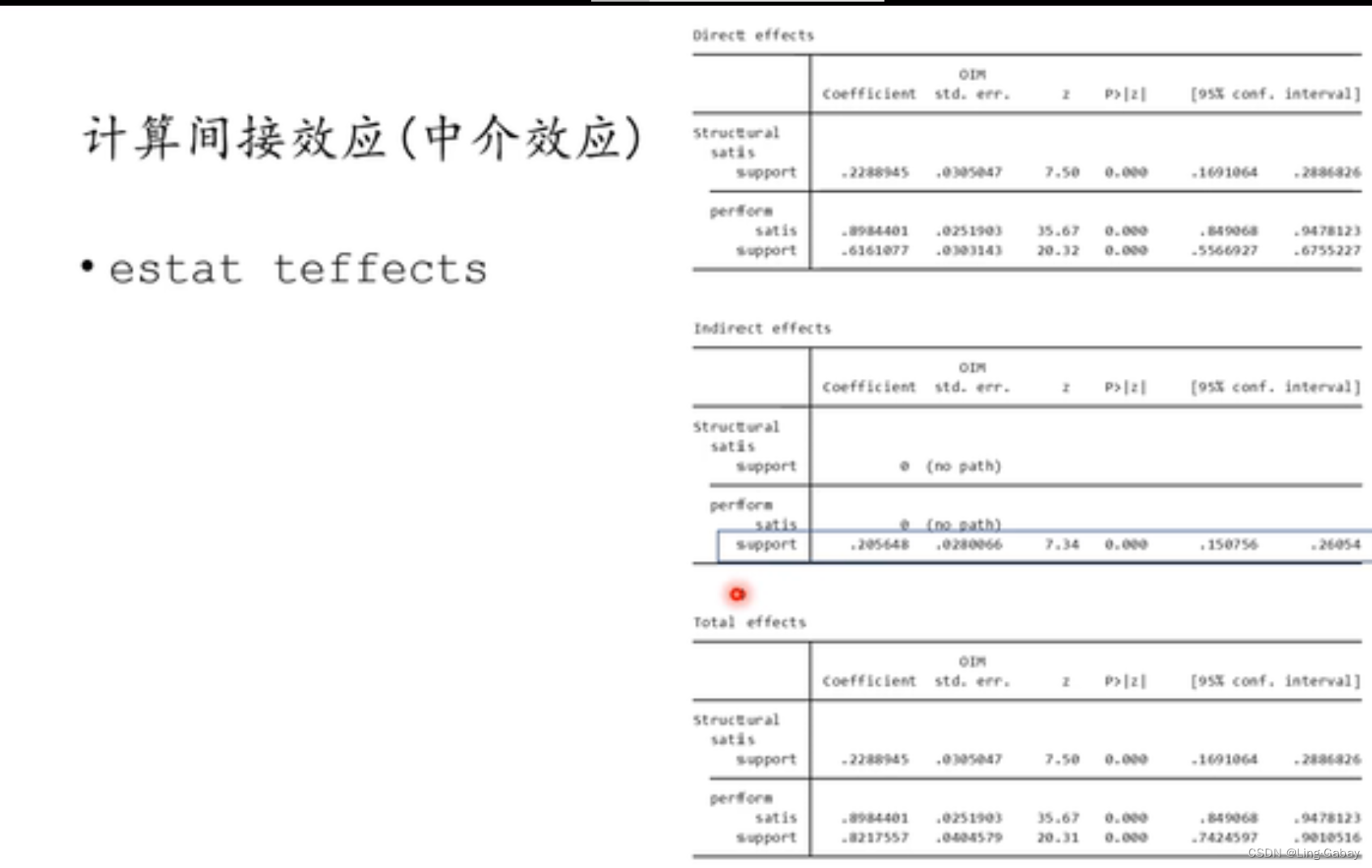
最好还是使用自助法


也可以使用
联立方程模型





旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)