
M3E 可能是最强大的开源中文嵌入模型
“介绍m3e开源中文嵌入模型,在中文的表现上,超过ChatGPT。”01—最近在研究和部署使用LangChain + LLM(ChatGPT/ChatGLM) 构建企业专有知识库时,接触到两个 embedding (嵌入)模型:text2vec,m3e-base。感兴趣模型和项目的部署和教程可以看这几篇文章:教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + Lan..
“ 介绍m3e开源中文嵌入模型,在中文的表现上,超过ChatGPT。”

01
—
最近在研究和部署使用 LangChain + LLM(ChatGPT/ChatGLM) 构建企业专有知识库时,接触到两个 embedding (嵌入)模型:text2vec,m3e-base。
感兴趣模型和项目的部署和教程可以看这几篇文章:
教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + LangChain
工程落地实践|基于 ChatGLM2-6B + LangChain 搭建专属知识库初步完成
工程落地实践|国产大模型 ChatGLM2-6B 阿里云上部署成功
例如配置文件中这段:
embedding_model_dict = {
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/home/featurize/data/text2vec-large-chinese", # 修改处
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}为什么要用到 embedding?
计算机只能处理数字,但我们希望它能够理解文字、图片或其他形式的数据。这就是embedding的作用。它将这些复杂的数据转换成数字表示,就像给它们贴上了标签一样。这些数字表示不仅保留了原始数据的重要信息,还能在计算机世界中更容易被处理和比较。
嵌入有点像字典,可以把不同的词、图片或对象转换成独特的数字编码。这样,我们就能用这些数字来进行计算、分类或做出预测。通过embedding,计算机可以变得更智能,因为它学会了如何用数字来理解和处理各种各样的数据。
例如,我们可以用一个三百维的数字向量(x1,x2,x3…x300)来表示一个词,这里每一个数字就是这个词在一个意义上的坐标。
举例来说,我们表述“猫”这个词,可以是(1,0.8,-2,0,1.5…)。
“狗”可以表示为(0.5,1.1,-1.8,0.4,2.2…)。
然后,我们可以通过这些数字的距离计算“猫”和“狗”的语义关系有多近。因为它们在某些数字上会更接近。
而与“桌子”的向量距离就会更远一些。
通过这种方法,embedding让词汇有了数学上的表示,计算机可以分析词汇间的关系了。
为什么把这个概念叫做 embedding (嵌入)呢?
嵌入的概念来源于拓扑学中,嵌入是在同胚基础上定义的,f把X映射到Z,若f是一个同胚且Z是Y的子空间。f称为一个X到Y的嵌入。
正如字面含义,嵌入强调的是X与Y的一部分结构相同.
若用神经网络把输入映射到更低维度的空间,实质强调的就是映射而已。
拓扑空间是指一个集合和在这个集合上定义的一组特定的开集构成的结构。而同胚关系是指两个拓扑空间之间存在一个双射(即一一对应),并且这个双射以及它的逆映射都是连续的。
换句话说,如果存在两个拓扑空间A和B,它们之间存在一个双射f:A → B,并且这个映射f以及它的逆映射f^{-1}:B → A都是连续的,那么我们就称A和B是同胚的。这种同胚关系意味着A和B在拓扑学的角度上是完全相同的,它们具有相同的拓扑性质和结构。
02
—
标题2
M3E Models :Moka(北京希瑞亚斯科技)开源的系列文本嵌入模型。
模型地址:
https://huggingface.co/moka-ai/m3e-base
M3E Models 是使用千万级 (2200w+) 的中文句对数据集进行训练的 Embedding 模型,在文本分类和文本检索的任务上都超越了 openai-ada-002 模型(ChatGPT 官方的模型)。
M3E的数据集,模型,训练脚本,评测框架都开源。
M3E 是 Moka Massive Mixed Embedding 的缩写
Moka,此模型由 MokaAI 训练,开源和评测,训练脚本使用 uniem ,评测 BenchMark 使用 MTEB-zh
Massive,此模型通过千万级 (2200w+) 的中文句对数据集进行训练
Mixed,此模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索
Embedding,此模型是文本嵌入模型,可以将自然语言转换成稠密的向量
模型对比
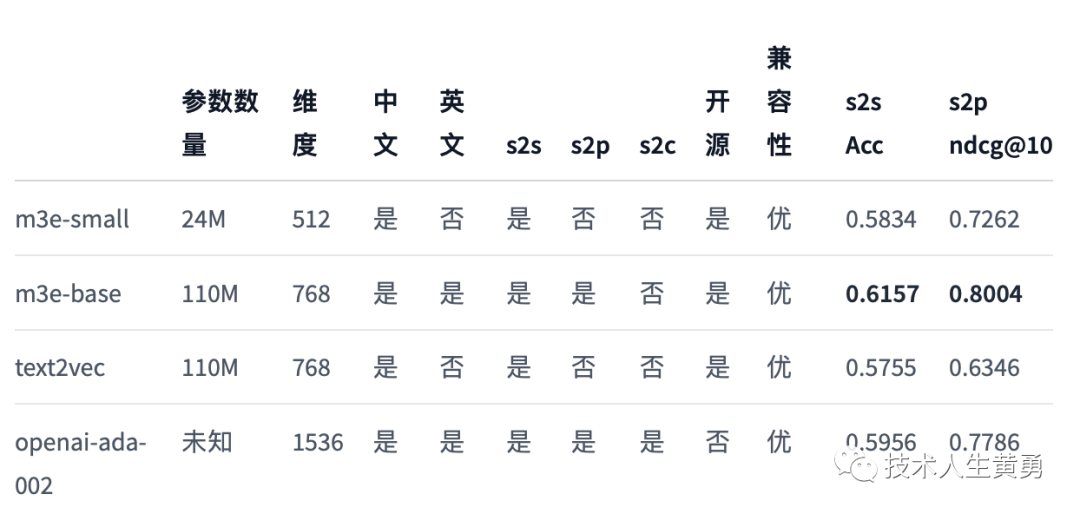
说明:
s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
s2c, 即 sentence to code ,代表了自然语言和程序语言之间的嵌入能力,适用任务:代码检索
兼容性,代表了模型在开源社区中各种项目被支持的程度,由于 m3e 和 text2vec 都可以直接通过 sentence-transformers 直接使用,所以和 openai 在社区的支持度上相当
ACC & ndcg@10,使用 MTEB 框架评测中文 Embedding 模型的 BenchMark,包含文本分类,文本重排,以及文本检索等任务。
Tips:
使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型
多语言使用场景,建议使用 openai-ada-002
代码检索场景,推荐使用 ada-002
文本检索场景,请使用具备文本检索能力的模型,只在 S2S 上训练的文本嵌入模型,没有办法完成文本检索任务
特性
中文训练集,M3E 在大规模句对数据集上的训练,包含中文百科,金融,医疗,法律,新闻,学术等多个领域共计 2200W 句对样本,数据集详见 M3E 数据集
英文训练集,M3E 使用 MEDI 145W 英文三元组数据集进行训练,数据集详见 MEDI 数据集,此数据集由 instructor team 提供
指令数据集,M3E 使用了 300W + 的指令微调数据集,这使得 M3E 对文本编码的时候可以遵从指令,这部分的工作主要被启发于 instructor-embedding
基础模型,M3E 使用 hfl 实验室的 Roberta 系列模型进行训练,目前提供 small 和 base 两个版本,可以按需选用
ALL IN ONE,M3E 旨在提供一个 ALL IN ONE 的文本嵌入模型,不仅支持同质句子相似度判断,还支持异质文本检索,你只需要一个模型就可以覆盖全部的应用场景,未来还会支持代码检索
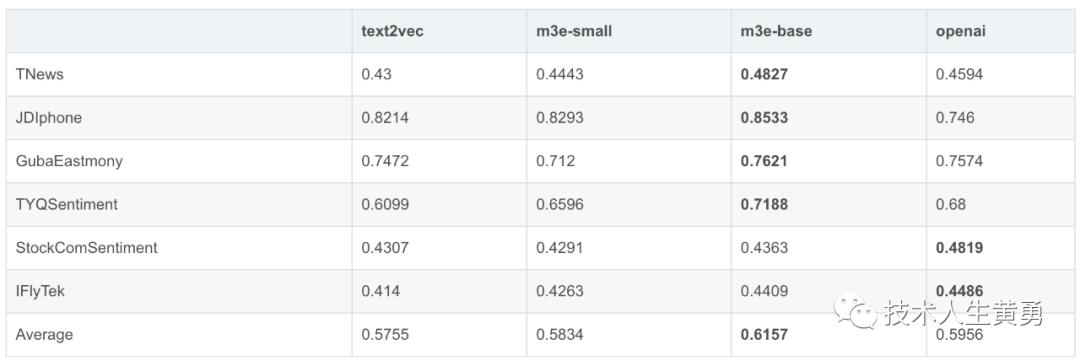
文本分类
数据集选择,选择开源在 HuggingFace 上的 6 种文本分类数据集,包括新闻、电商评论、股票评论、长文本等
评测方式,使用 MTEB 的方式进行评测,报告 Accuracy。
检索排序
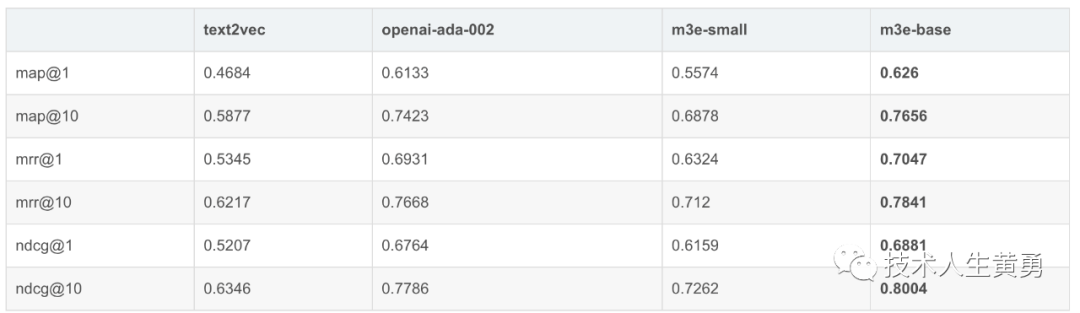
T2Ranking 1W
数据集选择,使用 T2Ranking 数据集,由于 T2Ranking 的数据集太大,openai 评测起来的时间成本和 api 费用有些高,所以我们只选择了 T2Ranking 中的前 10000 篇文章
评测方式,使用 MTEB 的方式进行评测,报告 map@1, map@10, mrr@1, mrr@10, ndcg@1, ndcg@10
注意!从实验结果和训练方式来看,除了 M3E 模型和 openai 模型外,其余模型都没有做检索任务的训练,所以结果仅供参考。
T2Ranking
数据集选择,使用 T2Ranking,刨除 openai-ada-002 模型后,我们对剩余的三个模型,进行 T2Ranking 10W 和 T2Ranking 50W 的评测。(T2Ranking 评测太耗内存了... 128G 都不行)
评测方式,使用 MTEB 的方式进行评测,报告 ndcg@10

阅读推荐:
ChatGPT开发实战|实现英文字幕翻译为中文双语的小工具
为什么你在用 ChatGPT 的提示词 Prompt 似乎效果不如人意?
Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本
ChatGPT 如何用?12个场景的 Prompts &万能话术模板 & 四个提问技巧
为什么对ChatGPT、ChatGLM这样的大语言模型说“你是某某领域专家”,它的回答会有效得多?(二)
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)