

crnn代码学习----小白向!
第一次写博客!最近学习了一下识别领域经典论文crnn,并copy了github上的一份代码来进行学习。作为小白,对代码并不是很熟悉,记录学习过程的同时也希望能够为志同道合的入门小伙伴提供一点帮助。在我的学习过程中我是自己打断点调试,弄清变量的变化过程,会有手写记录流程图,当你把整个文件过了一遍之后,你会发现自己真的很有成就感!这是github项目地址基础配置:ubuntu16.04cuda=10.
目录
5.predict流程【key,输入图片,网络处理流程都在这里】
1.前言
第一次写博客!
最近学习了一下识别领域经典论文crnn,并copy了github上的一份代码来进行学习。作为小白,对代码并不是很熟悉,记录学习过程的同时也希望能够为志同道合的入门小伙伴提供一点帮助。在我的学习过程中我是自己打断点调试,弄清变量的变化过程,会有手写记录流程图,当你把整个文件过了一遍之后,你会发现自己真的很有成就感!
这是github项目地址crnn-pytorch 之所以选择这个收藏量并不是最高的项目,是因为我看到他的项目模块明确,而且亲测了一下是可以很方便配置环境和跑起来predict.py文件的,相较于那些收藏高的对小白更加友好
基础配置:ubuntu16.04 cuda=10.2
环境配置:其实就是创建好环境名称,然后执行项目里打包好的requirements,之后的推理,数据集下载,训练就按照github上来就可以,不出问题这个项目是都可以跑通的。
git clone https://github.com/GitYCC/crnn-pytorch.git
conda create -n crnn python==3.7.0
conda activate crnn
cd crnn-pytorch
pip install -r requirements.txt2.crnn整体结构
这里就直接上图了,这是paper的网址crnn 建议没读过的uu配合某b或者csdn上的讲解来过一遍,清楚大概的原理以及ctc_decoder到底怎么工作的。
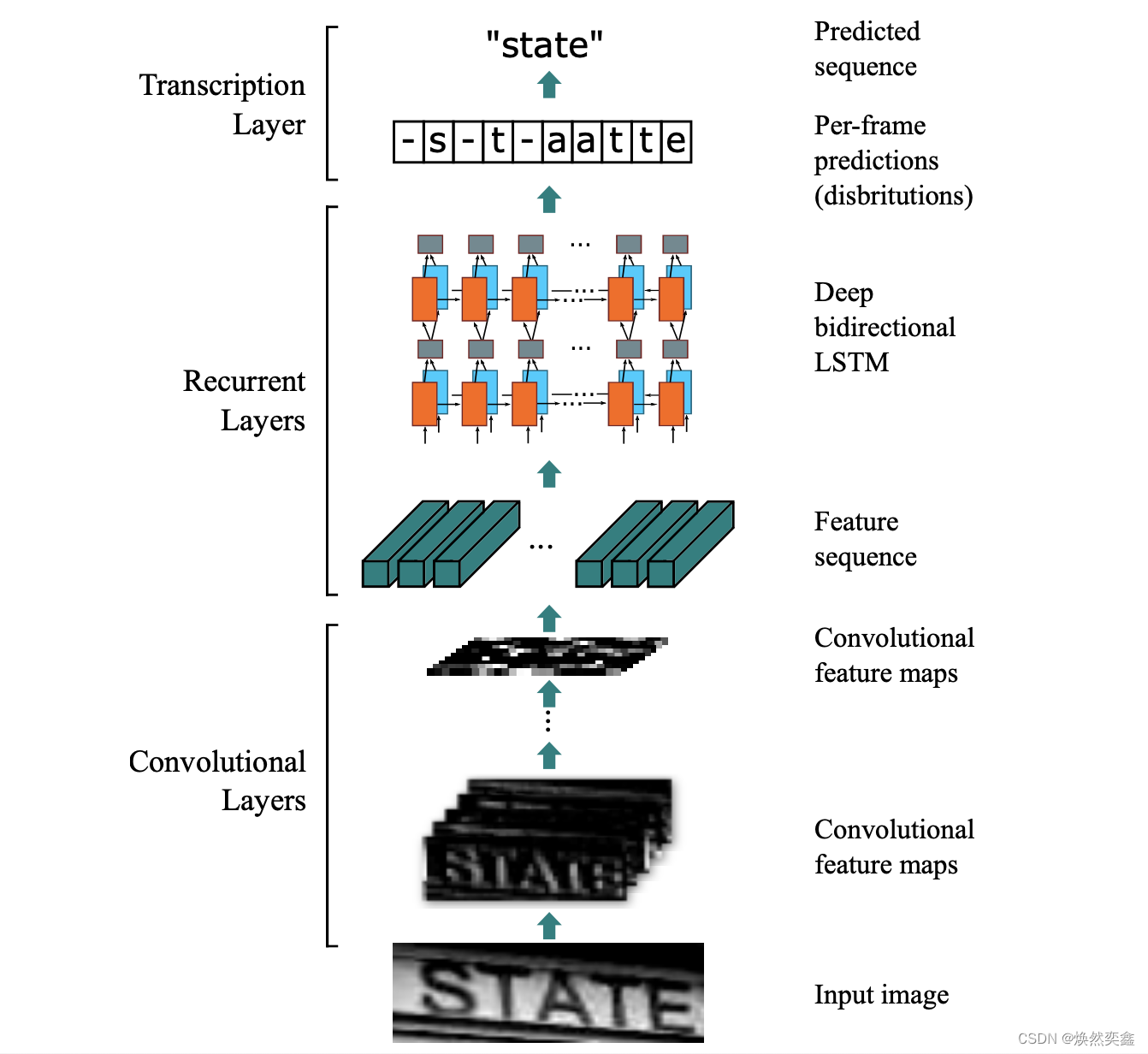
3.model.py代码
我是遵照我提供的github项目来的,整体项目结构是这样:
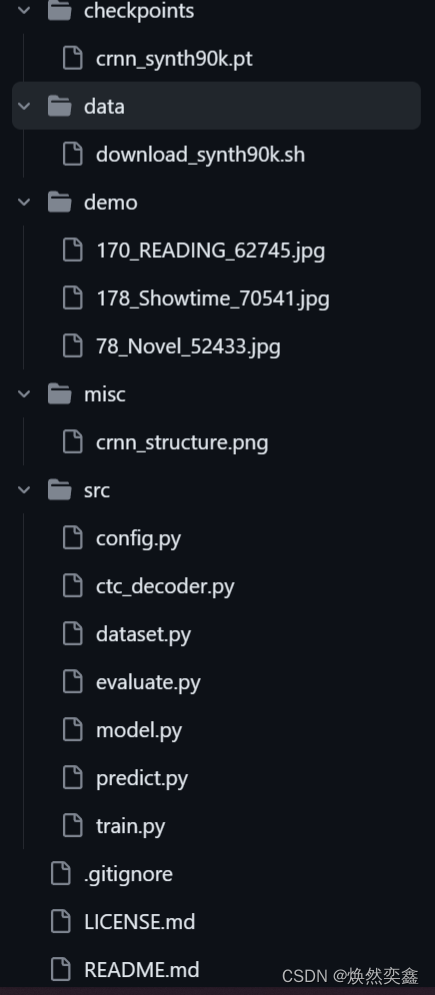
心理压力小很多,没有那么多py文件,其实主要关注的就只有src目录下的文件,其余或是图片,或是权重文件等。这里我择取对于模型重要的两个文件,model.py文件主要是crnn结构中的CNN和RNN部分,ctc_decoder.py文件就是对应translator部分。这么清晰,学习起来目标都明确一些!
import torch.nn as nn
# 传入img[],输出对应未处理过的原始标签
class CRNN(nn.Module):
def __init__(self, img_channel, img_height, img_width, num_class,
map_to_seq_hidden=64, rnn_hidden=256, leaky_relu=False):
super(CRNN, self).__init__()
self.cnn, (output_channel, output_height, output_width) = \
self._cnn_backbone(img_channel, img_height, img_width, leaky_relu)
self.map_to_seq = nn.Linear(output_channel * output_height, map_to_seq_hidden)
self.rnn1 = nn.LSTM(map_to_seq_hidden, rnn_hidden, bidirectional=True)
self.rnn2 = nn.LSTM(2 * rnn_hidden, rnn_hidden, bidirectional=True)
self.dense = nn.Linear(2 * rnn_hidden, num_class)
def _cnn_backbone(self, img_channel, img_height, img_width, leaky_relu):
# 确保变量img_height是16的倍数。如果img_height不是16的倍数,将会抛出一个AssertionError异常
assert img_height % 16 == 0
assert img_width % 4 == 0
channels = [img_channel, 64, 128, 256, 256, 512, 512, 512]
kernel_sizes = [3, 3, 3, 3, 3, 3, 2]
strides = [1, 1, 1, 1, 1, 1, 1]
paddings = [1, 1, 1, 1, 1, 1, 0]
nn.Sequential()
# 是PyTorch中的一个模型容器,可以用来定义一个由多个网络层按顺序组成的神经网络模型
cnn = nn.Sequential()
# 定义了卷积层和relu激活函数的一一组合
def conv_relu(i, batch_norm=False):
# shape of input: (batch, input_channel, height, width)
input_channel = channels[i]
output_channel = channels[i+1]
cnn.add_module(
f'conv{i}',
nn.Conv2d(input_channel, output_channel, kernel_sizes[i], strides[i], paddings[i])
)
if batch_norm:
cnn.add_module(f'batchnorm{i}', nn.BatchNorm2d(output_channel))
relu = nn.LeakyReLU(0.2, inplace=True) if leaky_relu else nn.ReLU(inplace=True)
cnn.add_module(f'relu{i}', relu)
# size of image: (channel, height, width) = (img_channel, img_height, img_width)
conv_relu(0)#第一层卷积和Relu激活
cnn.add_module('pooling0', nn.MaxPool2d(kernel_size=2, stride=2))
# (64, img_height // 2, img_width // 2)
conv_relu(1)
cnn.add_module('pooling1', nn.MaxPool2d(kernel_size=2, stride=2))
# (128, img_height // 4, img_width // 4)
conv_relu(2)
conv_relu(3)
cnn.add_module(
'pooling2',
# 注意这里的池化核是矩形的
nn.MaxPool2d(kernel_size=(2, 1))
) # (256, img_height // 8, img_width // 4)
# 在第5层和第6层卷积层之后分别插入两批归一化层
conv_relu(4, batch_norm=True)
conv_relu(5, batch_norm=True)
cnn.add_module(
'pooling3',
nn.MaxPool2d(kernel_size=(2, 1))
) # (512, img_height // 16, img_width // 4)
conv_relu(6) # (512, img_height // 16 - 1, img_width // 4 - 1)
# 到这里CNN的提取层就完了,输出output_channel, output_height, output_width =512,1,24
output_channel, output_height, output_width = \
channels[-1], img_height // 16 - 1, img_width // 4 - 1
return cnn, (output_channel, output_height, output_width)
def forward(self, images):
# shape of images: (batch, channel, height, width)
conv = self.cnn(images)
batch, channel, height, width = conv.size()
# .view()方法可以用来创建一个具有相同数据但不同形状的新的Numpy数组或PyTorch张量
conv = conv.view(batch, channel * height, width)
conv = conv.permute(2, 0, 1) # (width, batch, feature)
seq = self.map_to_seq(conv)
recurrent, _ = self.rnn1(seq)
recurrent, _ = self.rnn2(recurrent)
output = self.dense(recurrent)
return output # shape: (seq_len, batch, num_class)其中我们尤其注意比较原文的网络参数设置与代码的这里:
channels = [img_channel, 64, 128, 256, 256, 512, 512, 512]
kernel_sizes = [3, 3, 3, 3, 3, 3, 2]
strides = [1, 1, 1, 1, 1, 1, 1]
paddings = [1, 1, 1, 1, 1, 1, 0]
发现是完全一 一对应的,一共七个卷积层,对应列表长度也是七。关于代码里定义的conv_relu函数,就是字面意思,卷积+池化,因为在crnn中卷积后都接了池化层。
4.ctc_decoder.py代码
该代码定义了三个函数:greedy_decode、beam_search_decode和prefix_beam_decode,用于分别实现贪心解码、束搜索解码和前缀束搜索解码,这里采用的束搜索解码beam_search_decode,所以也只分析这一段代码
首先定义 reconstruct函数,可以理解为去重和去掉blank的步骤
from collections import defaultdict
import pdb
import torch
import numpy as np
from scipy.special import logsumexp # log(p1 + p2) = logsumexp([log_p1, log_p2])
# 将负无穷赋值给变量
NINF = -1 * float('inf')
DEFAULT_EMISSION_THRESHOLD = 0.01
#从hh-e--ll-l--o到hello的一步
def _reconstruct(labels, blank=0):
new_labels = []
# merge same labels
previous = None
for l in labels:
if l != previous:
new_labels.append(l)
previous = l
# delete blank
new_labels = [l for l in new_labels if l != blank]
return new_labels
def beam_search_decode(emission_log_prob, blank=0, **kwargs):
# 允许将任意数量的关键字参数传递给函数。在函数定义中,可以使用 ** kwargs语法来捕获这些可选关键字参数
beam_size = kwargs['beam_size']
# 从kwargs字典中获取名为emission_threshold的值。如果emission_threshold存在于kwargs中,则返回其对应的值;否则返回np.log
# DEFAULT_EMISSION_THRESHOLD)的值
emission_threshold = kwargs.get('emission_threshold', np.log(DEFAULT_EMISSION_THRESHOLD))
length, class_count = emission_log_prob.shape
# 初始化一个束(beam)列表
beams = [([], 0)] # (prefix, accumulated_log_prob)
for t in range(length):
new_beams = []
for prefix, accumulated_log_prob in beams:
for c in range(class_count):
log_prob = emission_log_prob[t, c]
if log_prob < emission_threshold:
continue
new_prefix = prefix + [c]
# log(p1 * p2) = log_p1 + log_p2
new_accu_log_prob = accumulated_log_prob + log_prob
# 每次通过new_beams.append往列表中添加一个二元组
new_beams.append((new_prefix, new_accu_log_prob))
# sorted by accumulated_log_prob
# key参数指定用于排序的关键字函数,reverse参数指定排序顺序是否为降序(默认为升序)
# new_beams是一个元素为元组的列表,每个元组包含两个元素:一个标签前缀列表和一个累积对数概率值。lambda x: x[1]
# 是一个匿名函数,它接受一个元组作为参数,并返回该元组的第二个元素,即累积对数概率值
# sort()方法将按照每个元组的累积对数概率值从大到小的顺序对new_beams进行排序,使得具有更高概率值的标签序列排在前面
new_beams.sort(key=lambda x: x[1], reverse=True)
# 选择前beam_size个具有最高累积对数概率值的标签序列
beams = new_beams[:beam_size]
# sum up beams to produce labels
# 通过下面这个循环后total_accu_log_prob储存了标签和对应概率对数值的键值对,
# 如{(28, 15, 11, 14, 19, 24, 17): -0.00976341948161246}是最后结果,其实beams的十个标签序列对应同一个序列
total_accu_log_prob = {}
for prefix, accu_log_prob in beams:
labels = tuple(_reconstruct(prefix, blank))
# .get(labels, NINF)方法将在字典中查找键为labels的元素,并返回其对应的值。如果字典中不存在这个键,则返回默认值NINF
total_accu_log_prob.get(labels, NINF)
# 如果当前的标签序列在字典中已经出现过,则使用字典中的累积对数概率值;否则,使用负无穷大(NINF)作为默认值
# log(p1 + p2) = logsumexp([log_p1, log_p2])
#注:这里的对数计算都是以自然底数e为底!
total_accu_log_prob[labels] = \
logsumexp([accu_log_prob, total_accu_log_prob.get(labels, NINF)])
pdb.set_trace()
labels_beams = [(list(labels), accu_log_prob)
for labels, accu_log_prob in total_accu_log_prob.items()]
labels_beams.sort(key=lambda x: x[1], reverse=True)
labels = labels_beams[0][0]
return labels定义好了beam_search_decode策略,就可以写最终的ctc_decoder了
def ctc_decode(log_probs, label2char=None, blank=0, method='beam_search', beam_size=10):
# 转置操作
emission_log_probs = np.transpose(log_probs.cpu().numpy(), (1, 0, 2))
# size of emission_log_probs: (batch, length, class)
decoders = {
'greedy': greedy_decode,
'beam_search': beam_search_decode,
'prefix_beam_search': prefix_beam_decode,
}
decoder = decoders[method]
decoded_list = []
for emission_log_prob in emission_log_probs:
decoded = decoder(emission_log_prob, blank=blank, beam_size=beam_size)
# label2char:{1: '0', 2: '1', 3: '2', 4: '3', 5: '4', 6: '5', 7: '6', 8: '7', 9: '8', 10: '9', 11: 'a', 12: 'b', 13: 'c',
# 14: 'd', 15: 'e', 16: 'f', 17: 'g', 18: 'h', 19: 'i', 20: 'j', 21: 'k', 22: 'l', 23: 'm', 24: 'n', 25: 'o',
# 26: 'p', 27: 'q', 28: 'r', 29: 's', 30: 't', 31: 'u', 32: 'v', 33: 'w', 34: 'x', 35: 'y', 36: 'z'}
if label2char:
# 将标签转化为序列,并加入到decoded_list中
decoded = [label2char[l] for l in decoded]
decoded_list.append(decoded)
return decoded_list5.predict流程【key,输入图片,网络处理流程都在这里】
这一步就是运行github的代码,把预测文件predict.py跑起来,它一共输入三张图片,分别是reading,showtime,novel。从这里也可从dataset.py看出这个项目的不完善在于它的字典只有小写字母,不包含大写字母,然后代码还有一个bug在于blank选的是0,如果识别的图片也有0是不是会出错,此处我没弄明白,希望各位指正。
输入图片,预测流程如下,自己断点调试,一个一个变量看的,训练除了会定义loss外,传入的处理流程也是一样的,希望让你更加清晰!

6.关于数据集与训练
训练使用的是Synth90k 数据集,github上有说明和链接,大小10G左右,主要问题在于——限流严重,自己试过,也让别人试过,应该和你网速无关,下载就只有100k/s,大概需要下载28h...我已经下下来了,之后有需要的伙伴的话我会把我的上传到网盘,看能不能加速一点。
Synth90k ![]() http://www.robots.ox.ac.uk/~vgg/data/text/
http://www.robots.ox.ac.uk/~vgg/data/text/
法一:建议如果你是服务器用户的话,一定要使用screen创建会话窗口来进行下载!否则断网或者关闭服务器后等于白下。这几天浪费了很多时间在服务器上乱下,没成功过,老是断掉就是这个原因.
screen -S <your_name> #<>里的名字自己定义,将成为会话窗口的名字
cd data
bash download_synth90k.sh
退出会话窗口,但后台还会执行程序,一劳永逸 。
按下Ctrl+A+D推出临时窗口
screen -list #查看所有打开过的会话窗口,找到自己对应的窗口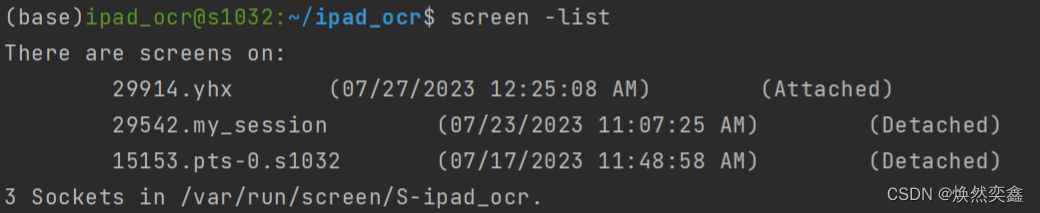
比如我的是my_session,那么执行screen -r 29542 (也就是your_name前面的一串数字)会重新进入窗口,可以查看实时进度。
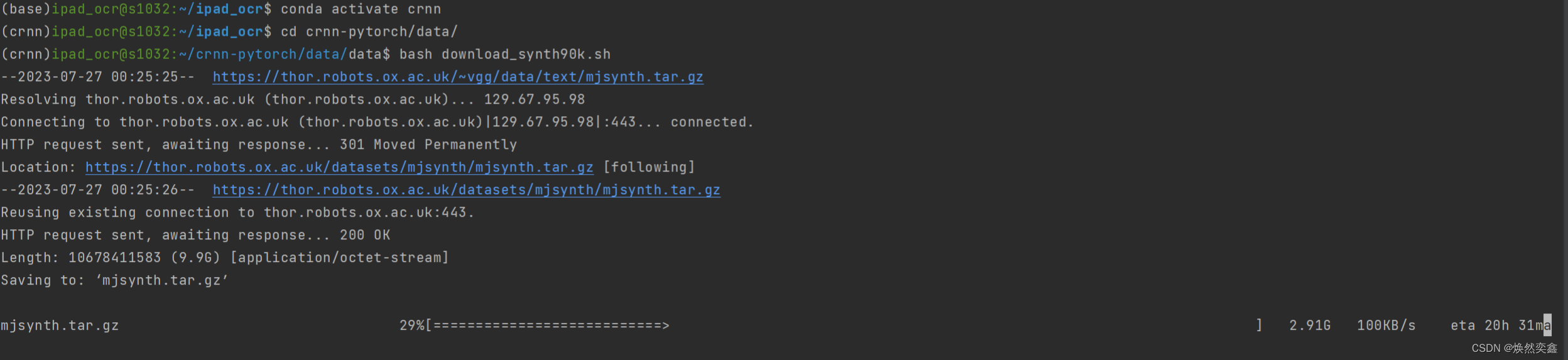
法二: 直接复制上面链接到浏览器可以本地下载,但如果本地下载好再通过pycharm或mobarxterm传输到服务器更耗时间,28h+传输基本得80h以上,而且21.1G的压缩包很吃本地内存,所以不建议。
等我下载完了再训练网络,到时候回来反馈结果。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)