MySQL 缓冲池 Buffer Pool 详解
Linux C/C++后端服务器开发 学习资料、教学视频和学习路线图(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),有需要的可以自行添加学习交流群 739729163 领取。,当执行读写的时候磁盘的数据页会加载到B
在应用系统中,我们为加速数据访问,会把高频的数据放在 「缓存」 (Redis、MongoDB)里,减轻数据库的压力。
在操作系统中,为了减少磁盘IO,引入了 「缓冲池」 (buffer pool)机制。
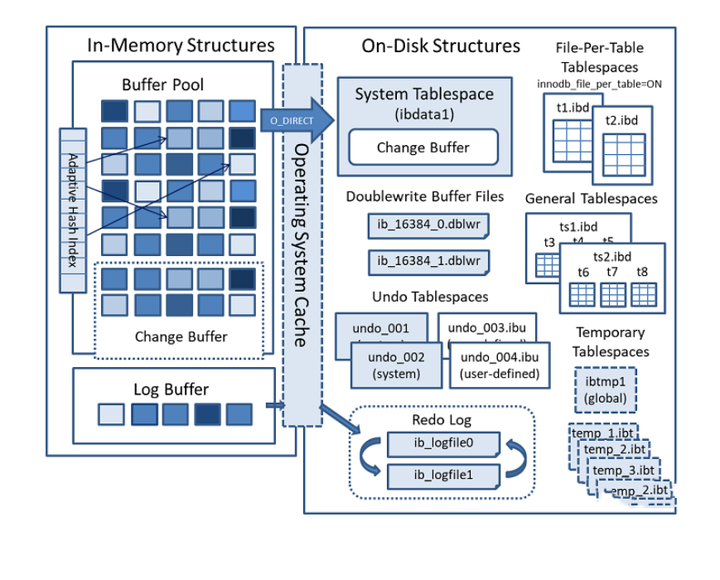
MySQL作为一个存储系统,为提高性能,减少磁盘IO,同样具有**「缓冲池」**(buffer pool)机制。 结构图如下:

「上述结构图中展示了Buffer Pool作为InnoDB内存结构的四大组件之一,不属于MySQL的Server层,是InnoDB存储引擎层的缓冲池」。因此这个跟MySQL8.0删掉的【查询缓存】功能是不一样的。
一、什么是Buffer Pool
「Buffer Pool即【缓冲池,简称BP】,BP以Page页为单位,缓存最热的数据页(data page)与索引页(index page),Page页默认大小16K,BP的底层采用链表数据结构管理Page」。

上图描述了Buffer Pool在innoDB中的位置,通过它所在的位置我们可以大概知道它的工作流程:
所有数据页的读写操作都需要通过buffer pool进行,
innodb 读操作,先从buffer_pool中查看数据的数据页是否存在,如果不存在,则将page从磁盘读取到buffer pool中。
innodb 写操作,先把数据和日志写入 buffer pool 和 log buffer,再由后台线程以一定频率将 buffer 中的内容刷到磁盘,「这个刷盘机制叫做Checkpoint」。
写操作的事务持久性由redo log 落盘保证,buffer pool只是为了提高读写效率。

「Buffer Pool缓存表数据与索引数据,把磁盘上的数据加载到缓冲池,避免每次访问都进行磁盘IO,起到加速访问的作用」。
- Buffer Pool是一块内存区域,是一种**「降低磁盘访问的机制」**。
- 数据库的读写都是在buffer pool上进行,和undo log/redo log/redo log buffer/binlog一起使用,后续会把数据刷到硬盘上。
- Buffer Pool默认大小 128M,用于缓存数据页(16KB)。
show variables like 'innodb_buffer%';
Buffer Pool 是 innodb的数据缓存, 除了缓存「索引页」和「数据页」,还包括了 undo 页,插入缓存、自适应哈希索引、锁信息等。
「buffer pool绝大多数page都是 data page(包括index page)」。
「innodb 还有日志缓存 log buffer,保存redo log」。
二、Buffer Pool的控制块
Buffer Pool中缓存的是数据页,数据页大小跟磁盘默认数据页大小一样(16K),为了更好管理的缓存页,Buffer Pool有一个**「描述数据的区域」** :
「InnoDB 为每一个缓存的数据页都创建了一个单独的区域,记录的数据页的元数据信息,包括数据页所属表空间、数据页编号、缓存页在Buffer Pool中的地址,链表节点信息、一些锁信息以及 LSN 信息等,这个区域被称之为控制块」。
「控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边」,
控制块大概占缓存页大小的5%,16 * 1024 * 0.05 = 819个字节左右。

上图展示了控制块与数据页的对应关系,可以看到在控制块和数据页之间有一个碎片空间。
这里可能会有疑问,为什么会有碎片空间呢?
上面说到,数据页大小为16KB,控制块大概为800字节,当我们划分好所有的控制块与数据页后,可能会有剩余的空间不够一对控制块和缓存页的大小,这部分就是多余的碎片空间。如果把 Buffer Pool 的大小设置的刚刚好的话,也可能不会产生碎片。
三、Buffer Pool的管理
「Buffer Pool里有三个链表,LRU链表,free链表,flush链表,InnoDB正是通过这三个链表的使用来控制数据页的更新与淘汰的」。
3.1 Buffer Pool的初始化
「当启动 Mysql 服务器的时候,需要完成对 Buffer Pool 的初始化过程,即分配 Buffer Pool 的内存空间,把它划分为若干对控制块和缓存页」。
- 「申请空间」 Mysql 服务器启动,就会根据设置的Buffer Pool大小(innodb_buffer_pool_size)超出一些,去操作系统**「申请一块连续内存区域」**作为Buffer Pool的内存区域。 这里之所以申请的内存空间会比innodb_buffer_pool_size大一些,主要是因为里面还要存放每个缓存页的控制块。
- 「划分空间」 当内存区域申请完毕之后,数据库就会按照默认的缓存页的16KB的大小以及对应的800个字节左右的控制块的大小,在Buffer Pool中划分**「成若干个【控制块&缓冲页】对」**。
划分空间后Buffer Pool的缓存页是都是空的,里面什么都没有,当要对数据执行增删改查的操作的时候,才会把数据对应的页从磁盘文件里读取出来,放入Buffer Pool中的缓存页中。
3.2 Free链表
「在Buffer pool刚被初始化出来的时候,里面的数据页以及控制块都是空的」,当执行读写的时候磁盘的数据页会加载到Buffer pool的数据页中,当BufferPool中间有的页数据持久化到硬盘后,这些数据页又会被空闲出来。
以上的过程中会有一个问题,如何知道那些数据页是空的,那些是有数据的,只有找到空的数据页,才能吧数据写进去,一种方式是遍历所有的数据页,根据经验,一般只要是全部遍历,对于一个有追求的码农肯定是不能忍的,innoDB的开发者无疑更加不能忍,所以就有了free链表。
3.2.1 Free链表是个啥
「Free链表即空闲链表,是一个双向链表,由一个基础节点和若干个子节点组成,记录空闲的数据页对应的控制块信息」。如下

-
Free链表作用:帮助找到空闲的缓存页
-
「基节点」
-
「是一块单独申请的内存空间(约占40字节)。并不在Buffer Pool的连续内存空间里」。
-
包含链表中子节点中头节点地址,尾节点地址,以及当前链表中节点的数量等信息。
-
「子节点」
-
「每个节点就是个空闲缓存页的控制块,即只要一个缓存页空闲,那它的控制块就会被放入free链表」
-
每个控制块块里都有两个指针free_pre(指向上一个节点),free_next(指向下一个节点)
Free链表存在的意义就是描述Buffer Pool中的数据页,所以Free链表跟数据页的是一一对应的关系,如下图所示:
上图就是Free链表记录空闲数据页的对应关系,这里可能会有一个误区,以为这个控制块,在Buffer Pool里有一份,在free链表里也有一份,似乎在内存里有两个一模一样的控制块,「如果这么想就大错特错了」。
「误区说明」
「free链表本身其实就是由Buffer Pool里的控制块组成的,前文中说到每个控制块里都有free_pre/free_next两个指针,分别指向自己的上一个free链表的节点,以及下一个free链表的节点。」
「Buffer Pool中的控制块通过两个指针,就可以把所有的控制块串成一个free链表。上面为了画图看起来更加清晰,所以把free链表单独画了一份出来,表示他们之间的指针引用关系。」
「基于此,真正的关系图应该下图」:

这里之所以会把两个图都画画出来,是因为网上很多博客画的图都是类似上面哪一种,「会给人产生在Buffer Pool和free链表各有一个控制块的误区」,我在开始的时候也产生了这样的疑问,所以在这里说明记录一下。
3.2.2 磁盘页加载到BufferPool的缓存也流程
通过free链表只需要三步就可以将磁盘页加载到BufferPool的缓存中:
「步骤一」
「从free链表中取出一个空闲的控制块以及对应缓冲页」。

「步骤二」
「把磁盘上的数据页读取到对应的缓存页,同时把相关的一些描述数据写入缓存页的控制块(例如:页所在的表空间、页号之类的信息)」。

「步骤三」
「把该控制块对应的free链表节点从链表中移除,表示该缓冲页已经被使用了」。

- 下面用一个伪代码来描述一下控制块是如何在free链表节点中移除的,假设控制块的结构如下
/**
* 控制块
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址,
*/
private String blockId;
/**
* Free链表中当前控制块的上一个节点地址
*/
private String freePre;
/**
* Free链表中当前控制块的下一个节点地址
*/
private String freeNext;
}
假设有一个控制块n-1,他的上一个节点是描述数据块n-2,下一个节点是描述数据块n,则它的数据结构如下:
/**
* 控制块 n-1
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址 block_n-1,
*/
blockId = block_n-1;
/**
* Free链表中当前控制块的上一个节点地址 block_n-2
*/
freePre = block_n-2;
/**
* Free链表中当前控制块的下一个节点地址 block_n
*/
freeNext = block_n;
}
上图我们使用了控制块N,要从free链表中移除,则只需要把block_n-1中的freeNext设置为null即可, block_n就失去了链表的引用了。
/**
* 控制块 n-1
*/
publicclass CommandBlock {
/**
* 控制块id,也就是自己,可以理解为当前控制块的地址 block_n-1,
*/
blockId = block_n-1;
/**
* Free链表中当前控制块的上一个节点地址 block_n-2
*/
freePre = block_n-2;
/**
* Free链表中当前控制块的下一个节点地址 block_n
*/
freeNext = null;
}
3.2.3 如何确定数据页是否被缓存
了解了磁盘页是通过Free加载到Buffer Pool 的缓存页的过程,不能所有的数据都去磁盘读取然后通过Free链表写入缓存页中,有可能在缓存页中已经有了这个数据页了,那么怎么确定应不应该去缓存数据页呢?
「数据库提供了一个数据页缓存哈希表,以表空间号+数据页号作为key,缓存页控制块的地址作为value」。
#注意:value是控制块的地址,不是缓存页地址
{表空间号+数据页号:控制块的地址}
当使用数据页时,会先在数据页缓存哈希表中查找,如果找到了,则直接根据value定位控制块,然后根据控制块找到缓存页,如果没有找到,则读取磁盘数据页写入缓存,最后写入数据页缓存哈希表。
「在这个过程中一条语句要执行,大致会经历以下几个过程」:
- 通过sql语句中的数据库名和表名可以知道要加载的数据页处于哪个表空间。
- 「根据表空间号,表名称本身通过一致性算法得到索引根节点数据页号」。
- 进而根据根节点数据页号,找到下一层的数据页,可以从数据页缓存哈希表得到对应缓存页地址。
- 通过缓存页地址就可以在Buffer Pool池中定位到缓存页。
重点误区!!!重点误区!!!重点误区!!! 重要的事情说三遍: 上面说的一致性哈希算法**「指在数据字典中【根节点的页号,不是当前查找的数据的数据页号】」**,当我们得到根节点页号后,通过B+tree一层一层往下找,在找下一层之前会通过数据缓存哈希表去buffer pool里面看看这个层的数据页存不存在,不存在则去磁盘加载。
3.3 LRU链表
了解LRU链表之前,我们先来考虑两个问题:
- 第一个问题:前面说到当从磁盘中读取数据页到Buffer Pool的时候,会将对应的控制块从Free链表中移除,那这个控制块移除之后被放到哪里去了呢?
- 第二个问题:Buffer Pool的大小是128MB,当Buffer Pool中空闲数据页全部别加载数据之后,新的数据要怎么处理呢?
以上两个问题都需要LRU链表来解决,下面带着这两个问题来看看LRU链表。
3.3.1 LRU链表是个啥
Buffer pool 作为一个innodb自带的一个缓存池,数据的读写都是buffer pool中进行的,操作的都是Buffer pool中的数据页,但是Buffer Pool 的大小是有限的(默认128MB),所以对于一些频繁访问的数据是希望能够一直留在 Buffer Pool 中,而一些访问比较少的数据,我们希望能将它够释放掉,空出数据页缓存其他数据。
「基于此,InnoBD采用了LRU(Least recently used)算法,将频繁访问的数据放在链表头部,而不怎么访问的数据链表末尾,空间不够的时候就从尾部开始淘汰,从而腾出空间」。
「LRU链表本质上也是有控制块组成的」。
3.3.2 LRU链表的写入过程
「当数据库从磁盘加载一个数据页到Buffer Pool中的时候,会将一些变动信息也写到控制块中,并且将控制块从Free链表中脱离加入到LRU链表中」。过程如下:

梳理一下整个过程:
- 「步骤一:根据表空间号,表名称本身通过一致性算法得到数据页号(这里省略了树状查找过程)」
- 「步骤二:通过数据页缓存哈希表判断数据页是否被加载」
- 「步骤三:从Free链表中获取一个控制块」
- 「步骤四:读取磁盘数据」
- 「步骤六:将数据写到空闲的缓存页中」
- 「步骤七:将缓存页的信息写回控制块」
- 「步骤八:将回控制块从Free链表中移除」
- 「步骤九:将从Free中移除的控制块节点加入到LRU链表中」
3.3.3 LRU链表的淘汰机制
「LRU算法的设计思路就是:链表头部的节点是最近使用的,链表末尾的节点是最久没被使用的,当空间不够的时候就淘汰末尾最久没被使用的节点,从而腾出空间」。
「LRU算法的目的就是为让被访问的缓存页能够尽量排到靠前的位置」。
- 「LRU 算法的设计思路」
- 当访问的页在 Buffer Pool 里,就将该页对应的控制块移动到 LRU 链表的头部节点。
- 当访问的页不在 Buffer Pool 里,除了要把控制块放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的节点。
- 「LRU 的实现过程」

- 有一次数据访问,访问了数据页23,数据页23不在Buffer Pool 里,因此在磁盘加载之后会将末尾的22号页淘汰,然后将23加载到链表的头部。
- 此时,数据页7被访问了,因为数据页7就在链表中,也就是页在 Buffer Pool 里,所以直接将数据页7移动到链表的头部即可。
- 如下图, LRU 链表长度为 22,节点分别为1到22的数据页控制块,初始状态如下
以上就是LUR链表的实现过程,但是这种方式对于MySQL来说会有问题,所以MySQL并没有直接使用LRU链表的简单实现,而是对其做了一些改进,具体做了哪些改进,我们在下文中继续解释。
3.4 Flush链表
前面解释了我们**「对数据的读写都是先对Buffer Pool中的缓存页进行操作,然后在通过后台线程将脏页写入到磁盘,持久化到磁盘中,即刷脏」**。
「脏页:当执行写入操作时,先更新的是缓存页,此时缓存页跟磁盘页的数据就会不一致,这就是常说的脏页」。
既然产生了脏页,那就是需要更新磁盘,也就是常说的刷脏,那如何确定那些缓存页需要刷脏呢?也不能吧所有的缓存页都重新刷新一百年磁盘,或者挨个遍历比对,这种方式肯定是不可取的,此时就需要Flush链表了。
3.4.1 Flush链表是个啥
「Flush链表与Free链表的结构很类似,也由基节点与子节点组成」。
- Flush链表是一个双向链表,链表结点是被修改过的缓存页对应的控制块(更新过的缓存页)
- Flush链表作用:帮助定位脏页,需要刷盘的缓存页
- 「基节点」:和free链表一样,链接首尾结点,并存储了有多少个描述信息块
- 「子节点」
- 「每个节点是脏页对应的控制块,即只要一个缓存页被修改,那它的控制块就会被放入Flush链表」
- 每个控制块块里都有两个指针pre(指向上一个节点),next(指向下一个节点)
「前面说了控制块其实是在Buffer Pool中的,控制块是通过上下节点的引用,组成一个链表,所以只需要通过基节点挨个遍历子节点,找到需要刷脏的数据页即可」。
3.4.2 Flush链表写入过程
当我们在写入数据的时候,我们知道磁盘IO的效率很慢,所以MySQL不会直接更新直接更新磁盘,而是经过以下两个步骤:
- 第一步:更新Buffer Pool中的数据页,一次内存操作;
- 第二步:将更新操作顺序写Redo log,一次磁盘顺序写操作;
这样的效率是最高的。顺序写Redo log,每秒几万次,问题不大。

上图中描述了在更新数据页的时候,Flush链表的写入过程,其实这只是在被更新的数据已经别加载到Buffer Pool的前提下,如果我们要更新的数据没有别预先加载,那这个过程是不是会先去读取磁盘呢?实际上并不会,MySQL为了提高性能,减少磁盘IO,做了很多的优化,当数据页不存在Buffer Pool中的时候,会使用写缓冲(change buffer)来做更新操作,具体的实现原理下一篇文章再展开解释。
「当控制块被加入到Flush 链表后,后台线程就可以遍历 Flush 链表,将脏页写入到磁盘」。
3.5 Buffer Pool 的数据页
上述了解了三种链表以及它们的使用方式,我们可以总结一下,「其实Buffer Pool 里有三种数据页页和链表来管理数据」。

- Free Page(空闲页) 表示此数据页未被使用,是空的,其控制块位于 Free 链表;
- 「Clean Page(干净页)」 表示此数据页已被使用,缓存了数据, 其控制块位于LRU 链表。
- 「Dirty Page(脏页)」 表示此数据页【已被使用】且【已经被修改】,数据页中数据和磁盘上的数据已经不一致。 当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该页就变成了干净页。 「脏页的控制块同时存在于 LRU 链表和 Flush 链表」。
Linux C/C++后端服务器开发 学习资料、教学视频和学习路线图(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),有需要的可以自行添加学习交流群 739729163 领取

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)