
SAM+遥感:RSPrompter,遥感图像实例分割利器!
关注公众号,发现CV技术之美本文转载自AI Around。本篇文章为大家介绍RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model (基于视觉基础模型的遥感实例分割提示学习),代码已开源。1. 背景借助大量的训练数据(SA-1B),Meta AI
关注公众号,发现CV技术之美
本文转载自AI Around。
本篇文章为大家介绍RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model (基于视觉基础模型的遥感实例分割提示学习),代码已开源。
1. 背景
借助大量的训练数据(SA-1B),Meta AI Research 提出的基础 "Segment Anything Model"(SAM)表现出了显著的泛化和零样本能力。尽管如此,SAM 表现为一种类别无关的实例分割方法,严重依赖于先验的手动指导,包括点、框和粗略掩模。此外,SAM 在遥感图像分割任务上的性能尚未得到充分探索和证明。
本文考虑基于 SAM 基础模型设计一种自动化实例分割方法,该方法将语义类别信息纳入其中,用于遥感图像。受prompt learning启发,本文通过学习生成合适的Prompt来作为 SAM 的输入。这使得 SAM 能够为遥感图像生成语义可辨别的分割结果,该方法称之为 RSPrompter。本文还根据 SAM 社区的最新发展提出了几个基于SAM的实例分割衍生方法,并将它们的性能与 RSPrompter 进行了比较。在 WHU Building、NWPU VHR-10 和 SSDD 数据集上进行的广泛实验结果验证了所提出的方法的有效性。
论文:https://arxiv.org/abs/2306.16269
代码:https://github.com/KyanChen/RSPrompter
由于在超过十亿个掩模上进行训练,SAM 可以在不需要额外训练的情况下分割任何图像中的任何对象,展示了其在处理各种图像和对象时显著的泛化能力。这为智能图像分析和理解创建了新的可能性和途径。然而,由于其交互式框架,SAM 需要提供先验的Prompt,例如点、框或掩模来表现为一种类别无关分割方法, 如下图(a)所示。显然,这些限制使 SAM 不适用于遥感图像的全自动解译。

(a)显示了基于点、基于框、SAM 的“全图”模式(对图像中的所有对象进行分割)以及 RSPrompter 的实例分割结果。SAM 执行类别无关的实例分割,依赖于手动提供的先验prompt。(b)展示了来自不同位置的点_prompt_、基于两个点的_prompt_和基于框的_prompt_的分割结果。_prompt_的类型、位置和数量严重影响 SAM 的结果。
此外,我们观察到遥感图像场景中的复杂背景干扰和缺乏明确定义的物体边缘对 SAM 的分割能力构成重大挑战。SAM 很难实现对遥感图像目标的完整分割,其结果严重依赖于prompt类型、位置和数量。在大多数情况下,精细的手动prompt对于实现所需效果至关重要,如上图(b)所示。这表明 SAM 在应用于遥感图像的实例分割时存在相当大的限制。
为了增强基础模型的遥感图像实例分割能力,本文提出了RSPrompter,用于学习如何生成可以增强 SAM 框架能力的prompt。本文的动机在于 SAM 框架,其中每个prompt组可以通过掩码解码器获取实例化掩码。想象一下,如果我们能够自动生成多个与类别相关的prompt,SAM 的解码器就能够产生带有类别标签的多个实例级掩码。然而,这个过程存在两个主要挑战:(i)类别相关的prompt从哪里来?(ii)应选择哪种类型的prompt作为掩膜解码器的输入?
由于 SAM 是一种类别无关的分割模型,其编码器的深度特征图无法包含丰富的语义类别信息。为了克服这一障碍,我们提取编码器的中间层特征以形成Prompter的输入,该输入生成包含语义类别信息的prompt。其次,SAM 的prompt包括点(前景/背景点)、框或掩膜。考虑到生成点坐标需要在原始 SAM prompt的流形中搜索,这严重限制了prompt器的优化空间,我们进一步放宽了prompt的表示,并直接生成prompt嵌入,可以理解为点或框的嵌入,而不是原始坐标。这种设计还避免了从高维到低维再返回到高维特征的梯度流的障碍,即从高维图像特征到点坐标,然后再到位置编码。
本文还对 SAM 模型社区中当前进展和衍生方法进行了全面的调查和总结。这些主要包括基于 SAM 骨干网络的方法、将 SAM 与分类器集成的方法和将 SAM 与检测器结合的技术。
2. 方法
2.1 SAM模型
SAM 是一个交互式分割框架,它根据给定的prompt(如前景/背景点、边界框或掩码)生成分割结果。它包含三个主要组件:图像编码器、prompt编码器和掩膜解码器。SAM 使用基于 Vision Transformer (ViT)的预训练掩码自编码器将图像处理成中间特征,并将先前的prompt编码为嵌入Tokens。随后,掩膜解码器中的交叉注意力机制促进了图像特征和prompt嵌入之间的交互,最终产生掩膜输出。该过程可以表达为:
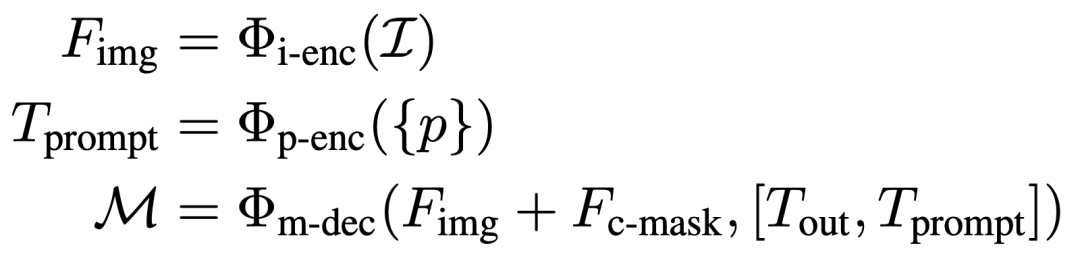
2.2 SAM 的实例分割扩展
除了本文中提出的 RSPrompter 之外,还介绍了其他三种基于 SAM 的实例分割方法进行比较,如下图(a)、(b) 和 (c) 所示。本文评估了它们在遥感图像实例分割任务中的有效性并启发未来的研究。这些方法包括:外部实例分割头、分类掩码类别和使用外部检测器,分别称为SAM-seg、SAM-cls 和 SAM-det。
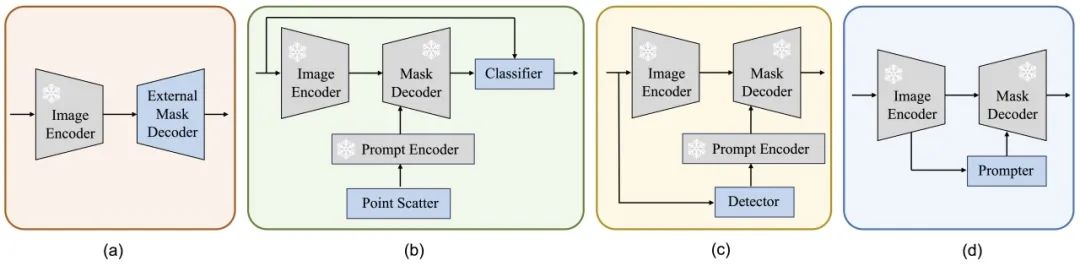
2.2.1 SAM-seg
SAM-seg利用了 SAM 图像编码器存在的知识,同时保持编码器不变。它从编码器中提取中间层特征,使用卷积块进行特征融合,然后使用现有的实例分割(Mask R-CNN和 Mask2Former)执行实例分割任务。这个过程可以表示为:

****2.2.2 SAM-cls
在 SAM-cls 中,首先利用 SAM 的“全图像”模式来分割图像中的所有潜在实例目标。其实现方法是在整个图像中均匀分布点并将每个点视为实例的prompt输入。在获得图像中所有实例掩码后,可以使用分类器为每个掩码分配标签。这个过程可以描述如下:
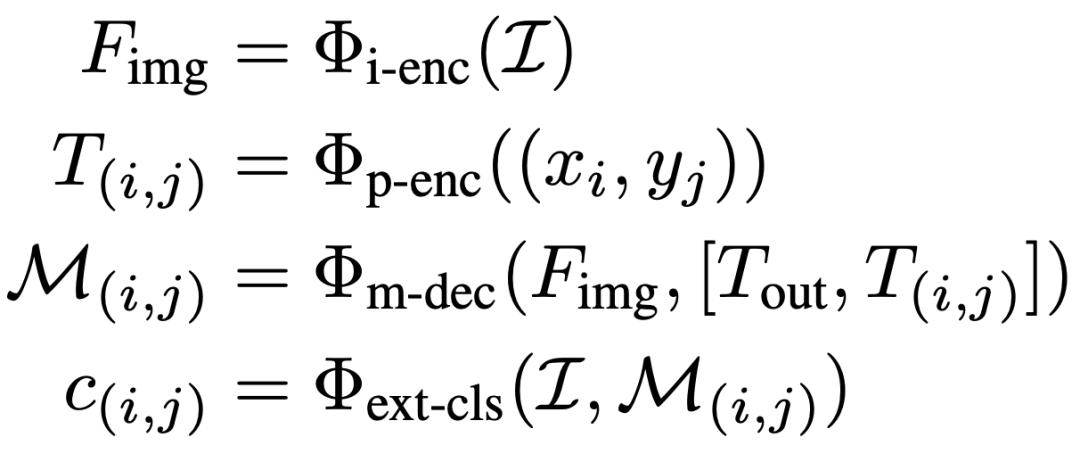
为了便捷,本文直接使用轻量级的 ResNet18 来标记掩码。其次,可以利用预训练的 CLIP 模型,使 SAM-cls 能够在不进行额外训练的情况下运行以达到零样本的效果。
****2.2.3 SAM-det
SAM-det 方法更加简单直接,已经被社区广泛采用。首先训练一个目标检测器来识别图像中所需的目标,然后将检测到的边界框作为prompt输入到 SAM 中。整个过程可以描述为:
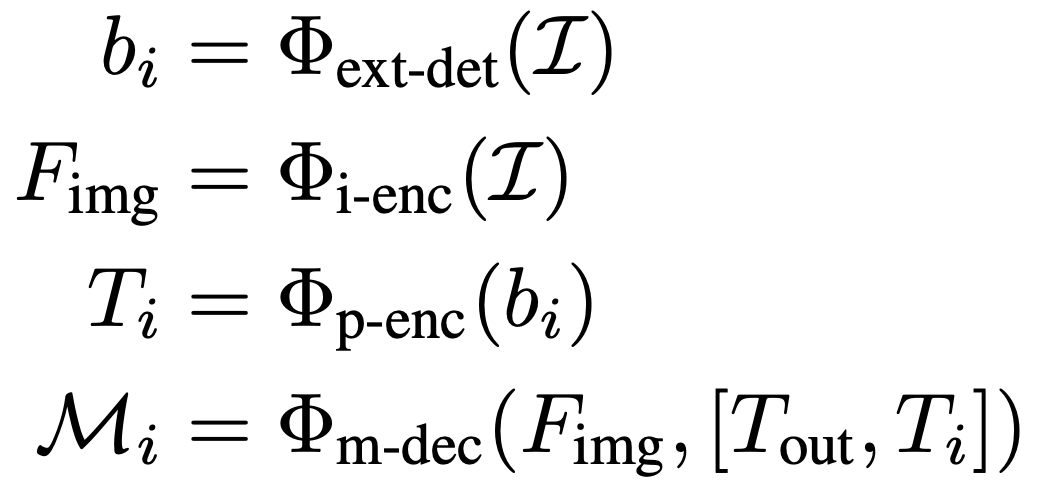
2.3 RSPrompter
2.3.1 概述
上图(d)展示了所提出的RSPrompter的结构,我们的目标是训练一个面向SAM的prompter,可以处理测试集中的任何图像,同时定位对象,推断它们的语义类别和实例掩码,可以表示为以下公式:
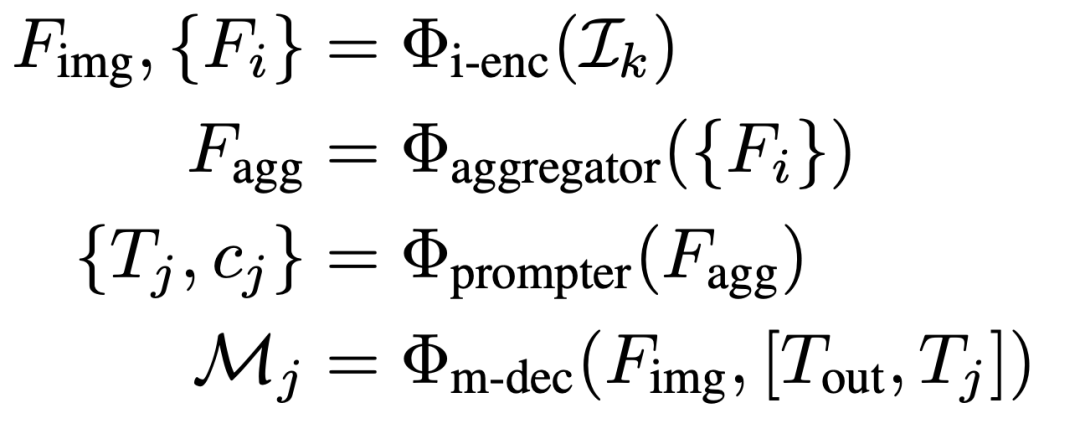
图像通过冻结的SAM图像编码器处理,生成Fimg和多个中间特征图Fi。Fimg用于SAM解码器获得prompt-guided掩码,而Fi则被一个高效的特征聚合和prompt生成器逐步处理,以获取多组prompt和相应的语义类别。为设计prompt生成器,本文采用两种不同的结构,即锚点式和查询式。
****2.3.2 特征聚合器
SAM是基于prompt的类别无关的分割模型,为了在不增加prompter计算复杂度的情况下获得语义相关且具有区分性的特征,本文引入了一个轻量级的特征聚合模块。如下图所示,该模块学习从SAM ViT骨干网络的各种中间特征层中表示语义特征,可以递归地描述为:
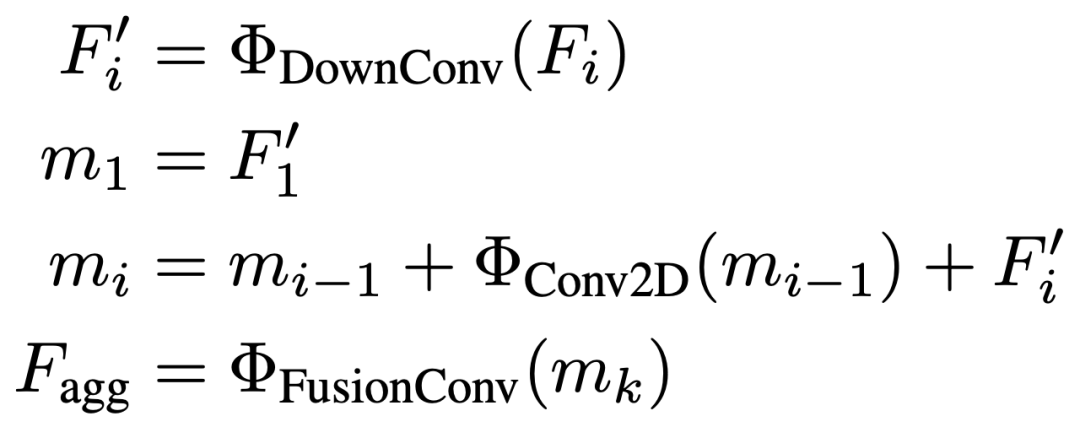

****2.3.3 锚点式Prompter
架构: 首先使用基于锚点的区域提议网络(RPN)生成候选目标框。接下来,通过RoI池化获取来自位置编码过的特征图的单个对象的视觉特征表示。从视觉特征中派生出三个感知头:语义头、定位头和prompt头。语义头确定特定目标类别,而定位头在生成的prompt表示和目标实例掩码之间建立匹配准则,即基于定位的贪心匹配。prompt头生成SAM掩码解码器所需的prompt嵌入。整个过程如下图所示,可以用以下公式表示:
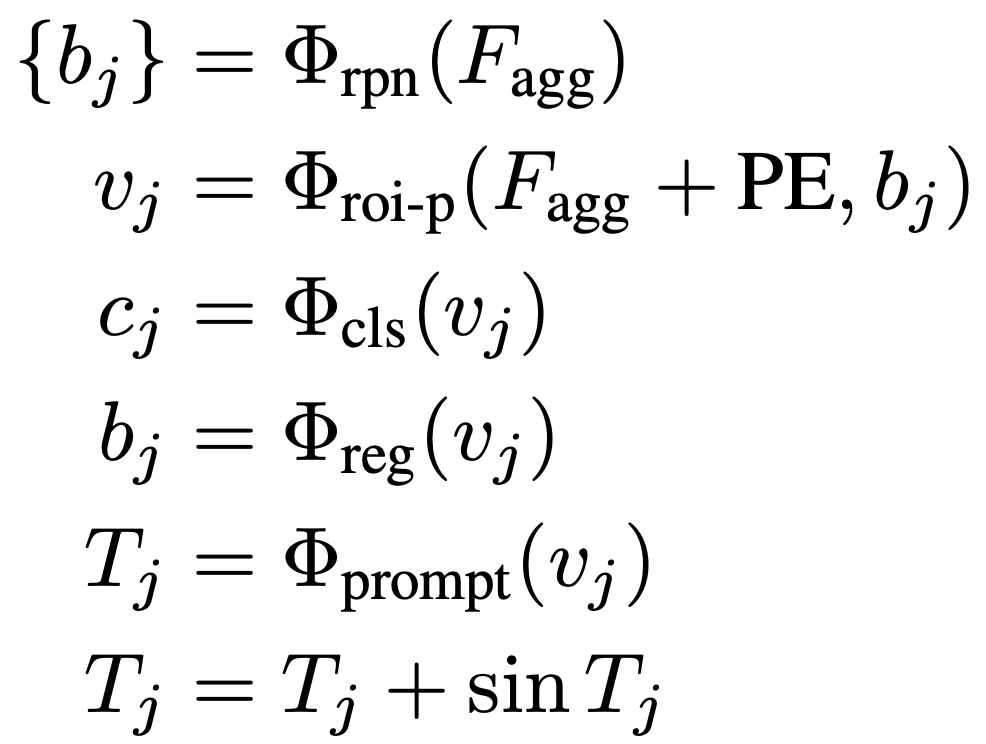
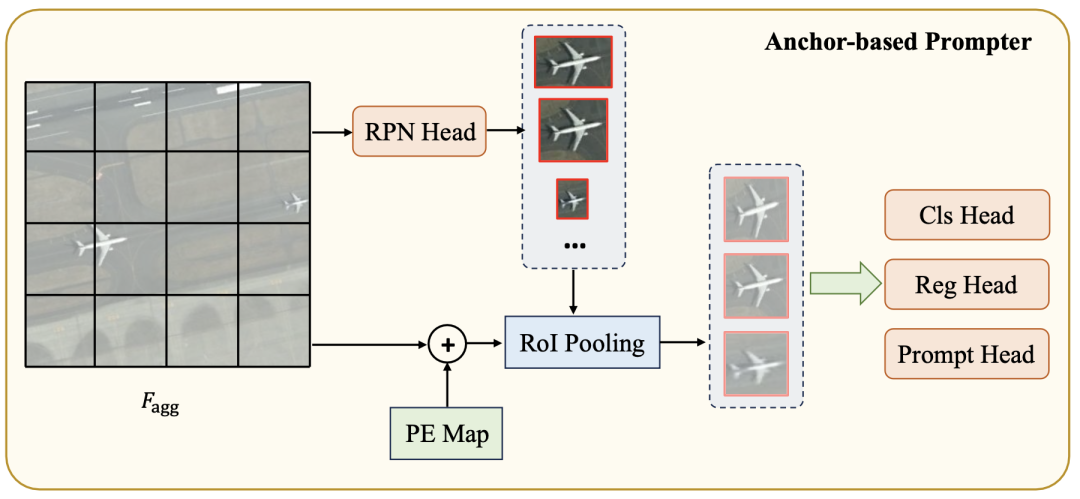
损失: 该模型的损失包括RPN网络的二元分类损失和定位损失,语义头的分类损失,定位头的回归损失以及冻结的SAM掩码解码器的分割损失。总损失可以表示为:
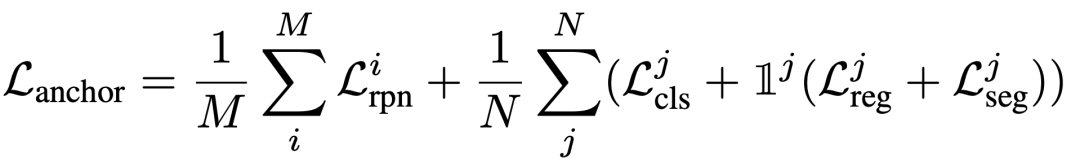
******2.3.4 **查询式Prompter
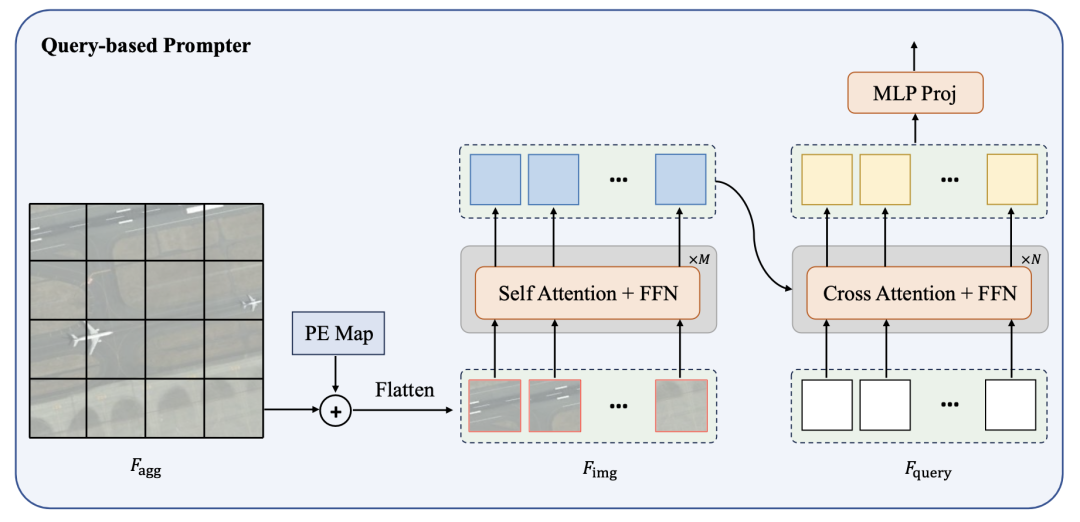
架构: 锚点式Prompter相对复杂,涉及到利用边界框信息进行掩码匹配和监督训练。为了简化这个过程,提出了一个基于查询的Prompter,它以最优传输为基础。查询式Prompter主要由轻型Transformer编码器和解码器组成。编码器用于从图像中提取高级语义特征,而解码器则通过与图像特征进行attention交互,将预设的可学习查询转换为SAM所需的prompt嵌入。整个过程如下图所示,可以表示为:
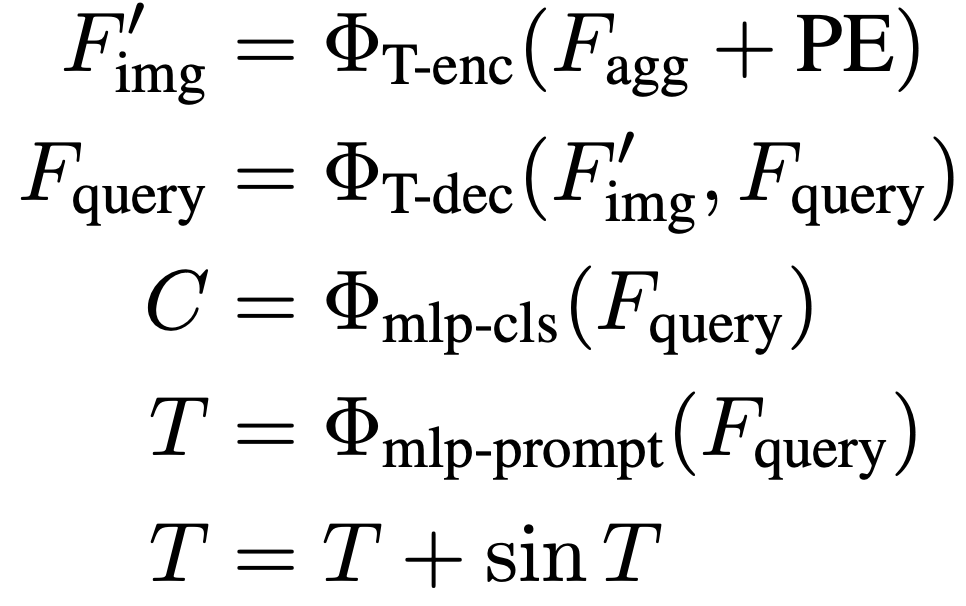
损失: 查询式Prompter的训练过程主要涉及两个关键步骤:(i)将由SAM掩码解码器解码的掩码与真实实例掩码进行匹配;(ii)随后使用匹配标签进行监督训练。在执行最优传输匹配时,我们定义考虑预测的类别和掩码的匹配成本,如下所示:
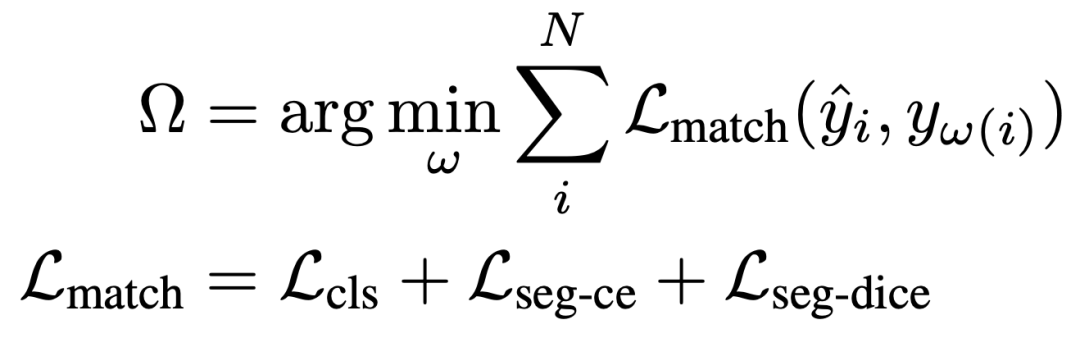
一旦每个预测实例与其相应的真实值配对,就可以应用监督项。这主要包括多类分类和二进制掩码分类,如下所述:
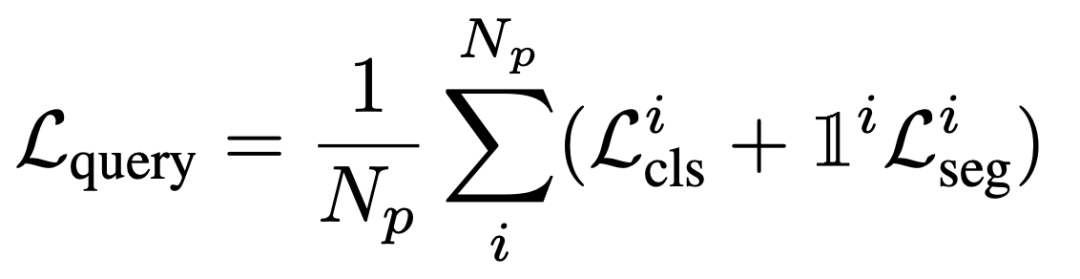
3. 实验
在本文中使用了三个公共的遥感实例分割数据集:WHU建筑提取数据集,NWPU VHR-10数据集和SSDD数据集。WHU数据集是单类建筑物目标提取分割,NWPU VHR-10是多类目标检测分割,SSDD是SAR船只目标检测分割。使用 mAP 进行模型性能评价。
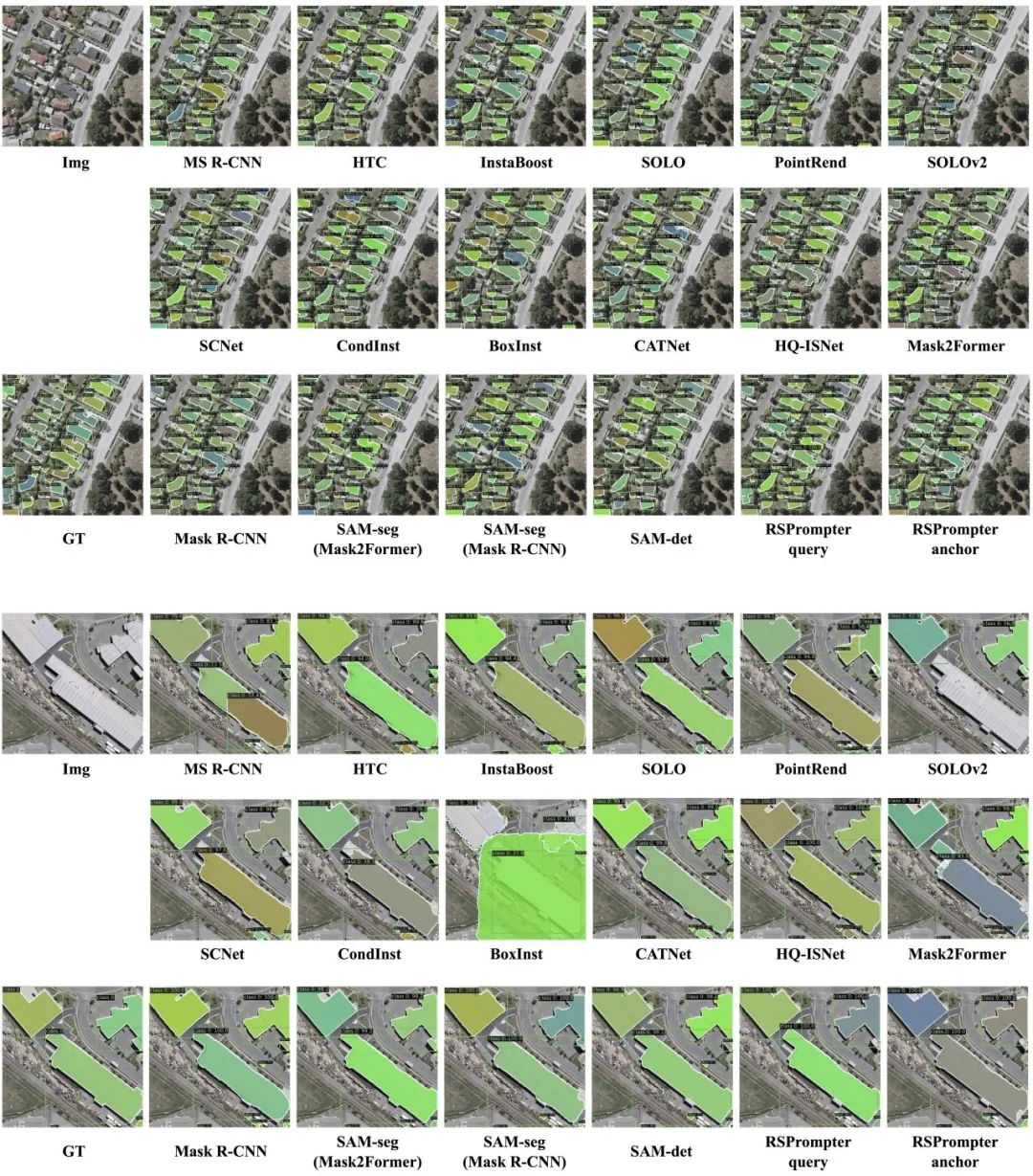
3.1 在WHU上的结果

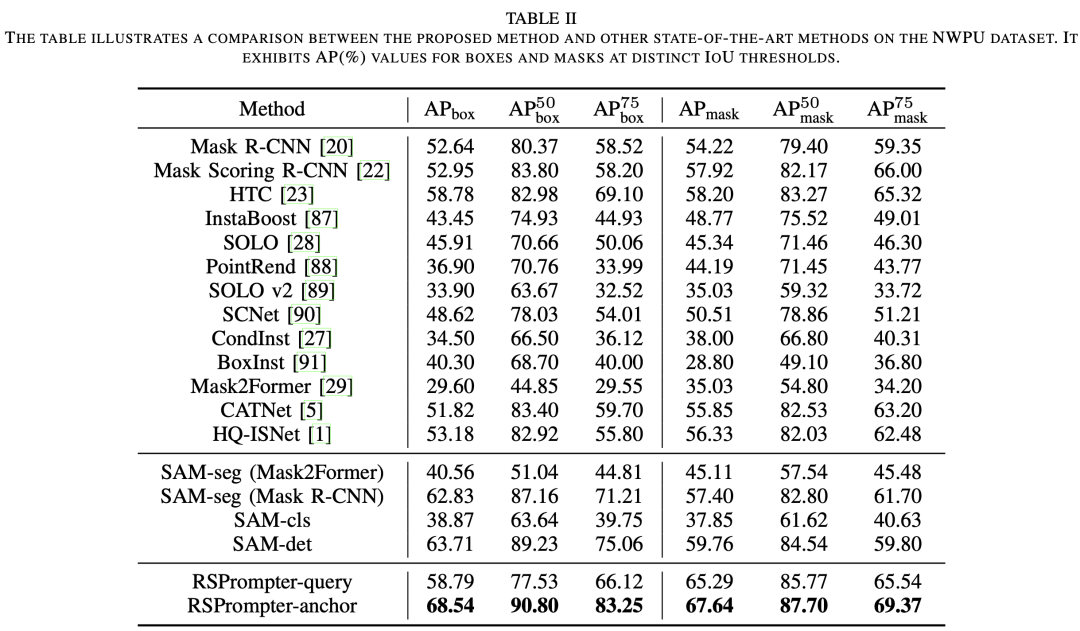
****3.2 在NWPU上的结果

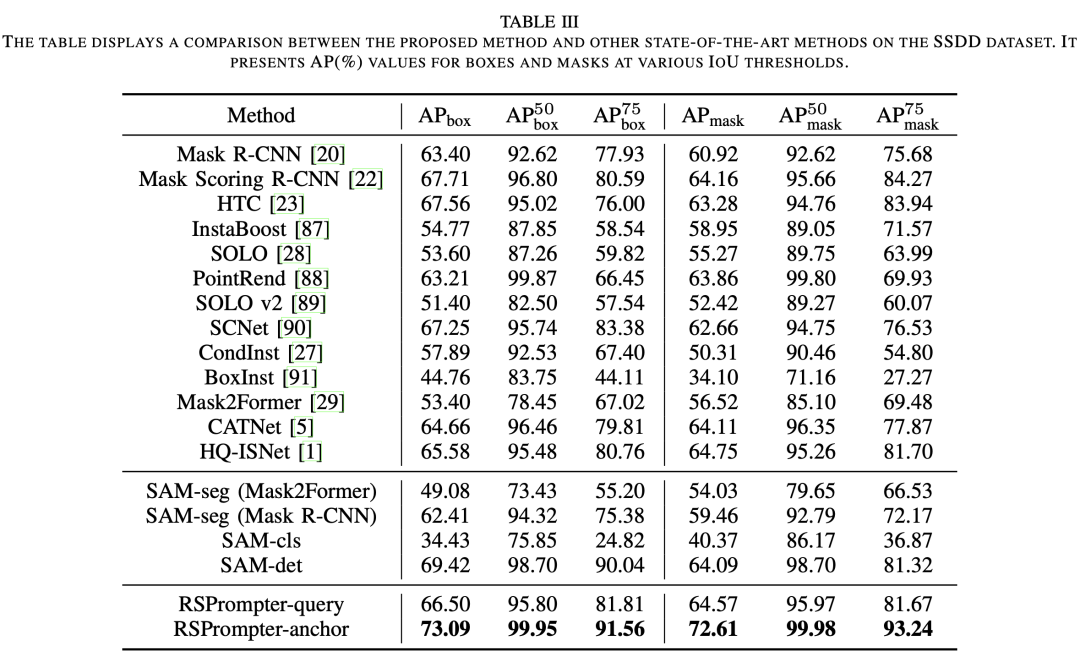
****3.3 在SSDD上的结果

4. 总结
在本文中,我们介绍了RSPrompter,这是一种用于遥感图像实例分割的prompt learning方法,利用了SAM基础模型。RSPrompter的目标是学习如何为SAM生成prompt输入,使其能够自动获取语义实例级掩码。相比之下,原始的SAM需要额外手动制作prompt,并且是一种类别无关的分割方法。RSPrompter的设计理念不局限于SAM模型,也可以应用于其他基础模型。基于这一理念,我们设计了两种具体的实现方案:基于预设锚点的RSPrompter-anchor和基于查询和最优传输匹配的RSPrompter-query。此外,我们还调查并提出了SAM社区中针对此任务的各种方法和变体,并将它们与我们的prompt learning方法进行了比较。通过消融实验验证了RSPrompter中每个组件的有效性。同时,三个公共遥感数据集的实验结果表明,我们的方法优于其他最先进的实例分割技术,以及一些基于SAM的方法。

END
欢迎加入「遥感图像」交流群👇备注:遥感


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)