
多目标优化遗传算法NSGA-Ⅱ
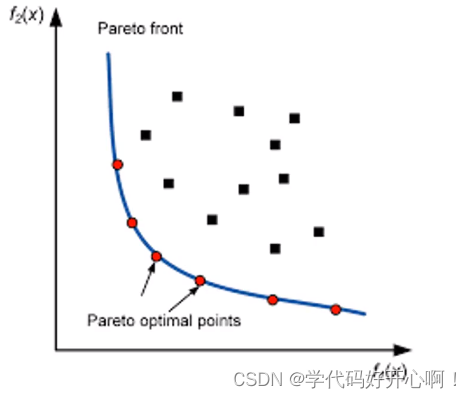
在接触编程之前,我们可能会在运筹学等相关教材中了解过多目标优化的知识, 其问题结构如下图所示:首先,要注意的是,决策变量要与每一个目标函数有关,假设x1、x2只与f1(x)有关,x3、x4只与f2(x)有关,那么这就不叫多目标优化问题,而应该叫做单目标优化问题。其次,每个目标函数之间要存在矛盾,比如目标函数f1(x)代表一台笔记本的性能和目标函数f2(x)代表一台笔记本的便携性。所谓鱼和熊掌不可兼
目录
Step2:快速非支配排序(与后面的循环里的快速非支配排序原理不一致)
参考资料:
2022.2.5韩老师十七课时(上)多目标优化:NSGA-II算法_哔哩哔哩_bilibili、
基于遗传算法的多目标优化算法(附代码案例)_多目标优化遗传算法_小潘爱上编程的博客-CSDN博客
遗传算法NSGA-2的基本计算流程讨论_哔哩哔哩_bilibili
(13条消息) NSGA-II算法介绍_不一样的烟火呦的博客-CSDN博客
一、什么是多目标优化?
在接触编程之前,我们可能会在运筹学等相关教材中了解过多目标优化的知识, 其问题结构如下图所示:

首先,要注意的是,决策变量要与每一个目标函数有关,假设x1、x2只与f1(x)有关,x3、x4只与f2(x)有关,那么这就不叫多目标优化问题,而应该叫做单目标优化问题。
其次,每个目标函数之间要存在矛盾,比如目标函数f1(x)代表一台笔记本的性能和目标函数f2(x)代表一台笔记本的便携性。所谓鱼和熊掌不可兼得,在想要一台性能出色的笔记本必然会损失其便携性。所以目标函数要相互矛盾,才可以构成多目标优化问题,反之,如果是目标函数分别为笔记本的性能和笔记本价格,这便成了单目标问题。
在传统多目标优化中,我们多采用加权法、整数规划和线性规划法等方法进行多目标优化。要注意的是,在单目标优化中,是可以找到最优解的,但是在多目标优化问题中,是找不到唯一最优解的。举个例子:
在一个双目标最优化问题求解的过程中,我们只能通过方法得到一组最优解,这一组解,就是帕累托前沿面,上面分布着该多目标优化问题的最优解集。能求出这样最优的帕累托前沿面,就可以让决策者根据自己的喜好来选择不同的最优解。
二、什么是NSGA- II
NSGA- II(nondominated sorting genetic algorithm II,带精英策略的快速非支配排序遗传算法),在学习该方法之前,我们有必要阐述清楚几个概念:
严谨版:
1、支配(dominnate)与非劣(non - inferior)
在多目标优化问题中,如果个体 p 至少有一个目标比个体 q 的好,而且个体 p 的所有目标都不比个体 q 的差,那么称个体 p 支配个体 q(p dominates q),或者称个体 q 受个体 p 支配(qis dominated by p),也可以说,个体 p 非劣于个体 q(p is non - inferior to q)。
2、序值(rank)和前端(front)
如果 p 支配 q,那么 p 的序值比 q 的低。如果 p 和 q 互不支配,或者说, p 和 q 相互非劣,那么 p 和 q 有相同的序值。序值为 1 的个体属于第一前端,序值为 2 的个体属于第二前端,依次类推。显然,在当前种群中,第一前端是完全不受支配的,第二前端受第一前端中个体的支配。这样,通过排序,可以将种群中的个体分到不同的前端。
3、拥挤距离(crowding distance)
拥挤距离用来计算某前端中的某个体与该前端中其他个体之间的距离,用以表征个体间的拥挤程度。显然,拥挤距离的值越大,个体间就越不拥挤,种群的多样性就越好。需要指出的是,只有处于同一前端的个体间才需要计算拥挤距离,不同前端之间的个体计算拥挤距离是没有意义的。
通俗版:
1、支配(dominnate)与非劣(non - inferior)
A、B是不同的两种策略,来应对很多目标,如果对所有目标来进行打分,A策略的任何一项目标都不低于B并且至少有一项大于B策略的评分,这叫做A支配B,或者A非劣B。
举个例子:班里有甲乙丙丁两名同学。在一次考试中,甲的每一科成绩都比丁高;乙和丁的英语一样,但是其余学科,乙均比丁的成绩高;丙和丁的成绩完全一样。在这里,各类同学对应着不同的策略,成绩对应着不同的目标。这样可以说甲支配丁,乙支配丁,丙不支配丁。
2、序值(rank)和前端(front)
通过一张图来理解,Rank1就是第一前端,Rank2是第二前端,第一前端的任何一个解都要比第二前端的目标函数高。相当于把相同目标函数得分的一类解都分到不同的前端。

3、拥挤距离(crowding distance)
也是通过一张图理解,可以看到在左上角和右下角区间内,密度明显比Cuboid里的密度大,这里的,需要注意的是拥挤距离必须放在同一类前端才有讨论的意义。我的理解为,拥挤距离越小,说明密度越大,这一片区域“探索”的越彻底,容易陷入局部最优解。反观密度小的区域内,密度小,说明“探索”的并不彻底,有很大的开发价值。后面会详细阐述拥挤距离的概念和用途。

三、NSGA- II的原理和过程

Step1:初始化种群
随机生成原始种群,随机分布在整个空间。
种群:就是一堆解的集合,譬如 x1、x2、x3……xn,其中每一个就是个体,譬如x1。
Step2:快速非支配排序(与后面的循环里的快速非支配排序原理不一致)
这里相当于复制种群,原先数量为N的种群P,通过例如轮盘赌(Roulette Wheel Selection)选择法进行筛选得到Q,种群数量由N变为2N。这一步我认为是扩大初代的种群个数,从而有利于种群的多样性。
Step 3 :选择、交叉、变异,生成新种群
选择:操作模仿自然界中的“优胜劣汰”法则,若个体的适应度高则其有更大概率被遗传到下一代,反之则概率较小。进行选择操作的方法有许多,比如轮盘赌选择、排序选择、最优个体保存、随机联赛选择等。
交叉:操作模拟自然界中染色体的交叉换位现象,用于生成新个体,决定了算法的全局搜索能力。
变异:操作是模拟生物的基因变异,同交叉操作一样,都用于产生新个体。
Step 4 :将父系种群和子系种群组合

种群数量由N变为2N。
Step 5 :快速非支配排序(真正的核心)

通过适应度测试得出不同前端的个体。例如F1、F2、F3。为了保持种群数量稳定性。从图中可以看出F1、F2前端的所有都会进入下一轮筛选。而F3中会有部分被淘汰掉,写到这里,有同学肯定就产生疑惑了,既然他们的前端一样,那说明优先度是一样的,怎么来区分呢?
在这里,就要用到之前提及的拥挤度。
拥挤距离越小,说明密度越大,这一片区域“探索”的越彻底,容易陷入局部最优解。反观密度小的区域内,密度小,说明“探索”的并不彻底,有很大的开发价值。所以会优先选出拥挤距离大的个体,来进入下一轮筛选,从而全面的探索各种可能性。
Step 6 :产生新的种群
往复迭代,即可求出最优的帕累托前沿面,从而寻找到一组最优解。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)