K8S漏洞修复
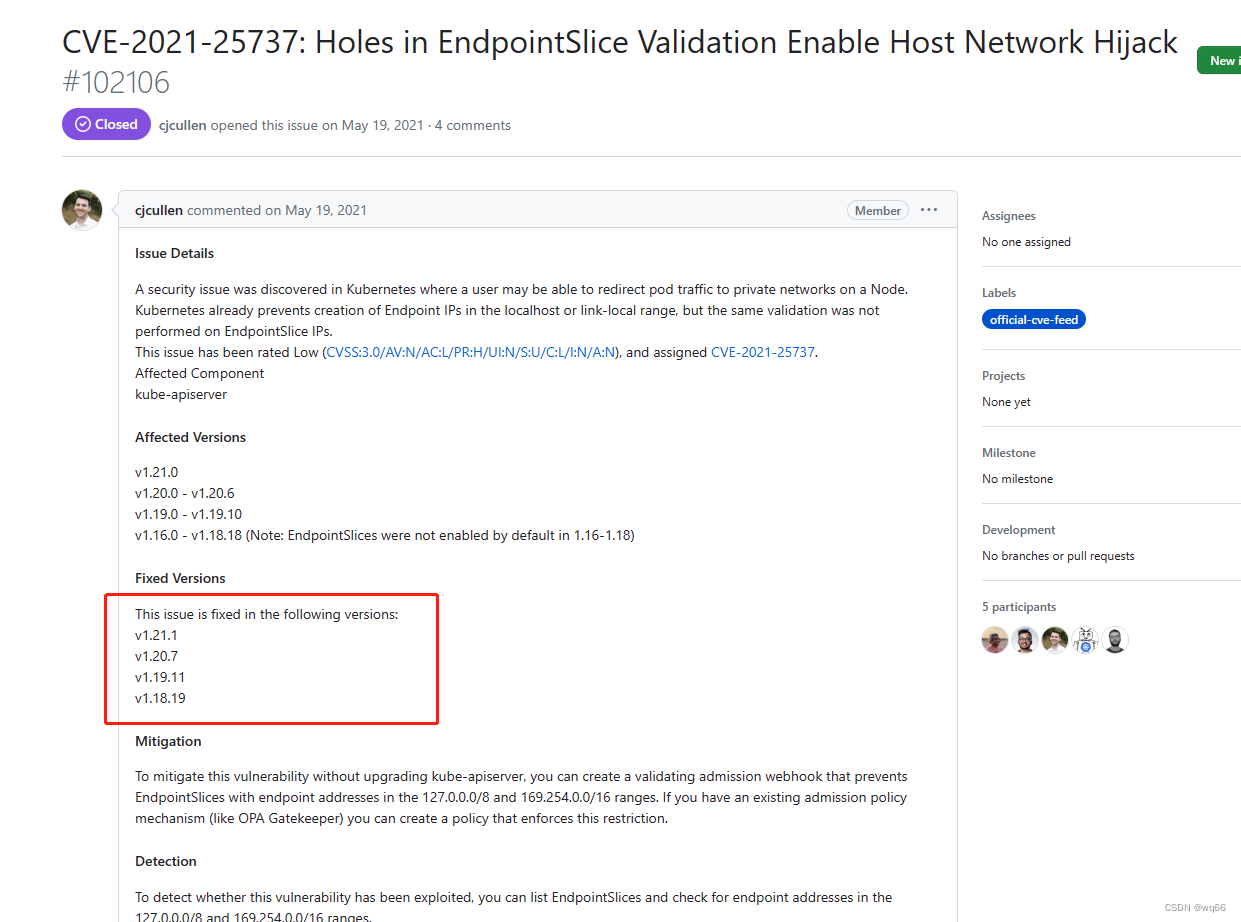
客户环境存在K8S的漏洞 分别是:Kubernetes kube-apiserver 输入验证错误漏洞(CVE-2021-25735) Kubernetes kube-apiserver信息泄露漏洞(CVE-2021-25737) 这两个漏洞官方给的建议就是升级到他们修复的版本。 以及因为api-server组件引起的openssl漏洞
CVE-2021-25737、CVE-2021-25735漏洞解决办法
一、前言
离线包下载地址:
链接:https://pan.baidu.com/s/1MuzhTs8ZIq8obCPRt2C6aw?pwd=yd8q
提取码:yd8q
客户环境存在K8S的漏洞 分别是:
Kubernetes kube-apiserver 输入验证错误漏洞(CVE-2021-25735)
Kubernetes kube-apiserver信息泄露漏洞(CVE-2021-25737)
这两个漏洞官方给的建议就是升级到他们修复的版本
下面可以看到一个建议升级到1.19.10,一个建议升级到1.19.11,为了防止升级到这两个版本又出现其他漏洞直接升级到1.19.16版本(1.9X版本目前最新的版本)


升级说明
可用的K8S集群,使用kubeadm搭建
可以小版本升级,也可以跨一个大版本升级,不建议跨两个大版本升级
对集群资源做好备份
升级目标
将kubernetes 1.19.0版本升级到1.19.16版本
现有集群版本已经节点如下:
[root@localhost shengji]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 16m v1.19.0
k8s-node1 Ready <none> 15m v1.19.0
k8s-node2 Ready <none> 15m v1.19.0
备份集群
kubeadm upgrade 不会影响你的工作负载,只会涉及 Kubernetes 内部的组件,但备份终究是好的。这里主要是对集群的所有资源进行 备份,我使用的是一个开源的脚本,项目地址:
下载脚本
mkdir -p /data
cd /data
unzip k8s-backup-restore.zip
执行备份
chmod +x /data/k8s-backup-restore/bin/k8s_backup.sh
cd /data/k8s-backup-restore/bin
./bin/k8s_backup.sh
如果要恢复怎么办?只需要执行如下步骤。
创建恢复目录
这里只是验证一下,我手动把deployment删除的
[root@k8s-master restore]# kubectl delete deployment nginx
deployment.apps "nginx" deleted
[root@k8s-master restore]# kubectl delete deployment redis
deployment.apps "redis" deleted
[root@k8s-master restore]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-6d56c8448f-qhm2b 1/1 Running 0 82m
kube-system coredns-6d56c8448f-zswxd 1/1 Running 0 76m
kube-system etcd-k8s-master 1/1 Running 0 95m
kube-system kube-apiserver-k8s-master 1/1 Running 0 95m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 95m
kube-system kube-flannel-ds-amd64-lzfzr 1/1 Running 0 109m
kube-system kube-flannel-ds-amd64-rjfxp 1/1 Running 0 109m
kube-system kube-flannel-ds-amd64-vtwwl 1/1 Running 0 109m
kube-system kube-proxy-jz5rj 1/1 Running 0 94m
kube-system kube-proxy-q4lvj 1/1 Running 0 94m
kube-system kube-proxy-v7hsv 1/1 Running 0 94m
kube-system kube-scheduler-k8s-master 1/1 Running 0 95m
mkdir -p /data/k8s-backup-restore/data/restore
将需要恢复的YAML清单复制到该目录下
cp default_deployments_redis.yaml ../../restore/
cp default_deployments_nginx.yaml ../../restore/
执行恢复命令
chmod +x /data/k8s-backup-restore/bin/k8s_restore.sh
cd /data/k8s-backup-restore
./bin/k8s_restore.sh
#验证
[root@k8s-master k8s-backup-restore]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6799fc88d8-9qbbp 1/1 Running 0 53s
nginx-6799fc88d8-pdlpq 1/1 Running 0 53s
redis-6749d7bd65-5wtd2 1/1 Running 0 53s
redis-6749d7bd65-kjlps 1/1 Running 0 53s
升级集群
Master升级
#安装1.19.16版本的kubeadm、kubectl、kubelet
tar xf kubeadm-v1.19.16.tar.gz
rpm -ivh kubeadm/*.rpm --nodeps --force
#导入1.19.16版本镜像
tar xf k8s-master-image-v1.19.16.tar.gz
[root@k8s-master shengji]# cd images/
for i in `ls`;do docker load -i $i ;done
#安装完成后验证版本是否正确。
[root@k8s-master shengji]# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.16", GitCommit:"e37e4ab4cc8dcda84f1344dda47a97bb1927d074", GitTreeState:"clean", BuildDate:"2021-10-27T16:24:44Z", GoVersion:"go1.15.15", Compiler:"gc", Platform:"linux/amd64"}
排空节点
#将节点标记为不可调度状态,这意味着Kubernetes不会将新的Pod调度到该节点上
kubectl cordon k8s-master
#kubectl drain命令用于将节点从Kubernetes集群中删除。在执行该命令之前,Kubernetes会将节点上的所有Pod转移到其他节点上,以确保应用程序的高可用性。--ignore-daemonsets选项表示在删除节点之前,忽略DaemonSet类型的Pod,因为DaemonSet类型的Pod应该在每个节点上运行,不能被转移。
kubectl drain k8s-master --ignore-daemonsets
运行升级计划,查看是否可以升级
kubeadm upgrade plan
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.19.0
[upgrade/versions] kubeadm version: v1.19.16
W0523 14:44:31.938911 23809 version.go:103] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable.txt": Get "https://dl.k8s.io/release/stable.txt": dial tcp 34.107.204.206:443: connect: no route to host
W0523 14:44:31.938957 23809 version.go:104] falling back to the local client version: v1.19.16
[upgrade/versions] Latest stable version: v1.19.16
[upgrade/versions] Latest stable version: v1.19.16
W0523 14:44:34.944777 23809 version.go:103] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.19.txt": Get "https://dl.k8s.io/release/stable-1.19.txt": dial tcp 34.107.204.206:443: connect: no route to host
W0523 14:44:34.944794 23809 version.go:104] falling back to the local client version: v1.19.16
[upgrade/versions] Latest version in the v1.19 series: v1.19.16
[upgrade/versions] Latest version in the v1.19 series: v1.19.16
Components that must be upgraded manually after you have upgraded the control plane with 'kubeadm upgrade apply':
COMPONENT CURRENT AVAILABLE
kubelet 3 x v1.19.0 v1.19.16
Upgrade to the latest version in the v1.19 series:
COMPONENT CURRENT AVAILABLE
kube-apiserver v1.19.0 v1.19.16
kube-controller-manager v1.19.0 v1.19.16
kube-scheduler v1.19.0 v1.19.16
kube-proxy v1.19.0 v1.19.16
CoreDNS 1.7.0 1.7.0
etcd 3.4.9-1 3.4.13-0
You can now apply the upgrade by executing the following command:
kubeadm upgrade apply v1.19.16
_____________________________________________________________________
The table below shows the current state of component configs as understood by this version of kubeadm.
Configs that have a "yes" mark in the "MANUAL UPGRADE REQUIRED" column require manual config upgrade or
resetting to kubeadm defaults before a successful upgrade can be performed. The version to manually
upgrade to is denoted in the "PREFERRED VERSION" column.
API GROUP CURRENT VERSION PREFERRED VERSION MANUAL UPGRADE REQUIRED
kubeproxy.config.k8s.io v1alpha1 v1alpha1 no
kubelet.config.k8s.io v1beta1 v1beta1 no
_____________________________________________________________________
#上面显示了我最高也就只能更新到1.19.16版本 上面的镜像我已经提前下载好了,因为我是离线安装
更新集群镜像
[root@k8s-master shengji]# kubeadm upgrade apply v1.19.16
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster...
[upgrade/config] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks.
[upgrade] Running cluster health checks
[upgrade/version] You have chosen to change the cluster version to "v1.19.16"
[upgrade/versions] Cluster version: v1.19.0
[upgrade/versions] kubeadm version: v1.19.16
[upgrade/confirm] Are you sure you want to proceed with the upgrade? [y/N]: y
[upgrade/prepull] Pulling images required for setting up a Kubernetes cluster
[upgrade/prepull] This might take a minute or two, depending on the speed of your internet connection
[upgrade/prepull] You can also perform this action in beforehand using 'kubeadm config images pull'
[upgrade/apply] Upgrading your Static Pod-hosted control plane to version "v1.19.16"...
Static pod: kube-apiserver-k8s-master hash: 1db6a5175c0535eb600be916f90b44ad
Static pod: kube-controller-manager-k8s-master hash: 305200cb0b9f6e61cb417b8344471780
Static pod: kube-scheduler-k8s-master hash: 670a3f9629c937daf0c4a0b80213c1f8
[upgrade/etcd] Upgrading to TLS for etcd
Static pod: etcd-k8s-master hash: 3e69ef9d1b0a8b8d3011ee895295a1de
[upgrade/staticpods] Preparing for "etcd" upgrade
[upgrade/staticpods] Renewing etcd-server certificate
[upgrade/staticpods] Renewing etcd-peer certificate
[upgrade/staticpods] Renewing etcd-healthcheck-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/etcd.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2023-05-23-14-44-52/etcd.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: etcd-k8s-master hash: 3e69ef9d1b0a8b8d3011ee895295a1de
Static pod: etcd-k8s-master hash: 0458af5a80d033050f37928985e65008
[apiclient] Found 1 Pods for label selector component=etcd
[upgrade/staticpods] Component "etcd" upgraded successfully!
[upgrade/etcd] Waiting for etcd to become available
[upgrade/staticpods] Writing new Static Pod manifests to "/etc/kubernetes/tmp/kubeadm-upgraded-manifests381471550"
[upgrade/staticpods] Preparing for "kube-apiserver" upgrade
[upgrade/staticpods] Renewing apiserver certificate
[upgrade/staticpods] Renewing apiserver-kubelet-client certificate
[upgrade/staticpods] Renewing front-proxy-client certificate
[upgrade/staticpods] Renewing apiserver-etcd-client certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-apiserver.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2023-05-23-14-44-52/kube-apiserver.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-apiserver-k8s-master hash: 1db6a5175c0535eb600be916f90b44ad
Static pod: kube-apiserver-k8s-master hash: 4694fccf396354f1524ae14959ade94b
[apiclient] Found 1 Pods for label selector component=kube-apiserver
[upgrade/staticpods] Component "kube-apiserver" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-controller-manager" upgrade
[upgrade/staticpods] Renewing controller-manager.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-controller-manager.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2023-05-23-14-44-52/kube-controller-manager.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-controller-manager-k8s-master hash: 305200cb0b9f6e61cb417b8344471780
Static pod: kube-controller-manager-k8s-master hash: e1e1004d81e4c6678f9036427a79d40c
[apiclient] Found 1 Pods for label selector component=kube-controller-manager
[upgrade/staticpods] Component "kube-controller-manager" upgraded successfully!
[upgrade/staticpods] Preparing for "kube-scheduler" upgrade
[upgrade/staticpods] Renewing scheduler.conf certificate
[upgrade/staticpods] Moved new manifest to "/etc/kubernetes/manifests/kube-scheduler.yaml" and backed up old manifest to "/etc/kubernetes/tmp/kubeadm-backup-manifests-2023-05-23-14-44-52/kube-scheduler.yaml"
[upgrade/staticpods] Waiting for the kubelet to restart the component
[upgrade/staticpods] This might take a minute or longer depending on the component/version gap (timeout 5m0s)
Static pod: kube-scheduler-k8s-master hash: 670a3f9629c937daf0c4a0b80213c1f8
Static pod: kube-scheduler-k8s-master hash: df4a37a2d67c95fdbd748058309dc783
[apiclient] Found 1 Pods for label selector component=kube-scheduler
[upgrade/staticpods] Component "kube-scheduler" upgraded successfully!
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.19" in namespace kube-system with the configuration for the kubelets in the cluster
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
[upgrade/successful] SUCCESS! Your cluster was upgraded to "v1.19.16". Enjoy!
[upgrade/kubelet] Now that your control plane is upgraded, please proceed with upgrading your kubelets if you haven't already done so.
#取消调度保护
[root@k8s-master shengji]# kubectl uncordon k8s-master
node/k8s-master uncordoned
如果是高可用还需要在其他 master 节点上执行命令:
kubeadm upgrade node
#重启kubelet
systemctl daemon-reload && systemctl restart kubelet
#然后等待一会查看
[root@k8s-master shengji]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 30m v1.19.16
k8s-node1 Ready <none> 30m v1.19.0
k8s-node2 Ready <none> 30m v1.19.0
Node升级
升级kubeadm
#安装1.19.16版本的kubeadm、kubectl、kubelet
tar xf kubeadm-v1.19.16.tar.gz
rpm -ivh kubeadm/*.rpm --nodeps --force
#导入1.19.16版本镜像
[root@k8s-node01]# docker load -i kube-proxy-v1.19.16.tar.gz
#是的node节点只需要这一个镜像
设置节点不可调度并排空节点
#master节点上面执行
kubectl cordon k8s-node1
kubectl drain k8s-node1 --ignore-daemonsets
升级节点
#node节点上执行
[root@k8s-node01]# kubeadm upgrade node
[upgrade] Reading configuration from the cluster...
[upgrade] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[preflight] Running pre-flight checks
[preflight] Skipping prepull. Not a control plane node.
[upgrade] Skipping phase. Not a control plane node.
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[upgrade] The configuration for this node was successfully updated!
[upgrade] Now you should go ahead and upgrade the kubelet package using your package manager.
重启kubelet、设置节点可调度
[root@k8s-node01]# systemctl daemon-reload && systemctl restart kubelet
#设置节点可调度
#下面的这个在master节点执行
[root@k8s-master]# kubectl uncordon k8s-node1
node2操作也和node1一样
验证集群
验证集群状态是否正常
[root@k8s-master images]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 105m v1.19.16
k8s-node1 Ready <none> 104m v1.19.16
k8s-node2 Ready <none> 104m v1.19.16
验证集群证书是否正常
[root@k8s-master ~]# kubeadm alpha certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf May 22, 2024 06:45 UTC 364d no
apiserver May 22, 2024 06:44 UTC 364d ca no
apiserver-etcd-client May 22, 2024 06:44 UTC 364d etcd-ca no
apiserver-kubelet-client May 22, 2024 06:44 UTC 364d ca no
controller-manager.conf May 22, 2024 06:45 UTC 364d no
etcd-healthcheck-client May 22, 2024 06:44 UTC 364d etcd-ca no
etcd-peer May 22, 2024 06:44 UTC 364d etcd-ca no
etcd-server May 22, 2024 06:44 UTC 364d etcd-ca no
front-proxy-client May 22, 2024 06:44 UTC 364d front-proxy-ca no
scheduler.conf May 22, 2024 06:45 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca May 20, 2033 06:29 UTC 9y no
etcd-ca May 20, 2033 06:29 UTC 9y no
front-proxy-ca May 20, 2033 06:29 UTC 9y no
“注意:kubeadm upgrade 也会自动对它在此节点上管理的证书进行续约。如果选择不对证书进行续约,可以使用 --certificate-renewal=false。”
故障恢复
在升级过程中如果升级失败并且没有回滚,可以继续执行kubeadm upgrade。如果要从故障状态恢复,可以执行kubeadm upgrade --force。
在升级期间,会在/etc/kubernetes/tmp目录下生成备份文件:
kubeadm-backup-etcd-
kubeadm-backup-manifests-
kubeadm-backup-etcd中包含本地etcd的数据备份,如果升级失败并且无法修复,可以将其数据复制到etcd数据目录进行手动修复。
kubeadm-backup-manifests中保存的是节点静态pod的YAML清单,如果升级失败并且无法修复,可以将其复制到/etc/kubernetes/manifests下进行手动修复。
修复后发现还有一个漏洞存在
刚开始以为是OpenSSL版本问题导致的后面升级之后发现还有 然后经过查阅资料发现 是kube-apiserver导致的

利用测试工具验证漏洞:
在任意节点安装测试工具 Nmap ,并执行测试命令。
注意: Nmap 版本需要 7.x 以上才可以。
rpm -Uvh https://nmap.org/dist/nmap-7.93-1.x86_64.rpm
[root@localhost ~]# nmap --script ssl-enum-ciphers -p 6443 192.168.100.5
Starting Nmap 7.93 ( https://nmap.org ) at 2023-05-29 10:59 CST
Nmap scan report for k8s-master (192.168.100.5)
Host is up (0.000046s latency).
PORT STATE SERVICE
6443/tcp closed sun-sr-https
Nmap done: 1 IP address (1 host up) scanned in 0.17 seconds
[root@localhost ~]# nmap --script ssl-enum-ciphers -p 6443 192.168.100.5
Starting Nmap 7.93 ( https://nmap.org ) at 2023-05-29 11:07 CST
Nmap scan report for k8s-master (192.168.100.5)
Host is up (0.000050s latency).
PORT STATE SERVICE
6443/tcp open sun-sr-https
| ssl-enum-ciphers:
| TLSv1.2:
| ciphers:
| TLS_ECDHE_RSA_WITH_3DES_EDE_CBC_SHA (secp256r1) - C
| TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (secp256r1) - A
| TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 (secp256r1) - A
| TLS_RSA_WITH_3DES_EDE_CBC_SHA (rsa 2048) - C
| TLS_RSA_WITH_AES_128_CBC_SHA (rsa 2048) - A
| TLS_RSA_WITH_AES_128_GCM_SHA256 (rsa 2048) - A
| TLS_RSA_WITH_AES_256_CBC_SHA (rsa 2048) - A
| TLS_RSA_WITH_AES_256_GCM_SHA384 (rsa 2048) - A
| compressors:
| NULL
| cipher preference: client
| warnings:
| 64-bit block cipher 3DES vulnerable to SWEET32 attack
| TLSv1.3:
| ciphers:
| TLS_AKE_WITH_AES_128_GCM_SHA256 (ecdh_x25519) - A
| TLS_AKE_WITH_AES_256_GCM_SHA384 (ecdh_x25519) - A
| TLS_AKE_WITH_CHACHA20_POLY1305_SHA256 (ecdh_x25519) - A
| cipher preference: client
|_ least strength: C
Nmap done: 1 IP address (1 host up) scanned in 0.19 seconds
注意: 扫描结果中重点关注 warnings,64-bit block cipher 3DES vulnerable to SWEET32 attack。
因为我们这里只要API-Server有问题就只修复他了,如果其他组件需要修复可以参考:https://blog.csdn.net/zpf17671624050/article/details/129145754?spm=1001.2014.3001.5502
修复 kube-apiserver
编辑 kube-apiserver 配置文件 /etc/kubernetes/manifests/kube-apiserver.yaml:
# 新增配置(在原文件 41 行后面增加一行每个版本估计行会不一样)
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,TLS_RSA_WITH_AES_128_GCM_SHA256,TLS_RSA_WITH_AES_256_GCM_SHA384,TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA
# 新增后的效果如下
- --service-cluster-ip-range=10.1.0.0/16
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
- --tls-cipher-suites=TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA,TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA,TLS_RSA_WITH_AES_128_GCM_SHA256,TLS_RSA_WITH_AES_256_GCM_SHA384,TLS_RSA_WITH_AES_128_CBC_SHA,TLS_RSA_WITH_AES_256_CBC_SHA
重启 kube-apiserver:
不需要手动重启,由于是静态 Pod, Kubernetes 会自动重启。
验证漏洞:
[root@localhost ~]# nmap --script ssl-enum-ciphers -p 6443 192.168.100.5
Starting Nmap 7.93 ( https://nmap.org ) at 2023-05-29 11:23 CST
Nmap scan report for k8s-master (192.168.100.5)
Host is up (0.000062s latency).
PORT STATE SERVICE
6443/tcp open sun-sr-https
| ssl-enum-ciphers:
| TLSv1.2:
| ciphers:
| TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA (secp256r1) - A
| TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (secp256r1) - A
| TLS_RSA_WITH_AES_128_CBC_SHA (rsa 2048) - A
| TLS_RSA_WITH_AES_128_GCM_SHA256 (rsa 2048) - A
| TLS_RSA_WITH_AES_256_CBC_SHA (rsa 2048) - A
| TLS_RSA_WITH_AES_256_GCM_SHA384 (rsa 2048) - A
| compressors:
| NULL
| cipher preference: client
| TLSv1.3:
| ciphers:
| TLS_AKE_WITH_AES_128_GCM_SHA256 (ecdh_x25519) - A
| TLS_AKE_WITH_AES_256_GCM_SHA384 (ecdh_x25519) - A
| TLS_AKE_WITH_CHACHA20_POLY1305_SHA256 (ecdh_x25519) - A
| cipher preference: client
|_ least strength: A
Nmap done: 1 IP address (1 host up) scanned in 0.73 seconds
注意:对比之前的漏洞告警信息,扫描结果中已经不存在 64-bit block cipher 3DES vulnerable to SWEET32 attack,说明修复成功。
遇到的问题
这个是在客服环境遇到的问题
我这里简单说一下我升级时候遇到的一个问题大致就是在另外的master节点上(因为是高可用集群所以有多个master)执行kubeadm upgrade node的时候会报一个错误,就是说我的某一个地址不是ipv4格式,简单的说我的那个地址可能是hosts文件配置的那种域名格式的地址。具体是什么地址我记不清了因为没报错了也没法重新复现这个报错,总之经过我长时间的排除问题,也尝试过各种方式最终也没解决此问题,最终只能选择重新加入master节点具体操作如下:
#先在其他master上对要 需要加入节点的机器执行这些:
#把它设置为不可调度
kubectl cordon <node name>
#驱逐节点上的pod
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
#删除此节点
kubectl delete node <node name>
#然后再把原来的配置清空
kubeadm reset
systemctl stop kubelet
systemctl stop docker
rm -rf /var/lib/cni/
rm -rf /var/lib/kubelet/*
rm -rf /etc/cni/
ifconfig cni0 down
ifconfig flannel.1 down
ifconfig docker0 down
ip link delete cni0
ip link delete flannel.1
systemctl start docker
#以上操作是清空配置
#在其他master节点上执行,先把kubernetes证书和配置文件复制到需要重新加入节点的机器上
ssh root@172.31.0.6 mkdir -p /etc/kubernetes/pki/etcd
scp /etc/kubernetes/admin.conf root@172.31.0.6:/etc/kubernetes
scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@172.31.0.6:/etc/kubernetes/pki
scp /etc/kubernetes/pki/etcd/ca.* root@172.31.0.6:/etc/kubernetes/pki/etcd
# 生成新的token
kubeadm token create
除token外,join命令还需要一个sha256的值,通过以下方法计算
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
#然后加入集群 里面的token和sha256 用自己生成的 --apiserver-advertise-address= 是防止指定的其他网卡上 此加入集群是加入master节点的
kubeadm join master.k8s.io:16443 --token k5j27i.bo0clckst09xkb6t \
--discovery-token-ca-cert-hash sha256:0a0e6689586e6c6529484ed947689f5aa292f268e9eae03377ac2bc0bc85a530 \
--apiserver-advertise-address=172.31.0.5 \
--control-plane
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get nodes
Kubernetes 版本信息泄露漏洞
描述
kubernetes 版本可以通过未授权访问的形式从/version端点获得
测试地址
https://10.12.181.XXX:6443/version
验证结果

修复方式
vim /etc/kubernetes/manifests/kube-apiserver.yaml
#加上这一行 --anonymous-auth 设置为 false,Kubernetes API Server 将要求用户在访问 API Server 之前进行身份验证和授权。这可以提高 Kubernetes 集群的安全性,防止未经授权的访问和操作
- --anonymous-auth=false
#加上wq保存 apiserver会自动重启

修复后的验证:


K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)