GekkoFS – A temporary distributed file system for HPC applications
GekkoFS主要是面向HPC领域,用于保存临时数据,而不是持久化的存储系统,所以就没有考虑数据的可用性(副本或者EC机制)和元数据的高可用等分布式系统的关键问题。核心目标就是追求文件系统的性能,所以有如下的亮点可供学习参考:1.通过截获linux系统调用实现lib库形式的客户端访问:客户端是在用户态实现的通过截获linux系统调用而实现的动态库。既不用实现一个VFS kernel客户端,省去了l
GekkoFS – A temporary distributed file system for HPC applications
Abstract—We present GekkoFS, a temporary, highly-scalable burst buffer file system which has been specifically optimized for new access patterns of data-intensive High-Performance Computing (HPC) applications. The file system provides relaxed POSIX semantics, only offering features which are actually required by most (not all) applications. It is able to provide scalable I/O performance and reaches millions of metadata operations already for a small number of nodes, significantly outperforming the capabilities of general-purpose parallel file systems.
Index Terms—Distributed File Systems, HPC, Burst Buffers
摘要:我们介绍了GekkoFS,这是一个临时的、高度可扩展的突发缓存文件系统,专门针对数据密集型高性能计算(HPC)应用的新访问模式进行了优化。该文件系统提供松散的POSIX语义,只提供大多数(而非所有)应用程序实际需要的功能。它能够提供可扩展的I/O性能,并且在节点数量较少的情况下就能达到数百万个元数据操作,明显优于通用并行文件系统的性能能力。
关键词:分布式文件系统、HPC、突发缓存。
I. INTRODUCTION
High-Performance Computing (HPC) applications are significantly changing. Traditional HPC applications have been compute-bound, large-scale simulations, while today’s HPC community is additionally moving towards the generation, processing, and analysis of massive amounts of experimental data.This trend, known as data-driven science, is affecting many different scientific fields, some of which have made significant progress tackling previously unaddressable challenges thanks to newly developed techniques [15], [30].
高性能计算(HPC)应用正在显著变化。传统的HPC应用程序是计算密集型的大规模模拟,而今天的HPC社区还向着生成、处理和分析大量实验数据的方向发展。这种趋势被称为数据驱动科学,正在影响许多不同的科学领域,其中一些领域通过新开发的技术取得了解决以前无法解决的挑战的重大进展[15],[30]。
Most data-driven workloads are based on new algorithms and data structures like graph databases which impose new requirements on HPC file systems [22], [39]. They include, e.g., large numbers of metadata operations, data synchronization, non-contiguous and random access patterns, and small I/O requests [9], [22]. Such operations differ significantly from past workloads which mostly performed sequential I/O operations on large files. They do not only slow down datadriven applications themselves but can also heavily disrupt other applications that are concurrently accessing the shared storage system [11], [35]. Consequently, traditional parallel file systems (PFS) cannot handle these workloads efficiently and data-driven applications suffer from prolonged I/O latencies, reduced throughput, and long waiting times.
大多数基于数据驱动的工作负载都基于新的算法和数据结构,比如图形数据库,这些对HPC文件系统提出了新的要求[22],[39]。它们包括大量的元数据操作、数据同步、非连续和随机访问模式以及小型I/O请求[9],[22]。这些操作与过去的工作负载有很大的不同,过去的工作负载主要是对大文件进行顺序I/O操作。它们不仅会减慢数据驱动应用程序本身的速度,还会严重干扰同时访问共享存储系统的其他应用程序[11],[35]。因此,传统的并行文件系统(PFS)无法高效处理这些工作负载,数据驱动的应用程序会遭受延迟的I/O、降低的吞吐量和长时间的等待时间。
Software-based approaches, e.g., application modifications or middleware and high-level libraries [12], [19], try to support data-driven applications to align the new access patterns to the capabilities of the underlying PFS. Yet, adapting such software is typically time-consuming, difficult to couple with big data and machine learning libraries, or sometimes (based on the underlying algorithms) just impossible
软件方法,例如应用程序修改或中间件和高级库[12],[19],试图支持数据驱动的应用程序将新的访问模式与底层PFS的能力对齐。然而,调整这样的软件通常需要耗费时间,很难与大数据和机器学习库耦合,有时甚至(基于底层算法)是不可能的。
Hardware-based approaches move from magnetic disks, the main backend technology for PFSs, to NAND-based solidstate drives (SSDs). Nowadays, many supercomputers deploy SSDs which can be used as dedicated burst buffers [18] or as node-local burst buffers. To achieve high metadata performance, they can be deployed in combination with a dynamic burst buffer file system [3], [40].
基于硬件的方法从磁盘(PFS的主要后端技术)转向基于NAND的固态硬盘(SSD)。现在,许多超级计算机都部署了SSD,可以用作专用突发缓冲区[18]或节点本地突发缓冲区。为了获得较高的元数据性能,它们可以与动态突发缓冲区文件系统[3]、[40]结合部署。
Generally, burst buffer file systems increase performance compared to a PFS without modifying an application. Therefore, they typically support POSIX which provides the standard semantics accepted by most application developers. Nevertheless, enforcing POSIX can severely reduce a PFS’ peak performance [38]. Further, many POSIX features are not required for most scientific applications [17], especially if they can exclusively access the file system. Similar argumentations hold for other advanced features like fault tolerance or security.
通常,爆发缓冲区文件系统可以提高性能,而无需修改应用程序。因此,它们通常支持POSIX,提供了大多数应用程序开发者所接受的标准语义。然而,强制执行POSIX可能会严重降低PFS的峰值性能[38]。此外,许多POSIX功能对于大多数科学应用程序[17]并不是必需的,特别是如果它们可以独占地访问文件系统。类似的论证也适用于其他高级功能,如容错性或安全性。
In this work, we present GekkoFS, a temporarily deployed, highly-scalable distributed file system for HPC applications which aims to accelerate I/O operations of common HPC workloads that are challenging for modern PFSs. GekkoFS pools together fast node-local storage resources and provides a global namespace accessible by all participating nodes. It relaxes POSIX by removing some of the semantics that most impair I/O performance in a distributed context and takes previous studies on the behavior of HPC applications into account [17] to optimize the most used file system operations.
在这项工作中,我们介绍了GekkoFS,一种临时部署的高度可扩展的分布式文件系统,旨在加速现代PFS难以应对的常见HPC工作负载的I/O操作。GekkoFS汇集了快速的节点本地存储资源,并提供全局命名空间,可由所有参与节点访问。它通过删除在分布式环境下最影响I/O性能的一些语义来放宽POSIX,并考虑到以前有关HPC应用程序行为的研究[17],以优化最常用的文件系统操作。
For load-balancing, all data and metadata are distributed across all nodes using the HPC RPC framework Mercury [34].The file system runs in user-space and can be easily deployed in under 20 seconds on a 512 node cluster by any user.Therefore, it can be used in a number of temporary scenarios, e.g., during the lifetime of a compute job or in longer-term use cases, e.g., campaigns. We demonstrate how our lightweight, yet highly distributed file system GekkoFS reaches scalable data and metadata performance with tens of millions of metadata operations per second on a 512 node cluster while still providing strong consistency for file system operations that target a specific file or directory.
为了实现负载均衡,使用HPC RPC框架Mercury [34]将所有数据和元数据分布在所有节点之间。该文件系统在用户空间运行,任何用户都可以在不到20秒的时间内在512个节点集群上轻松部署。因此,它可以在许多临时情况下使用,例如,在计算作业的生命周期内或在更长期的用例中,例如运动。我们展示了我们的轻量级但高度分布式的文件系统GekkoFS如何在512个节点集群上实现可扩展的数据和元数据性能,每秒处理数千万个元数据操作,同时为针对特定文件或目录的文件系统操作提供强一致性。
II. RELATED WORK
General-purpose PFSs like GPFS, Lustre, BeeGFS, or PVFS [4], [14], [27], [31], [32] provide long-term storage which is mostly based on magnetic disks. GekkoFS instead builds a short-term, separate namespace from fast node-local SSDs that is only temporarily accessible during the runtime of a job or a campaign. As such, GekkoFS can be categorized into the class of node-local burst buffer file systems, while remoteshared burst buffer file systems use dedicated, centralized I/O nodes [40], e.g., DDN’s IME [1].
通用PFS(如GPFS、Lustre、BeeGFS或PVFS [4],[14],[27],[31],[32])提供基于磁盘的长期存储。相比之下,GekkoFS则从快速的节点本地SSD构建了一个短期的、独立的命名空间,只在作业或运行期间临时可访问。因此,GekkoFS可以归类为节点本地的burst buffer文件系统,而远程共享的burst buffer文件系统则使用专用的集中式I/O节点 [40],例如DDN的IME [1]。
In general, node-local burst buffers are fast, intermediate storage systems that aim to reduce the PFS’ load and the applications’ I/O overhead [18]. They are typically collocated with nodes running a compute job, but they can also be dependent on the backend PFS [3] or in some cases even directly managed by it [24]. BurstFS [40], perhaps the most related work to ours, is a standalone burst buffer file system, but, unlike GekkoFS, is limited to write data locally. BeeOND [14] can create a job-temporal file system on a number of nodes similar to GekkoFS. However, in contrast to our file system, it is POSIX compliant and our measurements show a much higher metadata throughput than offered by BeeOND [36].
通常,本地节点缓冲区是旨在减轻PFS负载和应用程序I/O开销的快速中间存储系统[18]。它们通常与运行计算作业的节点放置在一起,但它们也可能依赖于后端PFS[3],甚至直接由其管理[24]。BurstFS[40]可能是与我们最相关的工作,它是一个独立的缓冲区文件系统,但与GekkoFS不同的是,它只能本地写入数据。BeeOND[14]可以在类似于GekkoFS的多个节点上创建临时文件系统。然而,与我们的文件系统不同的是,它符合POSIX,而我们的测量结果显示我们的文件系统比BeeOND提供的元数据吞吐量高得多[36]。
The management of inodes and related directory blocks are the main scalability limitations of file systems in a distributed environment. Typically, general-purpose PFSs distribute data across all available storage targets. As this technique works well for data, it does not achieve the same throughput when handling metadata [5], [28], although the file system community presented various techniques to tackle this challenge [3], [13], [25], [26], [41], [42]. The performance limitation can be attributed to the sequentialization enforced by underlying POSIX semantics which is particularly degrading throughput when a huge number of files is created in a single directory from multiple processes. This workload, common to HPC environments [3], [24], [25], [37], can become an even bigger challenge for upcoming data-science applications. GekkoFS is built on a new technique to handle directories and replaces directory entries by objects, stored within a strongly consistent key-value store which helps to achieve tens of millions of metadata operations for billions of files.
在分布式环境下,inode及相关目录块的管理是文件系统的主要可扩展性限制。通常,通用PFS将数据分布在所有可用存储目标上。尽管这种技术在处理数据时效果良好,但在处理元数据时却无法实现相同的吞吐量[5],[28],虽然文件系统社区提出了各种技术来解决这个挑战[3],[13],[25],[26],[41],[42]。性能限制可以归因于基础POSIX语义所强制执行的顺序化,当从多个进程在单个目录中创建大量文件时,特别是在HPC环境[3],[24],[25],[37]中普遍存在的工作负载时,这会降低吞吐量,而对于即将到来的数据科学应用程序而言,这种工作负载可能会变得更加棘手。 GekkoFS基于一种处理目录的新技术,通过在强一致的键值存储中存储对象来替换目录条目,从而帮助实现每秒数千万的元数据操作,适用于数十亿个文件。
III. DESIGN AND IMPLEMENTATION
GekkoFS offers a user-space file system for the lifetime of a particular use case, e.g., within the context of an HPC job. The file system uses the available local storage of compute nodes to distribute data and metadata and combines their node-local storage into a single global namespace.
GekkoFS 提供了一个特定使用情况的用户空间文件系统,例如,在 HPC 作业的上下文中。该文件系统利用计算节点的本地存储来分发数据和元数据,并将它们的本地存储组合成单个全局命名空间。
The file system’s main goal focuses on scalability and consistency. It should therefore scale to an arbitrary number of nodes to benefit from current and future storage and network technologies. Further, GekkoFS should provide the same consistency as POSIX for file system operations that access a specific data file. However, consistency of directory operations, for instance, can be relaxed. Finally, GekkoFS should be hardware independent to efficiently use today’s network technologies as well as any modern and future storage hardware that is accessible by the user.
该文件系统的主要目标是可扩展性和一致性。因此,它应该能够扩展到任意数量的节点,以利用当前和未来的存储和网络技术。此外,GekkoFS 应该为访问特定数据文件的文件系统操作提供与 POSIX 相同的一致性。然而,例如目录操作的一致性可以放宽。最后,GekkoFS 应该是硬件无关的,以有效地使用今天的网络技术以及用户可以访问的任何现代和未来的存储硬件。
Similarly to PVFS [6] and OrangeFS [21], GekkoFS does not provide complex global locking mechanisms. In this sense, applications should be responsible to ensure that no conflicts occur, in particular, w.r.t. overlapping file regions. However, the lack of distributed locking has consequences for operations where the number of affected file system objects is unknown a priori, such as readdir() called by the ls -l command.In these indirect file system operations, GekkoFS does not guarantee to return the current state of the directory and follows the eventual-consistency model. Furthermore, each file system operation is synchronous without any form of caching to reduce file system complexity and to allow for an evaluation of its raw performance capabilities.
A. POSIX relaxation
与 PVFS [6] 和 OrangeFS [21] 类似,GekkoFS 不提供复杂的全局锁定机制。在这种意义上,应用程序应该负责确保没有冲突发生,特别是关于重叠的文件区域。然而,分布式锁定的缺乏对于受影响的文件系统对象数量未知的操作,如通过 ls -l 命令调用的 readdir() 操作,会产生后果。在这些间接文件系统操作中,GekkoFS 不能保证返回目录的当前状态,而是遵循最终一致性模型。此外,每个文件系统操作都是同步的,没有任何形式的缓存来减少文件系统的复杂性,并允许评估其原始性能能力。
GekkoFS does not support move or rename operations or linking functionality as HPC application studies have shown that these features are rarely or not used at all during the execution of a parallel job [17]. Finally, security management in the form of access permissions is not maintained by GekkoFS since it already implicitly follows the security protocols of the node-local file system.
GekkoFS不支持移动或重命名操作或链接功能,因为HPC应用程序研究表明,在并行作业执行期间很少或根本不使用这些功能[17]。最后,GekkoFS不维护访问权限的安全管理,因为它已经隐含地遵循了节点本地文件系统的安全协议。
B. Architecture
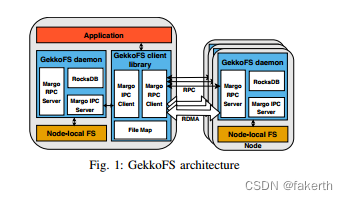
GekkoFS’ architecture (see Figure 1) consists of two main components: a client library and a server process. An application that uses GekkoFS must first preload the client interposition library which intercepts all file system operations and forwards them to a server (GekkoFS daemon), if necessary. The GekkoFS daemon, which runs on each file system node, receives forwarded file system operations from clients and processes them independently, sending a response when finished. In the following paragraphs, we describe the client and daemon in more detail.
GekkoFS的架构(见图1)由两个主要组件组成:客户端库和服务器进程。使用GekkoFS的应用程序必须首先预加载客户端拦截库,该库拦截所有文件系统操作并在必要时将它们转发到服务器(GekkoFS守护进程)。GekkoFS守护进程在每个文件系统节点上运行,接收来自客户端的转发文件系统操作,并独立处理它们,处理完成后发送响应。在下面的段落中,我们将更详细地描述客户端和守护进程。
a) GekkoFS client: The client consists of three components: 1) An interception interface that catches relevant calls to GekkoFS and forwards unrelated calls to the node-local file system; 2) a file map that manages the file descriptors of open files and directories, independently of the kernel; and 3) an RPC-based communication layer that forwards file system requests to local/remote GekkoFS daemons.
a) GekkoFS客户端:客户端由三个组件组成:1)拦截接口,用于捕获与GekkoFS相关的调用,并将不相关的调用转发到节点本地文件系统;2)文件映射,独立于内核管理已打开文件和目录的文件描述符;3)基于RPC的通信层,将文件系统请求转发给本地/远程的GekkoFS守护进程。
Each file system operation is forwarded via an RPC message to a specific daemon (determined by hashing of the file’s path) where it is directly executed. In other words, GekkoFS uses a pseudo-random distribution to spread data and metadata across all nodes, also known as wide-striping. Because each client is able to independently resolve the responsible node for a file system operation, GekkoFS does not require central data structures that keep track of where metadata or data is located. To achieve a balanced data distribution for large files, data requests are split into equally sized chunks before they are distributed across file system nodes. If supported by the underlying network fabric protocol, the client exposes the relevant chunk memory region to the daemon, accessed via remote-direct-memory-access (RDMA).
每个文件系统操作都通过RPC消息转发到一个特定的守护进程(由文件路径的哈希确定),在那里直接执行。换句话说,GekkoFS使用伪随机分布将数据和元数据分散到所有节点中,也称为广域条带化。由于每个客户端都能够独立地解决文件系统操作的负责节点,因此GekkoFS不需要中央数据结构来跟踪元数据或数据的位置。为了实现大文件的平衡数据分布,数据请求在分布到文件系统节点之前被分割成相等大小的块。如果底层网络协议支持,客户端会将相关的块内存区域暴露给守护进程,通过远程直接内存访问(RDMA)进行访问。
b) GekkoFS daemon: GekkoFS daemons consist of three parts: 1) A key-value store (KV store) used for storing metadata; 2) an I/O persistence layer that reads/writes data from/to the underlying local storage system (one file per chunk); and 3) an RPC-based communication layer that accepts local and remote connections to handle file system operations.
b) GekkoFS 守护进程:GekkoFS 守护进程由三部分组成:1) 用于存储元数据的键值存储(KV 存储);2) 一个 I/O 持久层,从/向底层本地存储系统读/写数据(每个块一个文件);以及 3) 基于 RPC 的通信层,接受本地和远程连接以处理文件系统操作。
Each daemon operates a single local RocksDB KV store [10]. RocksDB is optimized for NAND storage technologies with low latencies and fits GekkoFS’ needs as SSDs are primarily used as node-local storage in today’s HPC clusters.
每个守护进程操作一个本地的 RocksDB KV 存储 [10]。RocksDB 针对低延迟 NAND 存储技术进行了优化,符合 GekkoFS 的需求,因为当前的 HPC 集群主要使用 SSD 作为节点本地存储。
For the communication layer, we leverage on the Mercury RPC framework [34]. It allows GekkoFS to be networkindependent and to efficiently transfer large data within the file system. Within GekkoFS, Mercury is interfaced indirectly through the Margo library which provides Argobots-aware wrappers to Mercury’s API with the goal to provide a simple multi-threaded execution model [7], [33]. Using Margo allows GekkoFS daemons to minimize resource consumption of Margo’s progress threads and handlers which accept and handle RPC requests [7].
对于通信层,我们利用 Mercury RPC 框架 [34]。它允许 GekkoFS 独立于网络,并在文件系统内高效地传输大数据。在 GekkoFS 中,Mercury 通过 Margo 库间接接口,该库提供了针对 Mercury API 的 Argobots-aware 封装,旨在提供简单的多线程执行模型 [7],[33]。使用 Margo 允许 GekkoFS 守护进程最小化 Margo 进度线程和处理程序的资源消耗,这些线程和处理程序接受和处理 RPC 请求 [7]。
IV. EVALUATION
We evaluated the performance of GekkoFS based on various unmodified microbenchmarks which catch access patterns that are common in HPC applications. Our experiments were conducted on the MOGON II supercomputer, located at the Johannes Gutenberg University Mainz in Germany. All experiments were performed on Intel 2630v4 Intel Broadwell processors (two sockets each). The main memory capacity inside the nodes ranges from 64 GiB up to 512 GiB of memory. MOGON II uses 100 Gbit/s Intel Omni-Path to establish a fat-tree network between all compute nodes. In addition, each node provides a data center Intel SATA SSD DC S3700 Series as scratch-space (XFS formatted) usable within a compute job. We used these SSDs for storing data and metadata of GekkoFS which uses an internal chunk size of 512 KiB.
我们基于各种未修改的微基准测试来评估 GekkoFS 的性能,这些测试能捕捉到 HPC 应用程序中常见的访问模式。我们的实验在德国约翰内斯·古腾堡大学的 MOGON II 超级计算机上进行。所有实验均在 Intel 2630v4 Intel Broadwell 处理器上执行(每个处理器有两个插槽)。节点内的主存储器容量从 64 GiB 到 512 GiB 不等。MOGON II 使用 100 Gbit/s 的 Intel Omni-Path 在所有计算节点之间建立了一个胖树网络。此外,每个节点提供一个数据中心 Intel SATA SSD DC S3700 系列作为临时存储空间(XFS 格式化),可在计算作业内使用。我们使用这些 SSD 存储 GekkoFS 的数据和元数据,GekkoFS 使用内部块大小为 512 KiB。
Before each experiment iteration, GekkoFS daemons are restarted (requiring less than 20 seconds for 512 nodes), all SSD contents are removed, and kernel buffer, inode, and dentry caches are flushed. The GekkoFS daemon and the application under test are pinned to separate processor sockets to ensure that file system and application do not interfere with each other.
在每次实验迭代之前,GekkoFS 守护进程都会重新启动(512 个节点需要不到 20 秒),清除所有 SSD 内容,并刷新内核缓冲区、inode 和 dentry 缓存。为确保文件系统和应用程序不互相干扰,GekkoFS 守护进程和测试应用程序会钉在不同的处理器插槽上。
A. Metadata performance
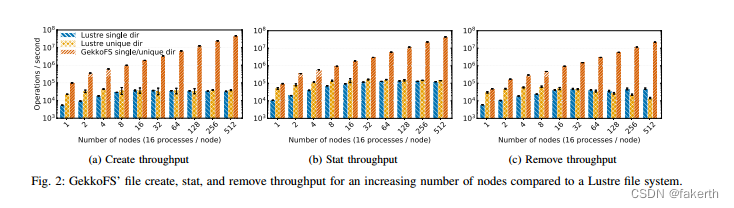
We simulated common metadata intensive HPC workloads using the unmodified mdtest microbenchmark [20] to evaluate GekkoFS’ metadata performance and compare it against a Lustre parallel file system. Although GekkoFS and Lustre have different goals, we point out the performances that can be gained by using GekkoFS as a burst buffer file system.In our experiments, mdtest performs create, stat, and remove operations in parallel in a single directory – an important workload in many HPC applications and among the most difficult workloads for a general-purpose PFS [37].
我们使用未修改的mdtest微基准[20]模拟常见的元数据密集型HPC工作负载,以评估GekkoFS的元数据性能,并将其与Lustre并行文件系统进行比较。虽然GekkoFS和Lustre的目标不同,但我们指出了使用GekkoFS作为突发缓冲文件系统可以获得的性能。在我们的实验中,mdtest在单个目录中并行执行create、stat和remove操作,这是许多HPC应用程序中重要的工作负载之一,也是通用PFS的最困难的工作负载之一[37]。
Each operation on GekkoFS was performed using 100,000 zero-byte files per process (16 processes per node). From the user application’s perspective, all created files are stored within a single directory. However, due to GekkoFS’ internally kept flat namespace, there is conceptually no difference in which directory files are created. This is in contrast to a traditional PFS that may perform better if the workload is distributed among many directories instead of in a single directory. Figure 2 compares GekkoFS with Lustre in three scenarios with up to 512 nodes: file creation, file stat, and file removal. The y-axis depicts the corresponding operations per second that were achieved for a particular workload on a logarithmic scale. Each experiment was run at least five times with each data point representing the mean of all iterations.GekkoFS’ workload scaled with 100,000 files per process, while Lustre’s workload was fixed to four million files for all experiments. We fixed the number of files for Lustre’s metadata experiments because Lustre was otherwise detecting hanging nodes when scaling to too many files.
每个在GekkoFS上执行的操作都使用每个进程100,000个零字节文件(每个节点16个进程)。从用户应用程序的角度来看,所有创建的文件都存储在单个目录中。然而,由于GekkoFS内部保留了一个扁平的命名空间,因此在哪个目录下创建文件在概念上没有区别。这与传统的PFS不同,如果工作负载分布在多个目录而不是一个目录中,则可能会表现得更好。图2将GekkoFS与Lustre在三种情况下进行比较,最多使用512个节点:文件创建、文件统计和文件删除。y轴以对数刻度表示实现了特定工作负载的每秒操作数。每个实验至少运行五次,每个数据点表示所有迭代的平均值。GekkoFS的工作负载随着每个进程的100,000个文件进行扩展,而Lustre的工作负载对于所有实验都固定为400万个文件。我们固定Lustre的元数据实验中的文件数,因为否则Lustre会检测到当扩展到太多文件时出现挂起节点的情况。
Lustre experiments were run in two configurations: All processes operated in a single directory (single dir) or each process worked in its own directory (unique dir).Moreover, Lustre’s metadata performance was evaluated while the system was accessible by other applications as well.
Lustre实验在两种配置下运行:所有进程在单个目录中操作(单目录),或每个进程在自己的目录中工作(独立目录)。此外,在系统可以被其他应用程序访问时评估了Lustre的元数据性能。
As seen in Figure 2, GekkoFS outperforms Lustre by a large margin in all scenarios and shows close to linear scaling, regardless of whether Lustre processes operated in a single or in an isolated directory. Compared to Lustre, GekkoFS achieved around 46 million creates/s (~1,405x), 44 million stats/s (~359x), and 22 million removes/s (~453x) at 512 nodes. The standard deviation was less than 3.5% which was computed as the percentage of the mean.
如图2所示,在所有情况下,GekkoFS都大大优于Lustre,并显示接近线性的扩展性,无论Lustre进程是在单个目录中操作还是在独立目录中操作。与Lustre相比,GekkoFS在512个节点上实现了大约4600万次创建/秒(约1,405倍),4400万次统计/秒(约359倍)和2200万次删除/秒(约453倍)。标准偏差小于3.5%,它被计算为均值的百分比。
B. Data performance
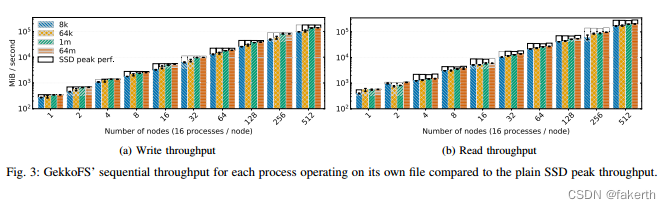
We used the unmodified IOR [20] microbenchmark to evaluate GekkoFS’ I/O performance for sequential and random access patterns in two scenarios: Each process is accessing its own file (file-per-process) and all processes access a single file (shared file). We used 8 KiB, 64 KiB, 1 MiB, and 64 MiB transfer sizes to assess the performances for many small I/O accesses and for few large I/O requests. We ran 16 processes on each client, each process writing and reading 4 GiB in total.
我们使用未经修改的 IOR [20] 微基准测试来评估 GekkoFS 在两种场景下的顺序和随机访问模式的 I/O 性能:每个进程都访问自己的文件(每进程一个文件)和所有进程访问一个文件(共享文件)。我们使用了 8 KiB、64 KiB、1 MiB 和 64 MiB 的传输大小来评估许多小的 I/O 访问和少量大的 I/O 请求的性能。我们在每个客户端上运行了 16 个进程,每个进程总共写入和读取了 4 GiB。
GekkoFS data performance is not compared with the Lustre scratch file system as the peak performance of the used Lustre partition, around 12 GiB/s, is already reached for ≤ 10 nodes for sequential I/O patterns. Moreover, Lustre has shown to scale linearly in larger deployments with more OSSs and OSTs being available [23].
由于在顺序 I/O 模式下,已经可以达到使用的 Lustre 分区的峰值性能(约为 12 GiB/s)且仅需要 ≤ 10 个节点,因此没有将 GekkoFS 的数据性能与 Lustre 临时文件系统进行比较。此外,Lustre 已经表现出在更大规模的部署中随着更多 OSS 和 OST 的提供而呈线性扩展 [23]。
Figure 3 shows GekkoFS’ sequential I/O throughput in MiB/s, representing the mean of at least five iterations, for an increasing number of nodes for different transfer sizes.In addition, each data point is compared to the peak performance that all aggregated SSDs could deliver for a given node configuration, visualized as a white rectangle, indicating GekkoFS’ SSD usage efficiency. In general, every result demonstrates GekkoFS’ close to linear scalability, achieving about 141 GiB/s (~80% of the aggregated SSD peak bandwidth) and 204 GiB/s (~70% of the aggregated SSD peak bandwidth) for write and read operations for a transfer size of 64 MiB for 512 nodes. At 512 nodes, this translates to more than 13 million write IOPS and more than 22 million read IOPS, while the average latency can be bounded by at most 700 μs for file system operations with a transfer size of 8 KiB.
图3显示了GekkoFS在不同传输大小下,针对节点数量的增加,顺序 I/O 吞吐量的 MiB/s 均值,表示至少五次迭代的平均值。此外,每个数据点都与所有聚合 SSD 可以在给定节点配置下提供的峰值性能进行比较,可视化为白色矩形,表示 GekkoFS 的 SSD 使用效率。总体而言,每个结果都展示了 GekkoFS 的近似线性可扩展性,对于 64 MiB 的传输大小,512 个节点的写入和读取操作可达到约 141 GiB/s(聚合 SSD 峰值带宽的约 80%)和 204 GiB/s(聚合 SSD 峰值带宽的约 70%)。在 512 个节点时,这相当于超过 1300 万个写入 IOPS 和超过 2200 万个读取 IOPS,而传输大小为 8 KiB 的文件系统操作的平均延迟最多可以限制在 700 μs 以内。
For the file-per-process cases, sequential and random access I/O throughput are similar for transfer sizes larger than the file system’s chunk size. This is due to transfer sizes larger than the chunk size internally access whole chunk files while smaller transfer sizes access one chunk at a random offset.Consequently, random accesses for large transfer sizes are conceptually the same as sequential accesses. For smaller transfer sizes, e.g., 8 KiB, random write and read throughput decreased by approximately 33% and 60%, respectively, for 512 nodes owing to the resulting random access to positions within the chunks.
对于每进程一个文件的情况,当传输大小大于文件系统的块大小时,顺序和随机访问的 I/O 吞吐量相似。这是因为大于块大小的传输大小在内部访问整个块文件,而较小的传输大小在随机偏移量上访问一个块。因此,对于大传输大小的随机访问来说,概念上与顺序访问相同。对于较小的传输大小,例如 8 KiB,由于在块内随机访问,随机写入和读取吞吐量在 512 个节点上分别下降约 33% 和 60%。
For the shared file cases, a drawback of GekkoFS’ synchronous and cache-less design becomes visible. No more than approximately 150K write operations per second were achieved. This was due to network contention on the daemon which maintains the shared file’s metadata whose size needs to be constantly updated. To overcome this limitation, we added a rudimentary client cache to locally buffer size updates of a number of write operations before they are send to the node that manages the file’s metadata. As a result, shared file I/O throughput for sequential and random access were similar to file-per-process performances since chunk management on the daemon is then conceptually indifferent in both cases.
对于共享文件情况,GekkoFS 同步和无缓存设计的缺点变得明显。最多只能达到约 150K 的写入操作每秒。这是由于维护共享文件元数据的守护程序上的网络争用造成的,该元数据的大小需要不断更新。为了克服这个限制,我们添加了一个基本的客户端缓存,用于在将写入操作发送到管理文件元数据的节点之前本地缓冲一些大小更新。结果,顺序和随机访问的共享文件 I/O 吞吐量与每进程一个文件的性能类似,因为在这两种情况下,守护程序上的块管理在概念上是不同的。
V. CONCLUSION AND ACKNOWLEDGEMENTS
We have introduced and evaluated GekkoFS, a new burst buffer file system for HPC applications with relaxed POSIXsemantics, allowing it to achieve millions of metadata operations even for a small number of nodes and close to linear scalability in various data and metadata use cases. Next, we plan to extend GekkoFS in three directions: Investigate GekkoFS’ with various chunk sizes, evaluate benefits of caching, and explore different data distribution patterns.
我们介绍并评估了 GekkoFS,这是一个新的高性能计算应用程序的 burst buffer 文件系统,它具有松散的 POSIX 语义,使其能够在各种数据和元数据用例中实现数百万的元数据操作,即使只有少量节点也能实现接近线性的可扩展性。接下来,我们计划在三个方向上扩展 GekkoFS:研究具有不同块大小的 GekkoFS、评估缓存的好处,并探索不同的数据分布模式。
The work has been funded by the German Research Foundation (DFG) through the ADA-FS project as part of the Priority Programme 1648. It is also supported by the Spanish Ministry of Science and Innovation (TIN2015– 65316), the Generalitat de Catalunya (2014–SGR–1051), as well as the European Union’s Horizon 2020 Research and Innovation Programme (NEXTGenIO, 671951) and the European Comission’s BigStorage project (H2020-MSCA-ITN2014-642963). This research was conducted using the supercomputer MOGON II and services offered by the Johannes Gutenberg University Mainz.
本项工作得到德国研究基金会 (DFG) ADA-FS 项目的资助,作为优先计划1648的一部分。此外,该项目还得到了西班牙科学与创新部(TIN2015-65316)、加泰罗尼亚自治政府(2014-SGR-1051)、欧盟Horizon 2020研究和创新计划(NEXTGenIO,671951)以及欧盟委员会的BigStorage项目(H2020-MSCA-ITN2014-642963)的支持。本研究使用了超级计算机MOGON II和由约翰内斯·古腾堡大学提供的服务。
总结
GekkoFS主要是面向HPC领域,用于保存临时数据,而不是持久化的存储系统,所以就没有考虑数据的可用性(副本或者EC机制)和元数据的高可用等分布式系统的关键问题。核心目标就是追求文件系统的性能,所以有如下的亮点可供学习参考:
1.通过截获linux系统调用实现lib库形式的客户端访问:客户端是在用户态实现的通过截获linux系统调用而实现的动态库。既不用实现一个VFS kernel客户端,省去了linux内核编程的复杂和难度;也不用实现基于fuse的用户态客户端,避免使用fuse而产生的性能损耗的问题。
2.文件系统对POSIX语义的放松:某些POSIX语义不用强支持,适度的放松可以显著提高性能。GekkoFS没有实现分布式锁,rename和link操作。它用了kv存储保存元数据,通过flat namespace实现了文件系统的命名空间。(和目前流行的对象存储的概念和实现很类似)从而可以大幅提高性能。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)