
【UVM源码】sequence机制使用方法和源代码解析
UVM机制sequence的使用方法介绍,UVM机制sequence机制相关的源代码解析。
本文目录
一、sequence机制使用方法
(1) sequence的body方法开发:
UVM的sequence和tc组合使用的机制下,发送不同激励是通过不同的sequence实现的,也就是不同的sequence中做不同的配置或者处理。在sequence进行的配置或者处理操作,一般情况下,就是实现sequence的body方法(user_sequence中body方法在其基类uvm_sequence_base中已将有了,只不过是空的);
如下图所示,在body方法中先声明并创建了个transaction,然后调用了start_item,之后进行随机,然后调用finish_item方法;
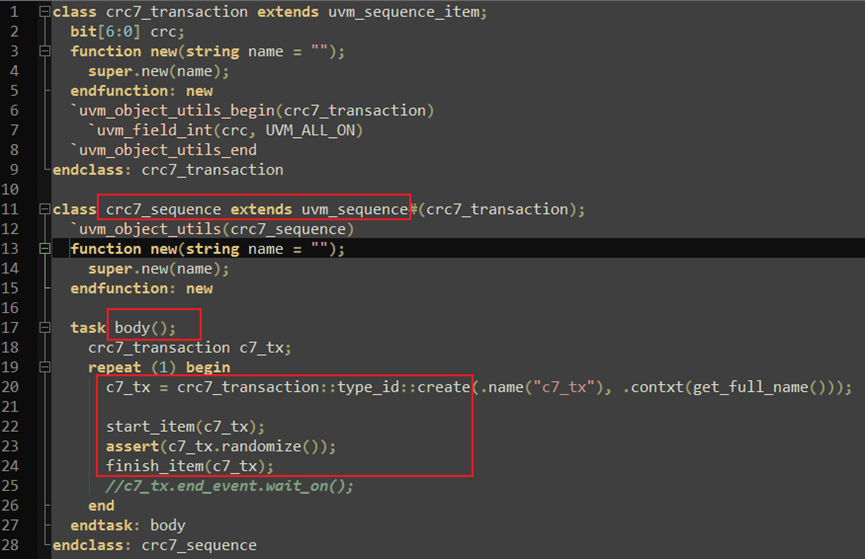
其实在body方法中这里执行的创建tr、start_item、随机和finish_item方法在UVM源码中用了宏来代替,最常用的有`uvm_do(tr)这个宏,如下图所示;
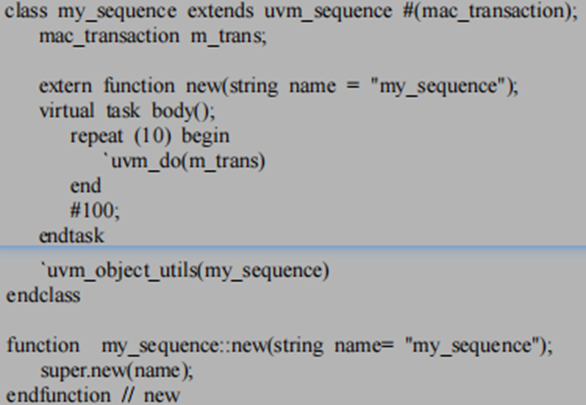
如果一个C复杂场景是先构造A场景,然后构造B场景,而此时A、B两种场景已经有了相应的sequence来实现了,此时这个复杂就可以通过`uvm_do直接执行A和B这两个sequence,即这个C复杂场景sequence的body函数中嵌套了A、B两个seq;

(2) sequence启动方式:
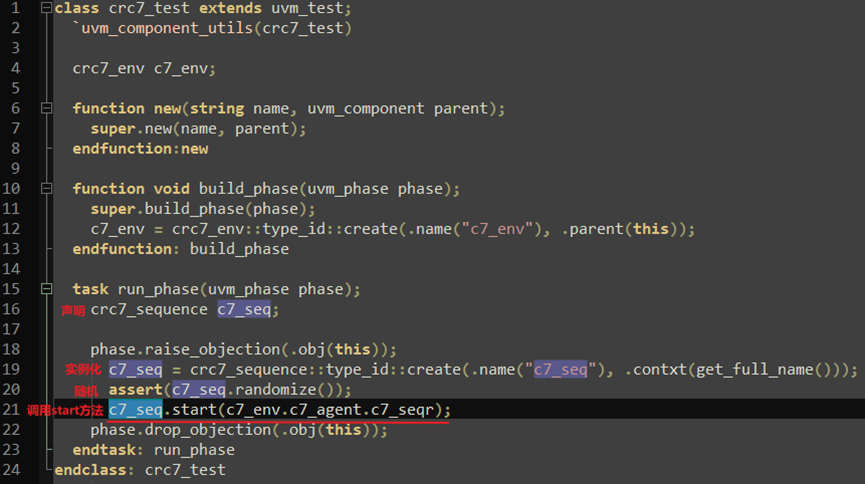
方法一:在testcase中直接启动:调用start()方法,如下所示,这个是在run_phase中启动的,那在仿真的时候也是执行到这里时会执行sequence的start方法;
 方法二:隐式启动:在tc的build_phase中通过uvm_config_db 配置 default_sequence启动(本质上还是调用start,在设置default_sequence这种方式时,这个seq可以先实例化,也可以先不实例化,uvm源码对这两种情况都支持);如下图所示;这种情况是在env.agt.sqr执行到main_phase时会执行这个sequence;
方法二:隐式启动:在tc的build_phase中通过uvm_config_db 配置 default_sequence启动(本质上还是调用start,在设置default_sequence这种方式时,这个seq可以先实例化,也可以先不实例化,uvm源码对这两种情况都支持);如下图所示;这种情况是在env.agt.sqr执行到main_phase时会执行这个sequence;
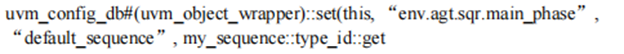
(3) virtual sequencer

TBD(待补充)
二、sequence机制源代码解析
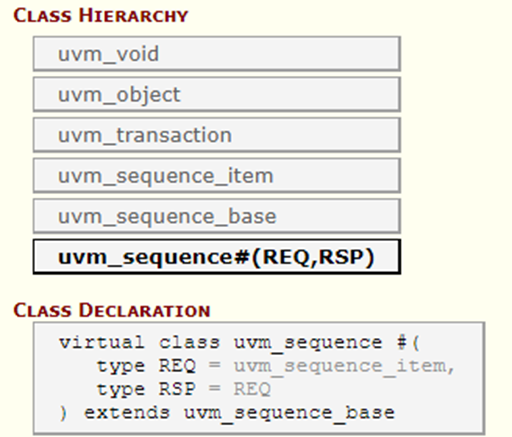
Sequences类继承关系
我们一般会通过default sequence来启动执行一个sequence,那它就会在sqr的main_phase中执行,或者通过start方法来启动执行一个sequence,这2种方法背后的原理是怎么样的呢?具体源代码执行了个什么呢?针对这些疑惑,我们接下来将一起看看源码;
首先看一下sequence类的继承关系;
sequence机制是需要sequence、sequencer、driver组件和TLM及其他机制(如config_db机制等)共同密切配合完成激励的下发的。其中sequence方面主要有以下类,其继承关系如下面介绍所示。
sequences封装了用户定义过程(user-defined procedures),这个过程生成多个基于事务的uvm_sequence_item。这些sequences可以以有趣的方式重复使用、扩展、随机化、顺序和分层组合,从而为DUT产生真实的激励。
使用uvm_sequence对象,用户可以封装DUT初始化代码、基于总线的压力测试、网络协议栈——任何程序性的东西——然后让它们都以特定或随机顺序执行,以更快地达到Corner情况和覆盖目标。
UVM sequence item和sequence类层次结构如下所示。
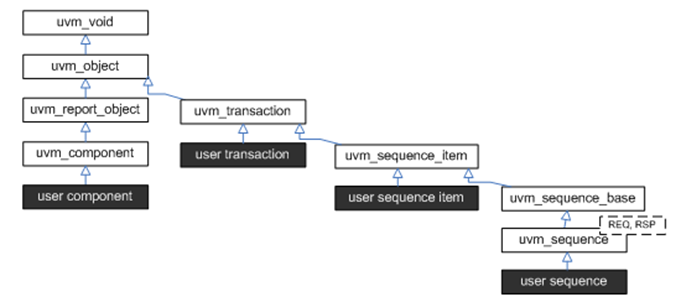
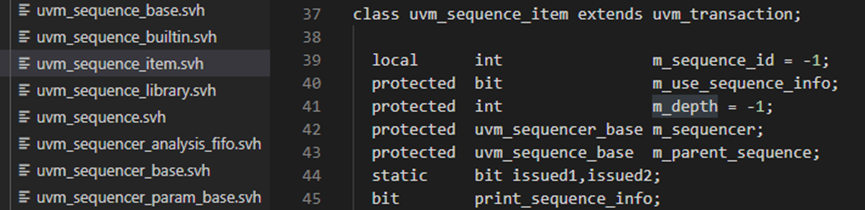
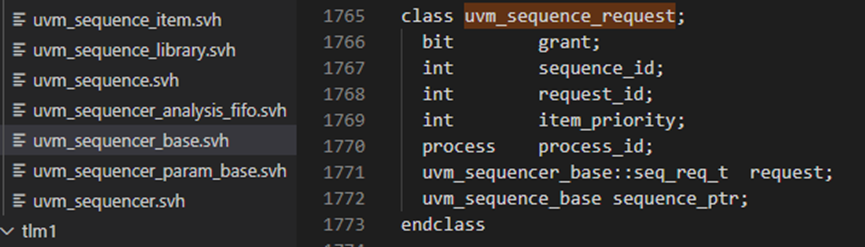
uvm_sequence_item:uvm_sequence_item 是用户定义事务的基类,它利用了sequence-sequencer机制的激励生成和控制功能。
uvm_sequence #(REQ,RSP): uvm_sequence 扩展了 uvm_sequence_item 以添加直接或通过递归执行其他 uvm_sequences 生成 uvm_sequence_items 流的能力。
通过上图可以看出了,先有uvm_transaction,其继承自uvm_object,后又uvm_sequence_item,uvm_sequence_item继承自uvm_transaction,最后有了uvm_sequence_base和uvm_sequence;
sequence相关类的源码文件介绍
uvm_sequence_item.svh文件
uvm_sequence_item
类的介绍:
用户定义的序列项的基类,也是 uvm_sequence 类的基类。 uvm_sequence_item 类为对象(包括序列项和序列)提供了在序列机制中操作的基本功能。

类的方法:
new:uvm_sequence_item 的构造方法。
get_sequence_id:私有方法;Get_sequence_id 是一种内部方法,不适用于用户代码。 sequence_id 不是一个简单的整数。 get_transaction_id 是为了让用户识别特定的transaction。
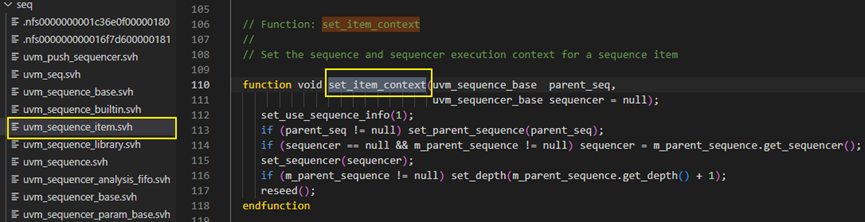
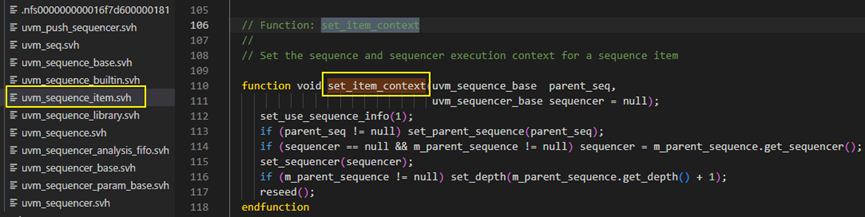
set_item_context:设置sequence_item的sequence和sequencer执行上下文
set_use_sequence_info、get_use_sequence_info:这些方法用于设置和获取 use_sequence_info 位的状态。
set_id_info:将被引用项目中的 sequence_id 和 transaction_id 复制到调用项目中。
set_sequencer:将序列的默认定序器设置为定序器。
get_sequencer:返回对此序列使用的默认排序器的引用。
set_parent_sequence:设置此 sequence_item 的父序列。
get_parent_sequence:返回对调用此方法的任何序列的父序列的引用。
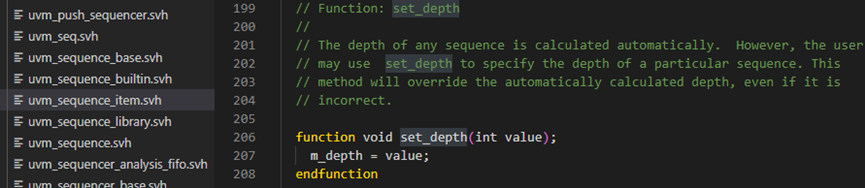
set_depth:自动计算任何序列的深度。
get_depth:从其父序列返回序列的深度。
is_item:这个函数可以在任何sequence_item 或sequence 上调用。
get_root_sequence_name:提供根序列(最顶层的父序列)的名称。
get_root_sequence:提供对根序列(最顶层的父序列)的引用。
get_sequence_path:提供完整层次路径中每个序列的名称字符串。
报告接口序列项目和序列将使用与它们关联的序列器来报告消息。
uvm_report、uvm_report_info、uvm_report_warning、uvm_report_error、uvm_report_fatal :这些是 UVM 中的主要报告方法。
uvm_sequence_base.svh文件
uvm_sequence_base
类的介绍:
uvm_sequence_base 类提供了创建序列项和/或其他序列流所需的接口。
通过直接调用或调用任何 `uvm_do_* 宏来调用序列的 start 方法来执行序列。
通过 start 执行序列
序列的 start 方法有一个 parent_sequence 参数,用于控制是否在父序列中调用 pre_do、mid_do 和 post_do。 它还有一个 call_pre_post 参数,用于控制是否调用其 pre_body 和 post_body 方法。 在所有情况下,总是调用它的 pre_start 和 post_start 方法。
当直接调用 start 时,您可以根据您的应用程序提供适当的参数。
序列执行流程如下所示
用户代码

依次调用以下方法

通过 `uvm_do 宏执行子序列
序列也可以作为父序列主体中的子代间接启动。 通过调用任何 uvm_do 宏间接调用子序列的 start 方法。 在这些情况下,调用 start 时将 call_pre_post 设置为 0,从而阻止调用启动序列的 pre_body 和 post_body 方法。 在子序列执行期间,调用父序列的 pre_do、mid_do 和 post_do 方法。
子序列执行流程看起来像
用户代码

依次调用以下方法
请记住,调用的是父序列的 pre|mid|post_do,而不是正在执行的序列。
通过 start_item/finish_item 或 uvm_do 宏执行序列项 通过调用 start_item/finish_item 或调用任何 uvm_do 宏,项目在父序列的主体中开始。 父序列的 pre_do、mid_do 和 post_do 方法将在项目执行时被调用。
序列项执行流程看起来像
用户代码

依次调用以下方法 尝试通过 start_item/finish_item 执行序列将产生运行时错误。
尝试通过 start_item/finish_item 执行序列将产生运行时错误。
类的方法:
do_not_randomize 如果设置,防止序列在被`uvm_do*() 和uvm_rand_send*() 宏执行之前被随机化,或者作为默认序列。
new uvm_sequence_base 的构造函数。
is_item 在项目上返回 1,在序列上返回 0。
get_sequence_state 将序列状态作为枚举值返回。
wait_for_sequence_state 等待序列达到给定状态之一。
get_tr_handle 返回此序列的完整记录事务句柄。
序列执行
start 执行这个序列,当序列完成时返回。
pre_start 此任务是用户可定义的回调,在可选执行 pre_body 之前调用。
pre_body 此任务是用户可定义的回调,仅当序列以 start 启动时才会在 body 执行之前调用。
pre_do 此任务是用户可定义的回调任务,如果任何序列已发出 wait_for_grant() 调用并且在定序器选择此序列之后且在项目被随机化之前,则在父序列上调用此任务。
mid_do 该函数是一个用户可定义的回调函数,在序列项被随机化之后,并且就在该项被发送到驱动程序之前调用。
body 这是主序列代码所在的用户定义任务。
post_do 此函数是一个用户可定义的回调函数,在驱动程序使用 this item_done 或 put 方法指示它已完成项目后调用。
post_body 该任务是一个用户可定义的回调任务,只有在序列以 start 启动时才会在 body 执行后调用。
post_start 此任务是一个用户可定义的回调,在 post_body 的可选执行后调用。
运行时阶段:
get_starting_phase 返回“开始阶段”。
set_starting_phase 设置“开始阶段”。
set_automatic_phase_objection 设置“自动对象到起始阶段”位。
get_automatic_phase_objection 返回(并锁定)“自动反对起始阶段”位的值。
顺序控制:
set_priority 序列的优先级可以随时更改。
get_priority 此函数返回序列的当前优先级。
is_relevant 默认 is_relevant 实现返回 1,表示序列总是相关的。
wait_for_relevant 当所有可用序列都不相关时,该方法由定序器调用。
lock 请求锁定指定的序列器。
grab 请求锁定指定的序列器。
unlock 移除此序列在指定序列器上获得的任何锁定或抓取。
ungrab 移除此序列在指定序列器上获得的任何锁定或抓取。
is_blocked 返回一个位,指示此序列当前是否由于另一个锁定或抓取而被阻止运行。
has_lock 如果此序列有锁,则返回 1,否则返回 0。
kill 这个函数将杀死序列,并导致序列的默认序列器中的所有当前锁和请求被删除。
do_kill 这个函数是一个用户挂钩,只要使用 sequence.kill() 或 sequencer.stop_sequences()(有效地调用 sequence.kill())终止序列,就会调用该函数。
序列项执行:
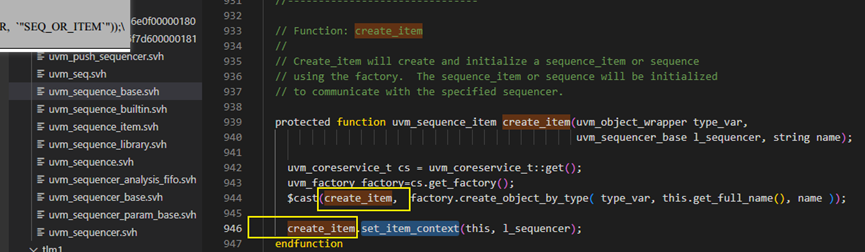
create_item: Create_item 将使用工厂创建和初始化一个 sequence_item 或序列。
start_item start_item 和 finish_item 一起将启动序列项的操作。
finish_item finish_item 与 start_item 一起将启动一个 sequence_item 的操作。
wait_for_grant 此任务向当前排序器发出请求。
send_request send_request 函数只能在 wait_for_grant 调用之后调用。
wait_for_item_done 序列可以选择调用 wait_for_item_done。
响应 API:
use_response_handler 当调用 enable 设置为 1 时,响应将被发送到响应处理程序。
get_use_response_handler 返回 use_response_handler 位的状态。
response_handler 当 use_response_handler 位被设置为 1 时,这个虚拟任务被序列器为每个到达这个序列的响应调用。
set_response_queue_error_report_disabled 默认情况下,如果 response_queue 溢出,则报错。
get_response_queue_error_report_disabled 该位为 0(默认值)时,响应队列溢出时生成错误报告。
set_response_queue_depth 响应队列的默认最大深度为 8。
get_response_queue_depth 返回响应队列的当前深度设置。
clear_response_queue 清空此序列的响应队列。
问题:
如下图中create_item是个指针吧?但是为什么没有声明它的地方?set_item_context是什么方法,源代码中怎么找不到?
set_item_context在uvm_sequence_item.svh文件中;
uvm_sequence.svh
uvm_sequence #(REQ,RSP)
类的介绍:
uvm_sequence 类提供了创建序列项和/或其他序列流所必需的接口。
变量
req 该序列包含一个名为req 的请求类型的字段。
rsp 该序列包含一个名为 rsp 的响应类型字段。
方法
new 创建并初始化一个新的序列对象。
send_request 该方法会将请求项发送到排序器,排序器会将其转发给驱动程序。
get_current_item 返回当前由 sequencer 执行的请求项。
get_response 默认情况下,序列必须通过调用 get_response 检索响应。
config_db方式发起一个sequence:
通过config_bd方式发起一个sequence,一般是在tc的build_phase中调用set方法,将这个sequence传递过去,代码示例如下:
//---------------------------------------------------------------------------------------------------------------//
uvm_config_db#(uvm_object_wrapper)::set(this,“*.m_seqr.run_phase”,“default_sequence”, my_sequence::get_type());
//---------------------------------------------------------------------------------------------------------------//
那执行了这个set之后,为什么会在sqr的main_phase或者run_phase中执行此sequence呢?
其实是因为在uvm_task_phase中的m_traverse方法中的第110行调用了seqr.start_phase_sequence(phase);我们知道需要消耗仿真时间的phase(比如reset_phase、main_phase等)都是继承自uvm_task_phase的,也就是在执行main_phase等这些phase时都会执行到下图中的m_traverse方法,也即都会执行到110行的seqr.start_phase_sequence(phase)方法。
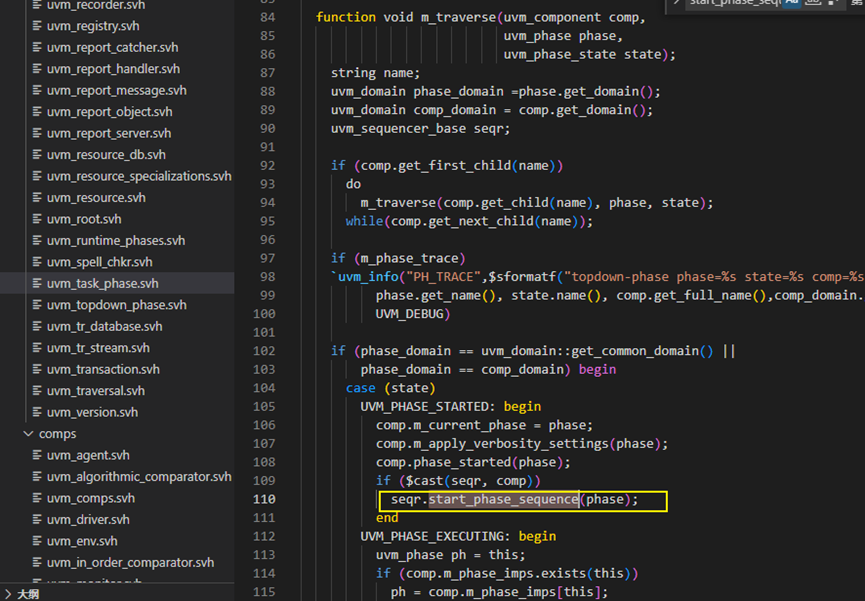
这个seqr.start_phase_sequence(phase)具体如下图所示,具体执行的东西是通过config_db得到set的seq,然后执行seq的start方法。
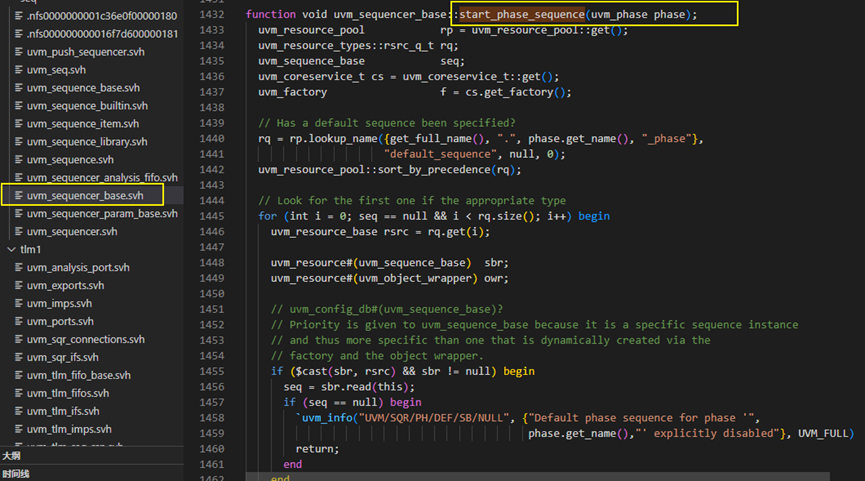

seq的start方法是什么呢?
start方法具体是uvm_sequence_base类中的方法,具体如下图所示。
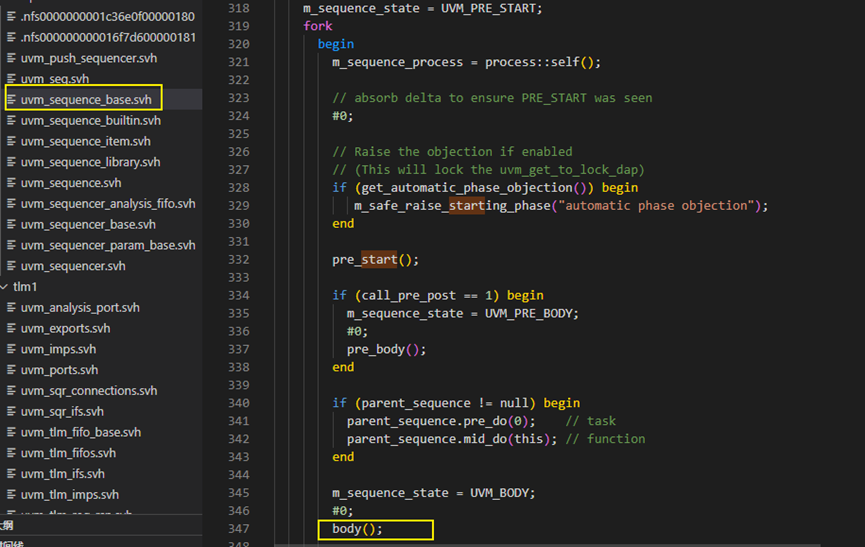
在这个start方法会执行347行的body方法,具体如下图所示。这个方法在uvm_sequence_base中定义,是个需方法,必须要重载,如果未重载,那么会报warning。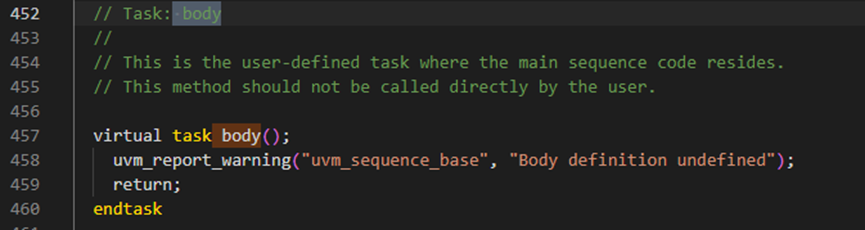
后面章节会对start方法进行详细介绍;
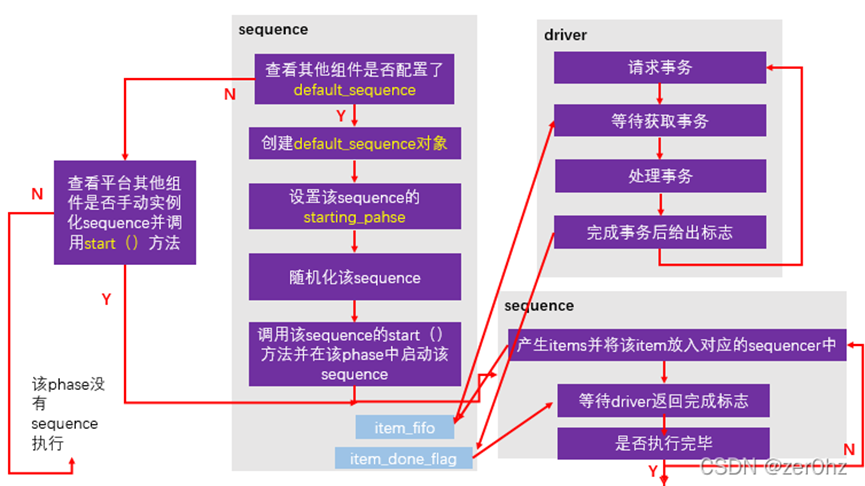
seq/sqr/drv相互配合通信机制图
(1)在sequence中放sequencer的句柄,在sequencer中放sequence的句柄,进行sequence与sequencer的“双向握手”;
(2)利用TLM机制进行driver、sequencer的握手。下文会对握手机制进行深入的剖析。
注:
用户自定义的transaction,是拓展自uvm_sequence_item这个类的。用户自定义的sequence是拓展自uvm_sequence的,而uvm_sequence又是从uvm_sequence_item拓展的。
1.driver发送request给sequencer;
2.sequencer把request数据发送给driver;
3.driver处理数据;
4.处理完成后,driver发送done给sequencer;
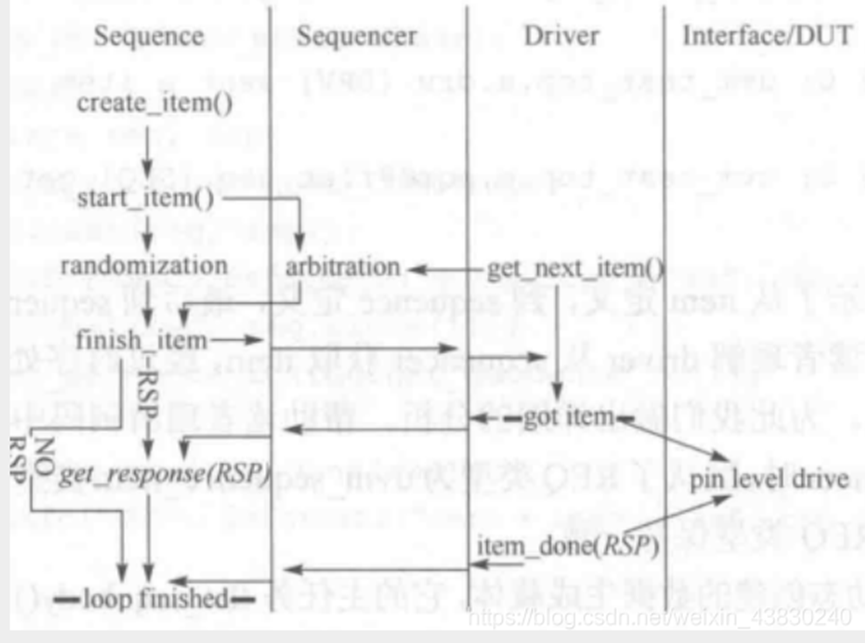
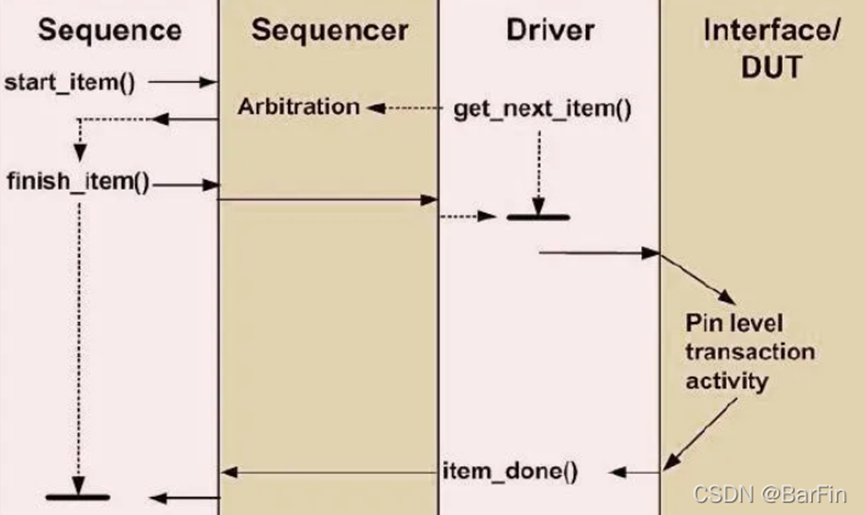
uvm_do宏定义的内容
在前面sequence的body方法中介绍了可以直接对某个transaction或者sequence执行uvm_do宏处理,那么`uvm_do宏的具体代码是什么?下面就是uvm_do宏的源代码;

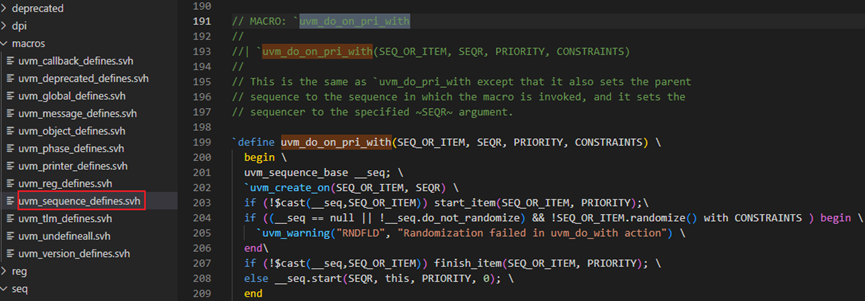
可以看到`uvm_do宏是又调用了uvm_do_on_pri_with宏,在这个宏中先创建实体,然后判断如果是item,则执行start_item,然后执行随机化,然后执行finish_item,如果是seq,则执行start方法;
start方法详解
start方法代码全貌:
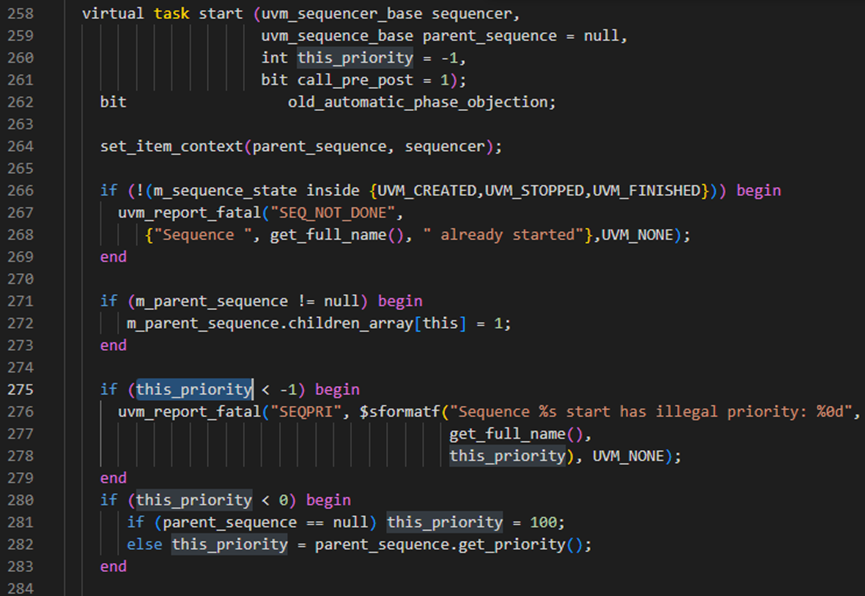
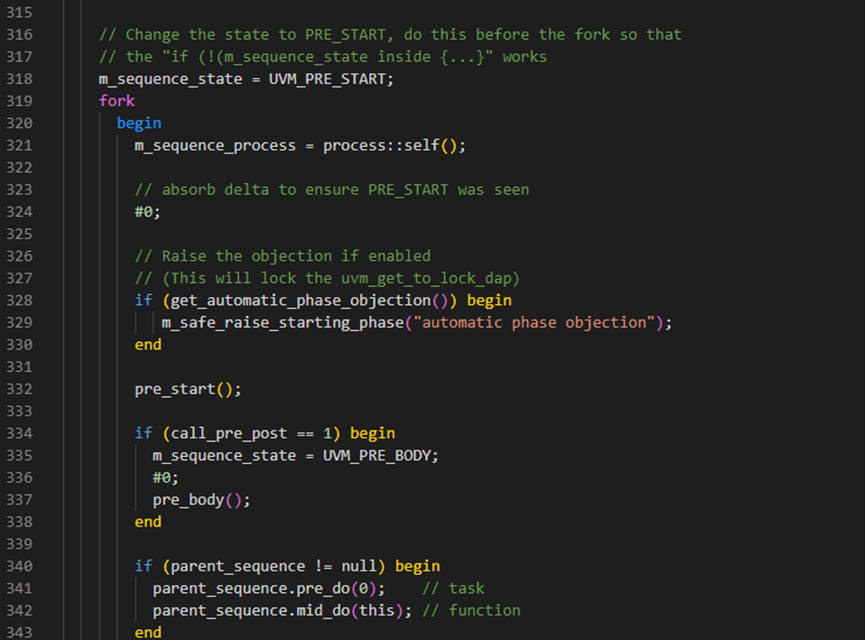
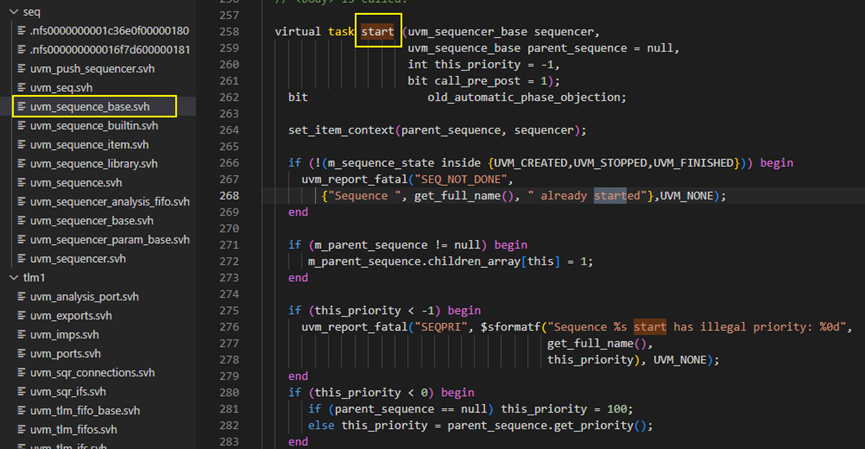
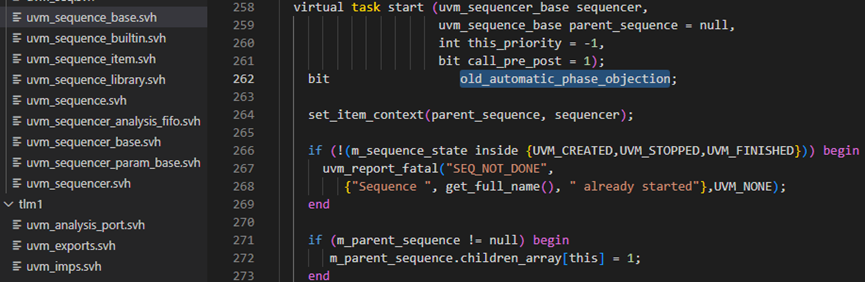
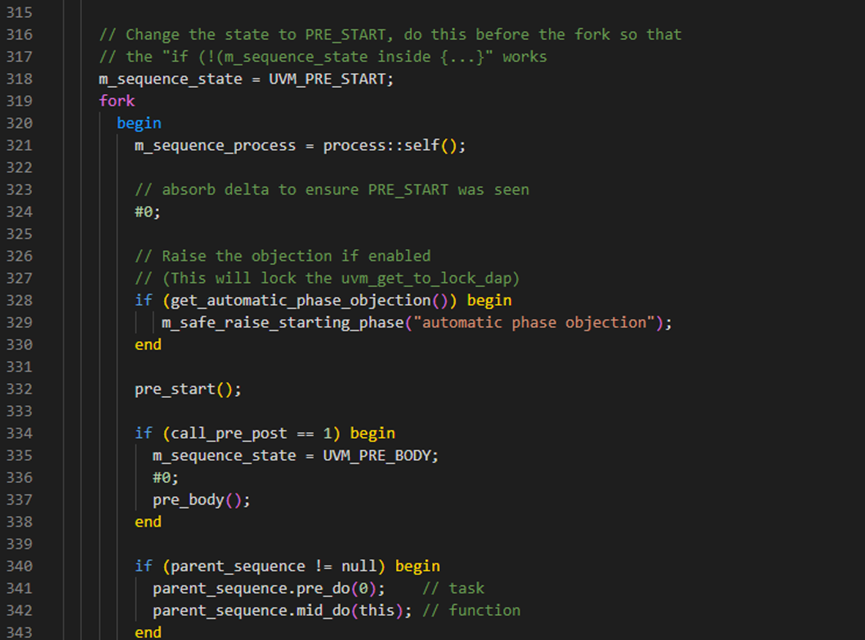
start方法有4个入参,如下图所示,第一个是uvm_sequencer_base类型的sequencer,第二个是uvm_sequence_base类型的parent_sequence,第三个是int类型的this_priority,指的是sequence的优先级,第四个是bit类型的call_pre_post,如果这个call_pre_post为1则执行pre_body和post_body,否则就不执行pre_body和post_body。
在start方法中的第262行,定义了局部变量old_automatic_phase_objection,这个具体化含义待弄清楚????
start方法中set_item_context方法
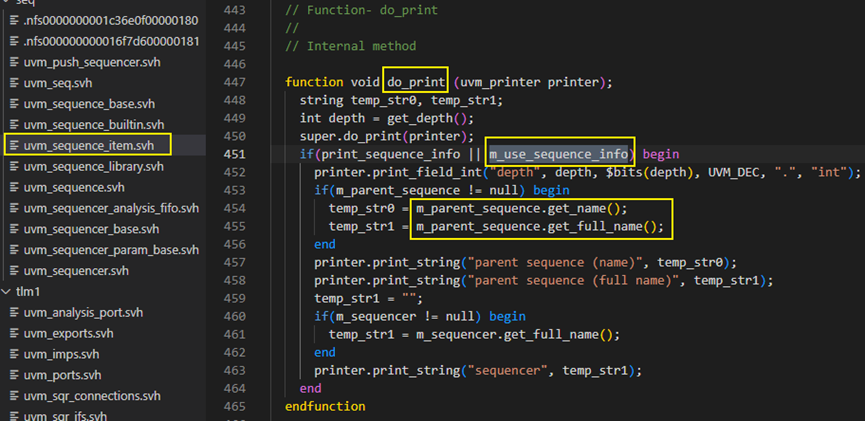
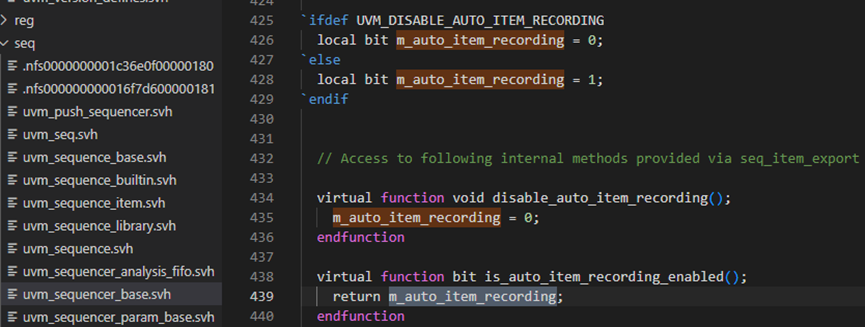
start方法接下来调用了set_item_context方法,并传入了parent_sequence和sequencer参量。set_item_context方法是在uvm_sequence_item中定义的,具体内容如下图,首先调用了set_use_sequence_info(1),这个是将值1传递给了m_use_sequence_info变量,而m_use_sequence_info变量控制了do_print方法中是否打印m_parent_sequence的信息。
再回到set_item_context方向中来,接下来判断parent_seq如果是非空指针,则将parent_seq作为入参调用set_parent_sequence方法,将parent_seq的指针给到m_parent_sequence。
之后判断如果sequencer为空但是m_parent_sequence非空,那么就将m_parent_sequence的m_sequencer给到sequencer变量(这里是调用了m_parent_sequence.get_sequencer方法,得到的是m_parent_sequence的m_sequencer)。
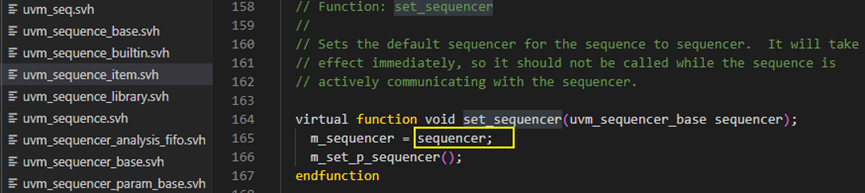
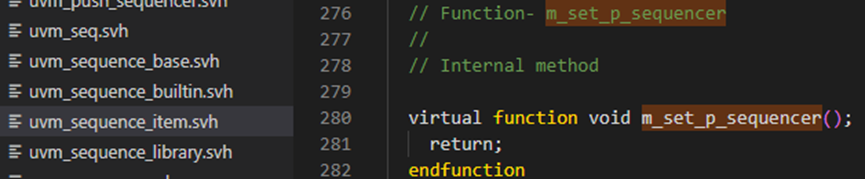
之后执行set_sequencer方法,传入sequencer参量,此时将sequencer指针赋值给m_sequencer,并调用m_seq_p_sequencer,在uvm_sequence_item中m_seq_p_sequencer是个空方法,只有在sequence中使用了`uvm_declare_p_sequencer宏时,这个方法会被重载。
之后再判断如果m_parent_sequence非空时,执行set_depth,这个含义目前还不清楚,存疑。之后执行reseed方法,重新随机种子。




再回到start方法上来,执行完set_item_context后,判断m_sequence_state是否处于正确状态,否则报fatal。然后判断m_parent_sequence如果非空,则将m_parent_sequence的children_array[this]关联数组置为1,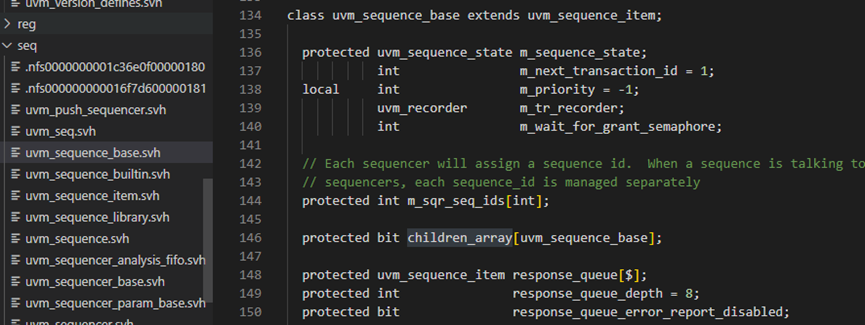
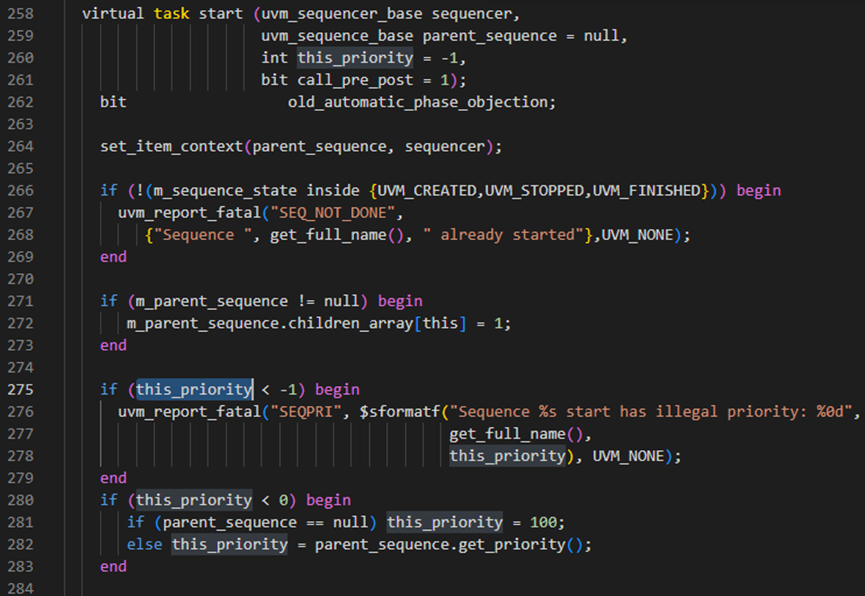
start方法中priority设置
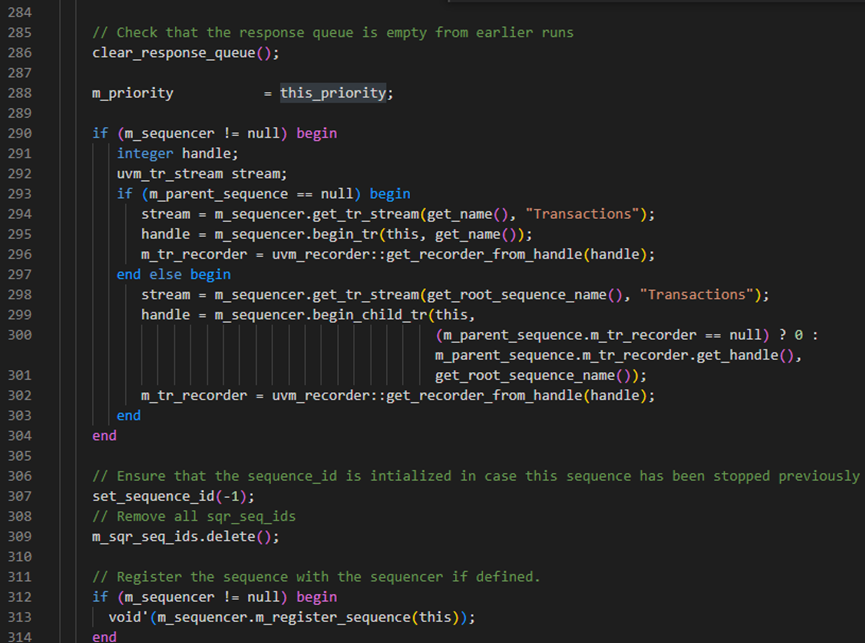
start函数的第275-283行进行优先级判断处理。其中276行是判断当传入的this_priority小于-1时,直接报fatal。而281-282行是判断当this_priority为-1时,也就是默认值时,如果parent_sequence为空时就将这个sequence的this_priority变量设置为100,否则就是如果有parent_sequence时,则更改this_priority为parent_sequence的m_priority设置为this_priority。设置好this_priority后,最后在start方法的第288行,会将this_priority赋值给到m_priority。



接下来start方法的第286行执行clear_response_queue方法,这个方法具体是执行了response_queue的delete函数,response_queue是一个uvm_sequence_item类型的队列,这样的目的就是将response_queue清空。


接下来start方法中判断m_sequencer如果非空,则开始调用begin_tr等,这些具体的作用是记录一下开始时间、触发事件等。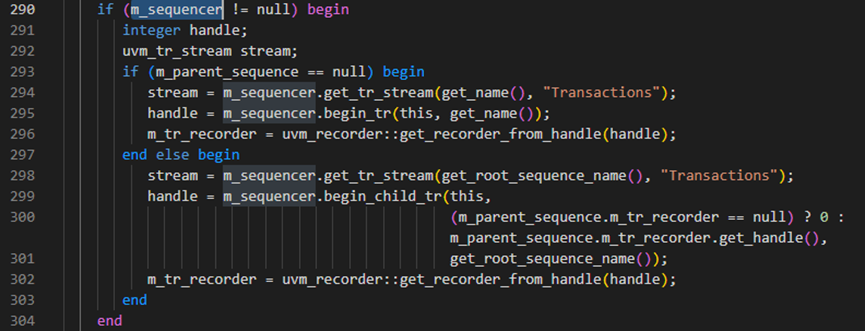
接下来start方法中执行set_sequence_id(-1)方法,这个方法的具体如下图,也就是说将m_sequence_id设置为-1;start方法之后调用m_sqr_seq_ids.delete()方法,这个方法是将关联数组m_sqr_seq_ids清零。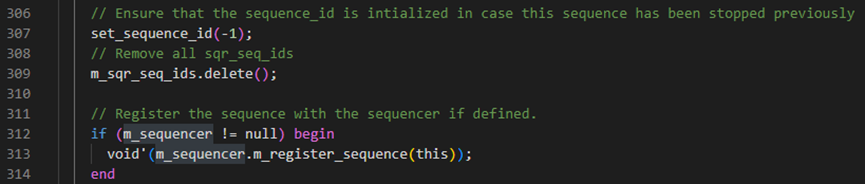

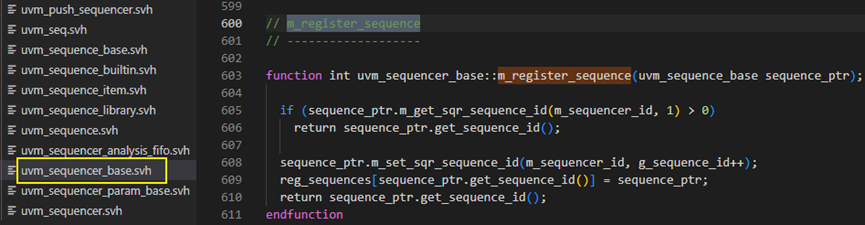
start方法中m_register_sequence方法
接下来start方法判断当m_sequencer不为空时,调用m_sequencer.m_register_sequence方法,这个方法具体如下图所示,在这个方法中首先判断了sequence_ptr.m_get_sqr_sequence_id(m_sequence_id,1)是否大于0,这里的m_sequencer_id是一个int类型的,其是在sequencer实例化new时得到静态变量g_sequencer_id的值。



我们先来看m_register_sequence的第608行,m_set_sqr_sequence_id具体如下所示,是将m_sqr_seq_ids关联数组中sequencer_id索引赋值为sequence_id,而这个sequence_id是g_sequence_id(这是一个静态int类型,每有一个seq调用此m_register_sequence时,g_sequencer_id就自加一,也就是说每个sequence有独一的这个id,然后在m_set_sqr_sequence_id方法的1400行,调用了set_sequence_id方法,将sequence独一无二的id设定为seq自有的m_sequence_id。
我们再回过头来看m_get_sqr_sequence_id方法,其具体内容如下图,从第下图中1381-1391行可以看出,先判断了m_sqr_seq_ids这个关联数组中有没有已经有这个sequencer_id,如果有,就将sequencer_id对应的sequence_id做为入参调用set_sequence_id方法,然后就退出此方法,假如m_sqr_seq_ids中关联数组中如果没有当前这个sequencer_id,那就set_sequence_id设置为-1。也就是说m_register_sequence方法中的605行是为了避免重复注册。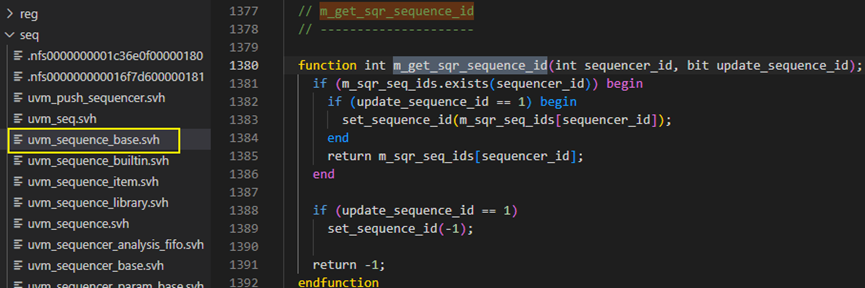
接下来m_register_sequence方法的第609行执行了reg_sequences关联数组的赋值,实际功能是将这个sequence及其sequence_id存进这个关联数组中;reg_sequence关联数组是索引为int类型值为uvm_sequence_base类型的关联数组。

可见,所谓的注册,一方面是给sequence的m_sequence_id赋值,给sequence的m_sqr_seq_ids中插入一条记录,另一方面是在sequencer的reg_sequences中插入一条记录。通过这种注册,sequence从sequencer中获得m_sequence_id的值,有了这个id,它才能在整个验证平台中通行。而作为颁发m_sequence_id的sequencer,它自然要记录自己颁发了哪个sequence_id,并把其颁发给了谁?
start方法中*_body方法调用
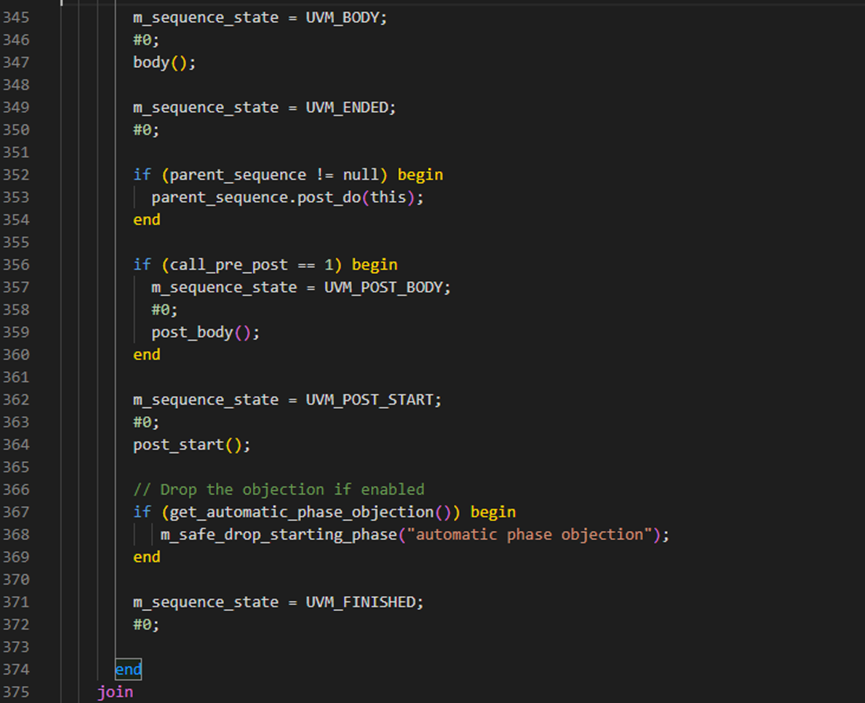
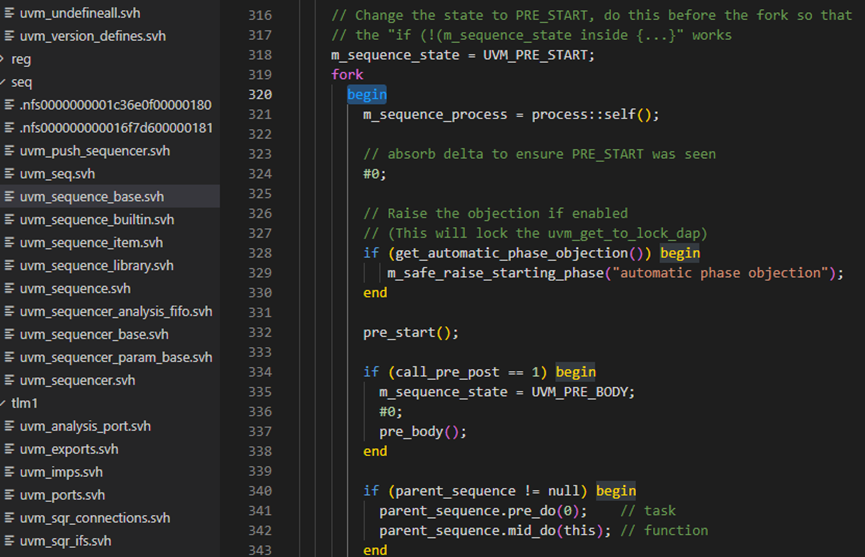
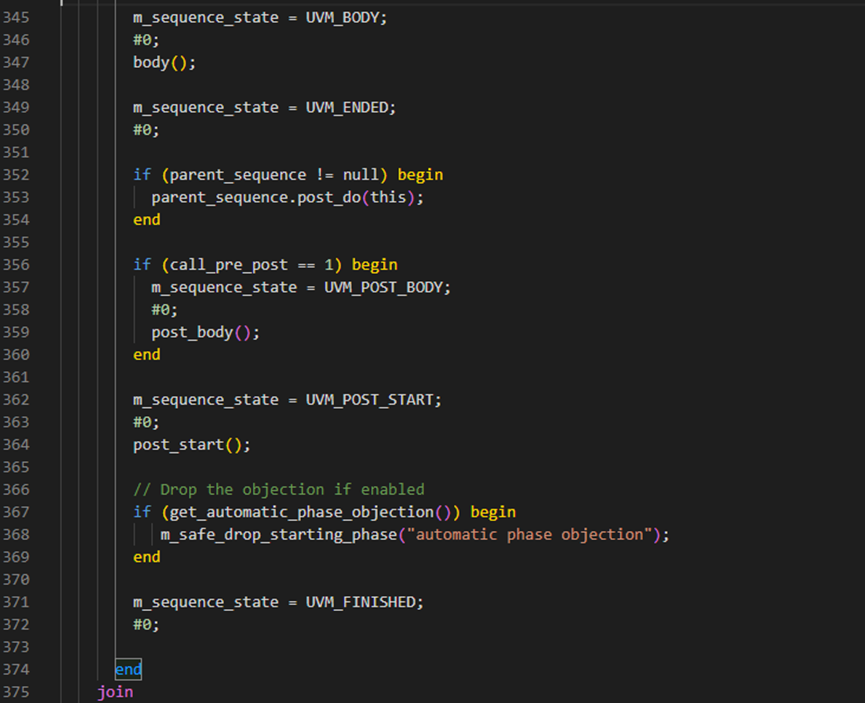
再回到start方法上,接下来就进入了forkjoin进程,如下图所示,在这个进程中通过调用pre_body,body等,让sequence的状态从PRE_START一直演变到FINISHED。这就是为什么当一个sequence启动后,系统会自动的执行body等的原因所在。
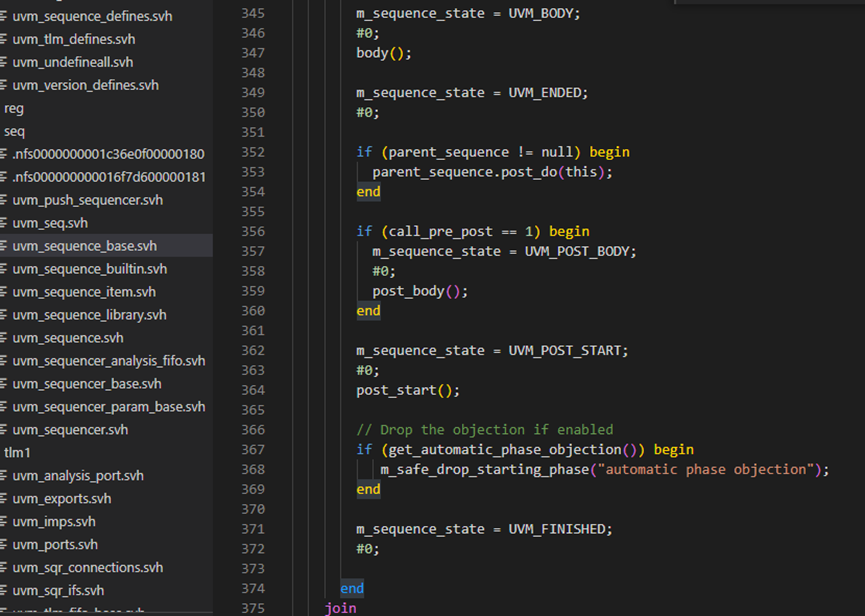
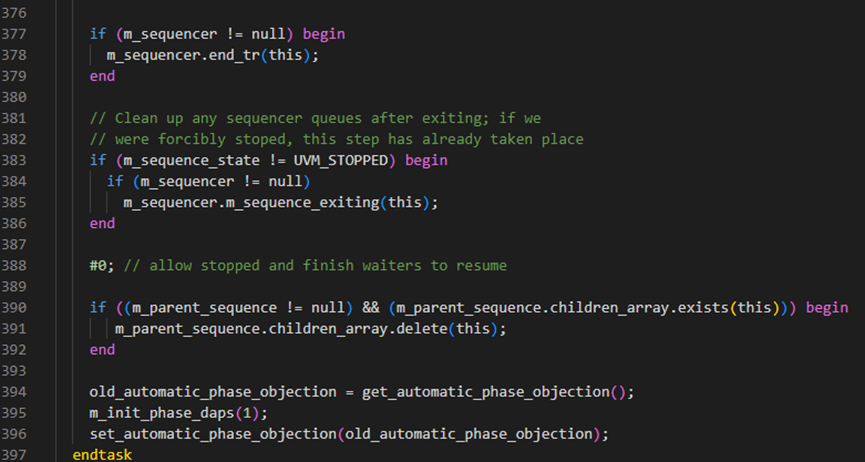
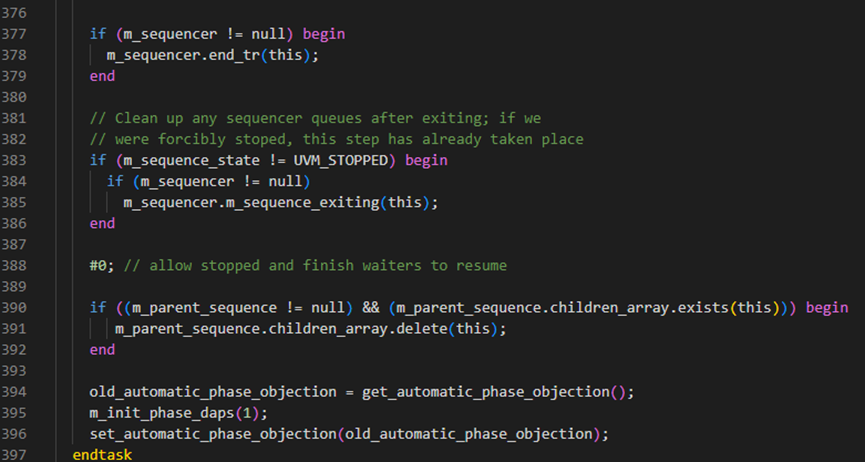
start方法接下来判断如果m_sequencer非空时,执行end_tr。然后在383行判断这个sequence是自然执行完毕还是被别的进程杀死根本没有执行完。如果是自然执行完毕,其状态将是FINISHED,如过是被杀死的,其状态是STOPPED。这里也就是说当为正常执行完时,会调用m_sequencer的m_sequence_exiting函数。
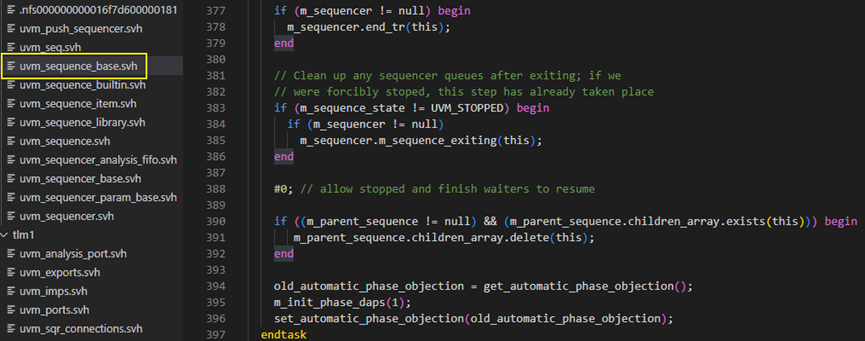
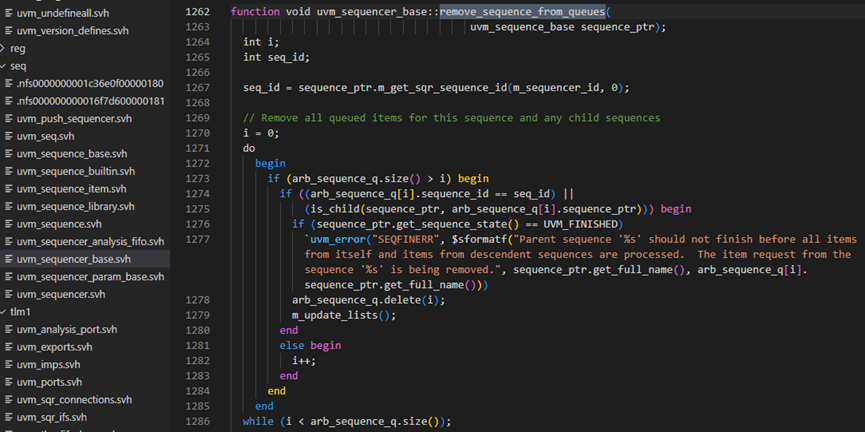
m_sequence_exiting具体如下图所示,其会调用remove_sequence_from_queue方法,具体如下面图所示,图中1267行是得到sequence的id,1270-1286行将会从arb_sequence_q中删除关于这条sequence的记录。arb_sequence_q是sequencer用于仲裁的一个队列,当有多个sequence同时请求发送sequence_item时,它通过这个队列来进行仲裁,关于仲裁这一点,将在后面详细介绍。1289-1305行是用于删除lock_list中的记录。由于一个sequence可以把一个sequencer给lock住,由于此sequence中已经结束,所以理应把其lock信号给删除。
其实无论是仲裁信息,还是lock信息,在一个sequence自然执行完毕的情况下,lock_list和arb_sequence_q中都不会有此sequence的记录。这里有这么多代码这样操作其实是为了应对sequence不是正常中止,而是被其他进程杀死的情况,这也就是为什么下面1722和1296行会报uvm_error了。
remove_sequence_from_queues方法的最后还调用了m_unregister_sequence方法,这个与register_sequence是相对于的。register_sequence是在reg_sequences中插入一条记录,这个函数则是从其中删除一条记录,即解除注册。



start方法接下来判断如果m_parent_sequence.children_array中有这个seq,那么就从children_array中将这个给删除掉。之后对automatic_phase_objection进行了一些处理,这个具体还不清楚,待解答。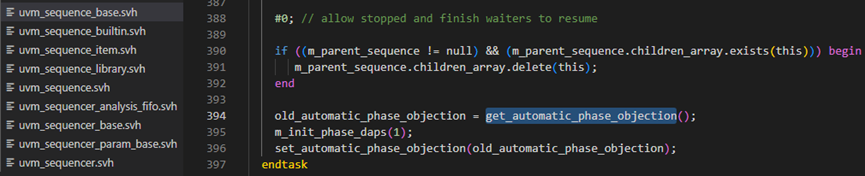
start_item方法详解
start_item方法代码全貌:

start_item函数入参,start_item方法有3个入参,第一个是uvm_sequence_item类型的item,第二个是int类型的set_priority,第三个是uvm_seqeuncer_base类型的sequencer。
start_item方法中首先声明了一个uvm_sequence_base类型的句柄seq。然后判断看传进来的局部变量item如果为空的话报fatal,然后退出start_item方法。
start_item方法接下来通过cast的方式来判断item是不是uvm_sequence_base的子类,如果是则报fatal,结束start_item方法。
start_item方法接下来判断如果sequencer为空指针的话,就将item.get_sequencer的结果(结果是返回的m_sequencer,m_sequencer是seq.start()方法时设定的)给到sequencer。982行也是一样的,985行则判断如果此时sequencer还是空的话,则报fatal,也就是说一个seq_item想要正常start_item成功就必须有sequencer。
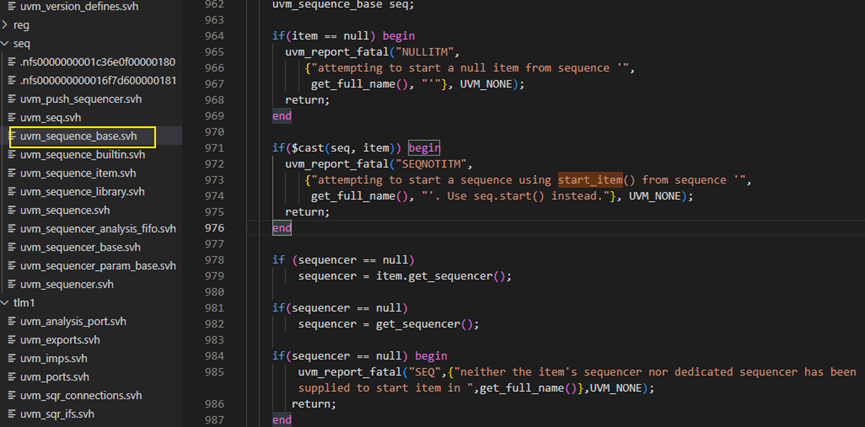

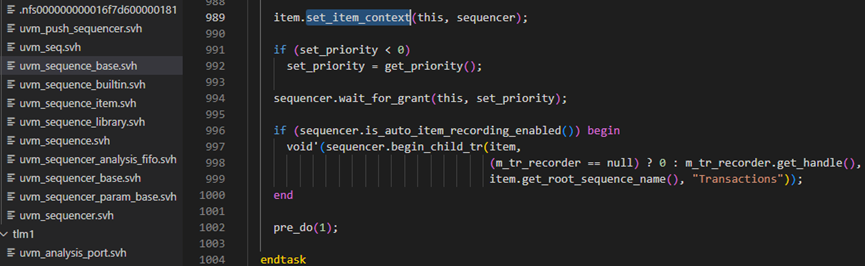
start_item方法接下来是调用item.set_item_context方法,此方法在start函数中有详细介绍,这里不再介绍。
start_item方法接下来判断set_priority如果小于0,则将get_priority方法的返回值给到set_priority,get_priority方法返回的是m_priority(m_priority是在seq.start方法调用中设置了的)。

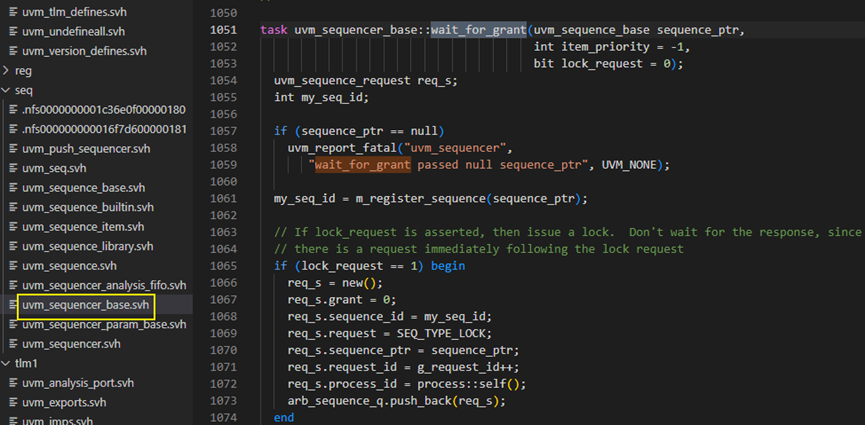
start_item方法中wait_for_grant方法
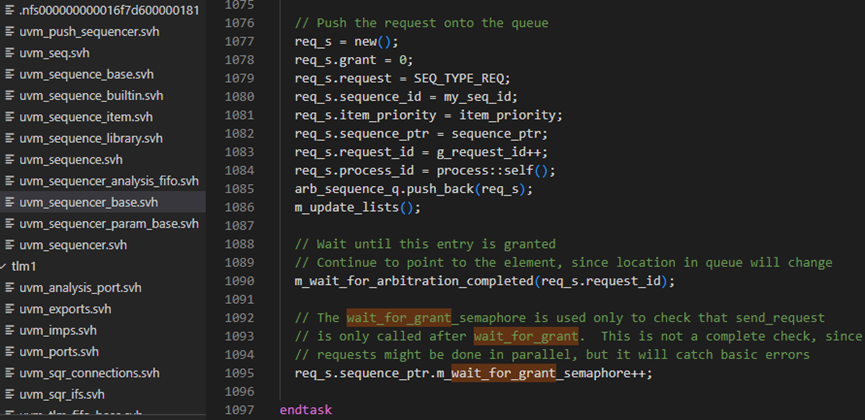
start_item方法接下来调用sequencer.wati_for_grant(this,set_priority)方法,此方法具体见下图,在第1061行得到sequence的id,1063-1074行用于有lock请求时,1077-1096行用于系统的仲裁机制;1085行是将一个req_s请求放入arb_sequence_q中。req_s是uvm_sequence_request类,其用于记录sequence向sequencer发出的请求信号,包括了sequence的id、sequence的指针及请求的类型。请求的类型有三种,分别为发送item的请求、lock请求和grab请求,看最后一个grab请求实际上用的还是第一个类型。1086行调用了m_update_list方法,具体就是将m_lock_arb_size++。1090行则是通过m_wait_for_arbitration_completed来等到仲裁完成,关于仲裁机制,后面会详细介绍。1095行则主要是用于保证send_request是在wait_for_grant之后被调用的。



start_item方法接下来调用了sequencer.is_auto_item_recording_enabled方法,来调用sequencer.begin_child_tr来记录seq的一些信息比如时间等(和start方法调用时的一样)。
start_item方法最后调用了回调函数pre_do方法,pre_do方法是用户自定义方法。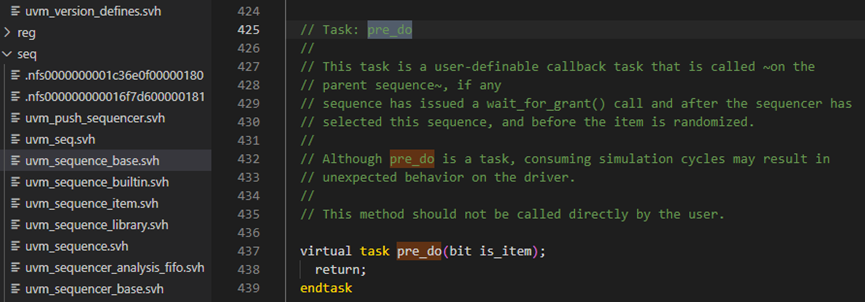
sequence仲裁机制
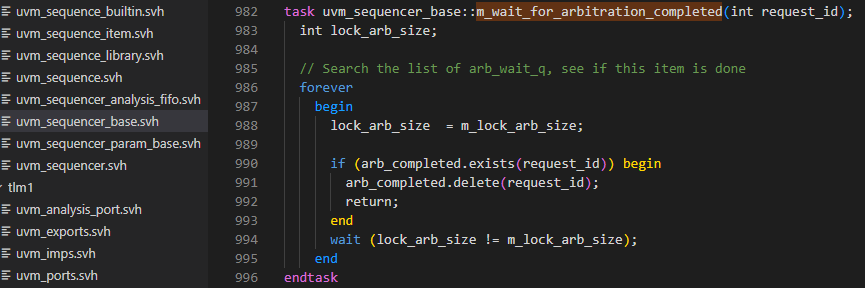
在start_item方法中调用了m_wait_for_arbitration_completed来等到仲裁完成,这个方法具体为下图所示,这个方法就是先进来lock_arb_size等于m_lock_arb_size后判断arb_completed关联数组中是否有request_id索引,有的话,就删除掉,然后退出m_wait_for-arbitraton_completed方法,否则当m_lock_arb_size有变换时,就再执行一次上述的判断。

m_lock_arb_size变换可能是因为有新的request加入了arb_sequence_q,也可能是仲裁完成引起的。m_lock_arb_size的变换要依靠driver的行为来改变。当在driver调用get_next_item时,会直接调用uvm_sequencer的get_next_item方法,具体如下图所示。212行与216行的判断条件是为了避免一个item重复的被发送的情况。217行调用m_select_sequence方法,之后223行会阻塞在那里等待m_req_fifo中放入要发送的item。
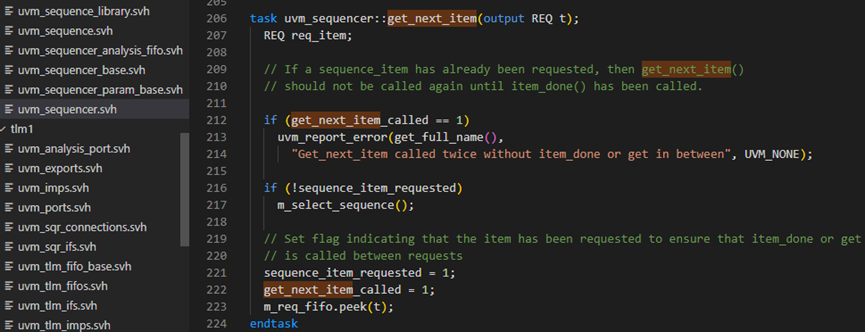

m_select_sequence方法具体如下图,717行调用wait_for_sequence,这个其实只是简单的#0延时,并无实质性内容。718行调用m_choose-next_request,此函数会返回可用的sequence在arb_sequence_q中的序号。如果没有可用的sequence,那么会返回-1,此时会执行720行,就会一直等到有可用的sequence。725行调用m_set_artbiration_competed方法,此方法具体如下图所示,只是在arb_completed中插入一条记录。726行把选定的sequence从仲裁队列中删除,727行更新m_lock_arb_size的值。此值改变,那么m_wait_for_arbitration_completed的918行将会被释放,表示此sequence已经获得了请求,后续的可以调用finish_item,包sequence_item发送给driver。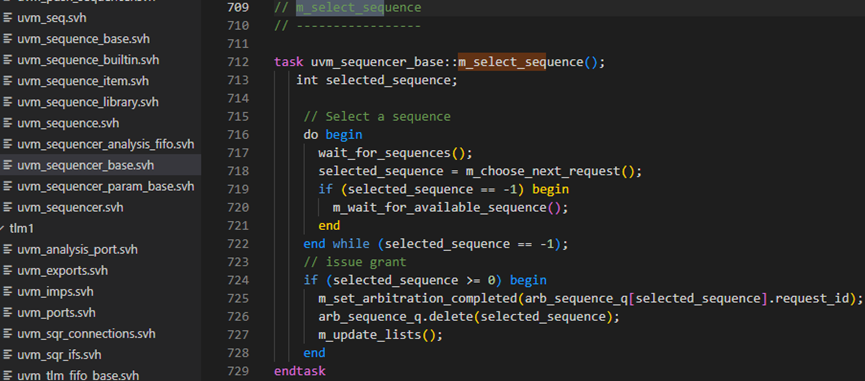



这里的关键是m_choose_next_request函数,此函数的全貌如下图,这个函数是仲裁机制的具体体现。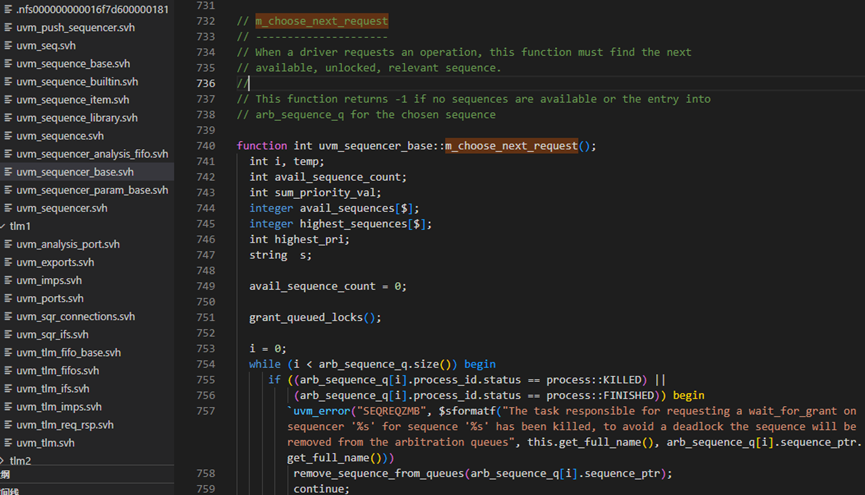
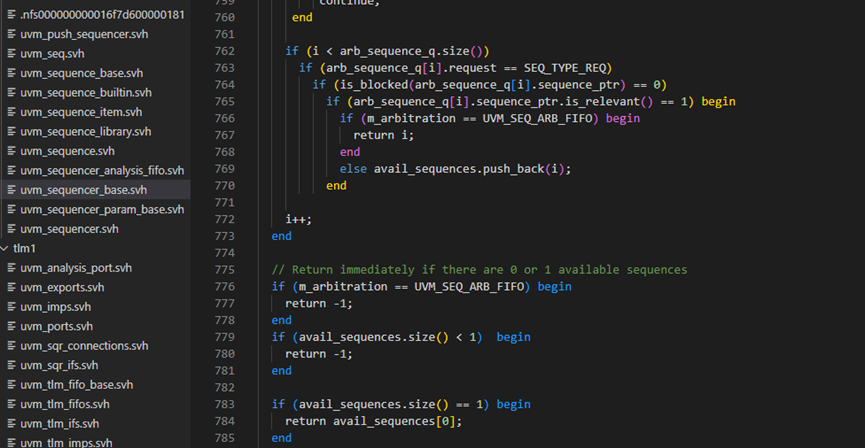
m_choose_next_request函数的第751行调用了grant_queued_locks方法,这是处理lock请求时要考虑的,这里暂且跳过。764行调用了is_blocked方法,这个也是处理lock时用到的,这里暂且跳过。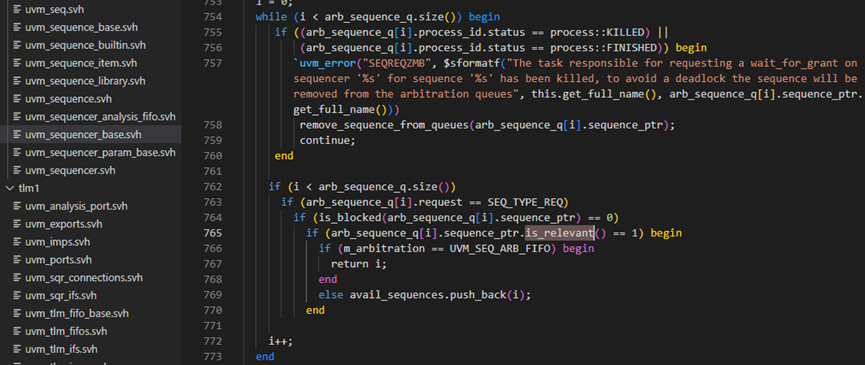
m_choose_next_request函数的第765行,调用了is_relevant方法,这个方法具体如下图所示,它是用于判断这个sequence是不是有效,如果无效,那么sequencer在仲裁时将不会考虑这个sequence。这是sequence主动控制自己发送item行为的一种方式,通过重载is_relevant函数,sequence可以动态控制是否发送item。
回到m_choose_next_request函数,在761-765行的条件都满足的情况下,那么根据设置的仲裁算法决定让哪一个sequence发送item。如果算法是SEQ_ARB_FIFO,那么将会直接返回当前的请求,否则把所有可用的请求放入avail_sequences中。

m_choose_next_request函数的第777和779行如果条件满足,说明761-765行的语句没有找到可用的request,这也就意味着根本就没有sequence要求发送item,此时会直接返回-1.如果783行条件满足,则表示如果只有一个sequence提出了请求,那么无论是采用什么仲裁方法,都只有选择这个sequence。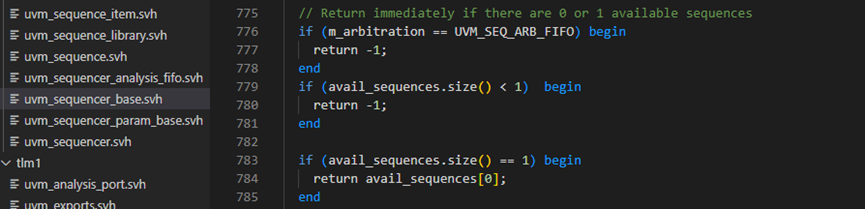
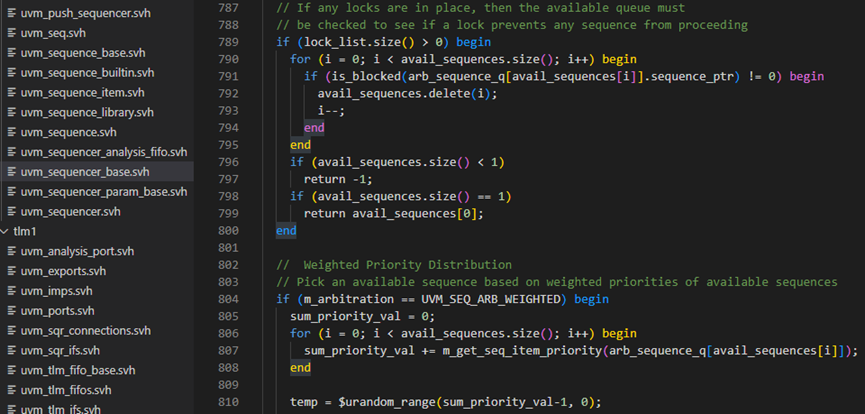
m_choose_next_request函数789-800行用于处理有lock请求存在时的情况,先跳过。
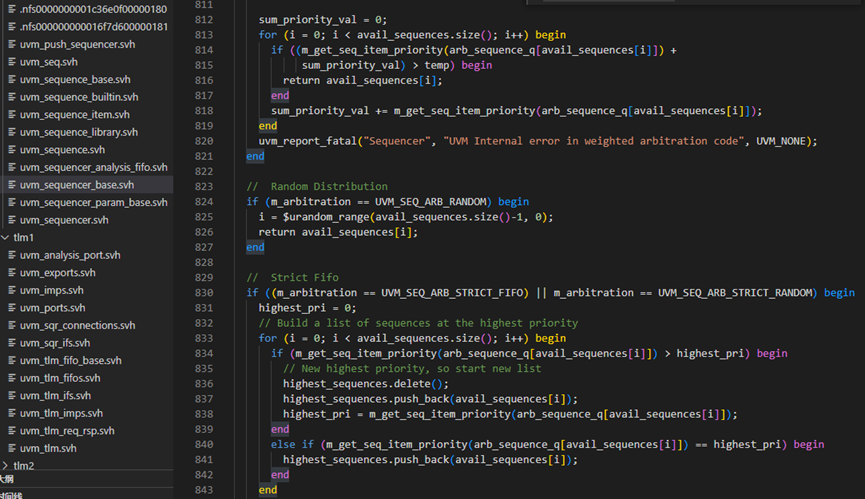
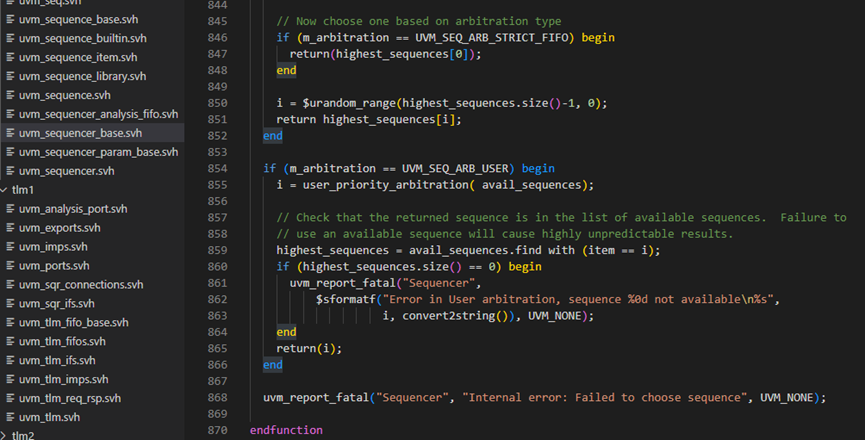
m_choose_next_request函数804-866行,则是根据不同的算法来处理请求。这里的算法定义位于uvm_object_globals.svh文件中。SEQ_ARB_FIFO表示先到的请求先发出,SEQ_ARB_WEIGHTTED则是给每个请求赋予一定的权重,根据不同的权重,随机的选择,SEQ_ARB_RANDOM则是纯粹的随机,即所有的请求的权重相同,SEQ_ARB_STRICT_FIFO则是表示先把请求按照priority分类,然后把有最高priority值的按时间顺序发出,SEQ_ARB_STRICT_RANDOM则是把请求按照priority分类,然后从最高priority值的请求中随机挑选一个,SEQ_ARB_USER则是用户自定义的行为。
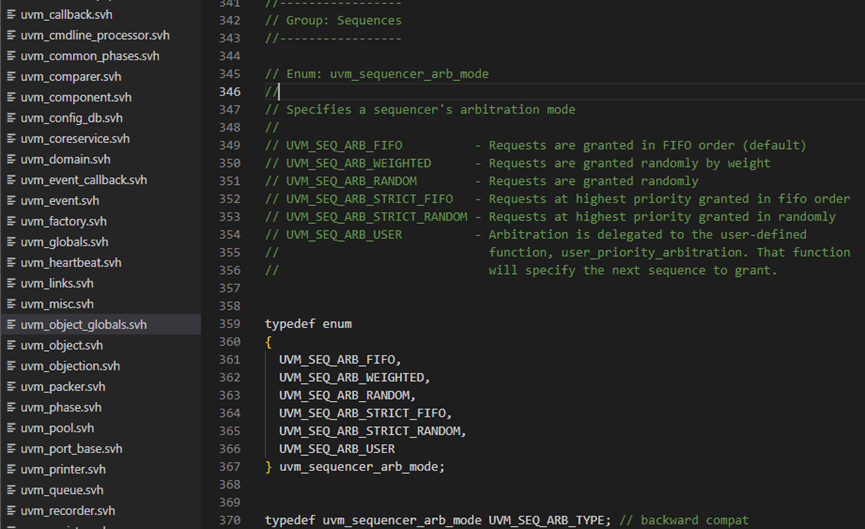
有lock请求时仲裁机制如何完成
接下来我们看一下当有lock请求时,仲裁机制是如何完成的。lock请求有2种,1是grab,2是lock。
grab和lock的定义如下图所示,2者都会调用m_lock_req方法,只是传入的参数不同。


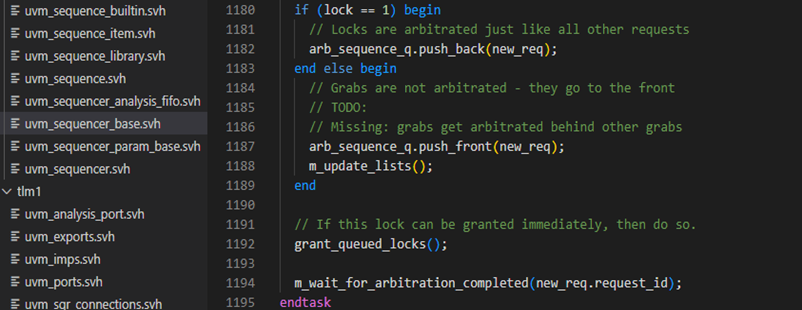
m_lock_req的定义如下图,1171行得到sequence的id,1172-1178行产生一个SEQ_TYPE_LOCK的请求,注意,这里是不区分lock还是grab的。lock和grab在1180-1189行进行了区分,lock时传入的lock值为1,则此时这个新产生的请求将会直接送入arb_sequence_q中,并且是放入这个队列的最后一个。但是如果是grab调用时,则是会放入队列的顶端,这样在发送下一个item时,首要的就是处理这个请求。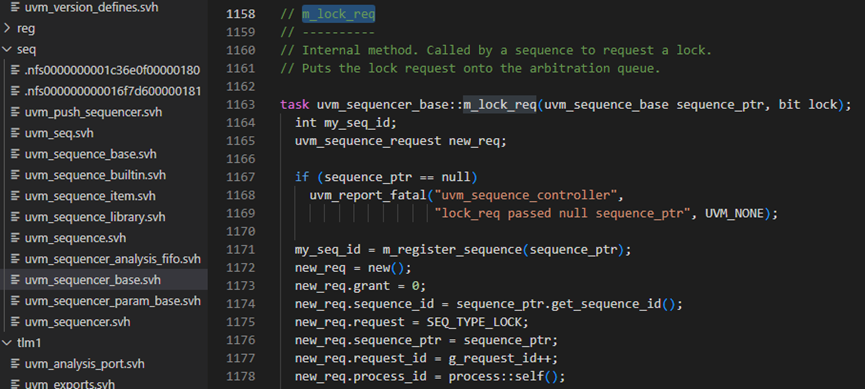
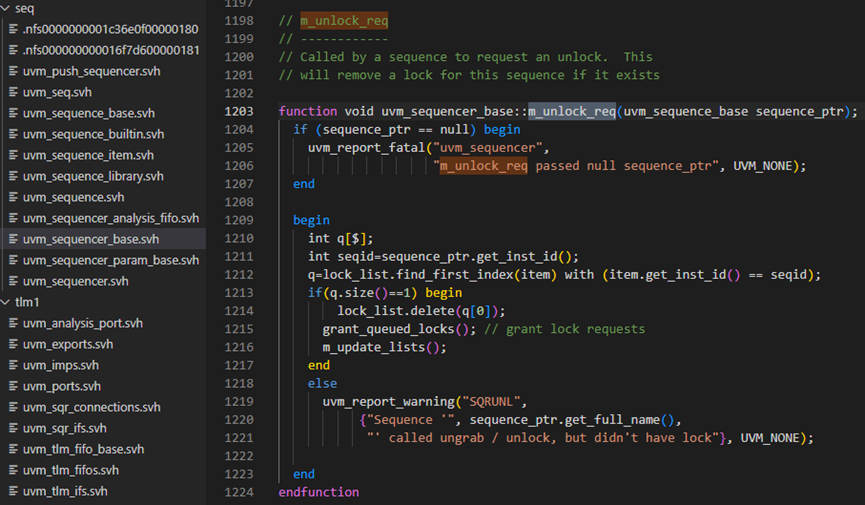
m_lock_req方法接下来调用了grant_queued_locks方法,此方法具体如下图,首先662-670行移除有死锁控制的sequence。664行会检查记录是否是SEQ_TYPE_LOCK类型的。685行将会调用is_blocked方法,我们先跳过这个函数,看697行,这一行会把一个发出lock请求的sequence放入lock_list中。也就是说,lock_list中存放的是所以发出lock请求的sequence的指针。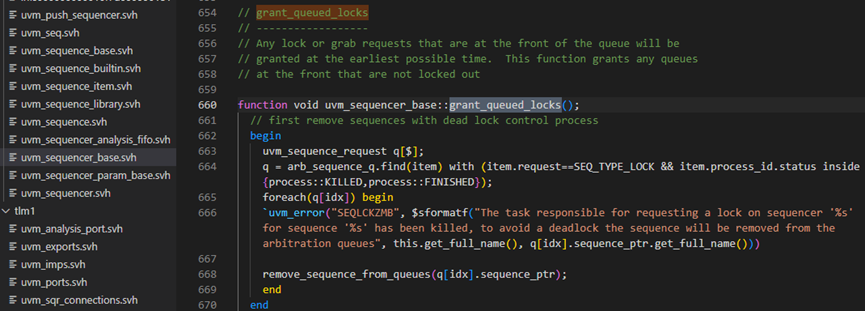
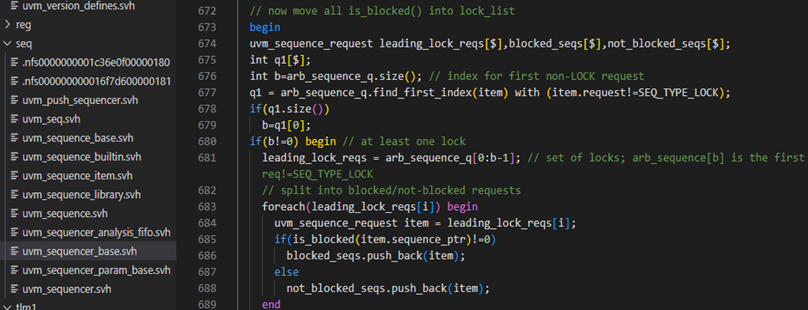
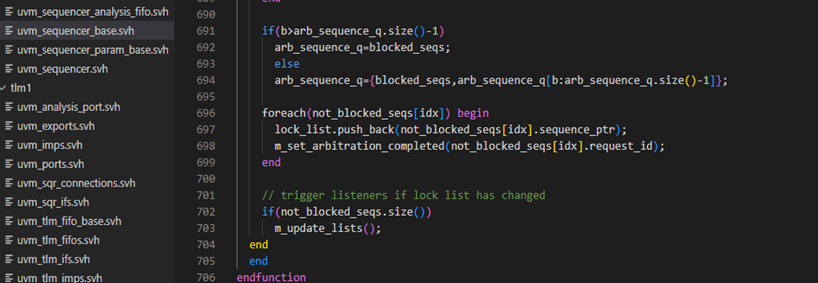
再回看一下is_blocked函数,具体如下图,如果lock_list中没有记录,那么将会执行1135行,将会直接返回0,也就是意味着没有sequence提出lock请求。1129-1131行用于判断lock_list中的记录内容是不是由这个sequence或者此sequence的parent_sequence发出的。如果都不是,说明有其他的sequence提交了lock请求,此sequencer已经被其它的sequence锁定了,于是会直接返回1.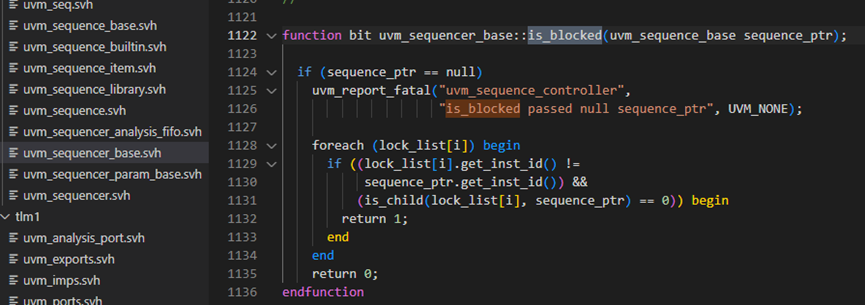
《uvm1.1源码解析》截图:

unlock和ungrab
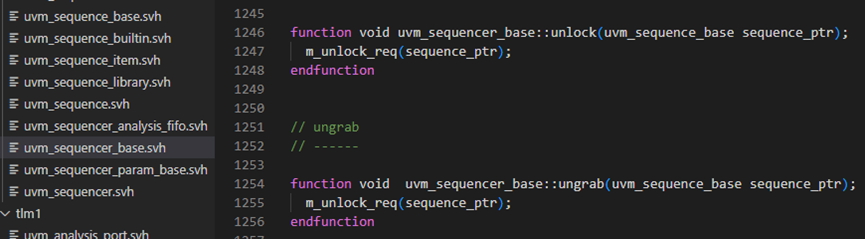
看一下unlock和ungrab,具体如下图,两个方法都是调用m_unlock_req方法,m_unlock_req方法主要是从lock_list中删除相关的记录。
因此总结一下grant_queued_locks做的事情,它会检查arb_sequence_q中的记录,如果发现SEQ_TYPE_LOCK类型的,那么将会把发出的这条记录的sequence放入lock_list中,表示此sequence中已经把sequencer给锁定了。假设arb_sequence_q中有3条SEQ_TYPE_LOCK记录,分别是由seq1、seq2、seq3发出的,那么调用grant_queued_locks时,将处理seq1的请求,让seq1获得sequencer的使用权。arb_sequence_q中关于seq1的记录被删除。seq2和seq3的记录还一直存在。当seq1把sequencer给释放之后,在m_choose_next_request时,会再次调用grant_queued_locks,此时它将会把sequencer的使用权赋予seq2,直到seq2把sequencer给释放。
我们回归m_choose_next_request中,调用了is_blocked函数,当时我们直接跳过了,现在回头来想一下,这里的意思是就是看一下arb_sequence_q中的要求发送item的sequence是不是准许被sequencer发送item(即有没有其他的sequence把sequencer锁定了),如果允许的话,再看一下这个sequence自身的is_realevant函数,并最终根据算法来决定让哪些sequence发送item。
finish_item方法详解
finish_item方法的全貌
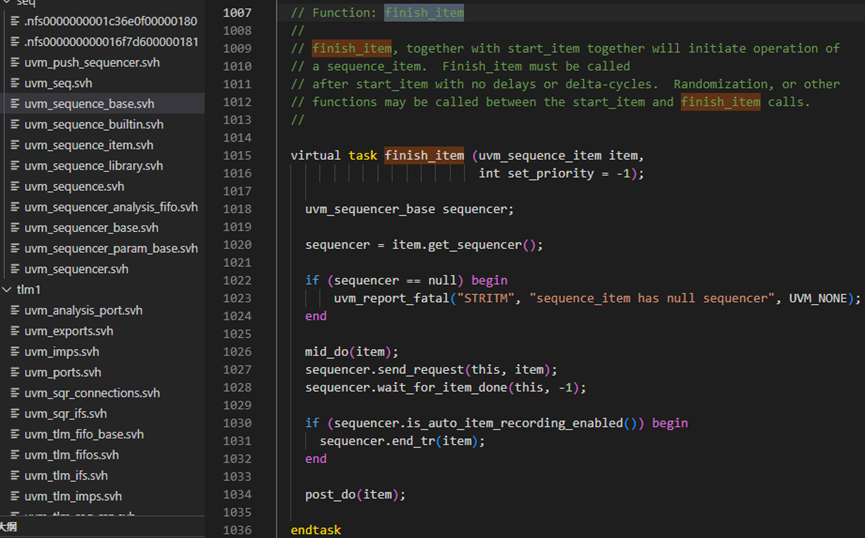
finish_item方法的第1020行,得到此item的sequencer,1026行调用回调函数mid_do。1027行调用send_request方法,这个方法是uvm_sequencer_base中定义的一个函数,具体如下图,send_request方法的273行保证sequence不为null,277行保证wait_for_grant一定要在此函数之前被调用,在介绍wait_for_grant时已经提过这一点。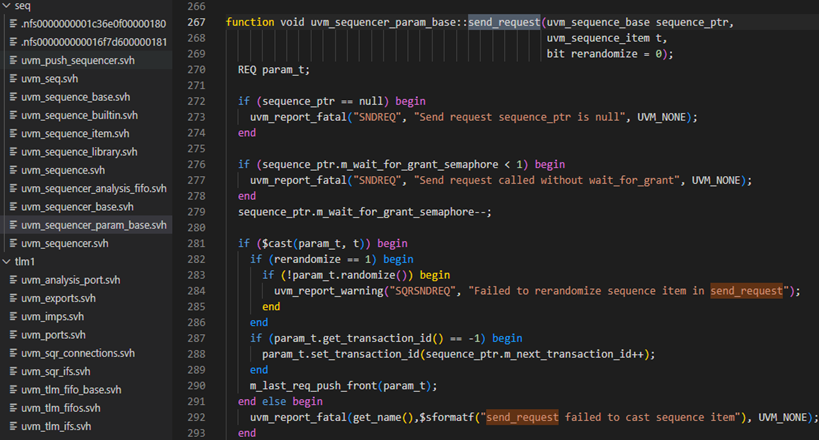
send_request方法中的第281行把要发送的item转换为派生类的指针。因为接下来可能牵扯到随机化。如果只是使用uvm_sequence_item类型的t,那么随机化的是t中的变量,但是对于那些param_t中的成员变量则不能随机化。比如对于下面的定义,如果调用t的randomize,那么a是不会随机化的,因为a不是uvm_sequence_item的成员变量。只有调用param_t的randomize才能让a随机化。
send_request方法接下来在282行根据rerandomize的值来判断是否需要再一次进行随机化。在uvm_do_on_pri_with宏中,在调用finished_item之间已经进行过一次随机化了。
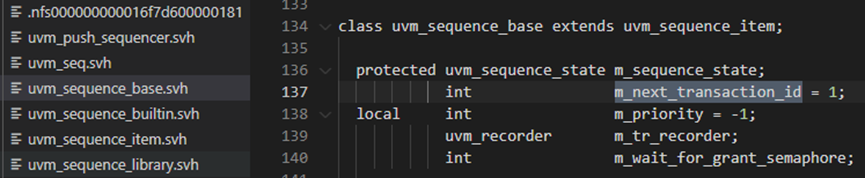
send_request方法接下来在287-289行判断item的transaction_id是否已经设置过了,如果没有设置过,那么就进行设置,288行用到了uvm_sequence_base的m_next_transaction_id变量,这个变量是个int类型的,每当有一个新的item从sequence中产生时,这个变量的值就加1.
send_request方法接下来在290行调用了m_last_req-push_front 方法,这个方法具体如下图,这个方法中的变量定义也如下图所示,可见,在真正的把item发送出去之前,sequence在其m_last_req_buffer中默认保存了最后发送的item。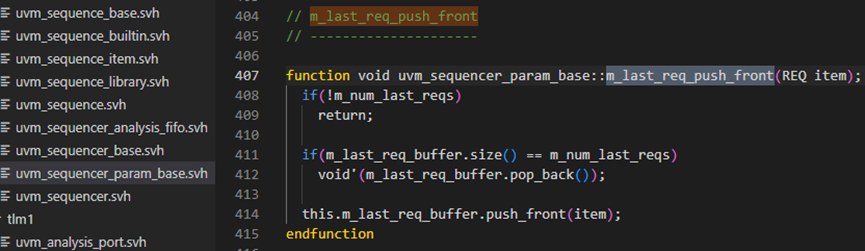

send_request方法接下来第295行把sequence的id信号存放在由此sequence产生的每一个item中。296行把item的sequencer赋值为这个sequence。297行向m_req_fifo中放入要发送的item。还记得uvm_sequencer的get_next_item中会等待m_reg_fifo中有新的item。这里放入item之后,uvm_sequencer的get_next_item将会把这个item取走,交给driver。301行记录共发送了多少个item。303行则再次的调用grant_queued_locks,意思就是尽快的处理arb_sequence_q的请求。到此,send_request分析完毕。
回到finish_item中来,finish_item方法中第1028行调用了wait_for_item_done函数,具体如下图,这个函数第1108-1109行复位了2个变量,1111-1115行根据这2个变量的值来判断driver是否已经调用了item_done函数。要了解这两个变量的具体用法,就要看item_done函数,这是uvm_sequencer中定义的函数。
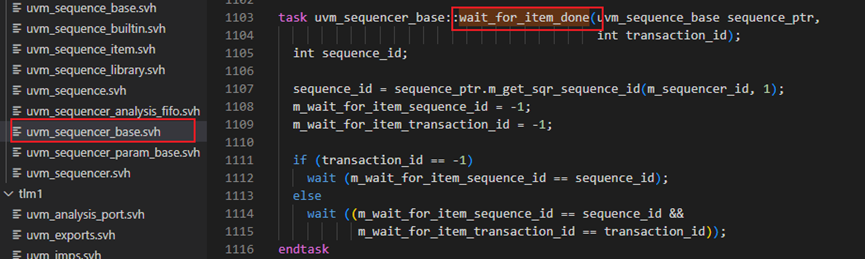
item_done函数具体如下图所示。当一个driver发送完一个item时,会调用seq_item_port的item_done,而这个item_done实际上就是uvm_sequencer的item_done。284行从m_req_fifo中试探着取,看能否取到。这里为什么要这么做?因为288-289行要设置两个变量的值,而这两个变量的值与发送的item直接相关。而在driver中调用item_done时,并没有把发送的item做为参数传递进来,所以这里需要把刚刚driver发送的item再次取出来。item_done有一个输入的参数,这个牵扯到了response机制,后面会仔细介绍。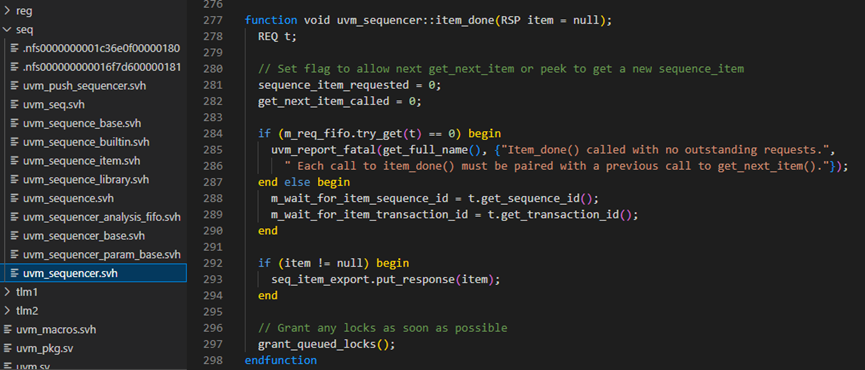
回到wait_for_item_done,当item_done被调用后,那么两个变量的值被设置,于是wait_for_item_done将会直接返回,finish_item的1031行将会调用end_tr函数。这里也不多做介绍。1034行调用回调函数post_do。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)