
Python开发之DataFrame数据的多种遍历方法
主要介绍DataFrame数据的多种遍历方法
一键AI生成摘要,助你高效阅读
问答
·
Python开发之DataFrame数据的多种遍历方法
前言:本博客转载自《DataFrame数据的多种遍历方法》
之前本人博客链接
《Python开发之Pandas的简单使用(一)》
《Python开发之Pandas的简单使用(二)》
《Python开发之处理常见的txt、excel、csv文档》
1 遍历DataFrame的三种方法
- iteritem()方法返回一个<class ‘method’>数据,可利用for循环获得输出
- iterrow()方法返回一个<class ‘generator’>数据,可利用for循环获得输出
- itertuple()方法返回一个<class ‘pandas.core.frame.Pandas’>数据,可利用getattr(row,‘列索引’)方法获得对应数据
演示数据准备:
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2003,2004,2005],
'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
frame = pd.DataFrame(data)
2 按列遍历
column_indexs = []
for column_index, row_data in frame.iteritems():
column_indexs.append(column_index)
print(row_data)
print(column_indexs)
运行结果:

3 按行遍历
3.1 第一种方法
row_indexs = []
for index, row in frame.iterrows():
row_indexs.append(index)
print(row)
print(row_indexs)
运行结果:
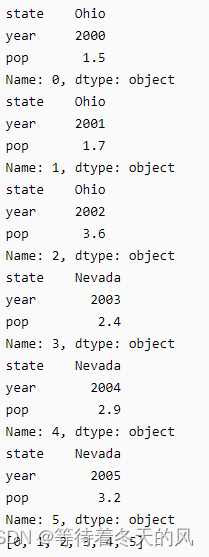
还可以通过列名获取对应数据
for index, row in frame.iterrows():
print(row['pop'])
运行结果:

3.2 第二种方法
for row in frame.itertuples():
print(getattr(row, 'state'), getattr(row, 'year'), getattr(row, 'pop'))
print(type(row))
运行结果:

4 遍历DataFrame某一列(行)数据
演示数据准备
data = {'state':['Ohio','Ohio','Ohio','Nevada','Nevada','Nevada'],
'year':[2000,2001,2002,2003,2004,2005],
'pop':[1.5,1.7,3.6,2.4,2.9,3.2]}
frame = pd.DataFrame(data)
4.1 获取frame的index属性,然后使用frame[列索引].get(行索引)获得对应的值
print(frame.columns)
for index in frame.index:
print(frame['state'].get(index))
运行结果:

与上面等价的两种写法
# 第一种
for index in frame.index:
print(frame['state'][index])
# 第二种
for index in frame.index:
print(frame.get('state').get(index))
4.2 获取frame的column属性,然后使用frame[列索引].get(行索引)获得对应的值
print(frame.index)
for column in frame.columns:
print(frame[column].get(0))
运行结果:

5 获取某一个值
5.1 DataFrame.at[行索引,列索引]获取某一个值

5.2 DataFrame.iat[默认行索引,默认列索引]获取某一个值

5.3 DataFrame.loc[行索引,列索引]获取某个值,与at不同的是,只输入某一参数,获得某一行或某一列
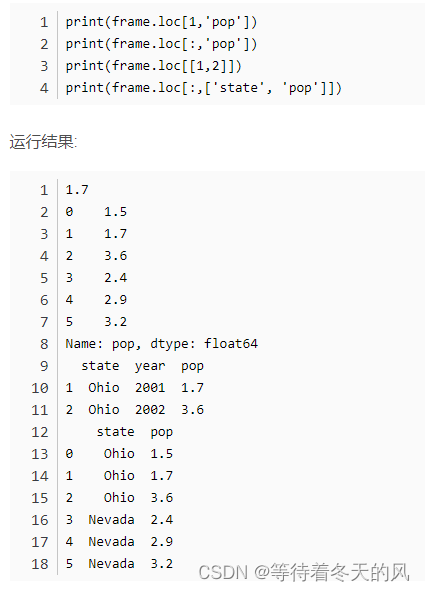
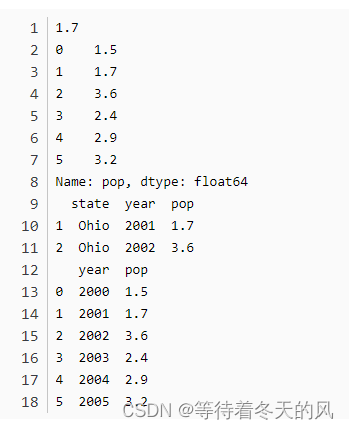
5.4 DataFrame.iloc[默认行索引,默认列索引]获取某个值,与iat不同的是,只输入某一参数,获得某一行或某一列:

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)