ChatGPT 与AI大模型发展简要综述
来源:数据观综合编辑:蒲蒲"日前,美国硅谷的初创公司OpenAI推出了一款新的人工智能对话模型ChatGPT,模型中首次采用RLHF(从人类反馈中强化学习)方式。目前,模型处于测试阶段,用户与ChatGPT之间的对话互动包括普通聊天、信息咨询、撰写诗词作文、修改代码等。功能如此“全面”的ChatGPT被称作“最强AI(人工智能)”,面世5天便已有超过100万用户使用。"ChatGPT为什么这么神?

来源:数据观综合
编辑:蒲蒲
"
日前,美国硅谷的初创公司OpenAI推出了一款新的人工智能对话模型ChatGPT,模型中首次采用RLHF(从人类反馈中强化学习)方式。
目前,模型处于测试阶段,用户与ChatGPT之间的对话互动包括普通聊天、信息咨询、撰写诗词作文、修改代码等。功能如此“全面”的ChatGPT被称作“最强AI(人工智能)”,面世5天便已有超过100万用户使用。
"

ChatGPT为什么这么神?
ChatGPT能够实现当前的交互,离不开OpenAI在AI预训练大模型领域的积累。
OpenAI最初提出的GPT1,采取的是生成式预训练Transform模型(一种采用自注意力机制的深度学习模型),此后整个GPT系列都贯彻了这一谷歌2017年提出,经由OpenAI改造的伟大创新范式。
简要来说,GPT1的方法包含预训练和微调两个阶段,预训练遵循的是语言模型的目标,微调过程遵循的是文本生成任务的目的。
2019年,OpenAI继续提出GPT-2,所适用的任务开始锁定在语言模型。GPT2拥有和GPT1一样的模型结构,但得益于更高的数据质量和更大的数据规模,GPT-2有了惊人的生成能力。不过,其在接受音乐和讲故事等专业领域任务时表现很不好。
2020年的GPT3将GPT模型提升到全新的高度,其训练参数是GPT-2的10倍以上,技术路线上则去掉了初代GPT的微调步骤,直接输入自然语言当作指示,给GPT训练读过文字和句子后可接续问题的能力,同时包含了更为广泛的主题。
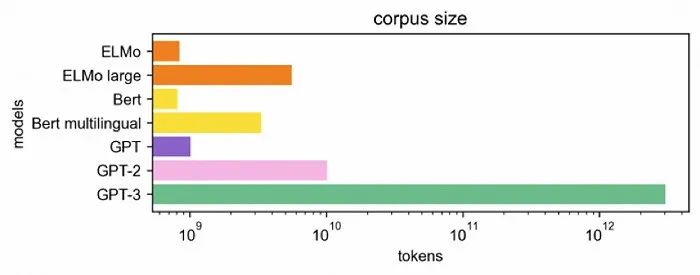 图源:Medium GPT系列模型的数据集训练规模
图源:Medium GPT系列模型的数据集训练规模
现在的ChatGPT则是由效果比GPT3更强大的GPT-3.5系列模型提供支持,这些模型使用微软Azure AI超级计算基础设施上的文本和代码数据进行训练。
具体来说,ChatGPT在一个开源数据集上进行训练,训练参数也是前代GPT3的10倍以上,还多引入了两项功能:人工标注数据和强化学习,相当于拿回了被GPT3去掉的微调步骤,实现了在与人类互动时从反馈中强化学习。
也因此,我们得以看到一个强大的ChatGPT:能理解人类不同指令的含义,会甄别高水准答案,能处理多元化的主题任务,既可以回答用户后续问题,也可以质疑错误问题和拒绝不适当的请求。
当初,GPT-3只能预测给定单词串后面的文字,而ChatGPT可以用更接近人类的思考方式参与用户的查询过程,可以根据上下文和语境,提供恰当的回答,并模拟多种人类情绪和语气,还改掉了GPT-3的回答中看似通顺,但脱离实际的毛病。
 ChatGPT自己回答与前代GPT3的能力区别
ChatGPT自己回答与前代GPT3的能力区别
不仅如此,ChatGPT能参与到更海量的话题中来,更好的进行连续对话,有上佳的模仿能力,具备一定程度的逻辑和常识,在学术圈和科技圈人士看来时常显得博学而专业,而这些都是GPT-3所无法达到的。
尽管目前ChatGPT还存在很多语言模型中常见的局限性和不准确问题,但毋庸置疑的是,其在语言识别、判断和交互层面存在巨大优势。

巨头抢滩AI“大模型”
自2018年以来,国内外超大规模预训练模型参数指标不断创出新高,“大模型”已成为行业巨头发力的一个方向。谷歌、百度、微软等国内外科技巨头纷纷投入大量人力、财力,相继推出各自的巨量模型。
国外的超大规模预训练模型起步于2018年,2021年进入“军备竞赛”阶段。
2018年,谷歌提出3亿参数BERT模型,惊艳四座,由此大规模预训练模型开始逐渐走进人们的视野,成为人工智能领域的一大焦点。
2019年2月,OpenAI推出了15亿参数的GPT-2,能够生成连贯的文本段落,做到初步的阅读理解、机器翻译等。
紧接着,英伟达推出了83亿参数的Megatron-LM,谷歌推出了110亿参数的T5,微软推出了170亿参数的图灵Turing-NLG。
2020年6月,大模型迎来了一个分水岭,OpenAI以1750亿参数的GPT-3,直接将参数规模提高到千亿级别。而作诗、聊天、生成代码等无所不能。
之后,微软和英伟达在2020年10月联手发布了5300亿参数的Megatron-Turing自然语言生成模型(MT-NLG)。
2021 年 1 月,谷歌推出的Switch Transformer模型以高达1.6 万亿的参数量打破了GPT-3作为最大AI模型的统治地位,成为史上首个万亿级语言模型。
2021年,12月,谷歌还提出了1.2万亿参数的通用稀疏语言模型GLaM,在7项小样本学习领域的性能超过GPT-3。
国内,超大模型研发厚积薄发,充分展示了中国企业的技术实力和应用需求。
2021年是中国超大规模AI模型的爆发年。在国内超大模型研发比国外公司晚,但是发展却异常的迅速。
4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。
阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6。
6 月,北京智源人工智能研究院发布了超大规模智能模型“悟道 2.0”,参数达到 1.75 万亿,成为当时全球最大的预训练模型。
7月,百度推出ERNIE 3.0 知识增强大模型,参数规模达到百亿。10月,浪潮发布约2500亿的超大规模预训练模型“源1.0”。
12月,百度推出ERNIE 3.0 Titan模型,参数规模达2600亿。而达摩院的M6模型参数达到10万亿,将大模型参数直接提升了一个量级。
到今年,大模型继续火热。最开始,大模型是集中在计算语言领域,但如今也已逐渐拓展到视觉、决策,应用甚至覆盖蛋白质预测、航天等等重大科学问题,谷歌、Meta、百度等等大厂都有相应的成果。一时间,参数量低于 1 亿的 AI 模型已经没有声量。
有研究实验表明,数据量与参数量的增大能够有效提升模型解决问题的精确度。以谷歌2021年发布的视觉迁移模型 Big Transfer 为例,分别使用 1000 个类别的 128 万张图片和 18291 个类别的 3 亿张图片两个数据集进行训练,模型的精度能够从 77% 提升到 79%。
简而言之,大模型往往具备一个特征:多才多艺,身兼多职。这对解决复杂场景的挑战至关重要。

规模就是一切?
近年来,大型语言模型的参数数量保持着指数增长势头。据预测,OpenAI开发中的最新大型语言模型GPT-4将包含约100万亿的参数,与人脑的突触在同一数量级。由此,出现了一个新的人工智能口号:“规模就是一切”。
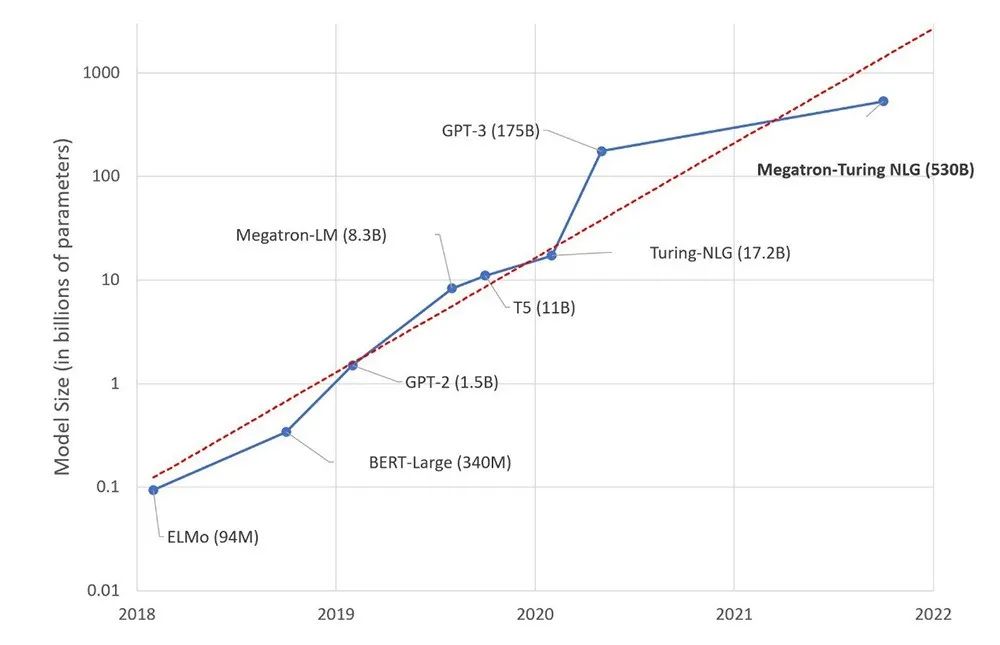 图片来源:https://huggingface.co/blog/large-language-models
图片来源:https://huggingface.co/blog/large-language-models
更大的模型带来了更高的训练成本。这既包括智力支出和经济成本,也有不可忽视的环境影响。马萨诸塞大学阿姆赫斯特分校的一项研究指出,仅是训练参数数量不到最新模型1%的BERT模型,就会造成652千克的碳排放,可与跨越美国东西海岸的一次航班所造成的碳排放相比拟。
与此同时,越来越大的模型所带来的效用提升正在缩小。人们发现,模型参数规模增长10倍,得到的性能提升往往不到10个百分点。相比直线,倒是那些同等(乃至更小)参数规模的新模型,会带来真正质的提升。还有一些研究者尝试把大模型拆分成更多小模型并集之所长,但由于其模型参数并不会全部加入计算,“这是否会是参数量狂热之下的一种数字泡沫”的质疑也随之而来。
而且,随着大型语言模型的广泛应用,一些负面的社会效应也开始显现。据预测,到2023年,约有5%的大学生会使用大型语言模型生成的文本来代替本应由他们自己撰写的作业,而与之对抗的检测手段则很难真正发挥作用。
就在上月,Meta公司发布了一个名为Galactica的大型语言模型,宣称它“可以总结学术论文,解决数学问题,生成维基百科文章,编写科学代码,标记分子和蛋白质,以及更多功能。”
但上线仅3天,该模型就在巨大争议中撤回。它虽然能生成一些貌似通顺的学术文本,但文本中的信息是完全错误的——貌似合理的化学方程,描述的是实际上并不会发生的化学反应;格式合规的引文参考的是子虚乌有的文献;甚而种族主义、性别歧视的观点,也能通过模型生成的文本而被包装成“科学研究”。批评者质疑,这样的模型会使学术造假变得更为隐蔽,也将使科学谣言的散播变得更加便利。
一般的观点认为,尽管人工智能系统能在诸多特定任务中显现出看似智能的行为,但它们并不像人那样理解它们所处理的数据。譬如,Character.ai、ChatGPT这样的模型应用虽然已能流畅地与人进行“对话”,而且相当程度上顾及到上下文,然而,人工智能系统中无法预测的错误、对于一般情况推广能力的欠缺等都被视为它们无法“理解”的证据。这样的大型语言模型并未真正“理解”语言所描述的现实世界。

AI大模型将往哪儿走?
在预训练大模型发展中,面临最大问题是什么,未来的发展方向又在哪儿呢?
阿里达摩院在发布的报告里认为,未来大模型的参数规模发展将进入冷静期,大模型与相关联的小模型协同将是未来的发展方向。
其中,大模型沉淀的知识与认知推理能力向小模型输出,小模型基于大模型的基础叠加垂直场景的感知、认知、决策、执行能力,再将执行与学习的结果反馈给大模型,让大模型的知识与能力持续进化,形成一套有机循环的智能系统。参与者越多,模型进化的速度也越快。
阿里达摩院预测,在未来的三年内,个别领域将以大规模预训练模型为基础,对协同进化的智能系统进行试点探索。
在未来的五年内,协同进化的智能系统将成为体系标准,让全社会能够容易地获取并贡献智能系统的能力,向通用人工智能再迈进一步。
百度研究院发布2022年十大科技趋势预测认为,备受业界关注的超大规模预训练模型,将呈现知识增强、跨模态统一建模、多学习方式共同演进的趋势,并逐渐实用化,破除盲目增加参数规模的“军备竞赛”。
预计2022年,大模型研发方向将转向“实用化”,大模型的效果、通用性、泛化性、可解释性和运行效率将持续提升,应用门槛不断降低,在多场景广泛落地。
相对而言,大量研究在预训练模型的落地能力上将持续努力,压缩、剪枝、蒸馏的工作仍起到重要作用。不止于算法本身,编译、引擎、硬件等方面的优化也在大步迈进。
整体而言,现在大规模预训练模型的研究,包括模型结构的演进和落地仍处在探索阶段,各家的持续探索正在不断扩大对大规模预训练模型的认知边界。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 3
3 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)