MindSpore平台的体验与部署
随着人工智能的不断发展,国内外的ai平台越来越多,今天就来体验一下华为旗下的国产ai平台,昇思(MindSpore)。本文对mindspore框架的部署以及会遇到的问题进行了简单的介绍,同时通过运行官网介绍的例子初步体验了昇思框架的优越性。总的来说,在安装方面依旧有着部分的兼容问题,但是可以通过pip解决。而MindSpore的优点则是较高的性能与对用户友好。在实际运行阶段,快速完成了对模型的训练
第一章 MindSpore框架的体验与部署
目录
MindSpore系列第一篇
前言
随着人工智能的不断发展,国内外的ai平台越来越多,今天就来体验一下华为旗下的国产ai平台,昇思(MindSpore)。
一、昇思是什么
MindSpore是由华为于2019年8月推出的新一代全场景AI计算框架,2020年3月28日,华为宣布MindSpore正式开源。昇思作为新一代ai框架有着自己得天独厚的优势。
二、使用步骤
1.在anaconda上部署MindSpore
在昇思官网安装指导页面获取自己对应的安装代码。这里,笔者使用的是Windows系统的anaconda环境,使用gpu进行运算。读者可以根据自己的机器环境进行配置。

在这里我们使用,anaconda navigator新建一个新的虚拟环境。
在新的环境的python环境下,输入刚才复制的代码。
出现问题,报错显示
让我们跟着教程重新安装一遍环境,依旧失败。
百度一下,发现是安装源的问题。
几经周折,数次调整后依旧无法安装,可能是清华源的问题。
最终选择使用pip安装。
成功安装并验证
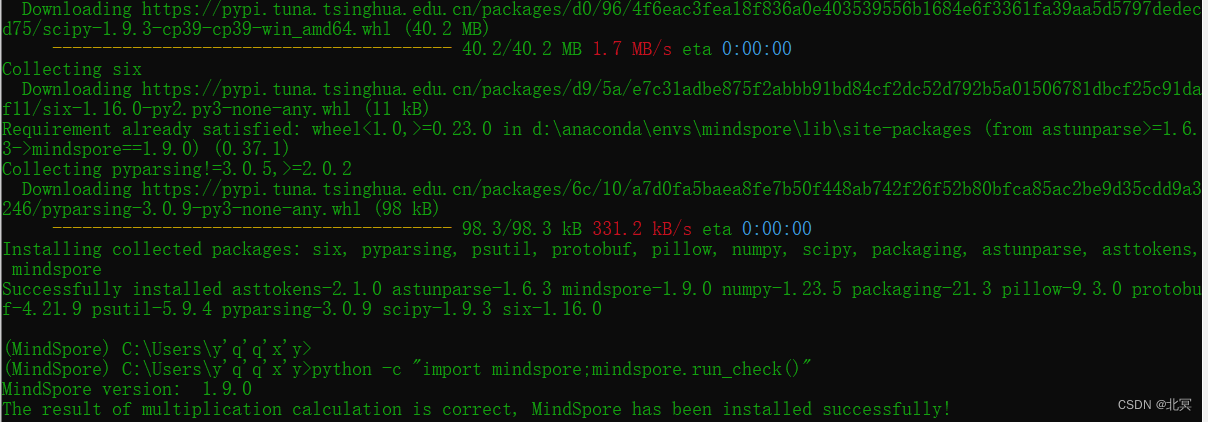
pip代码如下:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.9.0/MindSpore/cpu/x86_64/mindspore-1.9.0-cp39-cp39-win_amd64.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple2.简单体验昇思框架
继续在navigator中,选择安装notebook

安装完成后打开notebook

简单运行官方的代码样例
import mindspore
from mindspore import nn
from mindspore import ops
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset导入成功
继续运行,下载数据集。
from download import download url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \ "notebook/datasets/MNIST_Data.zip" path = download(url, "./", kind="zip", replace=True)出现报错
--------------------------------------------------------------------------- ModuleNotFoundError Traceback (most recent call last) Cell In [2], line 1 ----> 1 from download import download 3 url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \ 4 "notebook/datasets/MNIST_Data.zip" 5 path = download(url, "./", kind="zip", replace=True) ModuleNotFoundError: No module named 'download'使用pip安装download模块
pip install download安装失败
选择conda,找不到对应的模块。
最终选择手动下载
https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip
移动到笔记本对应的个人文件夹目录并解压
成功跳过下载并运行下面的代码
train_dataset = MnistDataset('MNIST_Data/train') test_dataset = MnistDataset('MNIST_Data/test') print(train_dataset.get_col_names())def datapipe(dataset, batch_size): image_transforms = [ vision.Rescale(1.0 / 255.0, 0), vision.Normalize(mean=(0.1307,), std=(0.3081,)), vision.HWC2CHW() ] label_transform = transforms.TypeCast(mindspore.int32) dataset = dataset.map(image_transforms, 'image') dataset = dataset.map(label_transform, 'label') dataset = dataset.batch(batch_size) return datasettrain_dataset = datapipe(train_dataset, 64) test_dataset = datapipe(test_dataset, 64)for image, label in test_dataset.create_tuple_iterator(): print(f"Shape of image [N, C, H, W]: {image.shape} {image.dtype}") print(f"Shape of label: {label.shape} {label.dtype}") breakfor data in test_dataset.create_dict_iterator(): print(f"Shape of image [N, C, H, W]: {data['image'].shape} {data['image'].dtype}") print(f"Shape of label: {data['label'].shape} {data['label'].dtype}") break# Define model class Network(nn.Cell): def __init__(self): super().__init__() self.flatten = nn.Flatten() self.dense_relu_sequential = nn.SequentialCell( nn.Dense(28*28, 512), nn.ReLU(), nn.Dense(512, 512), nn.ReLU(), nn.Dense(512, 10) ) def construct(self, x): x = self.flatten(x) logits = self.dense_relu_sequential(x) return logits model = Network() print(model)Network< (flatten): Flatten<> (dense_relu_sequential): SequentialCell< (0): Dense<input_channels=784, output_channels=512, has_bias=True> (1): ReLU<> (2): Dense<input_channels=512, output_channels=512, has_bias=True> (3): ReLU<> (4): Dense<input_channels=512, output_channels=10, has_bias=True> > >定义损失函数与优化器
loss_fn = nn.CrossEntropyLoss() optimizer = nn.SGD(model.trainable_params(), 1e-2)定义训练函数:
def train(model, dataset, loss_fn, optimizer): # Define forward function def forward_fn(data, label): logits = model(data) loss = loss_fn(logits, label) return loss, logits # Get gradient function grad_fn = ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True) # Define function of one-step training def train_step(data, label): (loss, _), grads = grad_fn(data, label) loss = ops.depend(loss, optimizer(grads)) return loss size = dataset.get_dataset_size() model.set_train() for batch, (data, label) in enumerate(dataset.create_tuple_iterator()): loss = train_step(data, label) if batch % 100 == 0: loss, current = loss.asnumpy(), batch print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")定义测试函数,评估性能
def test(model, dataset, loss_fn): num_batches = dataset.get_dataset_size() model.set_train(False) total, test_loss, correct = 0, 0, 0 for data, label in dataset.create_tuple_iterator(): pred = model(data) total += len(data) test_loss += loss_fn(pred, label).asnumpy() correct += (pred.argmax(1) == label).asnumpy().sum() test_loss /= num_batches correct /= total print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")最终运行模型:
epochs = 3 for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(model, train_dataset, loss_fn, optimizer) test(model, test_dataset, loss_fn) print("Done!")Epoch 1 ------------------------------- loss: 2.303244 [ 0/938] loss: 2.285310 [100/938] loss: 2.254808 [200/938] loss: 2.173993 [300/938] loss: 1.815277 [400/938] loss: 1.376053 [500/938] loss: 1.102494 [600/938] loss: 0.804129 [700/938] loss: 0.569727 [800/938] loss: 0.633577 [900/938] Test: Accuracy: 83.7%, Avg loss: 0.537655 Epoch 2 ------------------------------- loss: 0.456971 [ 0/938] loss: 0.687430 [100/938] loss: 0.434879 [200/938] loss: 0.502015 [300/938] loss: 0.356903 [400/938] loss: 0.405563 [500/938] loss: 0.350419 [600/938] loss: 0.280745 [700/938] loss: 0.249667 [800/938] loss: 0.418286 [900/938] Test: Accuracy: 90.2%, Avg loss: 0.336636 Epoch 3 ------------------------------- loss: 0.382209 [ 0/938] loss: 0.376853 [100/938] loss: 0.325569 [200/938] loss: 0.358031 [300/938] loss: 0.303792 [400/938] loss: 0.420408 [500/938] loss: 0.470213 [600/938] loss: 0.286934 [700/938] loss: 0.188889 [800/938] loss: 0.246530 [900/938] Test: Accuracy: 91.9%, Avg loss: 0.281553 Done!
总结
本文对mindspore框架的部署以及会遇到的问题进行了简单的介绍,同时通过运行官网介绍的例子初步体验了昇思框架的优越性。
总的来说,在安装方面依旧有着部分的兼容问题,但是可以通过pip解决。而MindSpore的优点则是较高的性能与对用户友好。在实际运行阶段,快速完成了对模型的训练。将来还期望能够进一步体验它的多层api、与昇腾计算的高效联动、动态图和静态图统一的编码方式等其他优点。
作为一款国产机器学习框架,昇思未来十分光明。
更多推荐




 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)