
Linux系统上C语言程序编写与调试
目录
3.2、预处理:gcc -E main.c -o main.i
3.3、编译:gcc -S main.i -o main.s
3.4、汇编:gcc -c main.s -o main.o
3.5、链接:gcc 所有需要被链接的目标.o文件 -o main
4、一步编译执行:gcc -o 可执行文件名 所有依赖的源文件
5、make命令及makefile文件编写——管理工程实现自动化编译
6.1、生成Debug可调试版本:gcc -o 可执行文件名 源文件 -g
1、可执行文件(程序)
我们编写代码的目的就是最终要能运行我们的代码,去完成某些操作。要想使代码运行起来,就要让代码文件变成一个可执行的文件(程序)。所以我们要先了解一下什么是可执行文件。
可执行文件:在Windows操作系统中,扩展名为:*.exe,*bat等的文件是可执行文件,可执行文件由指令和数据构成。Linux是靠文件属性来判断是否可执行。
但是,可执行程序不是仅仅在Windows中将文件后缀名修改为.exe或在Linux中将文件属性添加上x就变成一个可执行文件了。
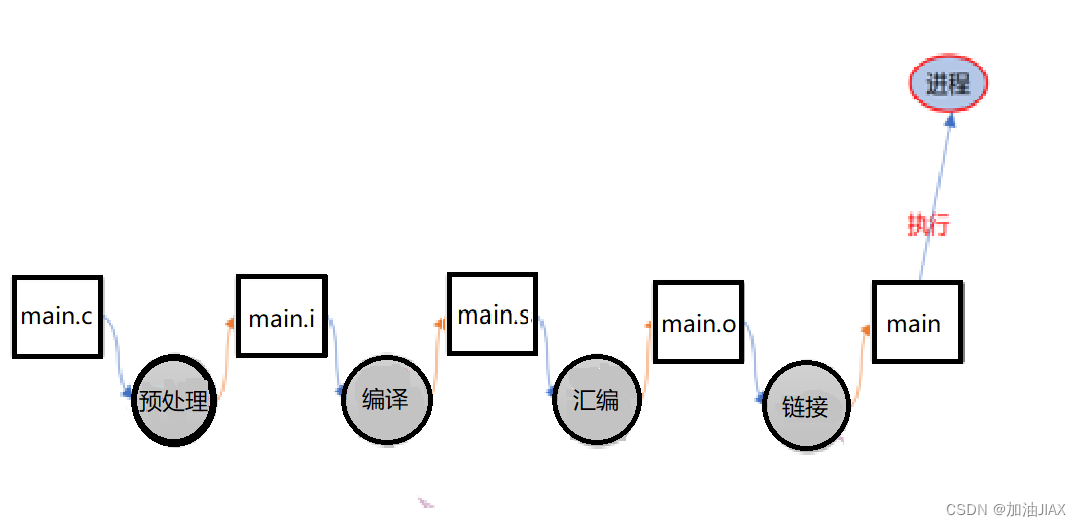
众所周知,计算机只认识机器码,也就是01二进制,而我们所用C/C++属于高级语言,计算机不能直接识别、运行。从C代码程序文件变成一个计算机可直接运行的文件,这其中需要经历预处理、编译、汇编、链接的重要过程,并不止是在编程软件上点一下编译、点一下运行就好了。
2、程序的编译链接过程
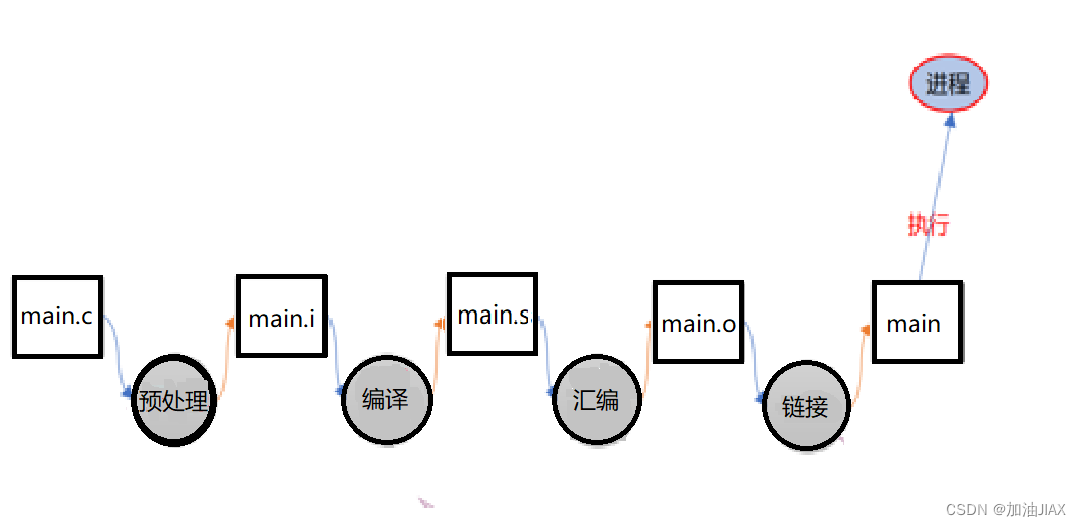
C程序编译链接的过程无论是在Windows上还是Linux上,都是一样的,只不过文件后缀不同,如经汇编后的机器码文件,也就是目标文件,在Linux上的后缀为.o,Windows上的后缀为.obj,还有可执行文件等。
注意:Windows系统以文件后缀名区分文件类别,Linux系统以文件属性区分文件。在Linux系统上文件代码文件有后缀,只是因为C编译器需要以后缀名来判断其是否是C语言程序(Linux常用命令-2.3.2普通文件)。
2.1、预处理阶段
主要工作是将头文件插入到所写的代码中,生成扩展名为“.i”的文件替换原来的扩展名为“.c”的文件,但是原来的文件仍然保留,只是执行过程中的实际文件发生了改变。此外,还有如下操作:
a) 删除所有的“#define”,并且展开所有的宏定义;
b) 处理所有的条件预编译指令,“#if”、“#ifdef”、“#endif”等;
c) 处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置;
d) 删除所有的注释;
e) 添加行号和文件名标识,以便于编译器产生调试用的符号信息及编译时产生编译错误和警告时显示行号;
f) 保留所有的#pragma 编译器指令,因为编译器需要使用它们。
2.2、编译阶段
主要工作是将 .i 文件中的代码翻译成特定汇编语言。
编译器首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作(词法分析、语法分析、语义分析),在检查无误后,编译器把代码翻译成汇编语言,同时将扩展名为“.i”的文件翻译成扩展名为“.s”的文件。
2.3、汇编阶段
主要工作:将上一步的汇编代码转换成机器码(machine code),这一步产生的文件叫做目标文件.o文件,是二进制格式。
2.4、链接阶段
主要工作:链接过程将多个目标文件以及所需的库文件(.so等)链接成最终的可执行文件。在项目中,我们编写的代码文件不止一个,所以需要将最终可执行程序依赖的所有目标文件进行链接。
3、在gcc编译器上进行程序编译运行实操
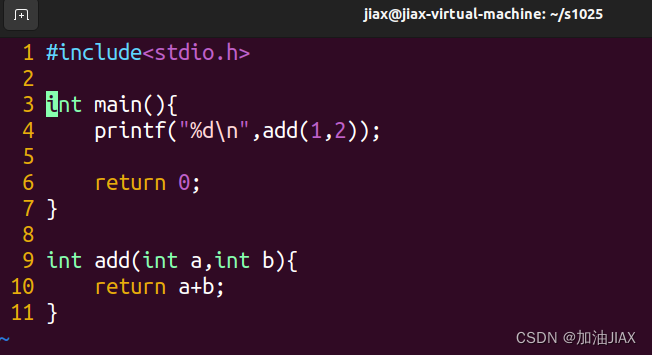
示例C程序文件:
main.c:此时add函数定义在main函数之后,且前方无声明,有错。
3.1、gcc安装
命令:sudo apt install gcc。若失败,先sudo apt-get install update,在sudo apt install gcc。
3.2、预处理:gcc -E main.c -o main.i

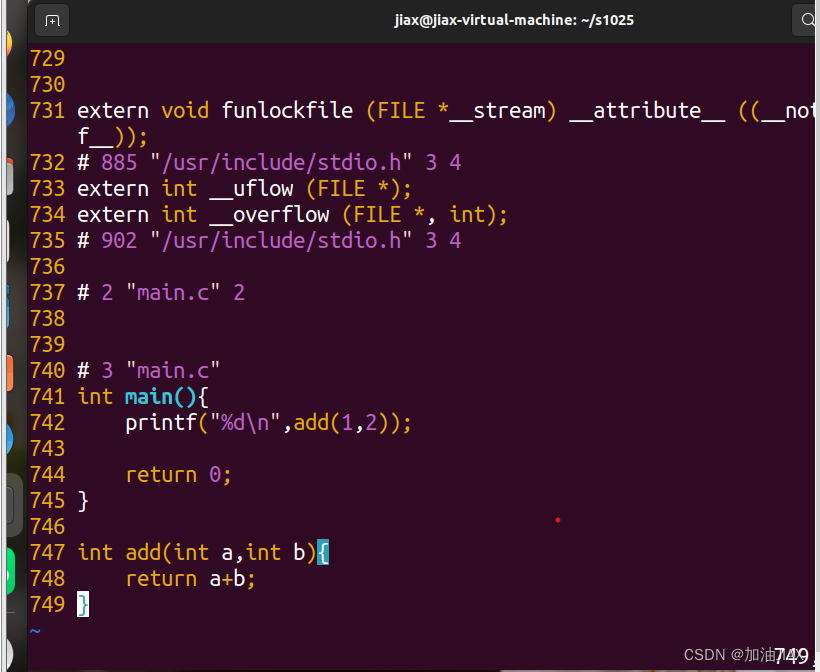
在执行完 gcc -E main.c -o main.i 命令后,系统将main.c文件进行预处理,未对代码是否正确进行检测,生成main.i文件。完成了对头文件stdio.h的插入。此时若查看main.i文件就会发现其中多出了几百行内容,就是因为插入了头文件stdio.h的内容。
3.3、编译:gcc -S main.i -o main.s
此时,系统对main.i中的代码进行编译,检查其是否出错。若无错,则将代码编译成汇编语言代码,生成main.s文件;若有错,则警告。
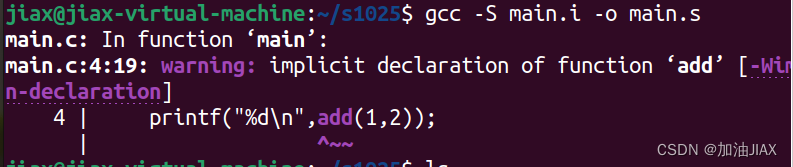
根据警告,对代码进行改错,再从头开始进行预处理、编译后,成功生成main.s文件。

并且,对main.s文件进行查看,发现其内容为汇编代码。
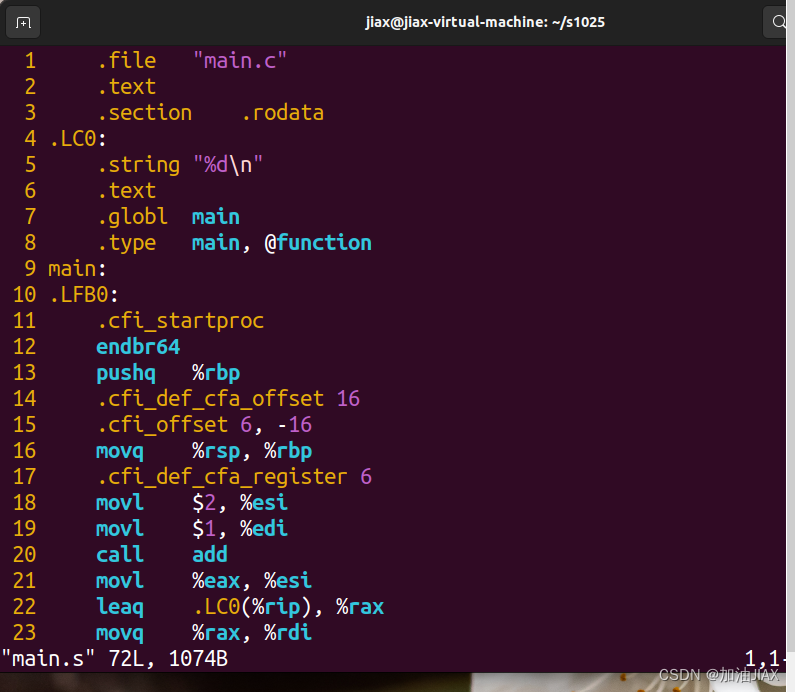
3.4、汇编:gcc -c main.s -o main.o
1、注意,此时 -c 是小写,若为大写 -C,并且因为main.c是一个有完整功能的程序文件,此时其不需要进行链接,其生成的目标二进制文件main.o就是可执行的。并且当前可执行的main.o不能再被链接。
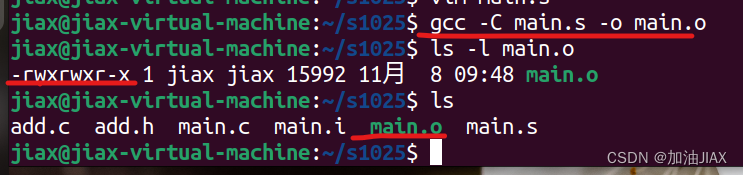
此时,系统将汇编语言文件main.s汇编成目标二进制文件main.o,此时main.o已具有可执行权限x。
执行:命令:./main.o。代码执行1+2的结果为3。

2、gcc -c main.s -o main.o
此时生成的main.o文件是不可以直接执行的,不具有x权限。

此时,若查看main.o文件的内容,会发现其内容不能被vi/vim编辑器解析。
3.5、链接:gcc 所有需要被链接的目标.o文件 -o main
若还有其他需要被链接的文件,则那些文件都要经过上述操作,生成.o文件,再在链接过程最终链接成为一个整体的可执行文件;若没有,就只链接一个文件就行。

3.6、执行可执行程序
可执行程序的执行与命令一样(命令就是系统自带的可执行程序)。只不过常用命令在系统/bin目录下存放着,可以直接在终端输入命令就可以执行;我们生成的可执行程序在我们当前所在的目录下,如果我们要执行生成的可执行程序就要使用 ./可执行程序名 格式进行执行。目的是告诉系统该可执行程序在当前目录下。如:

如果我们想要像命令一般执行 main 可执行程序,可以将 main可执行程序 移动到 /bin 目录下,这样就可以和命令一样使用main。但需要注意,main可执行程序就不可以和 /bin 目录下的命令同名,不然会导致出错。

4、一步编译执行:gcc -o 可执行文件名 所有依赖的源文件
测试文件:
add.h:

add.c:
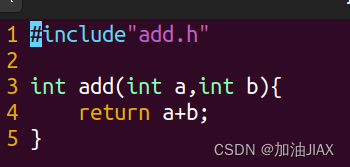
main.c:
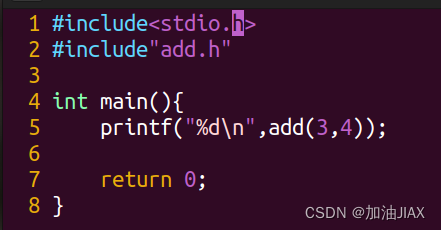
上述过程比较复杂,所以系统还提供了将所有最终可执行程序依赖的源文件进行预处理、编译、汇编、链接的一步方法。只需在 gcc -o 可执行文件名 命令后添加上所有依赖的源文件就可以了。如:
使用命令:gcc -o main main.c add.c 。
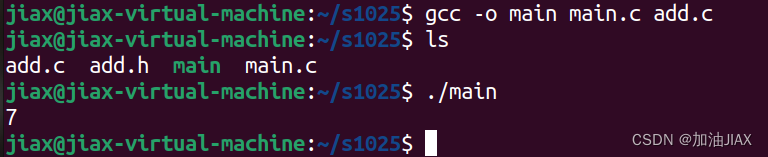
5、make命令及makefile文件编写——管理工程实现自动化编译
安装make命令:sudo apt install make。
对于较大的项目或工程中,最后生成的可执行文件依赖的源文件特别多的话,也可以选择使用编写makefile文件的方式,对所有源文件进行自动编译。
测试文件:
add.c:
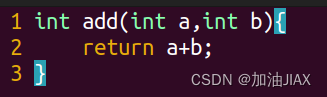
mul.c:
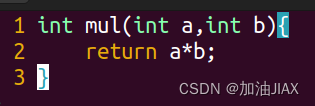
main.c:
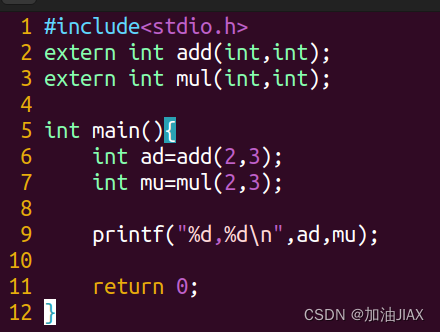
makefile文件,其格式如下:
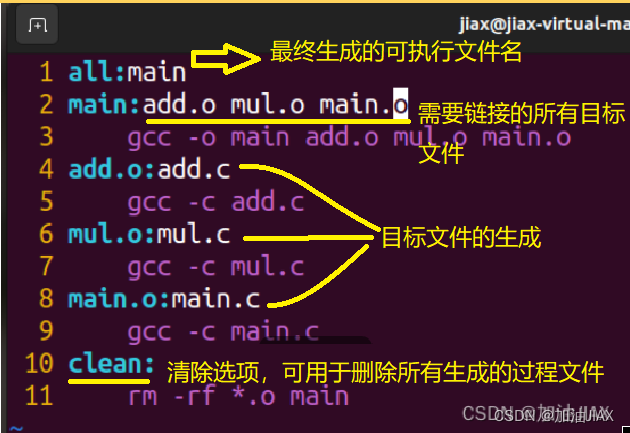
注意:在gcc代码行的缩进需要使用Tab来实现,使用四个空格键是不行的。
make命令的使用:在安装好make命令和编写好makefile文件后,直接在终端使用make命令,就可以对所有源文件进行编译链接,得到最终的可执行文件。
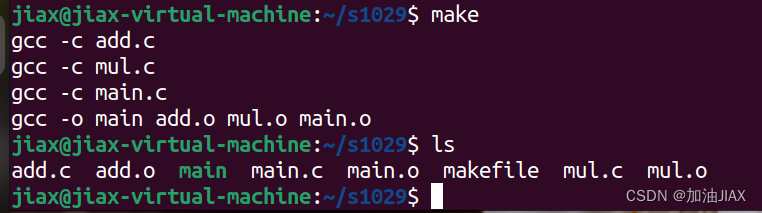
此时,main就是最终的可执行文件。
clean的使用命令:make clean。
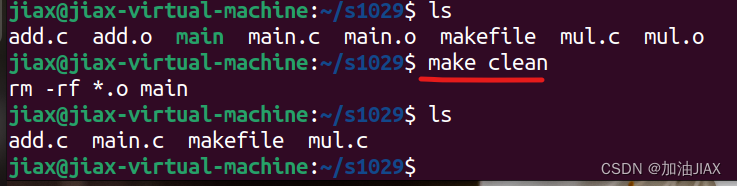
6、gdb代码调试
安装命令:sudo apt install gdb。
可执行程序分为Debug版本和Release版本两种,如vs上:
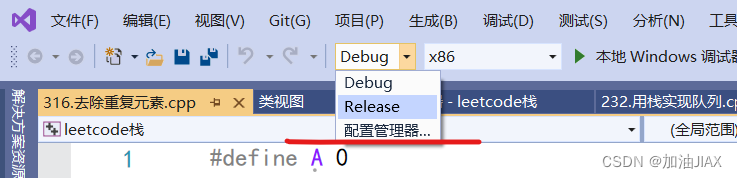
Debug版本:
Debug版本为可调试版本,生成的可执行文件中包含调试需要的信息,我们作为开发人员,最常用的就是debug版本的可执行文件。
Debug 版本的生成: 因为调试信息是在编译过程时加入到中间文件(.o)中的,所以必须在编译时控制其生成包含调试信息的中间文件。
gcc -c hello.c -g ---> 生成包含调试信息的中间文件
gcc -o hello hello.o
或者gcc -o hello hello.c -g
Release 版本:
Release版本为发行版本,是提供给用户使用的版本。用 gcc 默认生成的就是 Release 版本。
首先将源代码编译、链接生成 Debug 版本的可执行文件,然后通过‘gdb Debug版本的可执行文件名’进入调试模式。
测试文件:
ps.c:程序目标为循环从键盘输入字符串,若字符串与"end"相等,则退出循环。
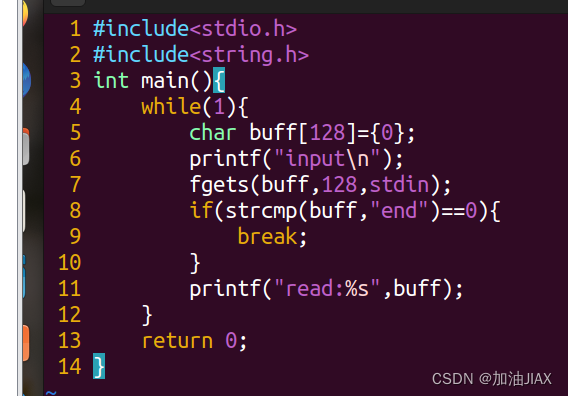
6.1、生成Debug可调试版本:gcc -o 可执行文件名 源文件 -g

6.2、进入程序调试:gdb Debug版可执行文件名
例如,使用 gdb ps 命令,进入ps程序调试:
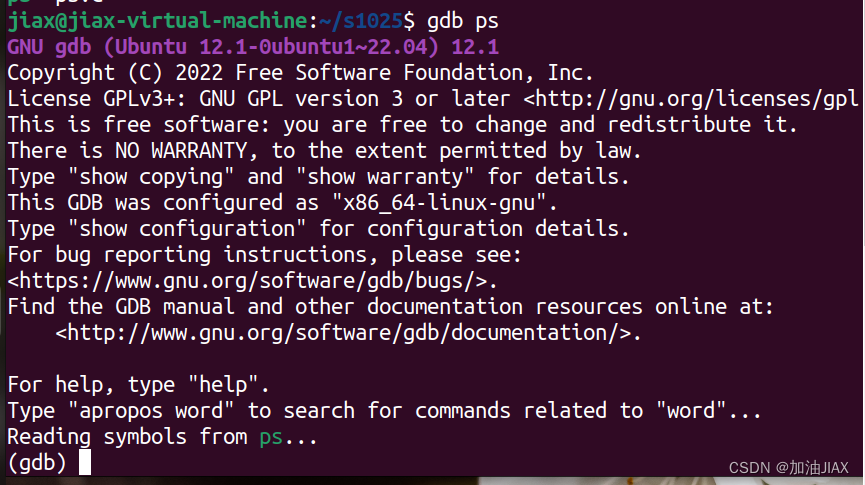
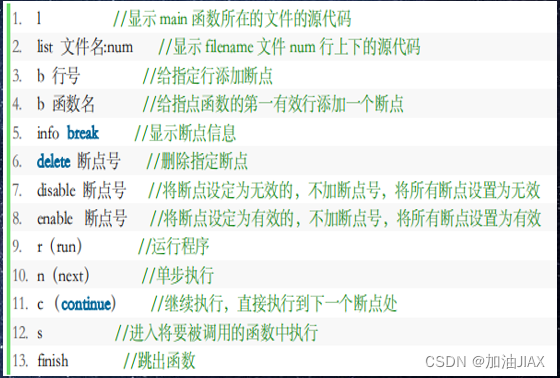
此时,就进入了程序的调试阶段,系统等待调试命令的下达。常用命令如下:

6.3、下断点:b 目标代码行号
例如,此时我们在程序第五行打断点,就使用命令 b 5。

6.4、从断点处开始运行调试与运行:r、n
使用 r 命令后,从程序断点处开始运行调试,并使用 n 命令一步步向下执行。
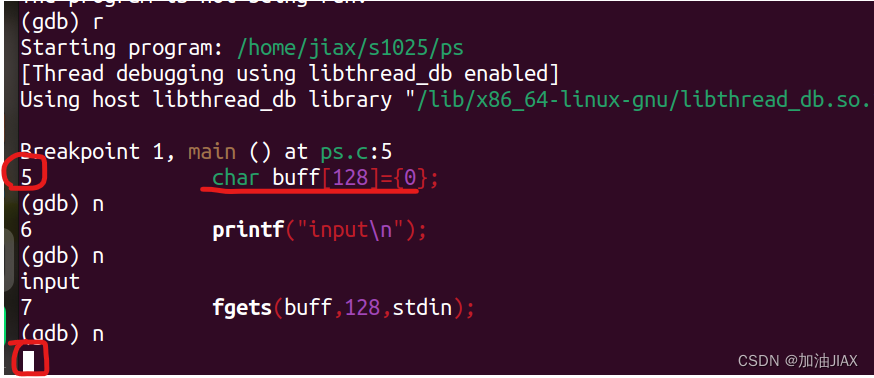
在程序调试过程中,程序显示正在运行的每一行的行号与代码内容。在执行到需要输入的代码时,光标闪烁,等待输入。
6.5、打印数组内容:p 数组名

在输入"end"字符串后,发现程序仍然向下执行,并未break跳出循环,这就发现了程序的漏洞。就可以使用 p buff 命令,查看buff数组保存的我们输入的字符串到底是不是"end"。

此时发现,buff数组将我们输入的回车也接收进去了,怪不得strcmp(buff,"end")不等于0。
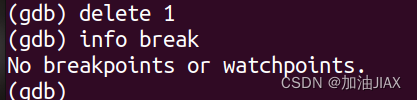
6.6、查看断点信息:info break
在达成目的后,我们就需要删除断点,而断点的删除需要使用到断点号,若不记得断点号了,就可以使用 info break 命令,查看断点信息,其中就有断点号。

6.7、删除断点:delete 断点号
此时,程序中只有一个断点,且断点号为1,就可以使用 delete 1 命令删除该断点。
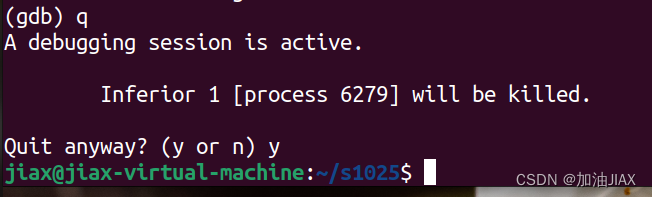
6.8、退出调试:q
在调试结束,就可以使用 q 命令退出调试。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)