Kubernetes 将应用迁移至kubernetes
之前是要将应用迁移到k8s平台上面的时候,第一步做的就是应用容器化,做应用容器化的时候要对操作系统的一些资源做对接的时候所面临的挑战。完成了容器化之后面临的挑战就是要将应用迁移到k8s平台,这个时候考虑的问题就更加多了。下面就是如何将应用迁移到k8s平台上面去。

之前是要将应用迁移到k8s平台上面的时候,第一步做的就是应用容器化,做应用容器化的时候要对操作系统的一些资源做对接的时候所面临的挑战。
完成了容器化之后面临的挑战就是要将应用迁移到k8s平台,这个时候考虑的问题就更加多了。
下面就是如何将应用迁移到k8s平台上面去。
pod spec

在主应用拉起之前可能需要做一系列初始化的动作,应用和应用之间是互相通信是基于jwt token的,就是要获取token来证明我是谁,当a应用访问b应用的时候,a应用要带着它颁发好的token去访问b应用,然后b应用会去校验这个token是不是有效的token。token代表的应用是谁,它有没有这样的权限,这样就能够完成应用之间微服务调用的一个权限控制。
所以token是在应用启动的时候一次性获取的。这就是initcontainer来完成的工作,通过主container和init container之间共享同样的一个volume。
在定义容器的时候就需要去想有哪些初始化的动作是一次性的,之后就可以看是否可以将初始化动作一次性的放到initcontainer里面去。
初始化从container可以有很多,是一个list,自上而下顺序执行。
然后应用启动的时候要几个主container。
容器运行的时候需要什么权限,比如要去动操作系统上面的权限。还有可能去配置容器网络的权限。
一个pod内有多个容器,那么彼此之间要去做通信,天然网络的namespace就是共享的,容器a和容器b之间直接就可以进行网络调用,但是很多namespace是不共享的,比如pid,它们的进程彼此是隔离的,你要a容器里面进程去控制b容器里面的进程,那么就是要share pid。所以要去规划哪些namespace是需要共享的,这些都可以通过pod spec来控制。
应用代码和配置是要分离的,这个配置是从secret还是configmap来,这些配置信息拿到之后然后通过什么样的方式来挂到容器内部,通过环境变量还是文件方式让容器的进程可以消费。
服务部署在集群内部,是要给集群内部提供服务还是集群外部提供服务,是依赖于集群内部还是集群外部,如果对集群内部的服务没有诉求,那我我的dns policy就不需要设置为cluster first,就不需要去连接coredns,就不需要给它额外的压力,就可以设置为default,让它直接使用主机的配置去查询,这样减少对dns的压力。
镜像拉取的策略是什么?这些都要思考。
Probe误用会造成严重后果

有个pod设置了探活的,每隔10s钟去探测我的应用是不是活着的,它通过执行本的的脚本去运行的,这个脚本的命令是通过curl命令去访问一下endpoint,然后看其是否能够正常的返回返回码,并且返回的body里面有我们期望的数据。
如果一切正常就认为是ok的,这里设置了timeout second为1,就是探测1s钟还没有返回的话,那么就按照超时处理,这就需要非常高的时效性需求。
健康检查是由kubelet发起的,在kubelet架构里面有probe manager,它是专门做健康检查的管理器,kubelet会去启动一个新的process,就是这个rprobe.sh去真正的做探活,它的父进程是容器里面的entrypoint,entry point,有些entrypoint是没有处理子进程能力的,比如envoy,如果rprobe被执行了,也就是process b执行了,执行完了退出,或者超时了退出,退出之后会变为僵尸进程,然后等父进程来清理,然后它才会真正的消失。
envoy作为一个entry point,它没有处理子进程的能力,这就导致每一次的rprobe,那么这个进程都会出一个僵尸进程,那么僵尸进程就快速涨上去了,就会导致机器上所有的id号都被用光了,迅速这个节点就不可用了。
这就是经典的误区,我们的entryponit没有处理子进程的能力,这样的话遇到退出,那么僵尸进程的处理就没人管。
如何防止PID泄漏

能不能使用单容器进程,如果rprobe提供的不是启动一个新的进程做健康检查,而是使用http get,envoy本身是对http请求启动的线程它是能够处理的,这样就不会有任何的泄漏。
如果没有办法就是要去处理多进程的容器,社区提供了很好的tini这个工具,它就是容器世界里面的systemd,如果要去处理多进程的容器,记得使用tini这个容器进程作为你的entry point,因为它本身就具有处理进程的能力。
在KUbernetes上部署应用的挑战

request是给调度器识别的,调度器在进行调度的时候参考的是request资源,它的语义是最少需要多少资源,调度器在进行调度完成之后,在节点上面将相应request资源扣除掉,作为剩下可调度的资源,也就是request资源会被锁定。
limit是资源所需要的上限,它主要是通过cgroup来控制资源上限的。(资源锁定是按照limit配额来锁定的)
所以针对一个应用就有一个下限和一个上限,如果request和limit完全一样,那么qos为guantter的pod它是没有如何超售的,你要多少资源,kubernetes就帮你锁定多少资源。
Pod数据管理

最不建议将数据存放在容器镜像目录里面,如果要存放临时数据就存放在emptydir,这样就不是overlayfs,而是volume mount进去了,那么性能会好一些,emptydir是我们最推荐的临时存储,因为它的生命周期和pod的生命周期是一致的,pod消失了那么emptydir也没有了,整个数据清理和pod的生命周期是绑定的,不需要额外的动作。
如果想要更加持久一些就host path,面向终端用户的应用我们是不开放host path的,开放host path都是说我这个应用希望修改主机上面的某些文件。
或者还有更加持久的存储需求,要么存在local disk里面,要么存在网络的disk里面。
如果要去读取配置,那么使用configmap或者secret等等mount到容器当中。
我的数据应该保存在哪里

无状态应用大数据尽量保存在emptydir。
应用配置

应用配置有多种方式,一个是通过环境变量,另外一个就是通过volume mount进去。
高可用部署

冗余部署,跨主机,跨机架。
更高的要求就是要跨集群,跨越region。
一个应用跨多个集群部署了,但是和集群大算力有关,可能北京有100台机器,但是在上海有1000台机器,那么在做应用部署的时候可能也是1:10,在做流量转发的时候,比如是多户数据中心,那么就不能按照1:1去做流量转发,外部用户的请求也希望通过1:10的请求分摊到两个数据中心,这样所谓的负载才可以均衡,这里就可以去做精细化的流量控制。
在做代码更新的时候都要去做灰度,所以deployment里面支持的rolling update straget,也就是按照比例去更新节点不同的实例,当有一个应用要跨越多个集群的时候,那么多个集群之间需要做回滚,比如一个应用部署到了北京,上海,深圳三个地方,那么v1-》v2那么是三个地域全部更新,还是希望在北京先验证,这就涉及到跨地域的顺序更新的一些需求,以及如何回滚,应用更新不一定全部成功,那么失败了如何回滚,如何快速的恢复。
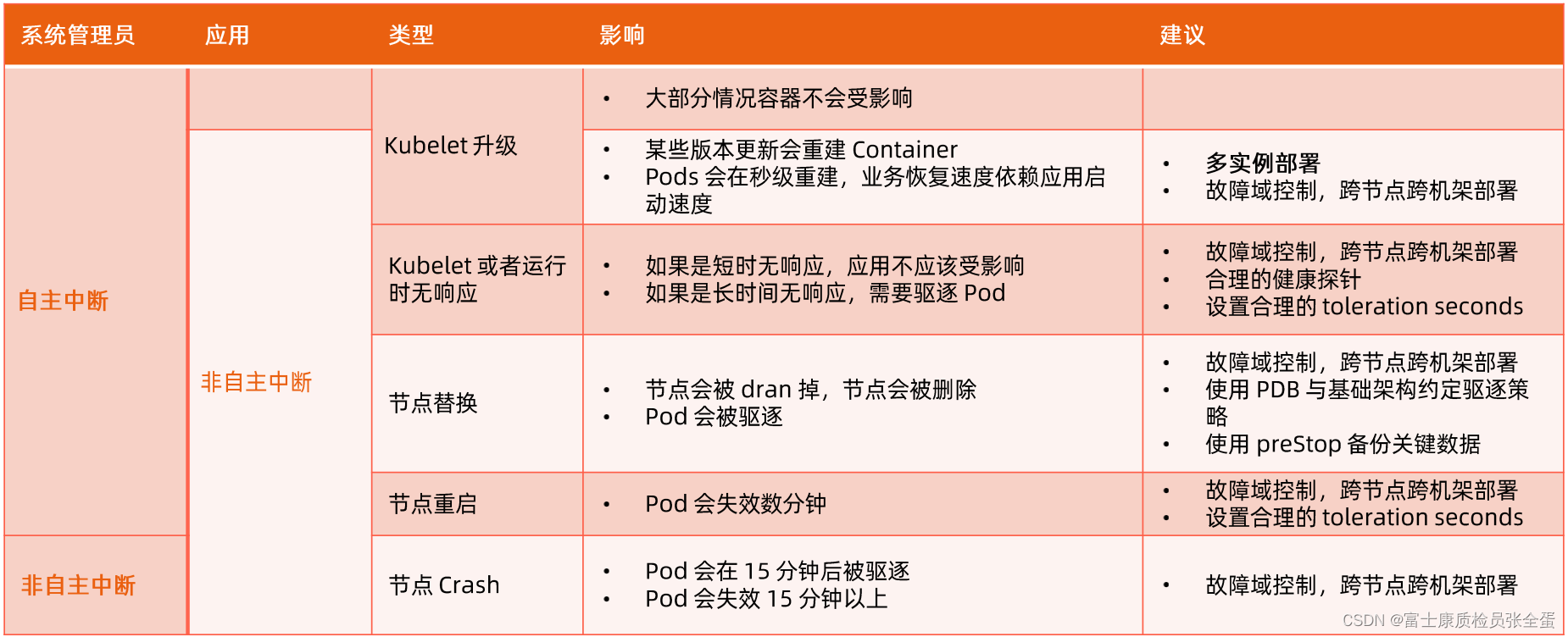
如何应对基础架构的影响

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)