
即席查询-Kylin&Presto
Presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景注意:虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、Oracle的替代品,也非不能用户处理在线事务。
目录
一、Kylin
Kylin简介
定义:Apache Kylin是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表
Kylin架构

1)REST Server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等。另外可以通过Restful接口实现SQL查询
2)查询引擎
当cube准备就绪后,查询引擎就能够获取并解析用户查询。随后会与系统中的其它组件进行交互,从而向用户返回对应的结果
3)路由器
在最初设计时曾考虑过将Kylin不能执行的查询引导去Hive中继续执行,但在实践后发现Hive与Kylin的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
4)元数据管理工具
Kylin是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin的元数据存储在hbase中。
5)任务引擎
这套引擎的设计目的在于处理所有离线任务,其中包括shell脚本、Java API以及Map Reduce任务等等。任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。
Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等
1)标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。
2)支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。
3)亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。
4)可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。
5)BI工具集成
Kylin可与现有BI工具集成,具体包括如下内容:
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与JavaScript、Web网页集成
Kylin安装
Kylin依赖环境
安装kylin前需要先部署好Hadoop、Hive、Zookeeper、HBase,并且需要在/etc/profile中配置以下环境变量HADOOP_HOME,HIVE_HOME,HBASE_HOME
查看Hbase是否正常启动
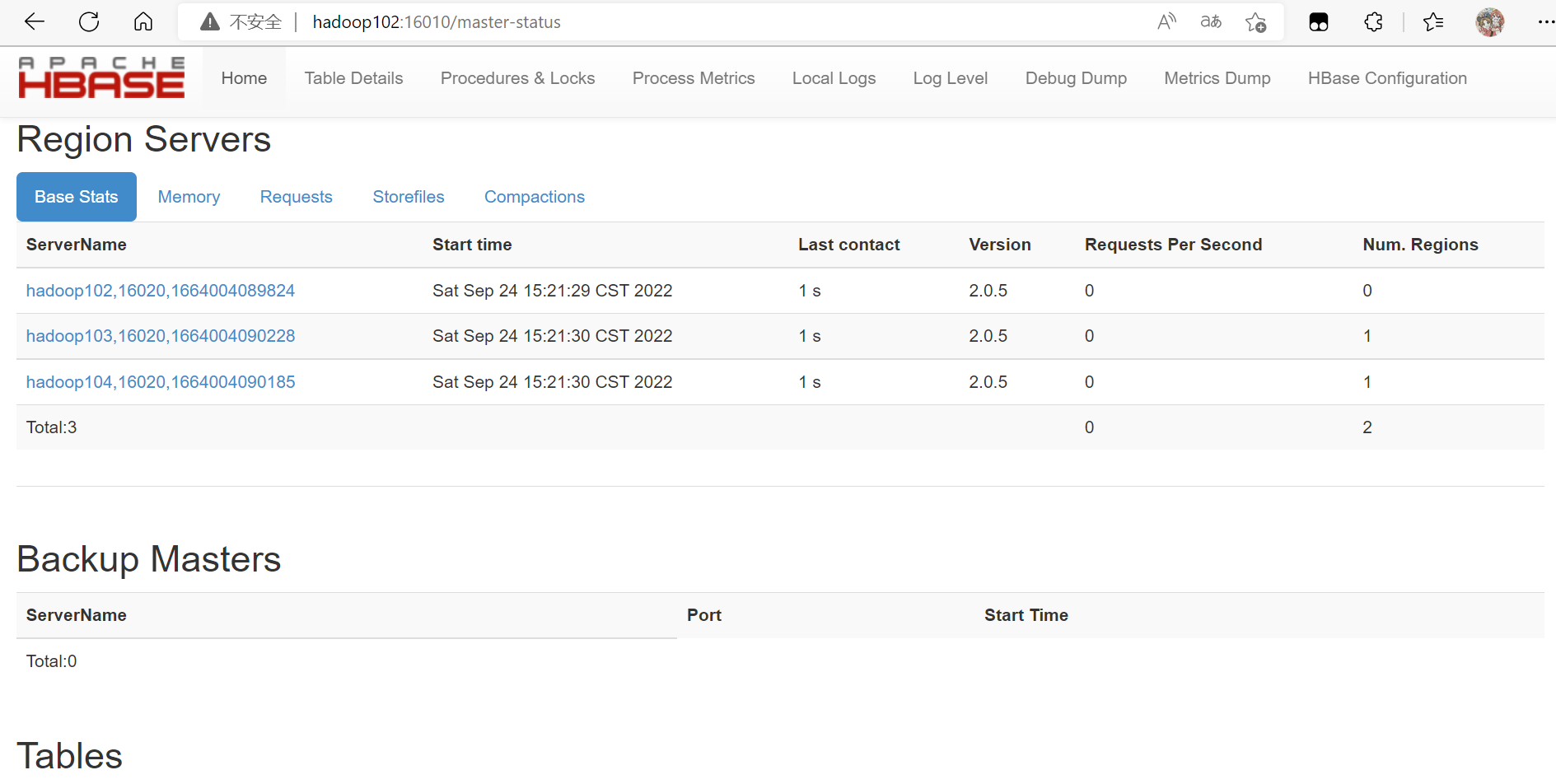
Kylin搭建
解压 重命名
tar -zxvf apache-kylin-3.0.2-bin.tar.gz -C /opt/module/
mv /opt/module/apache-kylin-3.0.2-bin /opt/module/kylinKylin兼容性问题
修改/opt/module/kylin/bin/find-spark-dependency.sh,排除冲突的jar包
需要增加内容:! -name '*jackson*' ! -name '*metastore*'

注意前后保留空格
Kylin启动
(1)需要先启动Hadoop、zookeeper、Hbase
(2)启动kylin
bin/kylin.sh start查看进程

在hadoop102:7070/kylin查看web页面

用户名:ADMIN 密码: KYLIN

Kulin Cube 构建原理
维度和度量
维度:即观察数据的角度。比如员工数据,可以从性别角度来分析,也可以更加细化,从入职时间或者地区的维度来观察。维度是一组离散的值,比如说性别中的男和女,或者时间维度上的每一个独立的日期。因此在统计时可以将维度值相同的记录聚合在一起,然后应用聚合函数做累加、平均、最大和最小值等聚合计算。
度量:即被聚合(观察)的统计值,也就是聚合运算的结果。比如说员工数据中不同性别员工的人数,又或者说在同一年入职的员工有多少。
Cube和Cuboid
有了维度跟度量,一个数据表或者数据模型上的所有字段就可以分类了,它们要么是维度,要么是度量(可以被聚合)。于是就有了根据维度和度量做预计算的Cube理论。
给定一个数据模型,我们可以对其上的所有维度进行聚合,对于N个维度来说,组合`的所有可能性共有2n种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存为一个物化视图,称为Cuboid。所有维度组合的Cuboid作为一个整体,称为Cube。
下面举一个简单的例子说明,假设有一个电商的销售数据集,其中维度包括时间[time]、商品[item]、地区[location]和供应商[supplier],度量为销售额。那么所有维度的组合就有24 = 16种,如下图所示:
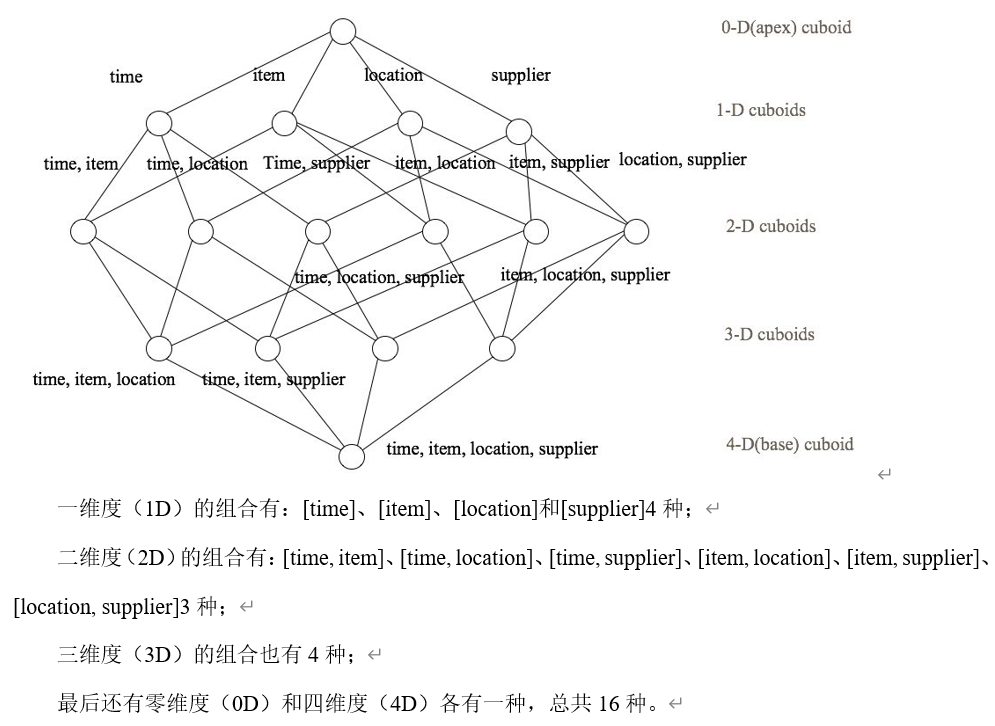
注意:每种维度组合就是一个Cuboid,16个Cuboid整体就是一个Cube
Cube构建算法
1)逐层构建算法

我们知道,一个N维的Cube,是由1个N维子立方体、N个(N-1)维子立方体、N*(N-1)/2个(N-2)维子立方体、......、N个1维子立方体和1个0维子立方体构成,总共有2^N个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉C后聚合得来的;这样可以减少重复计算;当 0维度Cuboid计算出来的时候,整个Cube的计算也就完成了。
每一轮的计算都是一个MapReduce任务,且串行执行;一个N维的Cube,至少需要N次MapReduce Job。
算法优点:
1)此算法充分利用了MapReduce的优点,处理了中间复杂的排序和shuffle工作,故而算法代码清晰简单,易于维护;
2)受益于Hadoop的日趋成熟,此算法非常稳定,即便是集群资源紧张时,也能保证最终能够完成。
算法缺点:
1)当Cube有比较多维度的时候,所需要的MapReduce任务也相应增加;由于Hadoop的任务调度需要耗费额外资源,特别是集群较庞大的时候,反复递交任务造成的额外开销会相当可观;
2)由于Mapper逻辑中并未进行聚合操作,所以每轮MR的shuffle工作量都很大,导致效率低下。
3)对HDFS的读写操作较多:由于每一层计算的输出会用做下一层计算的输入,这些Key-Value需要写到HDFS上;当所有计算都完成后,Kylin还需要额外的一轮任务将这些文件转成HBase的HFile格式,以导入到HBase中去;
总体而言,该算法的效率较低,尤其是当Cube维度数较大的时候。
2)快速构建算法

也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,该算法的主要思想是,每个Mapper将其所分配到的数据块,计算成一个完整的小Cube 段(包含所有Cuboid)。每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果。如图所示解释了此流程。
与旧算法相比,快速算法主要有两点不同:
1) Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
2)一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。
Presto
Presto简介
Presto概念
Presto是一个开源的分布式SQL查询引擎,数据量支持GB到PB字节,主要用来处理秒级查询的场景
注意:虽然Presto可以解析SQL,但它不是一个标准的数据库。不是MySQL、Oracle的替代品,也非不能用户处理在线事务
Presto架构
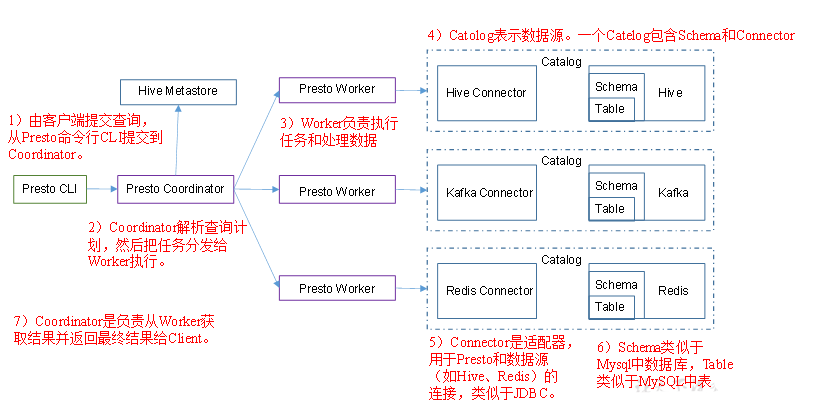
Presto优缺点

Presto安装
解压
tar -zxvf presto-server-0.196.tar.gz -C /opt/module/
改名
mv presto-server-0.196/ presto
在/opt/module/presto目录创建存储数据文件夹
mkdir data
进入/opt/module/presto目录,创建存储配置文件文件夹
mkdir etc
在/opt/module/presto/etc目录下添加jvm.config配置文件
vim jvm.config
添加内容:
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
Presto可以支持多个数据源,在Presto中叫catalog,这里我们配置支持hive的数据源,配置一个hive的catalog
presto/etc目录下
mkdir catalog
cd catalog/
vim hive.properties
添加如下内容
connector.name=hive-hadoop2
hive.metastore.uri=thrift://hadoop102:9083
将hadoop102的presto分发到Hadoop103、Hadoop104上
xsync presto分发后,分别进入三台主机的/opt/module/presto/etc路径 配置node属性 node id 每个节点都不一样
[hadoop102 etc] vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/module/presto/data
[hadoop103 etc] vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffffe
node.data-dir=/opt/module/presto/data
[hadoop104 etc] vim node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-fffffffffffd
node.data-dir=/opt/module/presto/data
Presto是由一个coordinator节点和多个worker节点组成。在hadoop102上配置成coordinator,在hadoop103、hadoop104上配置为worker。
(1)在hadoop102上配置coordinator节点
vim config.properties
添加内容:
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery-server.enabled=true
discovery.uri=http://hadoop102:8881
(2)在hadoop103、104配置worker节点
vim config.properties
coordinator=false
http-server.http.port=8881
query.max-memory=50GB
discovery.uri=http://hadoop102:8881
在hadoop102的/opt/module/hive目录,启动Hive Metastore 用admin角色
nohup bin/hive --service metastore >/dev/null 2>&1 &分别在102、103、104上启动Presto Server
前台启动Presto(控制台显示日志)
bin/launcher run
后台启动Presto
bin/launcher startPresto命令行Client安装
将presto-cli-0.196-executable.jar上传到hadoop102的/opt/module/presto文件夹下
修改文件名
mv presto-cli-0.196-executable.jar prestocli
增加执行权限
chmod +x prestocli
启动prestocli
./prestocli --server hadoop102:8881 --catalog hive --schema default
Presto命令行操作
select * from schema.table limit 100
Presto可视化Client安装
将yanagishima-18.0.zip上传到hadoop102的/opt/module目录
解压
unzip yanagishima-18.0.zip
cd yanagishima-18.0
进入conf/中 编写yanagishima.properties配置
vim yanagishima.properties
添加内容
jetty.port=7080
presto.datasources=admin-presto
presto.coordinator.server.admin-presto=http://hadoop102:8881
catalog.atguigu-presto=hive
schema.admin-presto=default
sql.query.engines=presto
在/opt/module/yanagishima-18.0路径下启动yanagishima
$
nohup bin/yanagishima-start.sh >y.log 2>&1 &
启动web页面 hadoop102:7080
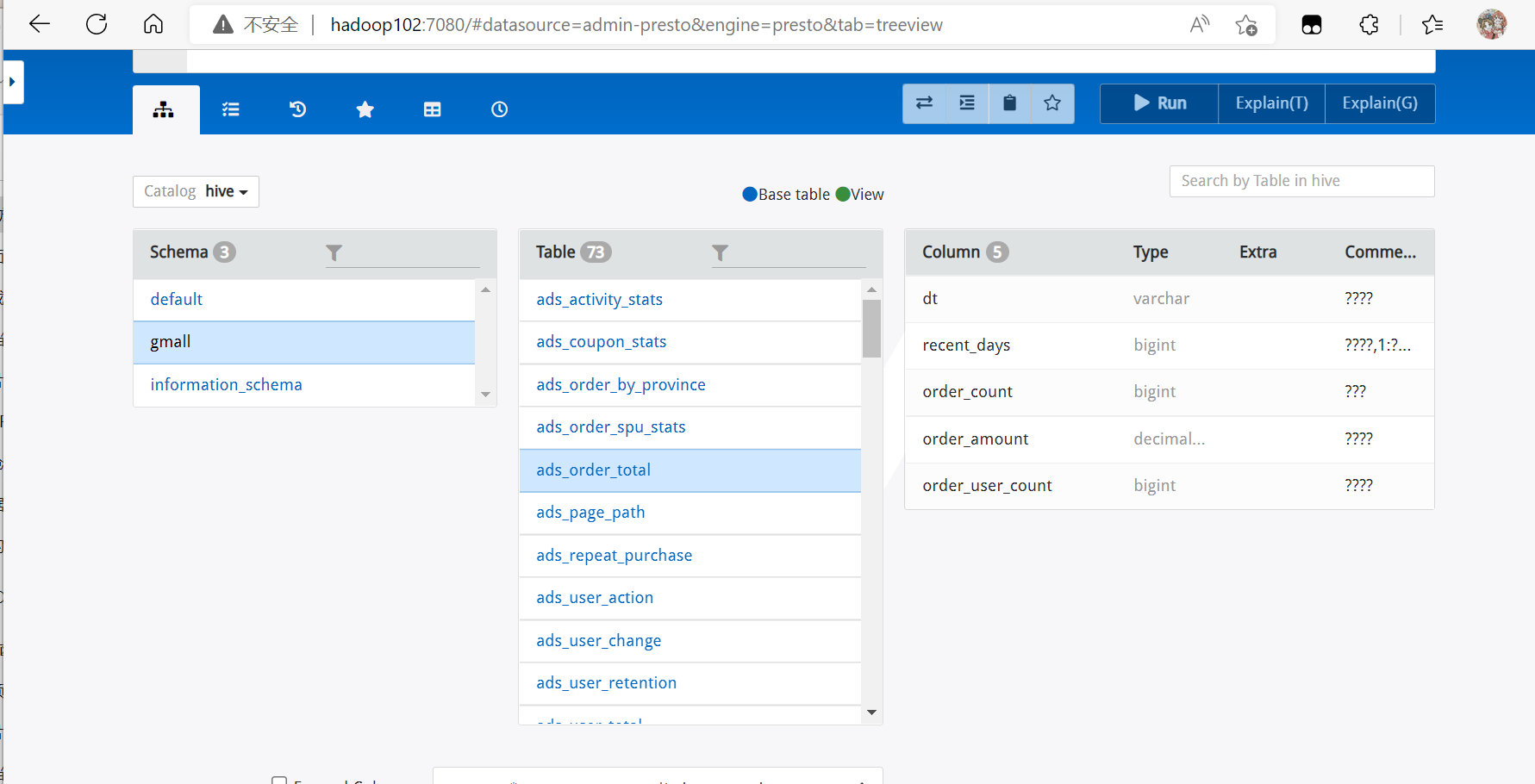
查看表结构

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)