
【mmopenlab系列使用DP模式进行单机多卡训练】windows下命令行和linux下面的 .sh 文件使用一文解决 | 商汤科技
普通的单机单卡训练模式难以解决模型训练速度过慢的问题,对此mmopenlab的代码文档提供了针对DP和DDP的 .sh 文件。其中,dist_train.sh 对应的是DP模式的单机多卡训练方式;slurm_train.sh 对应的是DDP模式的多机多卡训练方式。注:这里本文只看了单机多卡训练模式。DP模式的命令行命令使用以及环境变量分析原。...
目录
前言
普通的单机单卡训练模式难以解决模型训练速度过慢的问题,对此mmopenlab的代码文档提供了针对DP和DDP的 .sh 文件。
其中,dist_train.sh 对应的是DP模式的单机多卡训练方式;slurm_train.sh 对应的是DDP模式的多机多卡训练方式。
注:这里本文只看了单机多卡训练模式。
DP模式的命令行命令使用以及环境变量分析
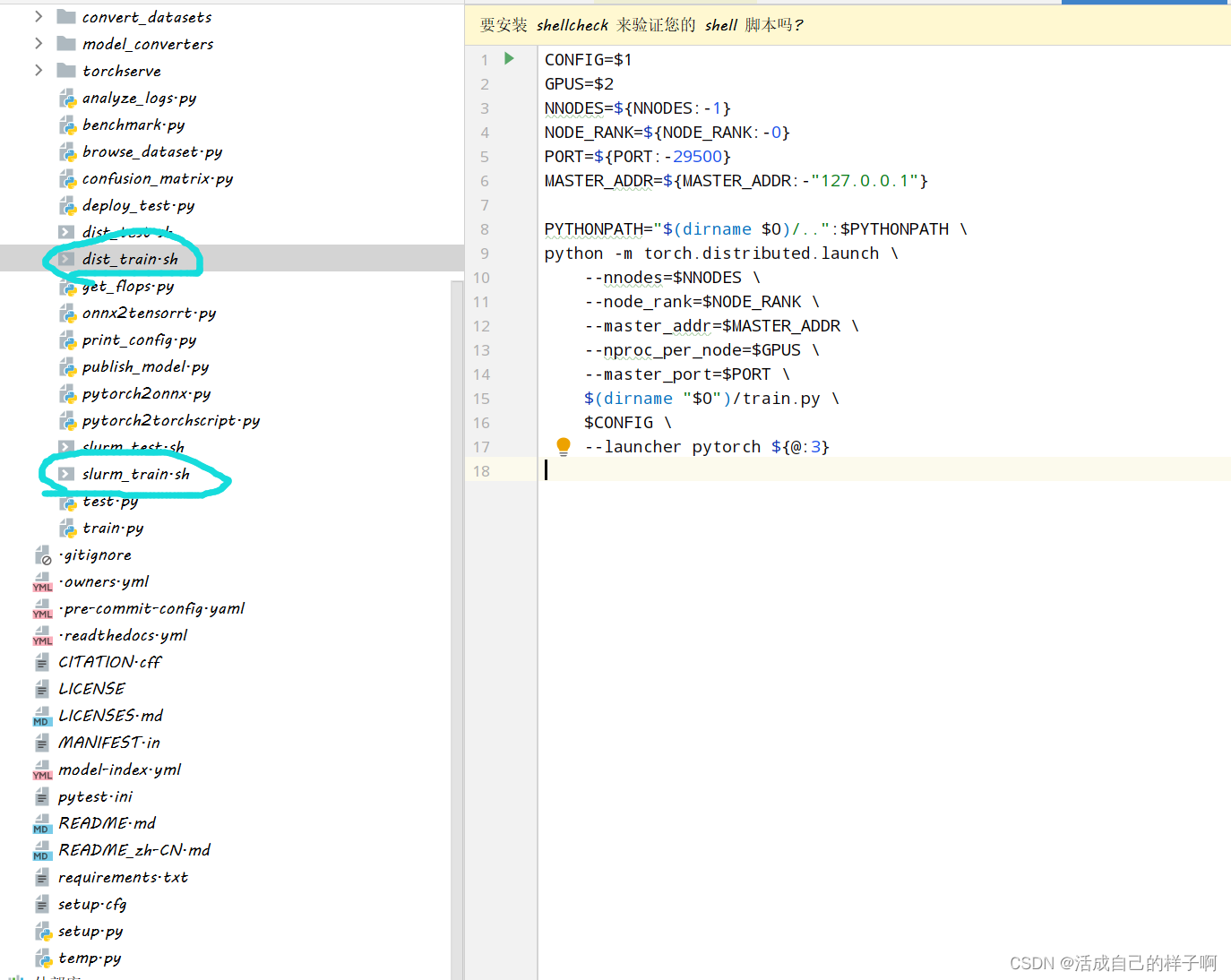
原dist_train.sh文件的分析:
CONFIG=$1 # 需要传输的第一个参数,即配置文件的路径
GPUS=$2 # 需要传输的第二个参数,即要使用的GPU格式个数
NNODES=${NNODES:-1} # 所有的结点数(这里默认的是1,即只使用一个结点,即单机)
NODE_RANK=${NODE_RANK:-0} # 结点编号(因为编号是从0开始,而且只有一个结点,所以这里是0)
PORT=${PORT:-29500}
MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
python -m torch.distributed.launch \
--nnodes=$NNODES \
--node_rank=$NODE_RANK \
--master_addr=$MASTER_ADDR \
--nproc_per_node=$GPUS \
--master_port=$PORT \
$(dirname "$0")/train.py \
$CONFIG \
--launcher pytorch ${@:3} # 使用的环境,这里使用pytorch
相关环境变量分析:
RANK: 用于表示进程的序号,用于进程间通信,泛指一个进程。
LOCAL_RANK: 在一台机器上面的进程编号。(每个机器都从0开始)
NODE: 结点。也指一个服务器。
NNODES: 所有的结点总数。
NODE_RANK:每个结点对应的序号,例如:0或1或2。
NPROC_PER_NODE: 每个结点开启的进程数。
WORLD_SIZE: 全局结点数 = NPROC_PER_NODE x NNODES
config配置文件预配置:
注意这两点即可,其他的均不用调整:
1.这里是每个gpu的,不是所有gpu的,故不需要是gpu数量的倍数。
2.调整iters。使用多gpu之后都要减小iters(在单卡训练的基础上)。
Windows DP 启动命令:
这里是我的启动命令:
python3 -m torch.distributed.launch --nproc_per_node 3 --node_rank 0 --nnodes 1 tools/train.py test_120k_3gpu/deeplabv3_r50-d8_512x512_4x4_160k_coco-stuff164k.py --gpu-id 2 --launcher pyt
orch与单卡训练的不同之处:
需要指定--nproc_per_node --node_rank --nnodes --launcher 参数(注意他们的位置!!!位置不能随意放置)
注:
如果报错:subprocess.CalledProcessError: Command '[xxx,xxx,xxx]' returned non
-zero exit status 1.
请往前看,这个不是最终报错,具体报错原因还在前面。
Linux DP 启动命令:(使用sh文件)
注:
1.使用 sh 文件之前需要编译一下,不然会报: -bash: ./tools/dist_train.sh: Permission denied
chmod 777 ./tools/dist_train.sh2.如果报错: tools/dist_train.sh: line 8: python: command not found
这是因为sh文件的启动命令默认的是python,可以改成自己的,比如python2、python3即可。
这里是我的启动命令:
sh tools/dist_train.sh test_120k_3gpu/deeplabv3_r50-d8_512x512_4x4_160k_coco-stuff164k.py 3 --work-dir test_120k_3gpu/
# 其中:只需要传config路径和gpus数量即可,其他参数可选参考
(2条消息) PyTorch多卡/多GPU/分布式DPP的基本概念(node&rank&local_rank&nnodes&node_rank&nproc_per_node&world_size)_hxxjxw的博客-CSDN博客_nproc_per_node https://blog.csdn.net/hxxjxw/article/details/119606518?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166022262716782248521003%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166022262716782248521003&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-119606518-null-null.142^v40^control,185^v2^control&utm_term=node_rank&spm=1018.2226.3001.4187
https://blog.csdn.net/hxxjxw/article/details/119606518?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166022262716782248521003%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166022262716782248521003&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-119606518-null-null.142^v40^control,185^v2^control&utm_term=node_rank&spm=1018.2226.3001.4187
训练一个模型 — MMSegmentation 0.27.0 文档https://mmsegmentation.readthedocs.io/zh_CN/latest/train.html
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)