

[Python] sys.argv
本文主要讲解sys模块中的sys.argv用法
一键AI生成摘要,助你高效阅读
问答
·

sys模块提供访问Python解释器使用或维护的属性,以及与Python解释器进行交互的方法
简单来讲,sys模块负责程序与Python解释器的交互,并提供了一系列的属性和方法,用于操控 Python运行时的环境,在 Python 程序中使用 sys 模块,首先需要使用 import 导入,代码如下:
import sys
导入sys模块后,就可以使用该模块提供的属性和方法了,其中sys.argv可以获取命令行参数(argv 属性表示传递给Python脚本的命令行参数列表)
sys.argv:以列表的方式获取运行Python程序的命令行参数存放其中,其中sys.argv[0]通常就是指该Python程序脚本名称,sys.argv[1]代表第一个参数,sys.argv[2]代表第二个参数,第三、第四参数以此类推
通过使用argv属性获取Python解释器的命令行参数列表,并使用argv[0]获取Python脚本的完整路径,代码如下:
# python脚本名为Demo.py
import sys
print(sys.argv)
print(sys.argv[0])
if sys.argv[1] == 'A':
print('我是A命令,该执行A命令了')
elif sys.argv[1] == 'B':
print('我是B命令,该执行B命令了')
else:
print('我是C命令,该执行C命令了')按快捷键<Win + R> ,输入cmd即可弹出Windows命令行窗口,在Demo.py脚本文件路径中输入python Demo.py A,结果如下图所示:
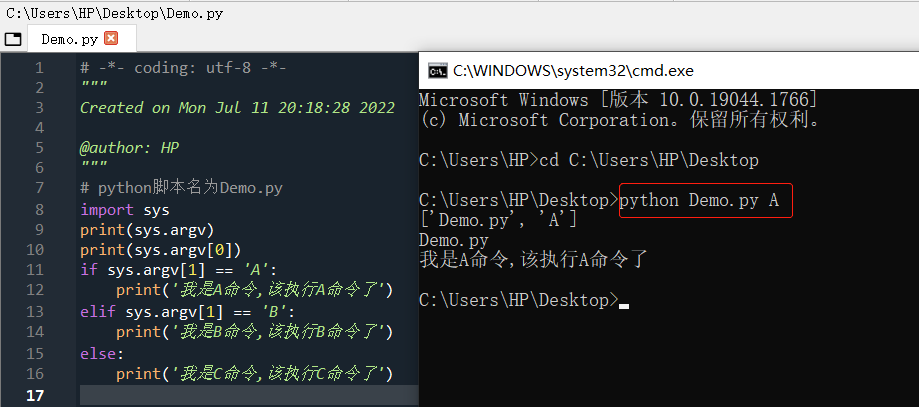
练习案例
数据准备
DROP TABLE IF EXISTS `demo_students`;
CREATE TABLE `demo_students` (
`sid` int(11) NOT NULL,
`cid` int(11) DEFAULT NULL,
`name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`sid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `demo_students` VALUES (1, 1, 'Odin');
INSERT INTO `demo_students` VALUES (2, 1, 'Jack');
INSERT INTO `demo_students` VALUES (3, 2, 'Lee');
INSERT INTO `demo_students` VALUES (4, 2, 'Bob');
INSERT INTO `demo_students` VALUES (5, 3, 'Tom');
DROP TABLE IF EXISTS `demo_courses`;
CREATE TABLE `demo_courses` (
`cid` int(11) NOT NULL,
`cname` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `demo_courses` VALUES (1, '语文');
INSERT INTO `demo_courses` VALUES (2, '数学');
INSERT INTO `demo_courses` VALUES (3, '英语');demo_students(学生表)
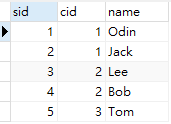
demo_courses(课程表)
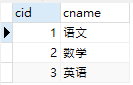
编写Test.py脚本
import pandas as pd
import pymysql
from sqlalchemy import create_engine
import json
import sys
PAR = sys.argv[1]
PARAM = json.loads(PAR)
DATABASE = {
'69': {
'host': 'localhost',
'user': 'root',
'password': '123456',
'database': 'test',
'port': 3306
}
}
# 连接哪台服务器
TB_CONNECT = "69"
DATABASE = DATABASE[TB_CONNECT]
# 以下是2个输入文件(input)
STUDENTS_INPUT = PARAM["Students"]
COURSES_INPUT = PARAM["Courses"]
# 以下是输出结果(output)
INFO_OUTPUT = "students_info"
def get_data_from_mysql(table_name=None):
"""
从数据库读取一张完整的表并返回该表对应的DataFrame
参数说明:
table_name: 数据库中存放的表名,字符串类型
"""
try:
con = pymysql.connect(host=DATABASE['host'],
user=DATABASE['user'],
password=DATABASE['password'],
database=DATABASE['database'],
port=DATABASE['port']
)
df = pd.read_sql("select * from `{}`".format(table_name),con)
return df
except Exception as e:
raise Exception("读取数据时发生错误:" + str(e))
finally:
con.close()
def save_data_to_mysql(df, table_name):
"""
将一个DataFrame保存至数据库
参数说明:
df: 一个DataFrame对象
table_name: 需要存入数据库的表名,字符串类型
"""
try:
ms_engine = create_engine(
'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(
DATABASE['user'], DATABASE['password'], DATABASE['host'],
DATABASE['port'], DATABASE['database']))
df.to_sql(table_name, ms_engine, if_exists='replace', index=False)
except Exception as e:
raise Exception("保存数据时发生错误:" + str(e))
finally:
ms_engine.dispose()
# 导入students和courses数据
df_students_data = get_data_from_mysql(STUDENTS_INPUT)
df_courses_data = get_data_from_mysql(COURSES_INPUT)
# students表和courses表根据字段'cid'进行左连接合并生成info表
df_info_result = pd.merge(df_students_data,df_courses_data,how='left',on=('cid'))
# info表只保留'sid','name','cname'字段
order = ['sid','name','cname']
df_info_result = df_info_result[order]
# 将info表中数据保存至数据库
save_data_to_mysql(df_info_result, INFO_OUTPUT)
print("The data is saved successfully")方法1:在编辑器Spyder中的IPython console窗口输入如下指令:
%run Test.py "{\"Students\":\"demo_students\",\"Courses\":\"demo_courses\"}"
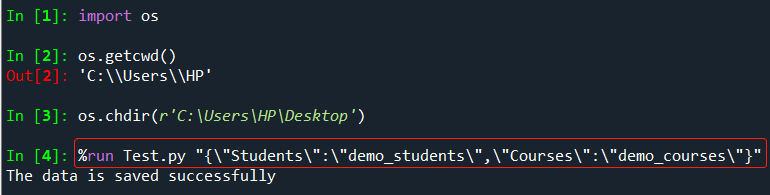
方法2:按快捷键<Win + R> ,输入cmd即可弹出Windows命令行窗口,在Test.py脚本文件路径中输入如下指令:
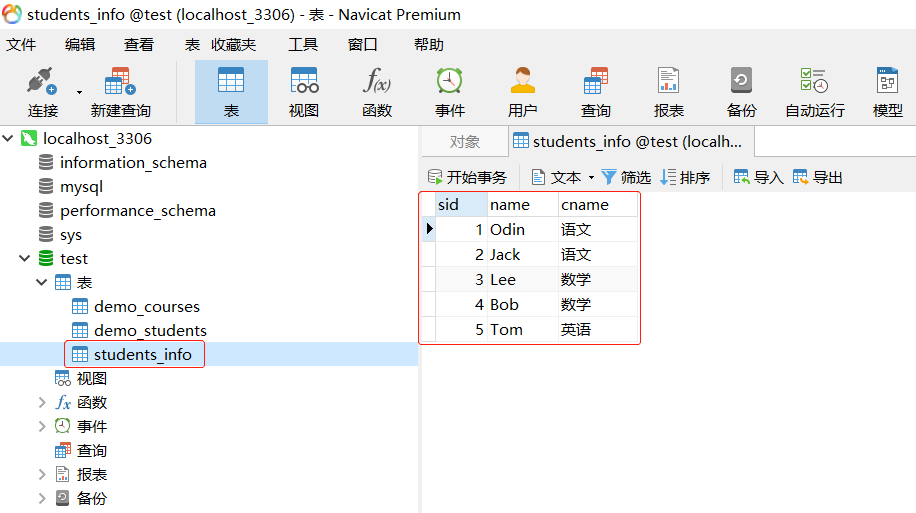
python Test.py "{\"Students\":\"demo_students\",\"Courses\":\"demo_courses\"}"结果如下图所示:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 12
12 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)