
MySql插入百万级数据的几种方法
MySQL插入大批量数据, MySQL插入百万级数据, MySQL表中插入百万数据
·
有时候我们在开发环境需要模拟生产环境中百万级甚至千万级的数据量,以测试相关代码的性能时,这时候我们就需要向表中快速插入大批量的数据,怎么插入呢?一般常用的有三种方法,如下:
1.通过存储过程插入
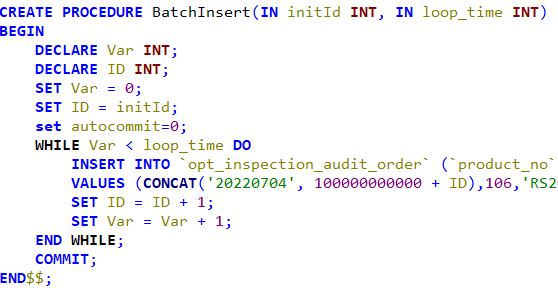
如果我们想简单快速的插入大批量数据,存储过程是个不错的选择,下面这个存储过程,是我向表xxx_audit_order中插入100万条数据,耗时25秒左右,这里建议:
1.插入数据前先把表中的索引去掉,数据插入完成之后,再创建索引
2.关闭事务的自动提交
以上两点对提高速度很有帮助,因为索引的维护以及每次插入都提交事务是很耗时间的

use test_db;
DROP PROCEDURE if EXISTS BatchInsert;
delimiter $$
CREATE PROCEDURE BatchInsert(IN initId INT, IN loop_counts INT)
BEGIN
DECLARE Var INT;
DECLARE ID INT;
SET Var = 0;
SET ID = initId;
set autocommit=0; -- 关闭自动提交事务,提高插入效率
WHILE Var < loop_counts DO
INSERT INTO `xxx_audit_order` (`product_no`,`xxx_channel_code`,`business_no`,`xxx_product_id`,`xxx_product_name`,`xxx_audit_no`,`xxx_audit_status`,`inspection_report_no`,`audit_report_no`,`re_audit_count`,`inspector_id`,`remark`,`delete_dt`,`create_by`,`create_dt`,`update_by`,`update_dt`,`xxx_link`,`service_standard_no`,`depth_inspection`,`execute_channel`,`seller_type`)
VALUES (CONCAT('20220704', 100000000000 + ID),106,'RS20190719143225916727',26958,'荣耀 Play',CONCAT('C0', 512201907191454553491 + ID),FLOOR(RAND()*10) % 4,'R1152109544189558784','R1152216911870734336',2,0,null,0,6532,UNIX_TIMESTAMP() + ID ,0,Now(),FLOOR(RAND()*10) % 3,'',0,1,null);
SET ID = ID + 1;
SET Var = Var + 1;
END WHILE;
COMMIT;
END$$;
delimiter ; -- 界定符复原为默认的分号
CALL BatchInsert(1, 1000000); -- 调用存储过程
2.通过应用代码插入
也就是说通过在应用代码中(我们自己造数据的测试代码)使用MySQL的batch insert方式插入:
insert into table(id,col) values(1,'foo'),(2,'bar')…
注意分批提交的大小,1000条插入一次还是3000条插入一次,也是会影响性能的
3.通过MySQL自带的mysqlImport工具
即使用load data通过文件导入

无需安装部署,在线快速体验 Byzer
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)