

光谱特征选择---连续投影算法SPA
作为光谱分析的重要环节,如何从冗余、复杂的变量中选取特征变量直接决定了预测模型的性能,在实际特征选择过程中,通常从两方面考虑特征选择的合理性:一是对目标变量y的解释性,二是不同自变量x间的冗余性,前者是考虑变量自身或变量组合的预测性能,后者考虑变量间的冗余问题,如何在保证对模型性能的同时减少变量冗余对于提高模型精度、降低过拟合风险和提高模型泛化性十分重要。本周分享连续投影算法(successive
作为光谱分析的重要环节,如何从冗余、复杂的变量中选取特征变量直接决定了预测模型的性能,在实际特征选择过程中,通常从两方面考虑特征选择的合理性:一是对目标变量y的解释性,二是不同自变量x间的冗余性,前者是考虑变量自身或变量组合的预测性能,后者考虑变量间的冗余问题,如何在保证对模型性能的同时减少变量冗余对于提高模型精度、降低过拟合风险和提高模型泛化性十分重要。
本周分享连续投影算法(successive projections algorithm,SPA),SPA算法2001年发表在Chemometrics and Intelligent Laboratory Systems期刊上,该算法原理简单,适用性较强,目前还有很多研究应用该方法进行分析。我们首先简单分析一下SPA的分析原理和关键步骤,然后给出代码,最后应用一个实例数据进行分析测试,完整代码及答疑在交流群,不在此展示。
1. SPA算法
SPA是一种前向迭代搜索方法,即从一个波长开始,然后在每次迭代中加入一个新变量,直至所选变量数达到设定值N。SPA的目的是选择光谱信息最少冗余的波长以解决共线性问题,其实现步骤可表示如下:
注意:对于波段数和起始位置的选择问题,可以通过对比不同参数的结果进行分析。
2. 代码分析
function [SelectedW] = SPA(SpecCal,Winitial,totN)% SpecCal 光谱矩阵(行为样品,列为波段)% Winitial 起始波段% totN 选择的波段总数% SelectedW 最终选择的波段[NoSp,Novab] = size(SpecCal);Varibs = 1:Novab;SelectedW = ones(1,totN);Specj = SpecCal;Specn = SpecCal(:,Winitial);SelectedW(1) = Winitial;for n = 1:totN-1 %待确定变量数的循环litW =SelectedW(1:n);Jnotsel = setdiff(Varibs,litW); %确定未映射变量APSpecj = zeros(1,length(Jnotsel));PSpecj = zeros(NoSp,Novab);stP = 1;for j = Jnotsel %未确定变量的循环PSpecj(:,j) = Specj(:,j) - (Specj(:,j)'*Specn)*Specn*(Specn'*Specn)^(-1);APSpecj(stP) = norm(PSpecj(:,j));stP = stP+1;endSelectedW(n+1) = Jnotsel(APSpecj==max(APSpecj));Specn = SpecCal(:,SelectedW(n+1));Specj = PSpecj;endend
3. 实例分析
此处以某油掺假比例预测数据为例,光谱数据为39x256,波长范围为897-2124 nm,选择SNV进行预处理,所得光谱数据为:
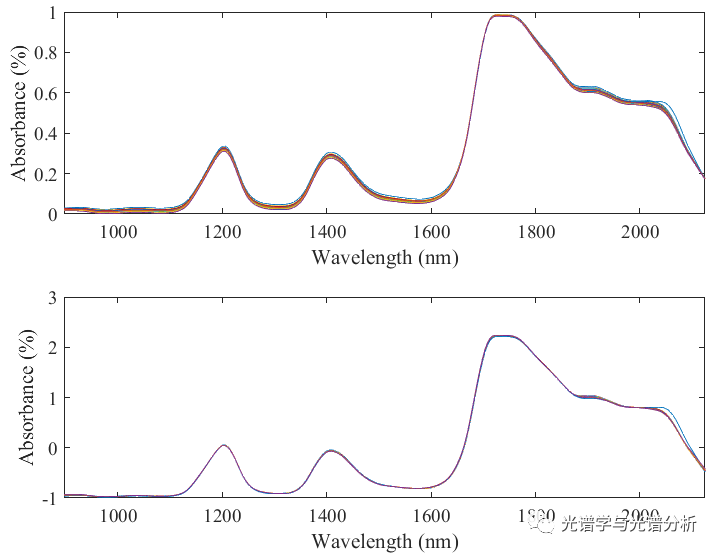
图1 原始与SNV光谱
SPA选择的特征变量(前60)分布为:
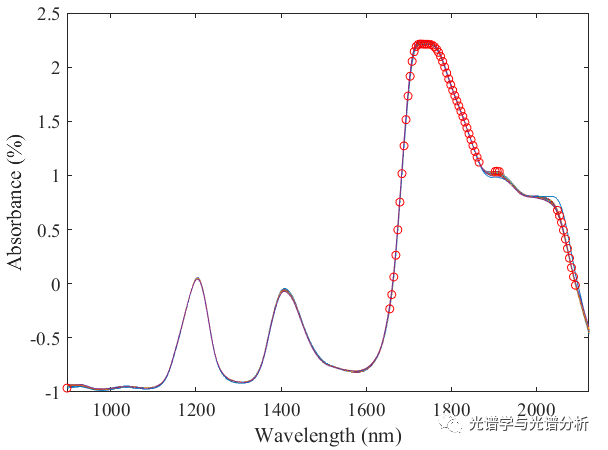
图2 SPA选择特征分布
分析发现,所选变量主要集中在1780nm左右,而在其他两个峰没有选择特征变量,主要原因是特征选择过程属于无监督过程,仅从自变量分布进行分析,未建立有效的预测模型。基于上述模型所建模型的预测结果为:
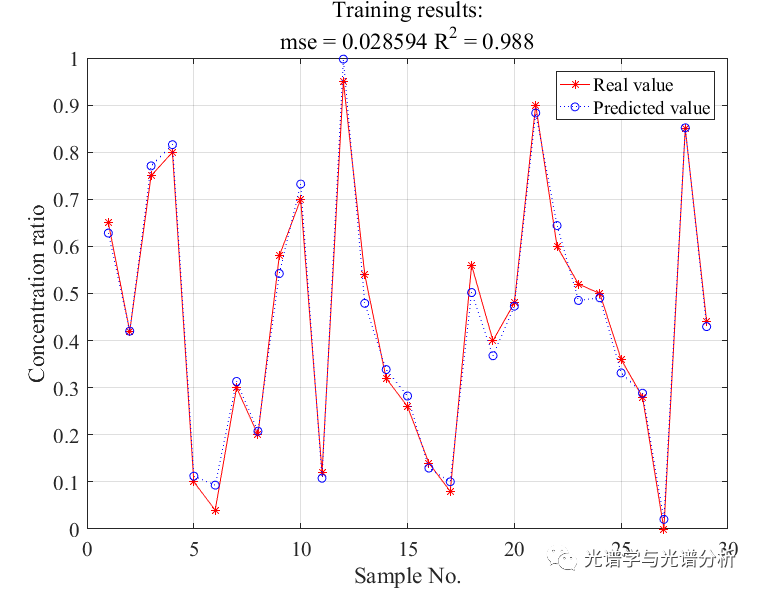

图3 SPA-PLS分析结果
实验分析结果表明,SPA-PLS模型的训练集和预测集精度相近,相比于原始数据集(0.96,0.93,LVs=4),SPA能够有效提高模型性能,但是相比于CARS,性能提升有限,主要原因是该方法特征选择过程为无监督过程,选择的变量最大化解释了自变量空间,未建立预测模型,因此变量解释能力有限。
有需要的话请添加LW10210094,请备注姓名和学校。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 20
20 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)