论文阅读_基于GCN的知识图对齐
介绍英文题目:Cross-lingual Knowledge Graph Alignment viaGraph Convolutional Networks中文题目:基于GCN的跨语言知识图对齐论文地址:https://aclanthology.org/D18-1032.pdf领域:知识图谱,知识对齐发表时间:2018作者:Zhichun Wang 北京师范大学出处:EMNLP被引量:198代码和
介绍
英文题目:Cross-lingual Knowledge Graph Alignment viaGraph Convolutional Networks
中文题目:基于GCN的跨语言知识图对齐
论文地址:https://aclanthology.org/D18-1032.pdf
领域:知识图谱,知识对齐
发表时间:2018
作者:Zhichun Wang 北京师范大学
出处:EMNLP
被引量:198
代码和数据:https://github.com/1049451037/GCN-Align
阅读时间:2022.04.15
其它介绍
文章亮点:
- 复习了之前的对齐方法
- 提出了邻接矩阵的计算以及属性的代入方法技巧
- GCNAlign和同类文件相比,引用量大,速度快,效果好,常作为默认工具
- 文章偏重真实场景中,多种关系,属性类别,属性值的应用。
泛读
- 针对问题:不同语言知识图中的实体对齐
- 结果:使用比较简单的方法,超过或得到与之前的方法近似的效果
- 核心方法:调整GCN层计算方法,可同时对结构和属性编码
- 难点:无
- 泛读后理解程度:直接精读
(看完题目、摘要、结论、图表及小标题)
精读
摘要
文中方法主要用于解决多语言知识图的实体对齐问题。文中提出GCNs(graph convolutional networks),利用预对齐实体,通过训练,将实体表征为低维向量。实体对齐基于实体和嵌入的距离计算。嵌入基于对图结构和实体属性的学习,结合二者得到更精确的结果。
1. 介绍
很多时候,需要知识在不同语言中具有相同编码,匹配,链接。手工难以实现,因此不断寻找自动方法。
传统对齐方法依赖机器翻译或者定义跨语言的特征来发现语言之间的关系。最近,常用基于嵌入的方法对齐,包含MTransE,JAPE等。两个图中有一些预对齐的实体,基于嵌入的方法通过训练将实体转换到低维空间,然后基于它们在低维空间的表示进行匹配,JE和ITransE也用于单语言中的知识融合和跨语言的知识对齐。上述方法无需依赖机器翻译或特征工程。
然而,上述方法都面临优化问题,比如 JE, MTransE和ITransE都使用超参数均衡损失函数,JAPE使用预对齐的实体将两个图合二为一,并给负例加权。实体嵌入既要编码结构信息,又要编码等价关系。另外,属性信息也应该被更好地利用。MTransE和ITransE未利用属性信息,JAPE只利用了属性类型。
文中提出基于图卷积的方法GCNs直接对实体的等价关系建模。卷积网络抽取图结构,利用节点的邻居编码:两个对等实体的邻居也常常是对等的实体。另外,还对属性进行了简单有效的利用。
文中模型主要优势如下:
- 使用图中的实体关系构建GCNs,只使用实体在图中的对等关系(没像JAPE使用词嵌入),模型复杂度低。
- 只需要预测对齐的实体作为训练数据,不需要预对齐的关系或属性。
- 结合关系结构和属性有效地提升了对齐效果。
2. 相关工作
2.1 图嵌入
图嵌入:将图中实体和关系映射到低维空间。学习图嵌入一般通过最小化全局损失函数。常用于关系预测,信息抽取等任务。
TransE
- 简单而有效的方法
- 时间:2013年
- 原理: h + r ≈ t h+r \approx t h+r≈t 编码后的头实体加关系约等尾实体
- 损失函数:最小化训练集上基于差值的排序标准
- 引申算法:TransH,TransR,TransD,后续的模型增加了复杂度,提升了效果
2.2 基于嵌入的实体对齐
JE
- 时间:2016年
- 把两个图映射到同一嵌入空间
- 通过种子对齐多个图
- 图嵌入使用TransE改进算法
- 损失函数:TransE损失+全局对齐损失
MTransE
- 时间:2017年
- 把两个图映射到不同嵌入空间
- 提供转换方法转换两组空间
- 图嵌入使用TransE改进算法
- 损失函数:知识图模型+对齐模型
- 训练时,需要两图中对齐的三元组
JAPE
- 时间:2017年
- 结合了结构嵌入和属性嵌入
- 结构嵌入使用TransE
- 属性嵌入使用Skip-gram模型,捕捉属性的相关性
- 需要预先对关系和属性对齐
ITransE
- 时间:2017年
- 先使用TransE学习实体和边的嵌入
- 利用对齐种子学习不同语言库在联合空间的知识图映射
- 通过使用新发现的实体对齐来更新实体的联合嵌入,从而实现迭代实体对齐
- 要求在KG之间共享所有关系
上述几个模型都使用类似框架:用TransE学习实体嵌入,再定义对齐实体嵌入之间的变换和对齐。
文中提出的方法使用了不同框架,它使用GCNS将实体嵌入到统一的向量空间中,其中对齐的实体被期望尽可能接近,并且只学习实体嵌入,不学习边嵌入,因而不需要边的相关先验知识。
3. 问题定义
KGs使用三元组,三元组又分为关系三元组〈entity1,relation,entity2〉和属性三元组〈entity,attribute,value〉,文中方法使用了两种。
KG 定义为 G =(E,R,A,TR,TA),其中E为实体,R为关系,A为属性,TR为关系三元组,TA为属性三元组,用符号V定义属性的具体值。
用G1,G2分别代表不同语言的两个图 。
S
=
{
(
e
i
1
,
e
i
2
)
∣
e
i
1
∈
E
1
,
e
i
2
∈
E
2
}
i
=
1
m
S={\{(e_{i1},e_{i2})|e_{i1}\in E_1,e_{i2} \in E_2}\}^m_{i=1}
S={(ei1,ei2)∣ei1∈E1,ei2∈E2}i=1m
S是G1与G2之间m个预先对齐的实体对,即种子。将任务定义为对齐不同语言的知识图,基于已知的对齐种子找到新的实体对齐。对于DBpedia和YAGO的这样数据集,可以利用多语言间链接来构建预测对齐的实体对。种子作为对齐过程中的训练数据。
4. 方法
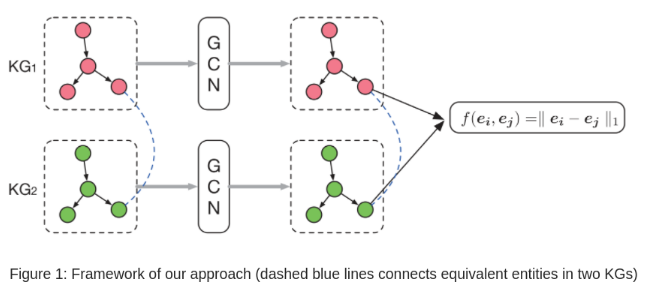
如图-1所示,KG1和KG2分别是不同语言的两个图,给出二者间的对齐种子S,基于GCN方法搜索图中更多的实体对齐。基本思想是利用GCN将不同语言的实体嵌入到同一个向量空间,相等的实体在空间中的距离越近越好。利用事先定义好的距离函数作为量度。
4.1 基于GCN的实体嵌入
GCN是一种直接操作图数据的神经网络结构,它使用端到端的学习来预测,其输入是任意大小和形状的图,具体输入是节点和结构的特征向量,其目标是学习一种方法来表示输入的特征,并生成节点级的输出。GCN可以将邻居节点的信息编码成实际的值,作用于下游的分类回归任务。解决图对齐问题基于以下两个假设:(1)相对节点具有类似属性(2)相同节点的邻居相同。GCNs结合了属性信息和结构信息,文中方法使用GCN将信息转换到低维向量空间中,相似的节点在该空间中编码也想似。
一个GCN模型包含多个层,第l层的输入是一个nxd(l)的特征矩阵,其中n是图中节点个数,d(l)是第l层的特征数。第l层的输出是通过图卷种计算出的矩阵:
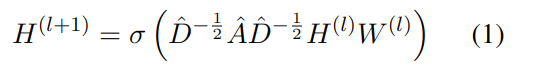
其中 σ是激活函数,A是nxn的邻接矩阵,用于描述图的连通性,A=A+I,它加入了单位矩阵I,I描述了节点自身的连通性;D是度矩阵,参数W(l)是d(l)xd(l+1)的参数矩阵,用于第l层输出向l+1层转换。
结构和属性嵌入
文中方法将不同图中的节点映射到同一向量空间,为了利用节点的结构和属性信息,在两个角度对齐了向量。h是每一层输出的特征向量,结构向量hs(0)被随机初始化,在训练过程中更新;属性向量ha(0)也在训练过程中更新。H是所有向量的表示。W是训练得到的参数。
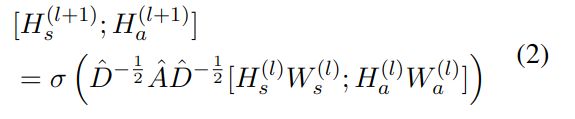
公式中的[ ; ] 表示concat连接两个矩阵;激活函数使用ReLU(.)=max(0,.)。
模型设置
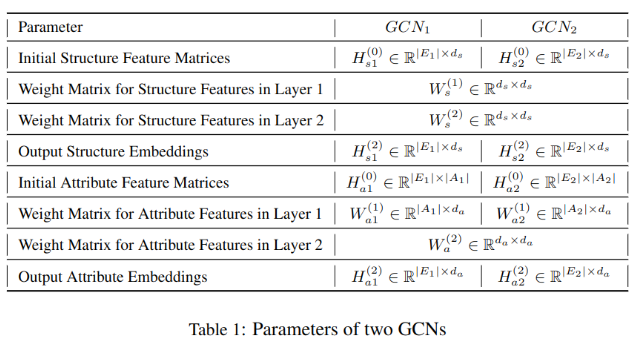
文中方法使用了两层GCN,每层处理一个图产生它的实体嵌入,对两个图分别生成GCN1和GCN2,描述实体的结构向量均使用ds作为其维度,两个模型共享参数矩阵Ws。对于实体的属性特征,输出特征的维度为da,由于两个图的特征个数不同,两个模型的输入属性特征不同,维度也不同。因此,第一层将属性转换成同一维度da(矩阵W不同),第二层属性GCN输出为同一维度da。
表-1展示了各数据的维度:
计算邻接矩阵
在GCN模型中,邻接矩阵A被用于卷积计算。与无向图不同的是,当前图包含多种关系。因此,重新定义了A:aij ∈A,aij是实体i传播到实体j的程度,通过不同的关系连接的实体,等价的概率也不同(比如关系:父母和朋友)。因此对每种关系计算了两种量度:

其中 #Triples_of_r 是包含关系r的三元组个数; #Head_Entities_of_r 和 #Tail_Entities_of_r 是头/尾实体和关系r同时存在的个数。用它来描述第i个实体对第j个实体的影响,以计算邻接矩阵:
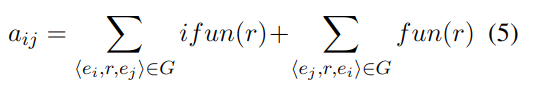
它同时反应了正向和反向的强度。举例如下:
例一:父子关系
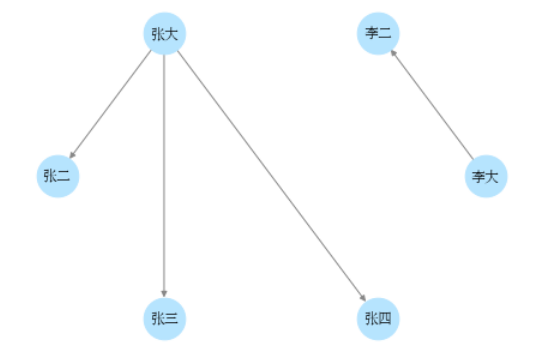
李大与李二:
f
u
n
=
1
4
i
f
u
n
=
1
4
a
i
j
=
1
4
+
1
4
=
0.5
\begin{aligned} & fun=\frac{1}{4} \\ & ifun=\frac{1}{4} \\ & a_{ij}=\frac{1}{4}+\frac{1}{4}=0.5 \end{aligned}
fun=41ifun=41aij=41+41=0.5
张大与张三:
f
u
n
=
3
4
i
f
u
n
=
1
4
a
i
j
=
3
4
+
1
4
=
1
\begin{aligned} & fun=\frac{3}{4} \\ & ifun=\frac{1}{4} \\ & a_{ij}=\frac{3}{4}+\frac{1}{4}=1 \end{aligned}
fun=43ifun=41aij=43+41=1
例二:朋友关系
(为简化对比,假设朋友关系是有向图,实际并不是)
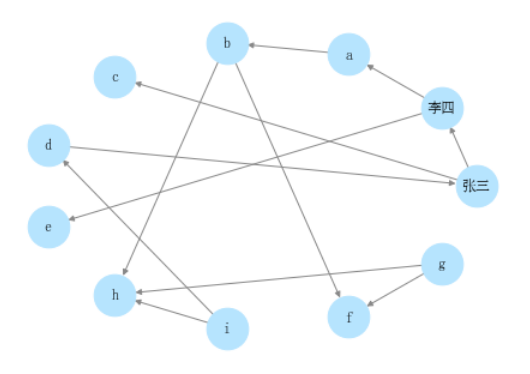
f
u
n
=
2
12
i
f
u
n
=
1
12
a
i
j
=
2
12
+
1
12
=
0.25
\begin{aligned} & fun=\frac{2}{12} \\ & ifun=\frac{1}{12} \\ & a_{ij}=\frac{2}{12}+\frac{1}{12}=0.25 \end{aligned}
fun=122ifun=121aij=122+121=0.25
总之:某种关系出现越少,对它所连接的实体影响越大(类似TF/IDF)。比如父子关系出现少影响大,朋友关系出现多影响小。
4.2 对齐预测
实体对齐基于两个图GCN输出结果的距离。设图G1中实体为ei,G2中实体为vj。计算距离:

其中f(x,y)是1范数(向量元素绝对值之和),hs和ha是实体的结构嵌入和属性嵌入,ds和da是输出维度,β是用于衡量结构和属性的超参数。
实体越相似,距离越近。计算G1中ei与G2中所有实体的距离,排序后返回相似度最高的实体作为对齐的候选项。G2向G1对齐也是同理(方向不同结果不同)。
4.3 模型训练
使用种子S来训练GCN模型,最小化基于边际的排序损失函数:
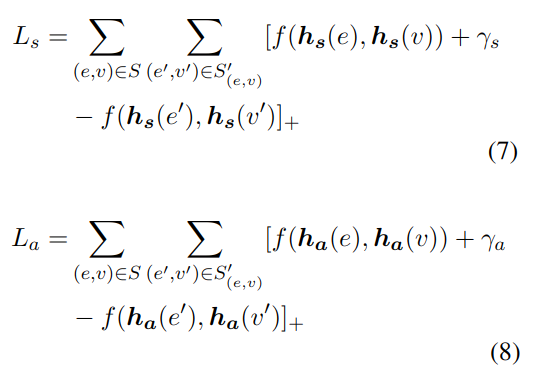
其中[x]+=max{0,x},S’是由e或v随机替换得到的负例,f用于计算距离,γs,γa > 0是超参数,用于提升对齐的效果,它是理想的正例和负例之间的距离(正例至少要比负例大γ,loss才能等于0)。
Ls和La分别是结构和属性的损失函数,二者相互独立,也分开优化,具体方法使用随机梯度下降。
5. 实验
5.1 数据集
DBP15K是由Sun等2017年构建的,基于DBpedia的多语言对齐数据集,包含:中文,英文,日文,法文。每组数据包含两种语言15K个实体的对齐,用于训练和测试。
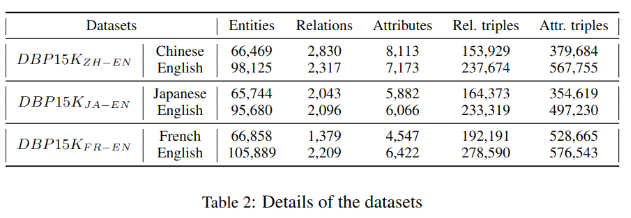
5.2 实验设置
使用JE,MTransE,JAPE,JAPE’(不预对齐关系和实体)作为对比基线,30%作为训练集,70%作为测试集。
Hits@k指的是正确对齐的实体排在前k个候选实体中的比例。
超参数设置成输出维度ds=1000,da=1000, γs = γa = 3, 计算距离时的 β 设为经验值0.9(关系占90%,属性占比10%)。
5.3 结果

(图太长,截了一部分)
其中关键字:SE w/o neg是无负例的结构三元组,SE是结构三元组,AE是属性三元组。
GCN(SE)与GCN(SE+AE)
可以看到加入属性三元组后,效果提升范围在1%-10%之间。这说明对齐主要依赖结构信息,而属性信息也很有用,文中结合二者的方法也是有效的。
GCN(SE+AE) 与基线
在中英互译的评测中JAPE有明显优势,GCN结果与之很相近。需要注意的是JAPE使用了额外的信息(词嵌入),而文中模型未使用这些先验知识,JAPE’在未使用先验知识的情况下效果就差了很多。而另两个数据集中,文中模型效果更好。相对JE和MTransE效果明显提升。
GCN与JAPE使用不同量的训练数据
用预对齐实体作为种子,直觉上训练样本越多,效果应该越好。

图二展示了取10%-50%作为训练集对比Hits@1,JAPE和GCN模型效果,除了图-2(a)中英文训练集超过40%的情况,其它GCN均优于JAPE。
总结和未来工具
GCN方法使用了结构和属性三元组,在各个数据集上表现都较好。
未来将探索更多基于GCN的方法,比如 Relational GCNs, Graph Attention Networks;以及在文中框架上迭代地发现新的实体对齐。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)