
史上最全八大排序讲解时间复杂度篇(0基础都能看懂)
1.冒泡排序冒泡排序的基本原理对存放原始数组的数据,按照从前往后的方向进行多次扫描,每次扫描都称为一趟。当发现相邻两个数据的大小次序不符合时,即将这两个数据进行互换,如果从小大小排序,这时较小的数据就会逐个往前移动,好像气泡网上漂浮一样。冒泡排序的特点:升序排序当中每一轮比较会把最大的数沉到最底(这里以从小到大为例),所有相互比较的次数每一轮会比前一轮少一次。冒泡排序的时间复杂度:O(n^2)O(
1.冒泡排序
冒泡排序的基本原理
对存放原始数组的数据,按照从前往后的方向进行多次扫描,每次扫描都称为一趟。当发现相邻两个数据的大小次序不符合时,即将这两个数据进行互换,如果从小大小排序,这时较小的数据就会逐个往前移动,好像气泡网上漂浮一样。
冒泡排序的特点:
升序排序当中每一轮比较会把最大的数沉到最底(这里以从小到大为例),所有相互比较的次数每一轮会比前一轮少一次。
冒泡排序的时间复杂度:O(n^2)
O(N)和真实的计算时间成正比
从前到后执行一轮要n次,O(N) N指的是数据的规模.
2.插入排序
基本原理
插入排序(英语:Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
以下动图为实例
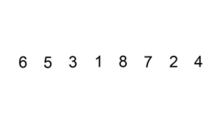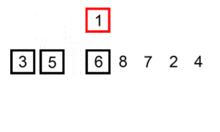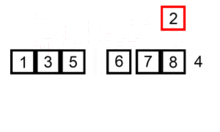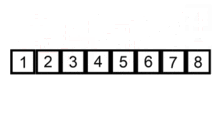
插入排序的时间复杂度:O(N^2)
一个数插入平均需要 O(二分之N),但是常数可以省略
插入排序的缺点: 后面的数值越小,我们需要移动的次数越多,进而影响整个程序
3.希尔排序
希尔排序的基本思想
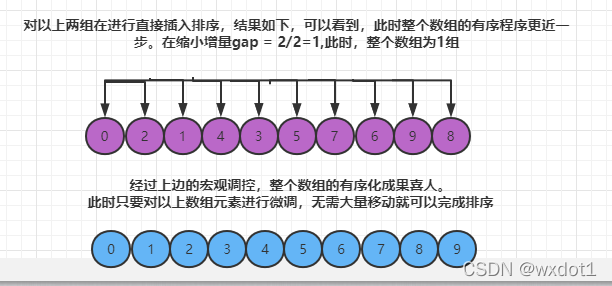
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量主键递减,每组包含的关键词也来越多,当增量减至1时,整个文件恰被分成一组,算法终止。如下图:

希尔排序时间复杂度:O(N log(N))
小tips:循环减半log(n)
希尔排序又叫缩小增量排序,把所有的数据进行分组,在组内进行排序,小数据往前走,大数据往后早,不断缩小组的间距。
分组的间隔:一般为数组长度的一半
4.选择排序
基本操作:
选择排序(select sorting)也是一种简单的排序方法。
它的基本思想是:第一次从arr[0到]arr[n-1]中选取最小值,与arr[0]交换,第二次从arr[1]到arr[n-1]中选取最小值,与arr[1]交换,第三次从arr[2]到arr[n-1]中选取最小值,与arr[2]交换,…,第i次从arr[i-1]arr[n-1]中选取最小值,与arr[i-1]交换,…, 第n-1次从arr[n-2]~arr[n-1]中选取最小值,与arr[n-2]交换,总共通过n-1次,得到一个按排序码从小到大排列的有序序列。
动态图:

简单选择排序 时间复杂度:O(N LOG(N))
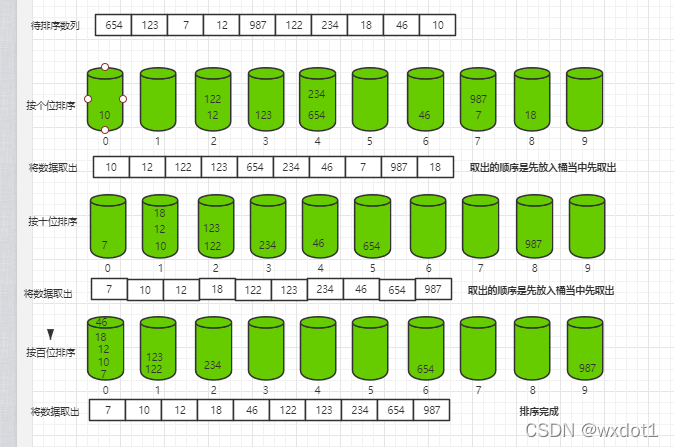
5.基数排序
基本思想
基数排序是桶排序的扩展,他的基本思想是:将整数按位切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的位数长度,数位较短的数前边补零。然后,从最低位开始,依次进行一次排序,这样从最低位排序一直到最高位排序完成后,就变成一个有序数列。

基数排序详解太过繁琐,详细可见本人详解基数排序博客
基数排序时间复杂度:O (kn)
6.快速排序
基本思想
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
算法描述
快速排序使用分治法来把一个串(名单)分为两个子串(子列表)具体算法描述如下:
- 会把数组当中的一个数当成基准数
- 一般会把数组中最左边的数当成基准数,然后丛两边进行检索。丛右边检索比基准数小的,
然后左边检索比基准数大的。如果检索到了,就停下,然后交换这两个元素,然后继续检索。
第一步是基本算法
动态图:(这里的数据是经过特殊处理的)
①:首先找到一个基准数 temp = 5
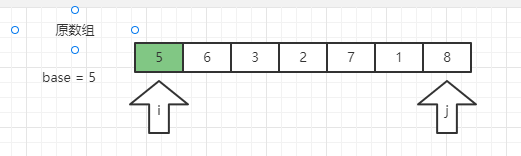
②:先移动右边的 指针 j ,找到第一个小于 5 的数 也就是 1
·· 然后在移动 执行 i ,找到第一个大于 5 的数 也就是 6
然后进行交换
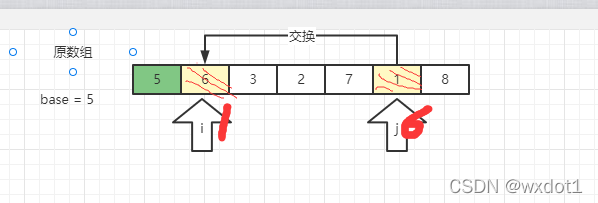
③:i 和 j 一旦相遇,就停止检索 。 把基准数和相遇位置为树进行交换

④:第一次排序完毕,排序完成以后我们会发现排序的左边比基准数小,右边比基准数大

这里是我们第一次排序的代码
一次排序需要 O(N) 它需要多少次呢,循环减半的过程 所以是log(n)
快速排序的时间复杂度:O(nLog(n))
7.归并排序
基本思想
归并排序就是递归得将原始数组递归对半分隔,直到不能再分(只剩下一个元素)后,开始从最小的数组向上归并排序。
- 将一个数组拆分为两个,从中间点拆开,通过递归操作来实现一层一层拆分。
- 从左右数组中选择小的元素放入到临时空间,并移动下标到下一位置。
- 重复步骤2直到某一下标达到尾部。
- 将另一序列剩下的所有元素依次放入临时空间。
- 将临时空间的数据依次放入原数据数组。
归并排序时间复杂度:O(N LOG(N))
8.堆排序
基本思想
1):将带排序的序列构造成一个大顶堆,根据大顶堆的性质,当前堆的根节点(堆顶)就是序列中最大的元素
2):将堆顶元素和最后一个元素交换,然后将剩下的节点重新构造成一个大顶堆;
3):重复步骤2,如此反复,从第一次构建大顶堆开始,每一次构建,我们都能获得一个序列的最大值,然后把它放到大顶堆的尾部。最后,就得到一个有序的序列了
堆排序太过复杂,在本篇不详细介绍,本人其他博客有详细阐述堆排序以及基数排序的文章
时间复杂度:O(n log(n))

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)