
RPA for Python(tagui)避坑指南 - 以咸鱼之王为例
文章目录前言initclick 点击函数snap 截图函数read ocr函数结语前言这两天测试使用了一下RPA for Python (以下简称pytagui,本质上就是用的tagui的库进行了封装)https://github.com/tebelorg/RPA-Python这个库,正好最近在玩阿B推广的咸鱼之王,就用pytagui做了个挂机值守小程序青春版。就根据这个小程序来说一下pytagu
前言
这两天测试使用了一下
RPA for Python (以下简称pytagui,本质上就是用的tagui的库进行了封装)
https://github.com/tebelorg/RPA-Python
这个库,正好最近在玩阿B推广的咸鱼之王,就用pytagui做了个挂机值守小程序青春版。就根据这个小程序来说一下pytagui系统操作的简单用法。
init
pytagui的第一步就是要初始化。chrome的初始化需要你用到神奇的上网方法,如果你Init失败可以看一下我的上一篇文章看看能不能解决。用到系统操作我们需要把r.init(visual_automation = True)这个参数设置为True。
需要注意的是本地操作需要安装JAVA,我是根据他提示的错误代码安装了Amazon Corretto这个版本的JAVA。
click 点击函数
init完就来看看他的点击函数。
| Function | Parameters | Purpose |
|---|---|---|
| click() | element_identifier (or x, y using visual automation) | left-click on element |
| rclick() | element_identifier (or x, y using visual automation) | right-click on element |
| dclick() | element_identifier (or x, y using visual automation) | double-click on element |
| hover() | element_identifier (or x, y using visual automation) | move mouse to element |
根据官方的解释呢,这个函数就是左键点击一下,其他的也好理解,右键点击、双击、移动鼠标,几个都接收一样的参数。输入的参数可以有两种,一种是x, y,一种是这个element_identifier。那X,Y好理解,就是需要他点击的坐标。(坐标可以通过微信的截图窗口快速获取。)

那我们来看一下这个element_identifier是什么东西?他有三种,分别用于不同的情况。
①在Chrome操作模式中,element_identifier就是爬虫中的选择器,这篇咱们就不说了。
②他可以是一个软件组件的图片。简单来说就是按键精灵中的模式匹配,从屏幕中找到你给他的图片,然后他帮你点这个图片的位置的中心。
③他可以是一个软件窗口的图片。用在snap和read里面,用于指定截图的范围,咱们后面讲到这两个函数再细说。
具体使用:
这个游戏每隔20级可以在这个位置领取一个奖励,没领的话会被覆盖掉。

所以我截取了一下可以领取的时候的图片,将这个图片作为参数传递给click,他就可以自动帮你识别并点击收取了

r.click('find.png')
就这么简单,但这里有一点需要注意的~传入的图片必须要是英文名的,如果你传入一个中文的路径,那你就和得到下面这个错误。这里我发现了这个库的第二个大问题(第一个是环境配置太麻烦了):对中文完全没有支持,包括后面的ocr也是一样的。
[RPA][ERROR] - ‘utf-8’ codec can’t decode bytes in position 39-40: invalid continuation byte
我用下来感觉这个库的第三个大问题是:这个库的点击运行效率有点慢,我们在按键精灵里面点击经常需要在后面加个等待。这个库不用,你把两个点击事件直接放在一起,会发现两次点击的间隔在1秒左右。不过我也不是要作弊,只是要让他做值守而已,点击慢对我来说不是问题。
snap 截图函数
这个函数式我唯一觉得他给我小惊喜的地方了。
| Function | Parameters | Purpose |
|---|---|---|
| snap() | element_identifier (page = web page), filename_to_save | save screenshot to file |
函数介绍很明确,就是给你截图用的,具体来说怎么截呢?
你可以输入一个界面的框,他会帮你匹配这个框,然后帮你截这个输入图片的大小。
比如,你可以先回去看一下上面的咸鱼之王的界面,
接下来我给你看一下我输入的参数

r.snap('win.png', 'get/{}.png'.format(time.time()))
然后我能得到这样一个结果:

这样你就能很清楚他设定这个函数的目的了,就是为了帮你保存一些没办法文字化的界面和图片。比如他的实例里面用了PDF软件的框,你就可以调用这个函数截取PDF里面的内容了。和click一样,图片路径依然只能使用英文+数字。
read ocr函数
当我测试了这个函数后,我就彻底放弃这个库了。这个ocr功能原本是这个库唯一的亮点(别的功能按键精灵都能实现。。。不过我很久没用按键精灵了,估计现在也可以实现OCR了。),但是呢,这个OCR不支持中文!

当你read上面这个图片时,你得到的是:
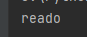
额还算靠谱吧。

当你read上面这个图片时,你得到的是:
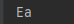
???
多测试了几次我发现,这个OCR库应该压根没有训练中文。毕竟他连中文路径都不支持。。
剩下的其他函数都挺好理解,大家可以自己测试一下。
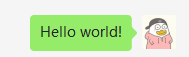
r.init(visual_automation=True, chrome_browser=False)
r.click('weixin.png')
r.keyboard('Hello world!')
r.keyboard('[enter]')
结语
晚上刚刚看到尤大在知乎上的回答,对自己作为一个伸手党有了较大的反省。开源本身就是一件很了不起的事,开源用户不该把自己定位成客户对库指手画脚,如果你真的对一个库有很深的感情,那你就应该让他变得更好。但是这个库可能确实不太适合国内的朋友们使用,标题的写的避坑的意思就是大家如果急用的话可以研究点别的库,不用一直盯着这个库就是。说来RPA这个概念真的是新瓶装旧酒,这些功能按键精灵不是都能做的更好吗?可能没用到的爬虫和不能用的OCR才是RPA的精髓吧,有兴趣的朋友可以外接一个中文的OCR库,应该还是能挺快上手的这个库。我是llsxily,你可以叫我橘子。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)