《kaldi语音识别实战》阅读笔记:单音素模型训练—train_mono.sh解析
第一阶段:模型初始化gmm-init-monoInitialize monophone GMM.Usage: gmm-init-mono <topology-in> <dim> <model-out> <tree-out>e.g.:gmm-init-mono topo 40 mono.mdl mono.tree将topo文件和声学特征维度作为输入,则
一、使用说明
1.1 描述
训练单音素模型。
steps/train_mono.sh
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>
main options (for others, see top of script file)
--config <config-file> # config containing options
--nj <nj> # number of parallel jobs
--cmd (utils/run.pl|utils/queue.pl <queue opts>) # how to run jobs.
<data-dir>:输入训练数据路径数据的路径。
<lang-dir>:输入语言目录的路径。
<exp-dir>:输出模型目录的路径,一般为exp/mono。
aishell调用实例

1.2 步骤
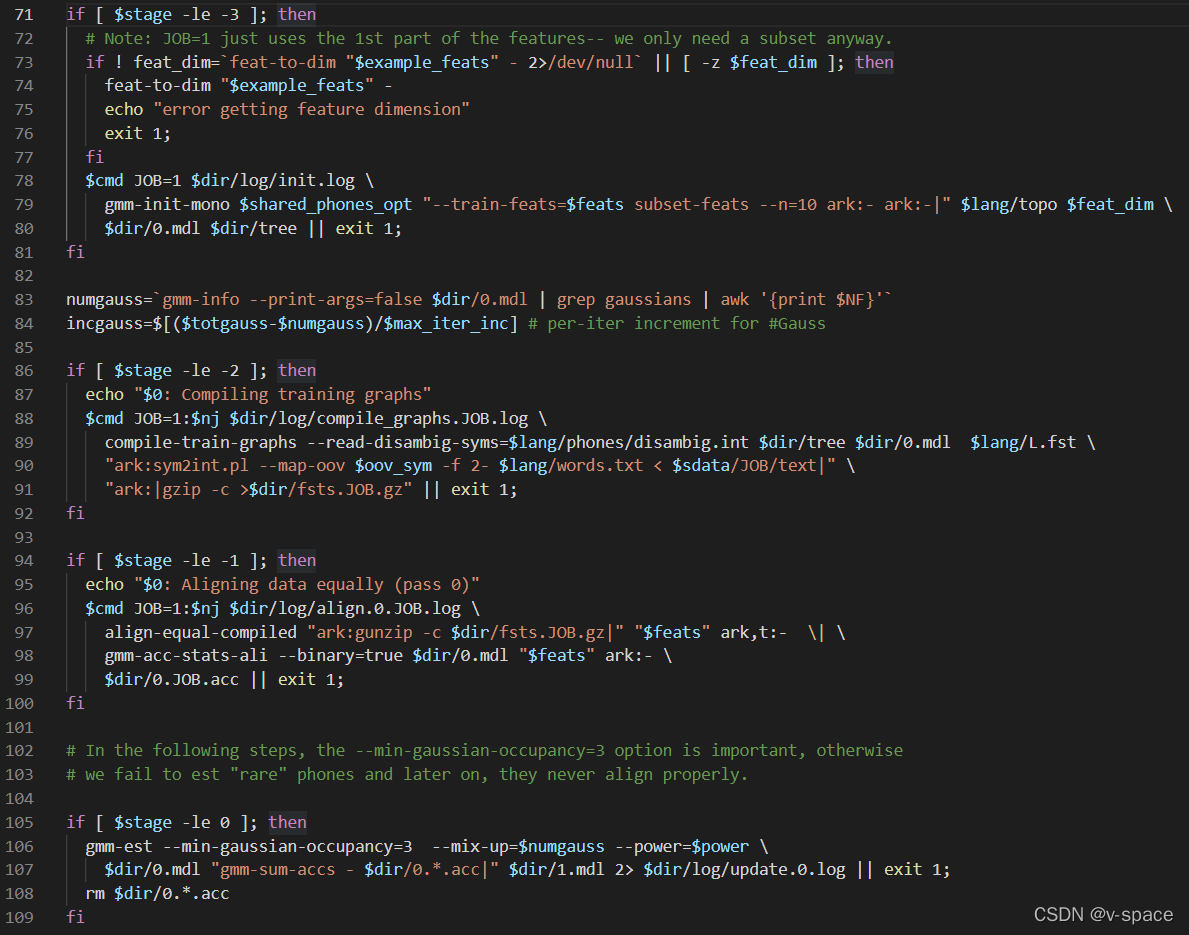
# 初始化,[topo feats] -> [0.mdl tree]
gmm-init-mono
# 生成训练图,[0.mdl text l.fst] -> [train.fst]
compile-train-graph
# 对标签进行初始化对齐[train.fst feats 0.mdl tree] -> [1.ali]
## 初始对齐时将训练样本按状态个数平均分段
align-equal-compiled
# 统计估计模型所需统计量,[feats 1.ali] -> [1.acc]
gmm-acc-stats-ali
# 参数重估,估计新的模型 [1.acc] -> [1.mdl]
gmm-est
# 迭代训练
for i < iteration
# 重新统计所需统计量,[$i.ali] -> [$i.acc]
gmm-acc-stats-ali
# 估计新的模型,[$i.acc] -> [$i.mdl]
gmm-est
# 重新对齐,[train.fst $i.mdl] ->[$i+1.ali]
## 迭代时候对齐由于已经有可用地模型来生成更准确地对齐结果
## 因此此时使用维特比算法生成对齐结果。
gmm-align-compiled
# 输出最后的模型
final.mdl = $i.md
实例
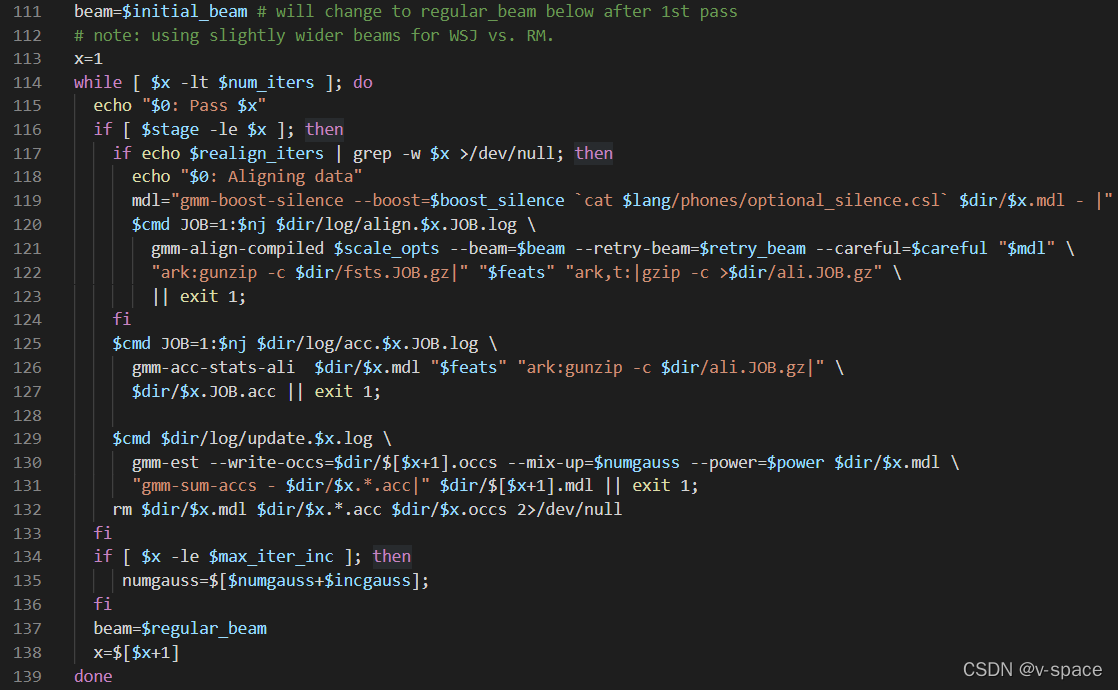
训练时gmm-est进行高斯分量的分裂,可通过totgauss来控制最大高斯分量个数。
二、部分阶段详细介绍
2.1 模型初始化
gmm-init-mono
Initialize monophone GMM.
Usage: gmm-init-mono <topology-in> <dim> <model-out> <tree-out>
e.g.: gmm-init-mono topo 40 mono.mdl mono.tree
将topo文件和声学特征维度作为输入,则会生成初始声学模型。不需要输入任何训练数据,进初始化一个基础模型。且生成的模型中每个状态只有一个高斯分量。后续训练会将单高斯分量分裂为多高斯分量。
其中1.3中,--shared-phones可以让某些音素共享相同的pdf,默认为空。--train-feats可以提供也可以不提供,如果提供,则可以让模型利用训练数据来统计其均值和方差使得初始化模型的参数有一个更好的训练起点。
2.2 训练
包括初始的构图、对齐、更新参数,迭代的对齐、更新参数。
介绍三个工具:
gmm-align
gmm-align
Align feature given GMM-based models.
Usage: gmm-align [options] tree-model-in lexicon-fst-in feature-rspecifier transcroptions-rspecifier alignments-wspecifier
e.g.:
gmm-align tree 1.mdl lex.fst scp:train.scp 'ark:sym2int.pl -f 2- words.txt text|' ark:1.ali
根据输入的声学模型及对应的Tree和L.fst文件,将声学特征和文本进行对齐,并声称ALI文件。
其中kaldi提供gmm-align-compiled工具,是gmm-align的简化版,其使用预先构建好的对齐状态图,而gmm-align在线构建对齐状态图。
gmm-acc-stats-ali
gmm-acc-stats-ali
Accumulate stats for GMM training.
Usage: gmm-acc-stats-ali [options] <model-in> <feature-rspecifier> <alignments-rspecifier> <stats-out>
e.g.: gmm-acc-stats-ali 1.mdl scp:train.scp ark:1.ali 1.acc
输入初始模型、训练数据及对应的对齐结果,输出用于GMM参数更新的ACC文件。ACC文件储存了GMM在EM训练中需要的统计量。
gmm-est
用来更新GMM参数得到新模型,完成一次迭代。
如有问题或建议欢迎私信。
严禁私自转载,侵权必究
参考:
[1] 《kaldi语音识别实战》[book]
[2] kaldi HMM-GMM全部训练脚本分解 [博客园]

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)