数据库面试题汇总
1、SQL 中 on 条件与 where 条件的区别数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。在使用 left join 时,on 和 where 条件的区别如下:1)on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。2)where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 l
1、SQL 中 on 条件与 where 条件的区别
- 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
- 在使用 left join 时,on 和 where 条件的区别如下:
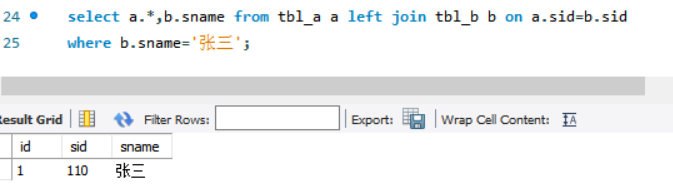
1)on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
2)where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
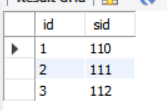
tbl_a
| id | sid |
|---|---|
| 1 | 110 |
| 2 | 111 |
| 3 | 112 |
 | |
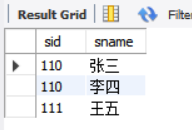
| tbl_b |
| sid | sname |
|---|---|
| 110 | 张三 |
| 110 | 李四 |
| 111 | 王五 |
 |
select a.*,b.sname from tbl_a a
left join tbl_b b on a.sid=b.sid
where b.sname='张三';

select a.*,b.sname from tbl_l a
left join tbl_b b on a.sid=b.sid and b.sname='张三';
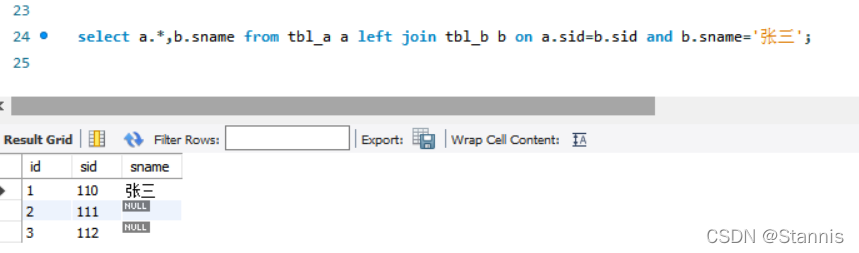
总结: 其实以上结果的关键原因就是 left join,right join,full join 的特殊性。
- 不管 on 上的条件是否为真都会返回 left 或 right 表中的记录,full 则具有 left 和 right 的特性的并集。
- 而 inner jion 没这个特殊性,则条件放在 on 中和 where 中,返回的结果集是相同的。
2、拉链表的原理
参照该文章内容
3、今天想截取截止到昨天的历史数据,条件怎么设置
4、数据库三范式
- 第一范式(确保每列保持原子性)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。
第一范式的合理遵循需要根据系统的实际需求来定。比如某些数据库系统中需要用到“地址”这个属性,本来直接将“地址”属性设计成一个数据库表的字段就行。但是如果系统经常会访问“地址”属性中的“城市”部分,那么就非要将“地址”这个属性重新拆分为省份、城市、详细地址等多个部分进行存储,这样在对地址中某一部分操作的时候将非常方便。这样设计才算满足了数据库的第一范式。
- 第二范式(确保表中的每列都和主键相关)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
比如要设计一个订单信息表,因为订单中可能会有多种商品,所以要将订单编号和商品编号作为数据库表的联合主键。
- 第三范式(确保每列都和主键列直接相关,而不是间接相关)
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
比如在设计一个订单数据表的时候,可以将客户编号作为一个外键和订单表建立相应的关系。而不可以在订单表中添加关于客户其它信息(比如姓名、所属公司等)的字段。
5、truncate、delete 与 drop 区别?
- 相同点
1、truncate和不带where条件的delete、以及drop都会删除表内数据
2、drop、truncate都是DDL语句,执行后会自动提交 - 不同点
1、truncate和delete只删除数据不删除表结构,drop将删除表的结构被依赖的约束、触发器、索引;
2、一般来说,执行速度:drop>truncate>delete
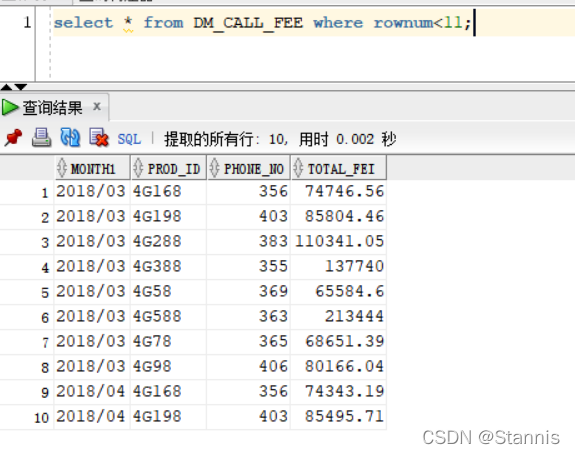
6、怎么取前10条数据
- oracle – rownum
select * from DM_CALL_FEE where rownum<11;
- mysql limit
select * from user_behaviour_data limit 10;

7、存储过程
存储过程
8、什么是内连接、外连接、全连接、笛卡尔积
| 连接 | 描述 |
|---|---|
| 内连接(inner join) | 返回满足条件的数据 |
| 外连接(left\right join) | 除显示两表满足匹配关系的记录,还返回左边或者右边全部 |
| 全连接(full join) | 返回左表和右表所有数据 |
| 笛卡尔积(cross join) | 显示两张表所有记录一一对应,没有匹配关系进行筛选 |
9、什么是代理键?代理键的作用是什么?
10、主键与唯一索引的区别是什么?
- 主键不允许空值,唯一索引允许空值
- 主键只允许一个,唯一索引允许多个
- 主键产生唯一的聚集索引,唯一索引产生唯一的非聚集索引
11、如何给表person创建视图v_person并给user1用户赋查询权限,如何给一赋权视图v_person收回user1用户查询权限。
| c_name | v1 | v2 |
|---|---|---|
| beijing | 001 | 100 |
| shanghai | 002 | 90 |
12、编写一个函数实现对于某人年龄的精确计算,入参为某人的出生年月日(birthday)和当前日期(nowdate)
13、已知有三个表:
student(stu_no,stu_name)
course(c_no,c_name,teacher)
stu_cou(stu_no,c_no,grade)
- 找出没有选修过“张三”老师授课的所有学生姓名
- 列出A课程成绩比B课程成绩好的同学该门课成绩高的所有学生的学号
- 列出既学过A课程又学过B课程的所有学生姓名
14、当天ETL跑批数据失败怎样来处理这个问题?
15、某保险公司有A B C D E F G一共7个代理人,准备组成两个培训小组进行业务培训,其中第一小组3人,第二组4人,分组需要满足以下条件:
- F必须在第二组
- C和E至多有一个在第一组
- A和C不能同组
- 如果B在第一组,则D也必须在第一组
问:如果A在第二组,则哪个代理人也一定在第二组,并写出理由
16、字符串分割函数 SUBSTRING_INDEX
select
SUBSTRING_INDEX(profile,',',-1) as gender,
count(*) as number
from user_submit
group by gender;
17、substring_index()
select
exam_id,
substring_index(tag,',',1) as tag,
substring_index(substring_index(tag,',',2),',',-1) as difficulty,
substring_index(tag,',',-1) as duration
from
examination_info
where duration=0;


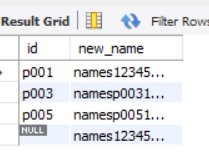
18、char_length()、substr()、concat()
select
id,
if(char_length(names)>13,concat(substr(names,1,10),'...'),names) as new_name
from orders
where char_length(names)>10;

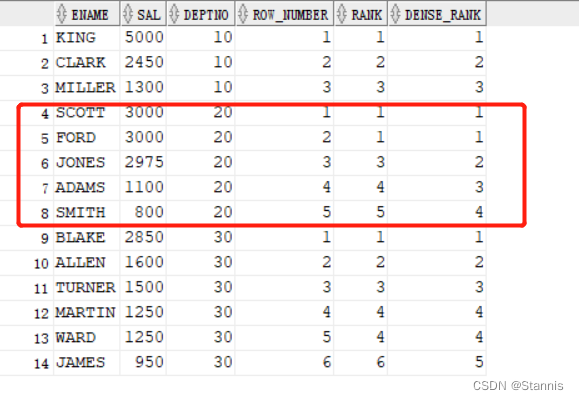
19、row_number()、rank()、dense_rank()
select
ename
,sal
,deptno
,row_number() over(partition by deptno order by sal desc) as row_number
,rank() over(partition by deptno order by sal desc) as rank
,dense_rank() over(partition by deptno order by sal desc) as dense_rank
from emp;
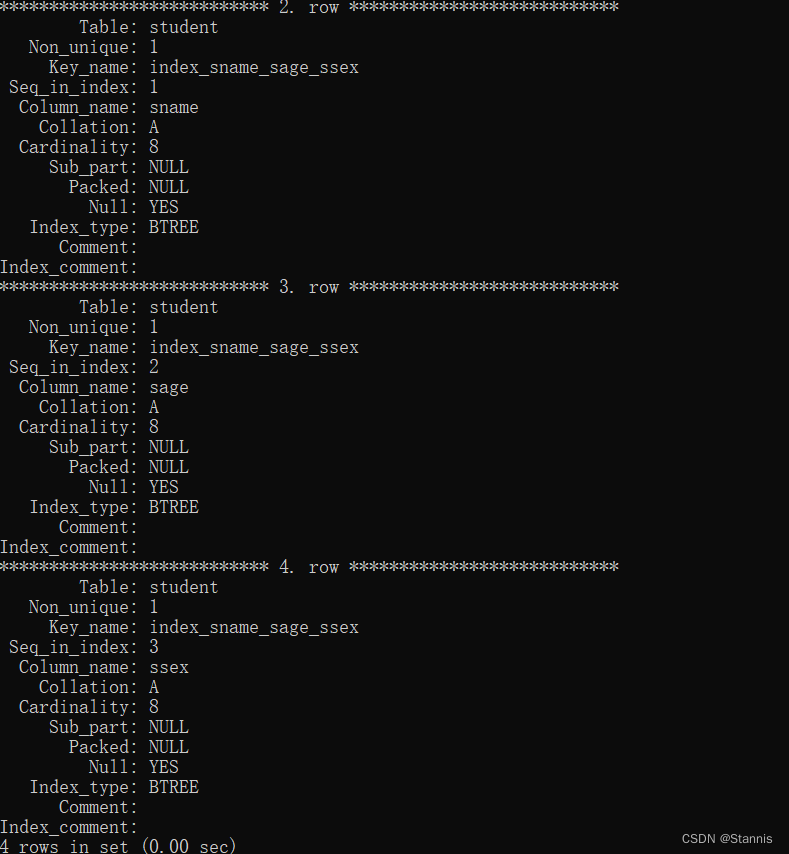
20、复合索引
a、两个或者多个列上的索引
CREATE INDEX indexName ON tableName(columnName1, columnName2, …);
b、复合索引的前导性:在MySQL中,如果创建了复合索引(name, salary, dept),就相当于创建了(name, salary, dept)、 (name, salary)和(name)三个索引,这被称为复合索引前导列特性,因此在创建复合索引时应该将最常用作查询条件的列放在最左边,依次递减。
CREATE INDEX index_sname_sage_ssex ON student(sname,sage,ssex);
SHOW INDEX FROM student;
EXPLAIN SELECT * FROM student WHERE sname='吴兰' AND sage>'1992-03-01 00:00:00' AND ssex='女';
EXPLAIN SELECT * FROM student WHERE sname='吴兰' AND sage>'1992-03-01 00:00:00';
EXPLAIN SELECT * FROM student WHERE sname='吴兰';
21、聚类索引与非聚类索引
- 聚集索引是数据和索引在一起
- 非聚集索引是数据和索引分开的
22、order by,sort by,distribute by,cluster by的区别是什么
参照该文档区别
23、取各部门工资前三的人员信息
- 使用窗口函数
select * from(
select
ename
,sal
,deptno
,row_number() over(partition by deptno order by sal desc) as row_number
,rank() over(partition by deptno order by sal desc) as rank
,dense_rank() over(partition by deptno order by sal desc) as dense_rank
from emp)
where row_number<4;
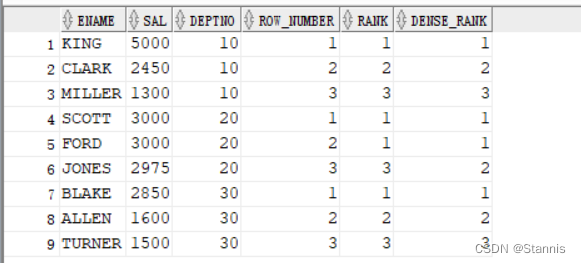
工资相同怎么取值看具体的需求,选择row_number() rank() dense_rank()
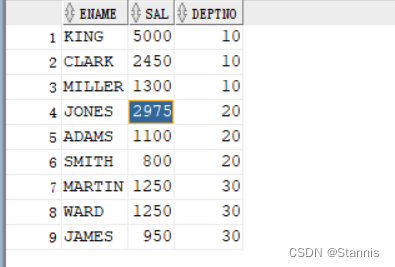
- 不使用窗口函数
select
a.ename
,a.sal
,a.deptno
from emp a
left join emp b on a.deptno=b.deptno and a.sal>=b.sal
group by a.ename
,a.sal
,a.deptno
having count(a.ename)<=3
order by a.deptno,a.sal desc;
24、留存率计算 1 2 3 7天留存率
25、计算用户每天的在线时长

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)