

谷歌浏览器插件Automa(入门,编写中,开专栏填坑中)
一般选择元素的id、name,之后便在表单中选择css selector模式,在指定位置输入[name=‘q’],半角符号,然后选择元素为“文本框”,并在指定位置输入“stack……可以看到这个功能叫做元素选择器,你可以使用它来定位输入框、按钮、又或者一张图片,一个序号,只需点击网页中的任意一个你想点击的位置,它都可以提取出所对应的CSS。,在想要点击处右键,点击检查,这时会弹出网页对应处的htm
谷歌浏览器插件Automa(入门,编写中)
0.待成长的无代码化爬虫
很抱歉在开头就泼你一盆冷水,遗憾地说Automa并不完美,或许是因为其有待成长(每次打开都会发现变了个样),但其所见即所得的体验依旧深深吸引着我。(因edge全局快捷键的完善,我现在从chrome转入到edge)
GitHub文档
官方文档
1快速入门模块
1.1 中文设置
进入插件的控制界面,如图进行操作
1.2 定位你想要操作的位置
这里有两种定位方法:CSS选择器、Xpath选择器
如果你是个编程小白的话则不需要考虑两者的区别,甚至乎高手也不考虑两者的区别,可口可乐和百事可乐的区别只有一群脑残粉互杠。
这里主要介绍css选择器,粗略地介绍,因为插件本身就提供了基于css的人性化定位功能,如图所示:
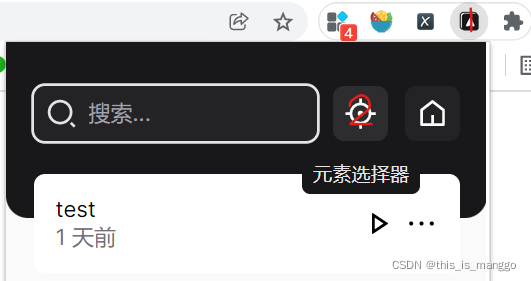
可以看到这个功能叫做元素选择器,你可以使用它来定位输入框、按钮、又或者一张图片,一个序号,只需点击网页中的任意一个你想点击的位置,它都可以提取出所对应的CSS
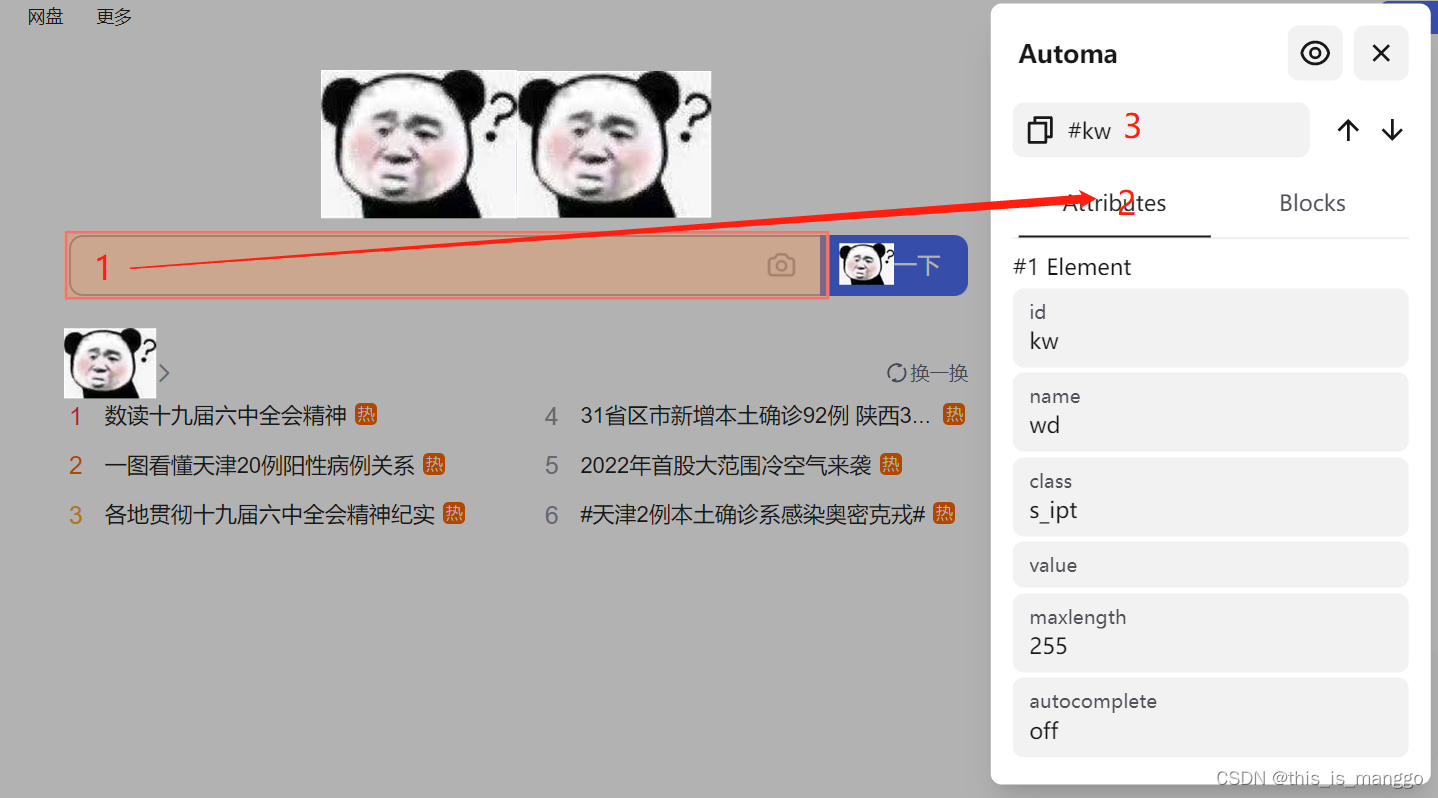
你可以在(组件中的)Element selector中输入#kw,或者[name=‘wd’],总之鲁迅说过,能跑起来就写了,管他那么多干嘛
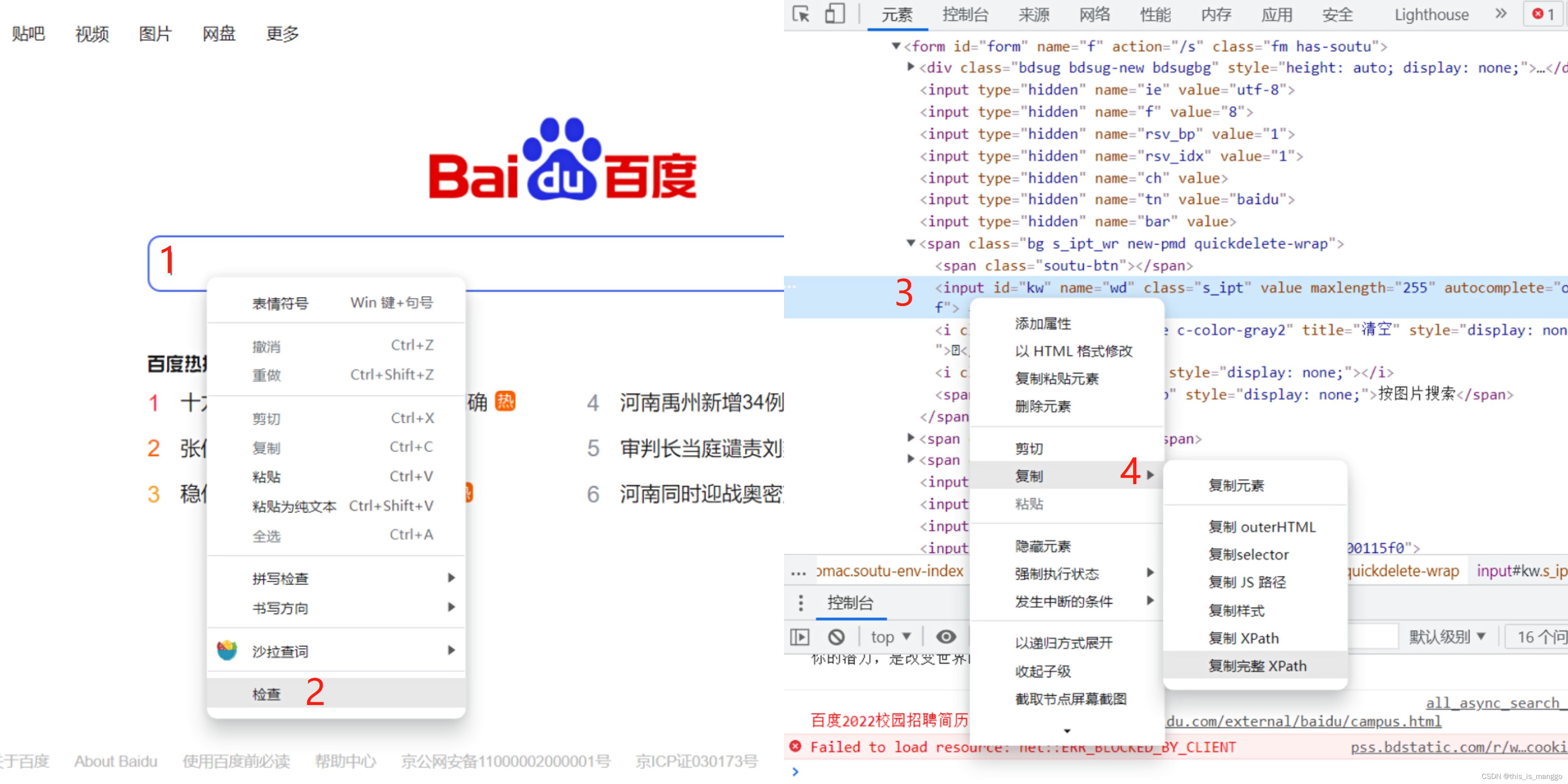
接下来介绍Xpath选择器,点击此处查阅xpath语法,在想要点击处右键,点击检查,这时会弹出网页对应处的html代码,在代码突出显示处右键,复制xpath(经测试,Automa对xpath的多元素支持并不完善)
1.3 进行操作
普通玩家对于组件的操作无非就输入文字,点击控件跳转页面,但高端玩家会为这些操作加上各种限制条件以让其适应各种网页,而这些内容将在进阶篇介绍。
1.3.1 点击
1.找到你要点击的位置
2.定位它(1.2有讲)
3.复制那个位置,粘贴到元素选择器上

1.3.2 输入
首先说一点,在Automa中输入内容是不需要提前选中元素的,使用方法类似与点击,但是多了需要输入的内容。
在HTML代码中,输入框通常放置于form中,而这一部分在程序员的口中被称为表单,所以你需要拖出表单组件,操作如图所示:

1.4 官方案例实战教学
1.4.1 百歌一下
1.首先是触发器,这里选择了手动,即自己去启动爬虫。
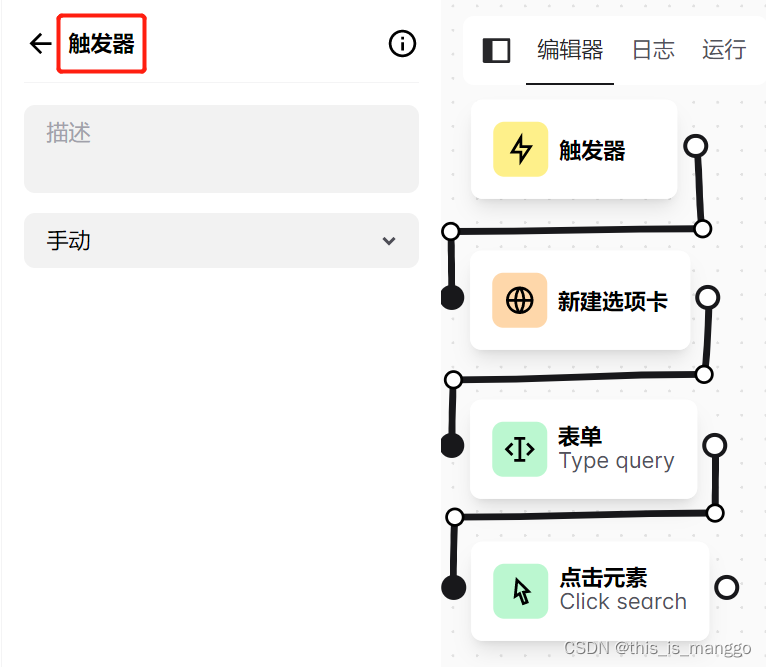
2.其次是打开需要爬取的网页,在指定地方输入网址,需要的可以在“描述”中写注释

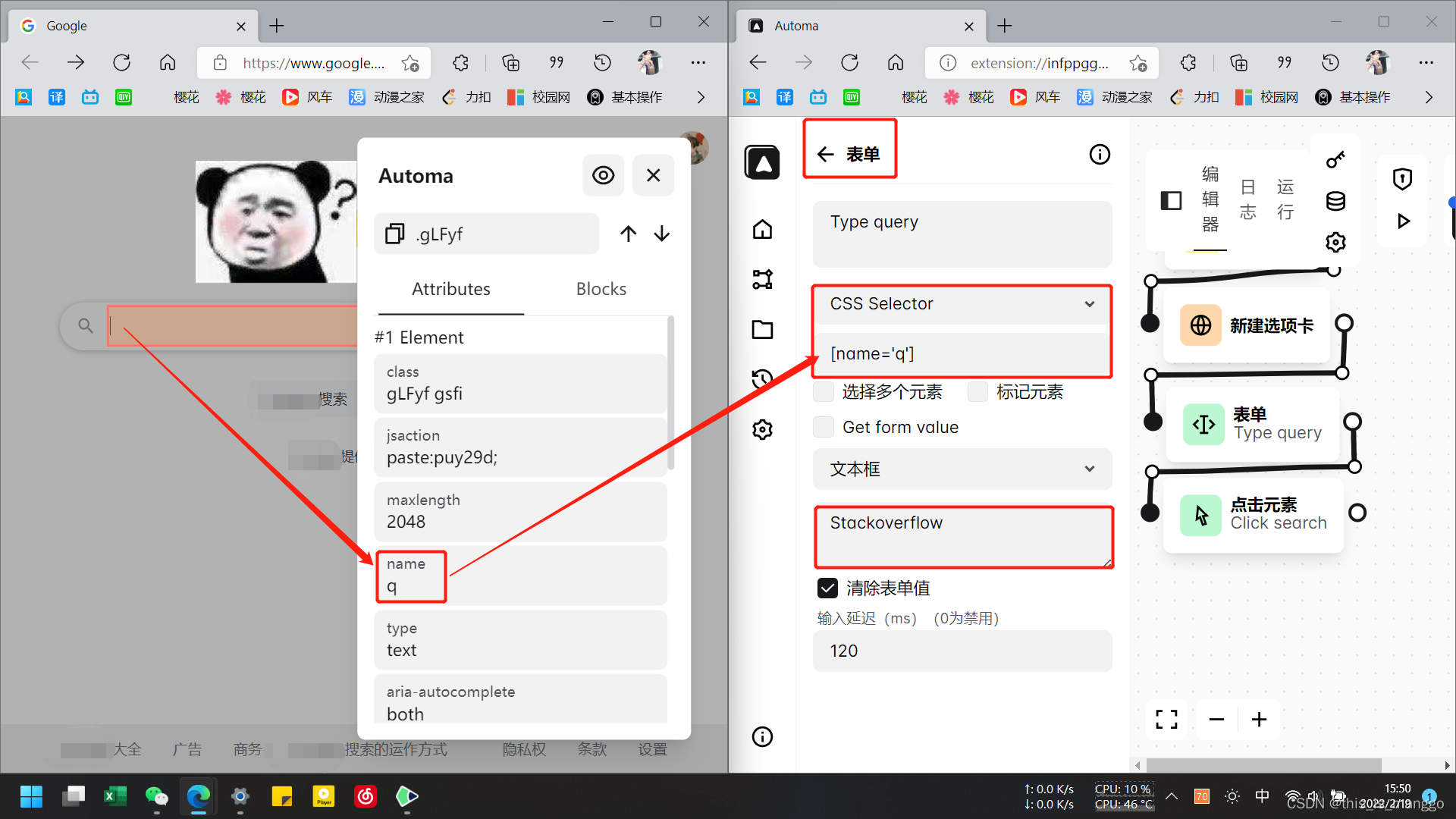
3.接下来便是爬虫中最重要的一步,确定元素,并对其进行操作,这里则对输入框进行输入操作。
一般选择元素的id、name,之后便在表单中选择css selector模式,在指定位置输入[name=‘q’],半角符号,然后选择元素为“文本框”,并在指定位置输入“stack……”(当然你也可以使用xpath)
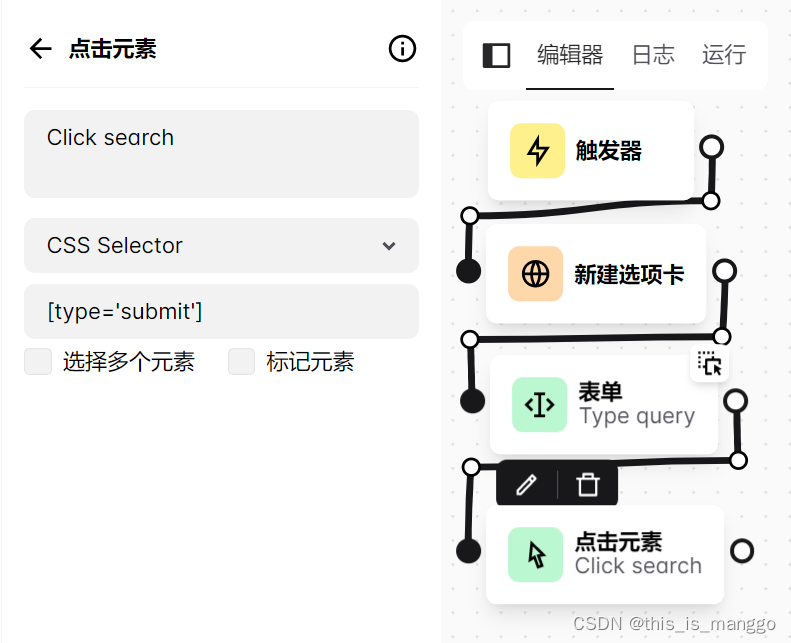
4.最后,由于404网站的搜索按钮被隐藏,这里采取一种比较取巧的方法,默认搜索按钮为[type=‘submit’],绝大部分情况下都可以运行。
5.最后,便是见证自动化的时刻

第一个案例就这样完成了,接下来请尝试一下将这个官方案例修改为“百度一下”
1.4.2 爬取文本
2. 进阶篇(拖更中)
2.1 Automa的变量类型
Automa的变量官方文档:https://github.com/Kholid060/automa/wiki/Features
依照官方文档提供的获取数据的方法,我将Automa的变量分为四种类型:全局键值对、数据列、循环、区块数据。
2.2 判断语句
2.?循环
Automa中有两种循环组件
- Repeat task(循环任务)
- Loop Data(循环数据):Loop Data与Loop breakpoint(循环断点)可以说是必须一起使用,就如同Linux的shell编程一样,循环由for、循环体、end组成。
#Loop Data 的 Loop through(意译:循环条件)
#Data columns(看不懂)
#Numbers(可以控制循环开始位置,但无法调整步长)
for i in range(start,end,1):
循环体
#Google sheets(404谷歌表格)
#Custom data(按照列表的元素循环)
lis=[]
for i in lis:
循环体

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)