2018_IJCAI_DELF: a dual-embedding based deep latent factor model for recommendation
[论文阅读笔记]DELF: a dual-embedding based deep latent factor model for recommendation—(IJCAI, 2018.07.13)-- Weiyu Cheng, Yanyan Shen, Yanmin Zhu, Linpeng Huang论文下载地址:https://doi.org/10.24963/ijcai.2018/462
[论文阅读笔记]2018_IJCAI_a dual-embedding based deep latent factor model for recommendation—(IJCAI, 2018.07.13)-- Weiyu Cheng, Yanyan Shen, Yanmin Zhu, Linpeng Huang
论文下载地址:https://doi.org/10.24963/ijcai.2018/462
发表期刊:IJCAI
Publish time: 13 July 2018
作者单位:上交
数据集:
Movielens 1M https://grouplens.org/datasets/movielens/1m/
Amazon Music http://jmcauley.ucsd.edu/data/amazon/
代码:
本文创新点(个人理解)
本文最大的创新点在于:dual_embedding
1.以前的的模型,用一个user latent embedding 表示用户
本文除了原始的embedding, 还通过uesr rate过的item来表示用户,新增了一个 item-based embedding来表示user.
2.对于item,同user。
Abstract(本文创新点)
1 this paper proposes a dual-embedding based deep latent factor model named DELF for recommendation with implicit feedback.
2 In addition to learning a single embedding for a user (resp. item), we represent each user (resp.
item) with an additional embedding from the perspective of the interacted items (resp. users).
3 We employ an attentive neural method to discriminate he importance of interacted users/items for dual-embedding learning.
4 We further introduce a neural network architecture to incorporate dual embeddings for recommendation
5 A novel attempt of DELF is to model each user-item interaction with four deep representations that are subtly fused for preference prediction
1 Introduction
1 An important challenge of applying latent factor models to implicit feedback based recommendation is: how to learn appropriate embeddings for users and items given scarce negative feedback? Since all the observed interactions are positive implicit feedback, learning user and item embeddings with only positive feedback will result in significant overfitting
2 前人工作的一些不足
3 本文的工作,与Abstract重复,就是解释的更详细了
2 Preliminaries
We consider a user-item interaction matrix R ∈ R M x N R\in R^{MxN} R∈RMxN from users’ implicit feedback, where M M M and N N N are the number of users and items, respectively. R u i = 1 R_{ui} = 1 Rui=1 indicates an interaction between user u u u and item i i i, and R u i = 0 R_{ui}=0 Rui=0 means no interaction is observed.
2.1 Neural Collaborative Filtering
1 Matrix Factorization (MF)
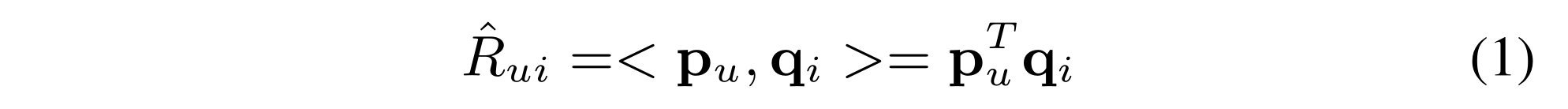
2 Neural Collaborative Filtering (NCF)

Note that the original NCF paper ensembles MLP and MF to obtain the NeuMF model. In this paper, we focus on developing single CF model for recommendation, while the proposed model can be ensembled with other models to achieve better performance.
2.2 NVSD & SVD++
NVSD
1 NSVD [Pa-terek, 2007] models users based on the items they have rated. Formally, each item is associated with two latent vectors
q
i
q_i
qi and
y
i
y_i
yi . The preference score of user
u
u
u to item
i
i
i is estimated as:
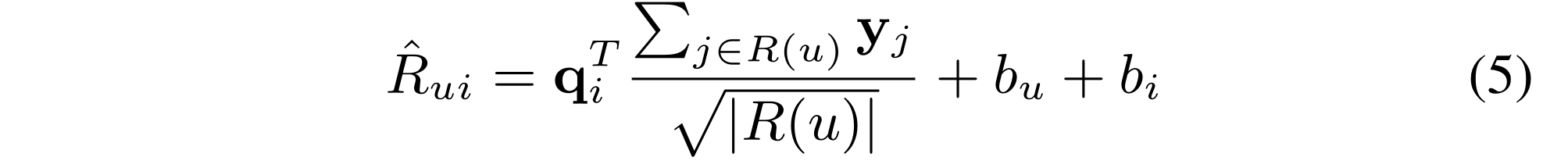
where
R
(
u
)
R(u)
R(u) is the set of items rated by user
u
u
u,
b
u
b_u
bu and b_i are bias terms
2 不足:
the main issue of NSVD is that two users who have rated the same set of items with entirely different ratings are tied to have the same representation
SVD++
SVD++ [Koren, 2008] is proposed for recommendation with explicit ratings, which estimates user-item preferences as follows:
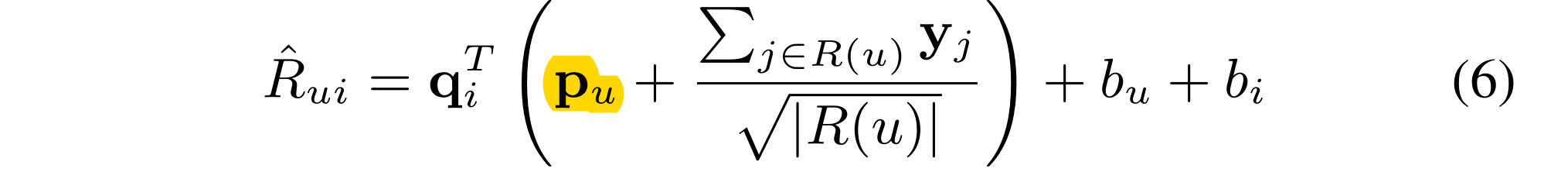
Where
p
u
p_u
pu is a latent factor. SVD++ leverages the NSVD-based representation to adjust the user latent factor rather than represent the user. We observe that NSVD-based latent factors are determined by users’ rated items, which are useful to avoid false negatives from noisy implicit feedback and more robust than explicitly parameterized factors.
3 DELF
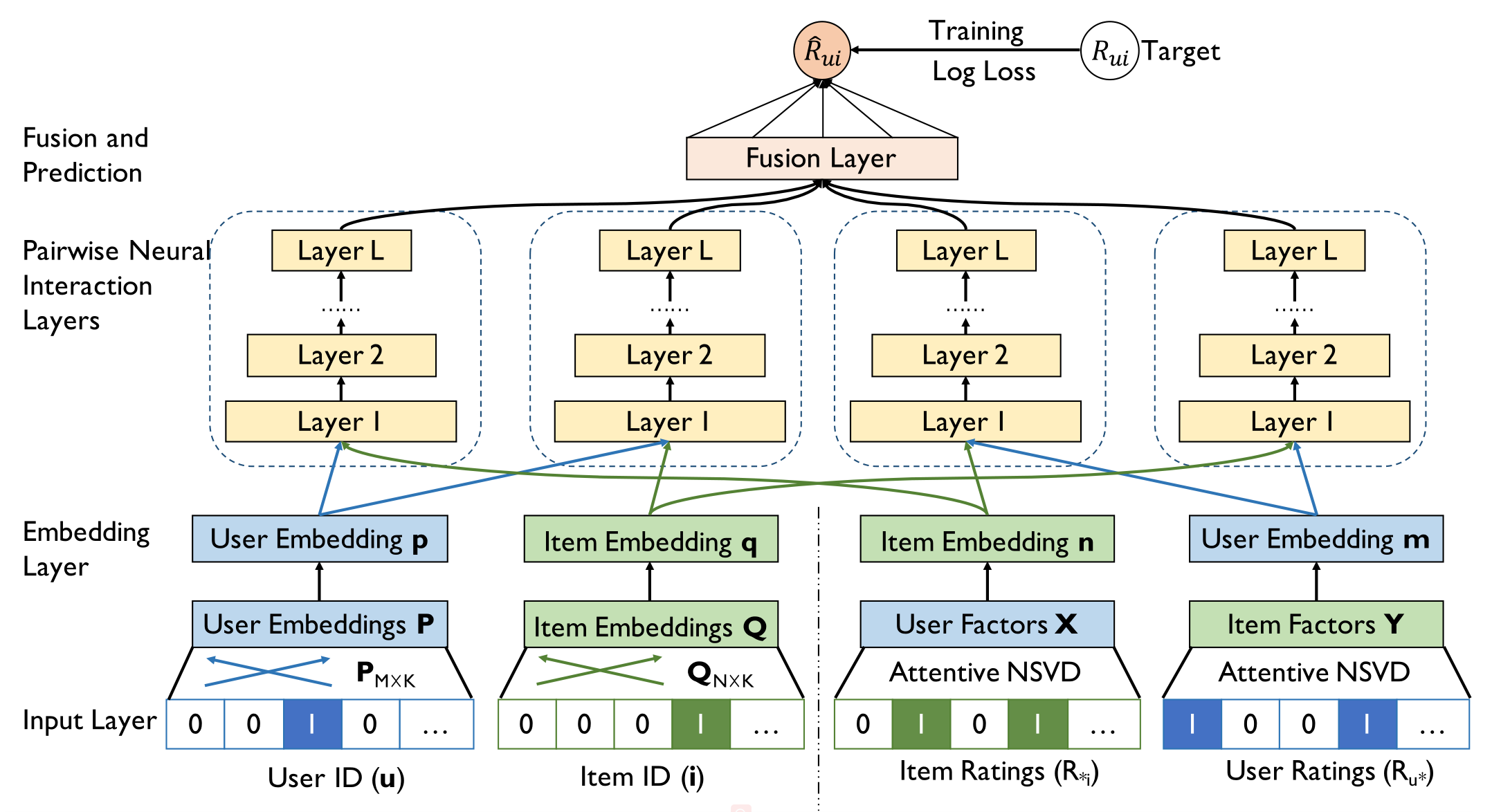
3.1 Model
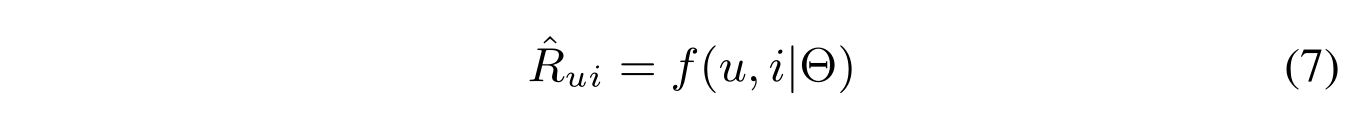
where where
Θ
\Theta
Θ denotes latent factors of
u
u
u and
i
i
i, and f denotes the interaction function. Figure 1 illustrates the design of
T
h
e
t
a
Theta
Theta and
f
f
f in DELF,
Input Layer
(1) Single-embedding based latent factor models simply associate u and i with their one-hot representations
u
u
u and
i
i
i.
(2) In addition to the one-hot vectors, DELF also incorporates the binary interaction vectors
R
u
∗
R_{u∗}
Ru∗ and
R
∗
i
R_{∗i}
R∗i from the observed interactions for
u
u
u and
i
i
i, respectively.
Embedding Layer
(1) The embedding layer projects each feature vector from the input layer into a dense vector representation.
(2) The primitive feature vector embeddings (i.e., u and i) can be obtained by referring to the embedding matrix as follows.
P
u
=
P
T
u
(8)
P_u = P^{T}u \tag{8}
Pu=PTu(8)
where
P
∈
R
M
x
N
P\in R^{MxN}
P∈RMxN denotes the user embedding matrix, and
K
K
K is the dimension of user embeddings. Similarly,
q
i
q_i
qi can be
obtained from the item embedding matrix
Q
Q
Q
(3) NSVD averages the factors of rated items to represent a user. However, different items can reflect user preference in different degrees. Therefore, we employ the attention mechanism [Bahdanau et al., 2014] to discriminate the importance of the interacted items automatically, as defined below:
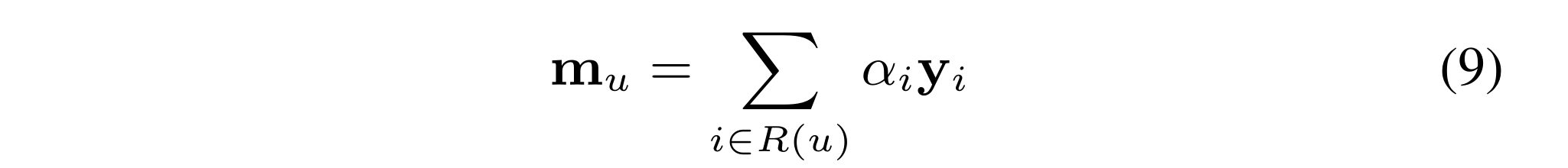
where
m
u
m_u
mu is the item-based user embedding, and
α
i
\alpha_i
αi is the attention score for item
i
i
i rated by user
u
u
u. Here we parameterize the attention score for item
i
i
i by:
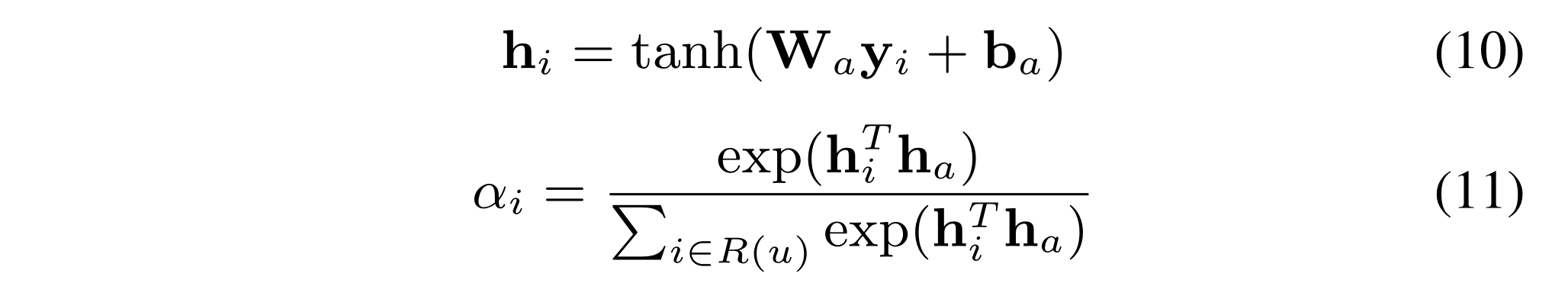
where
W
a
W_a
Wa,
b
a
b_a
ba denote the weight matrix and bias vector respectively, and
h
a
h_a
ha is a context vector.
Pairwise Neural Interaction Layers
(1) Instead of using a single network structure, we model interactions for the two kinds of user/item embeddings separately, and obtain four deep representations for different embedding interactions. Formally,
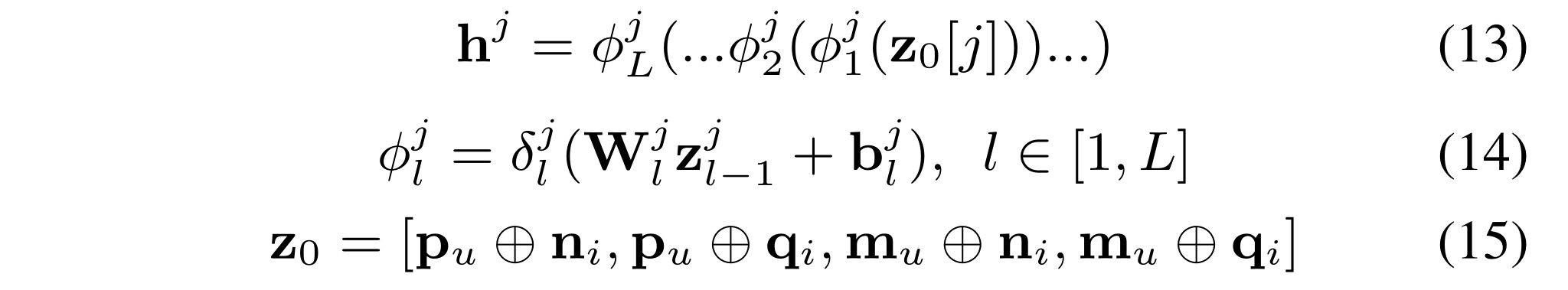
where
j
∈
{
1
,
2
,
3
,
4
}
j\in \{1,2,3,4\}
j∈{1,2,3,4};
h
j
h^j
hj is the deep representation of embedding interaction learned by the
j
−
t
h
j-th
j−thfeedforward neural network;
ϕ
l
j
\phi^j_l
ϕlj is the
l
−
t
h
l-th
l−th layer in network j;
W
l
j
,
W^j_l,
Wlj,
b
l
j
b^j_l
blj,and
δ
l
j
\delta^j_l
δlj denote the weight matrix, bias vector and activation function of layer
l
l
l int network j, respectively;
(2) An insight of DELF is that the primitive and additional embeddings should be of varying importance to the final preference score under different circumstances
(3) Modeling embedding interactions separately avoids two kinds of embeddings from affecting each other and hence may benefit the prediction result.
(4) In DELF, we choose Rectifier ReLU as the activation function by default if not otherwise specified, which is proven to be non-saturated and ields good performance in deep networks [Glorot et al., 2011]
(5) As for the network structure, we follow the setting proposed by [He et al., 2017] and employ a tower structure for each network, where igher layers have smaller number of neurons.
Fusion and Prediction.
We propose two fusion schemes: MLP and an empirical scheme.
(1) For MLP , the combined feature after the fusion layer is formulated as:
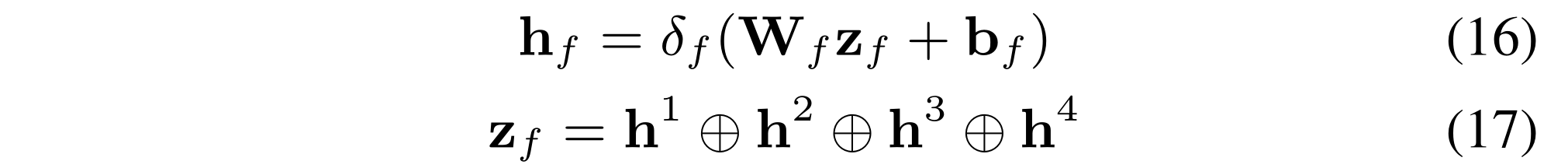
where
W
f
W_f
Wf,
b
f
b_f
bf,
δ
f
\delta_f
δf are the weght matrix, bias vector and activation function, respectively;
z
f
z_f
zf is the concatenation of four latent interaction representations. We dub this model “DELF-MLP”
(2) The empirical scheme follows our observation that primitive embeddings
p
u
p_u
pu and
q
i
q_i
qi should be less expressive with fewer ratings but yield good performance with enough true instances. Hence, we empirically assign non-uniform weights to four deep representations. ormally, for user
u
u
u and item
i
i
i, we have:
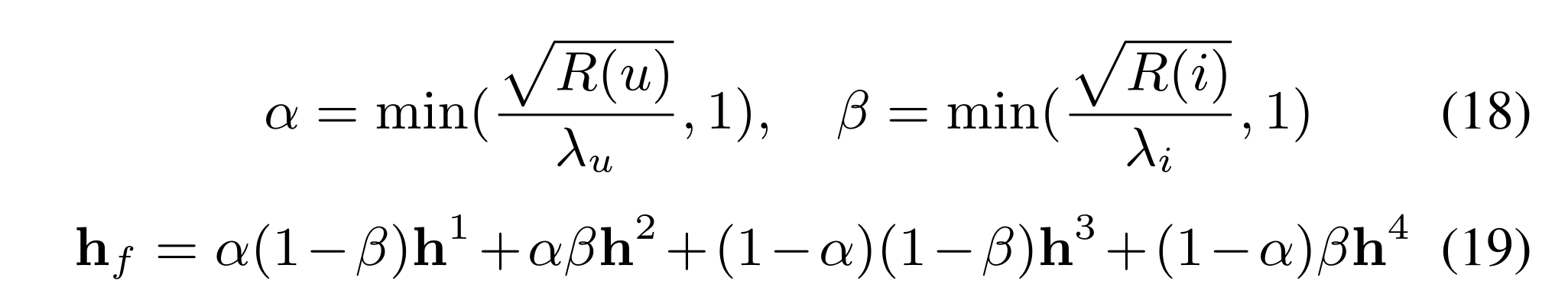
where
λ
u
\lambda_u
λu and
λ
i
\lambda_i
λi are hyper-parameters to be tuned via the validation set.
We dub this model “DELF-EF”.
(3) At last, the output
h
f
h_f
hf of the fusion layer is transformed to the final prediction score:
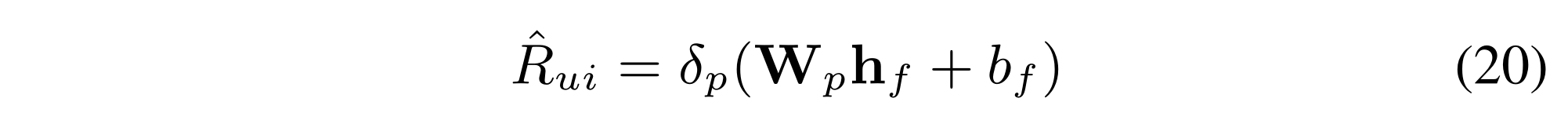
where
W
p
W_p
Wp,
b
f
b_f
bf are the weight matrix and bias term, respectively;
δ
p
\delta_p
δp is the sigmoid function as we expect the prediction score to be in the range of [0, 1].
(4) It is worthy noticing that both NCF and NSVD can be interpreted as special cases of our DELF framework.
(一般一个新的模型,都是在前人模型基础上的扩展,新的模型要包含前人的模型)
3.2 Learning
(1) Both point-wise and pair-wise objective functions are widely used in recommender systems. In this work, we employ point-wise objective function for simplicity and leave the other one as future work.
(2) Due to the one-class nature of implicit feedback, we follow [He et al., 2017] to use the binary cross-entropy loss, which is defined as:
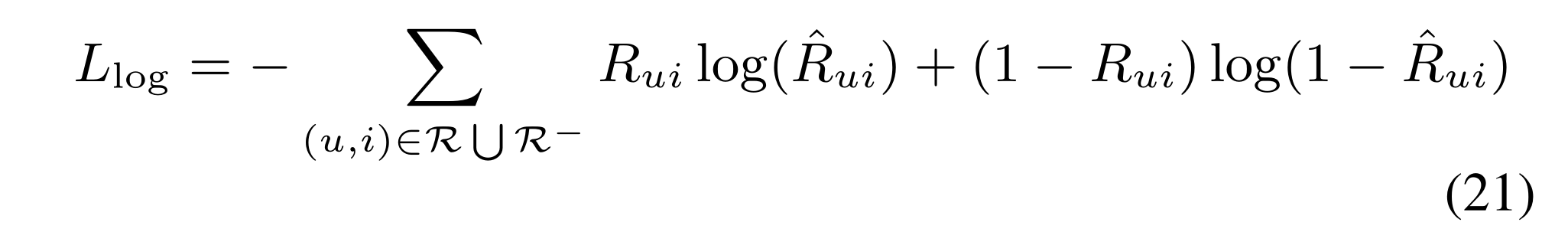
(3) To optimize the objective function, we adopt Adam, a variant of Stochastic Gradient Descent (SGD) that dynamically tunes the learning rate during training process and leads to faster convergence
4 Experiments
4.1 Experiments Settings
Datasets
Movielens 1M1 and Amazon Music2. We transformed both datasets to implicit feedback, where each entry is marked as 0 or 1 denoting whether the user has rated the item.

Evaluation Protocol
(1) we employed the widely used leave-one-out evaluation
(2) we followed the common strategy to randomly sample 100 items that are not interacted with the user.
(3) We used Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG) [He et al., 2015] as metrics. The ranked list is truncated at 10 for both metrics.
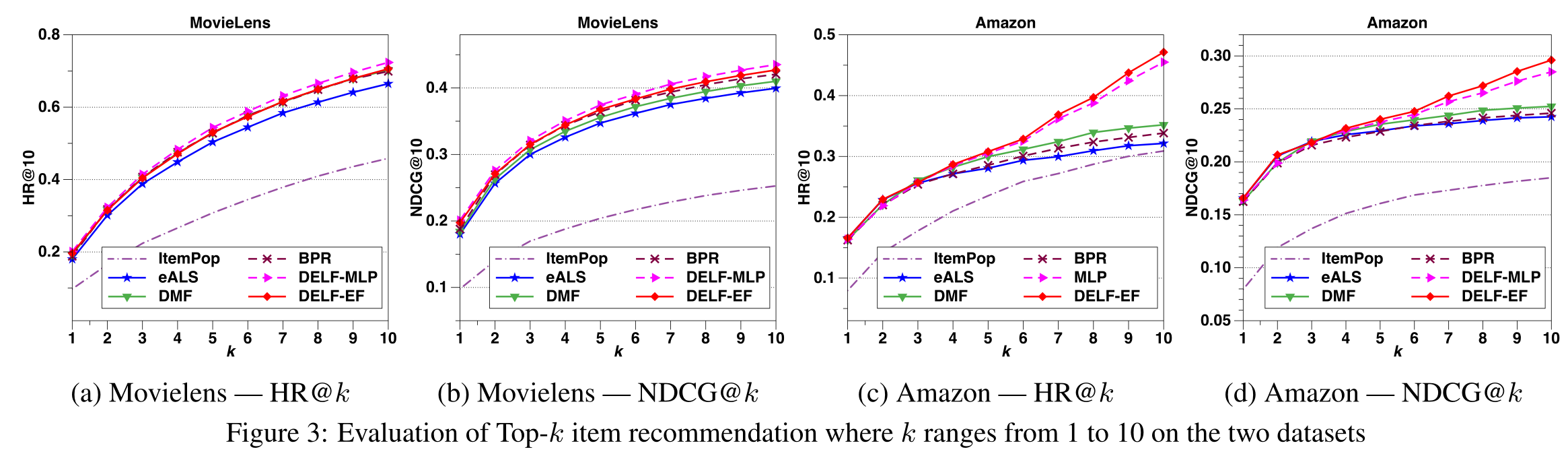
Compared Methods
-ItemPop
-eALS
-BPR
-MLP
-NeuiMF
-DMF
Parameter Settings
4.2 Performance Comparison (RQ1)

4.3 Effects of Key Components (RQ2)
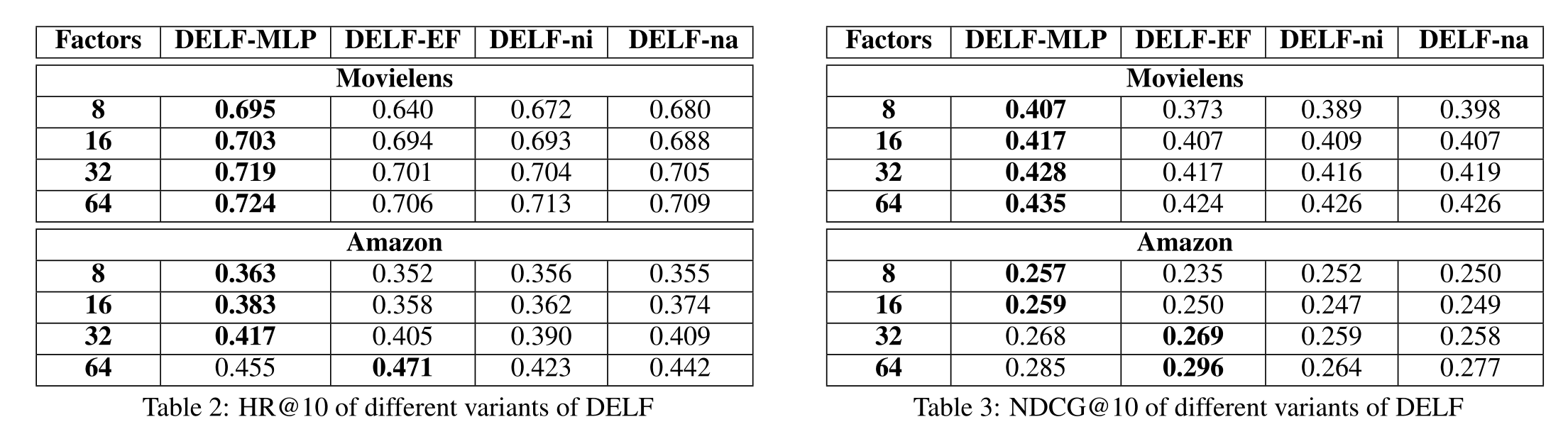
4.4 Hyper-parameter Investigation (RQ3)
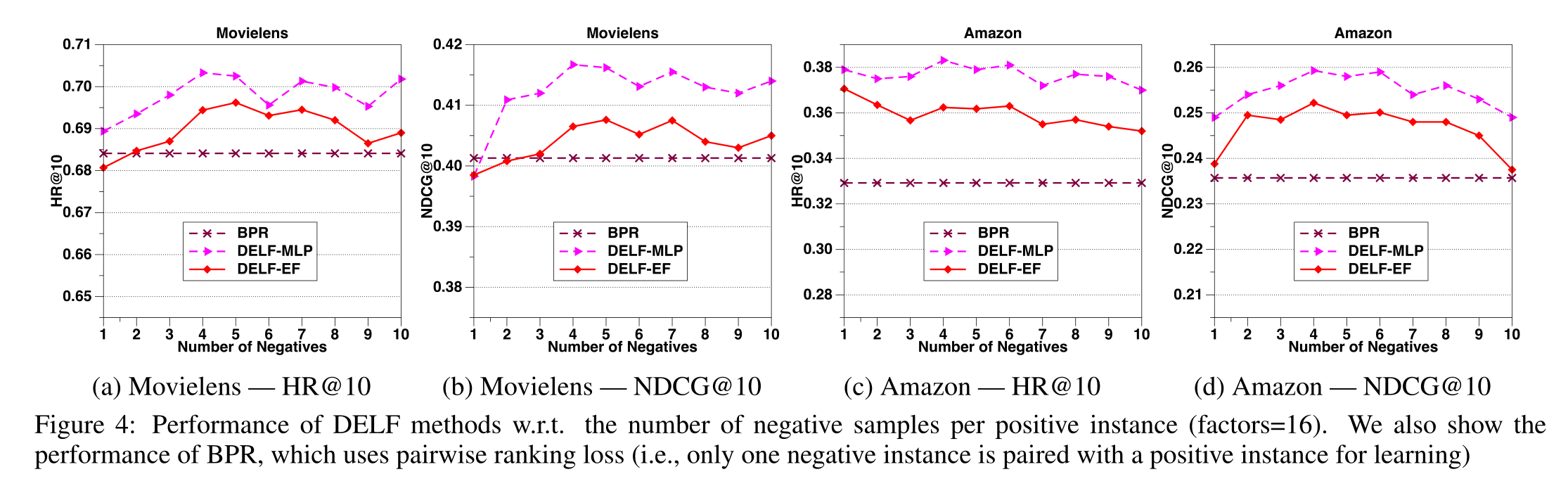
5 Conclusion and Future Work
(1) In this paper, we propose a novel deep latent factor model with dual embeddings for recommendation.
(2) In addition to the primary user and item embeddings, we employ an attentive neural method to obtain additional embeddings for users and items based on their interaction vectors from implicit feedback.
(3) n the future, we plan to extend DELF to incorporate auxiliary information. Auxiliary information such as social relations, user review and knowledge base can be utilized to characterize users/items from different perspectives.
Acknowledgements
Reference

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)