西瓜书 第一章 绪论
第一章绪论1.1 引言 理解机器学习人类的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。1.2 基本术语假设我们收集了一批西瓜的数据,例如:(色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=沉闷), (色泽=浅自;根蒂=硬挺;敲声=清脆)……每对括号内是一个西瓜的记录。**数据集:*
·
1.1 引言 理解机器学习
人类的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
1.2 基本术语
假设我们收集了一批西瓜的数据,例如:(色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=沉闷), (色泽=浅自;根蒂=硬挺;敲声=清脆)……每对括号内是一个西瓜的记录。
- 数据集:这组数据的集合叫做数据集
- 示例/样本:每条记录是关于一个事件或者对象(本书指西瓜)的描述
- 属性/特征:例如:色泽,根蒂,敲声
- 属性值:属性上的取值,例如青绿,沉闷,硬挺
- 属性空间/样本空间/输入空间:属性张成的空间。如果在坐标轴上表示,每个西瓜都可以用坐标轴中的一个点表示。
- 特征向量:每个西瓜都可以用坐标轴中的一个点表示,一个点也是一个向量,例如(青绿,蜷缩,浊响),即每个西瓜为:一个特征向量(feature vector)。因此我们也把一个示例称为一个“特征向量”。
- 维数:一个样本的特征数。例如有 色泽,根蒂,敲声三个特征数,则维数为3。
- 训练样本:计算机程序学习经验数据生成算法模型的过程中,每一条记录称为一个“训练样本”。
- 训练集:训练样本组成的集合。【特殊】
- 测试样本:在训练好模型后,我们希望使用新的样本来测试模型的效果,则每一个新的样本称为一个“测试样本”。
- 测试集:测试样本组成的集合。【一般】
- 分类:预测值为离散值,例如好瓜,坏瓜。
- 回归:预测值为连续值,例如西瓜的成熟度0.95、0.75。
- 聚类:将训练集的西瓜分成若干组,每组称为一个“簇”;这些自动形成的簇可能存在潜在的划分,比如浅色瓜,深色瓜或者本地瓜,外地瓜。但这些潜在的概念使我们事先不知道的,有助于我们了解数据的内在规律。
- 监督学习:训练数据有标记信息的学习任务。例如分类,回归。
- 无监督学习:训练数据没有标记信息的学习任务。例如聚类。
- 泛化能力:机器学习出来的模型适用于新样本的能力。具有强泛化能力的模型可以很好地适用于整个样本空间。
1.3 假设空间
- 归纳:从特殊到一般的泛化过程。
- 演绎:从一般到特殊的特化过程。
- 假设空间:例如色泽属性有青绿,乌黑,浅白三种可能取值,还要考虑到,色泽无论取什么值都合适(即瓜的好坏与色泽无关),我们用*表示。考虑得到一种极端情况,好瓜这个概念不成立,世界上根本没有好瓜我们用∅表示这个假设。若色泽,根蒂,敲声分别有三种可能取值,则假设空间规模为4x4x4+1=65。


- 版本空间:有多个假设与训练集一致,即存在一个与训练集一致的“假设集合”。
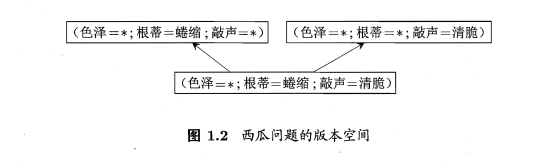
如何求取版本空间?
链接: https://blog.csdn.net/m0_37688984/article/details/79461983.
1.4 归纳偏好
- 归纳偏好:机器学习算法在学习过程中对某种类型假设的偏好。例如,某种原因使得它笔记色泽和敲声,更愿意去相信根蒂决定瓜的好坏。
- 奥卡姆剃刀:若有多个假设与观察一致,则选择最简单的那个。【作用:用来引导算法确立正确的偏好】
- 没有免费的午餐”定理(NFL定理):总误差与学习算法无关。
注意: 脱离具体问题,空泛的谈论“什么学习算法更好”,毫无意义。
课后习题:
1.1 表1.1 中若只包含编号为 的两个样例?试给出相应的版本空间.
1.色泽=青绿 根蒂=蜷缩 敲声=浊响
2.色泽=青绿 根蒂=蜷缩 敲声= *
3.色泽=青绿 根蒂=* 敲声= 浊响
4.色泽= * 根蒂= 蜷缩 敲声= 浊响
5.色泽= * 根蒂= * 敲声= 浊响
6.色泽= * 根蒂= 蜷缩 敲声= *
7.色泽= 青绿 根蒂= * 敲声= *
1.2



CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)