闲聊型对话系统之NLG总结报告
文章目录1 项目介绍1.1 背景知识介绍1.2 NLG的实现方式1.2.1 基于模板1.2.2 检索式1.2.3 生成式1 项目介绍1.1 背景知识介绍对话系统按领域分类,分为任务型和闲聊型。闲聊型对话系统有Siri、微软小冰、小度等。它们实现可以以任意话题跟人聊天。任务型对话系统是以完成特定任务为目标的对话系统。例如可以以订机票为一个特定的任务,实现的对话系统。我们这里重点关注任务型对话系统。任
文章目录
1 项目介绍
1.1 背景知识介绍
对话系统按领域分类,分为任务型和闲聊型。闲聊型对话系统有Siri、微软小冰、小度等。它们实现可以以任意话题跟人聊天。任务型对话系统是以完成特定任务为目标的对话系统。例如可以以订机票为一个特定的任务,实现的对话系统。我们这里重点关注闲聊型对话系统。
例如用户输入一句话:帮我订一张去北京的票。通过NLU能够识别到其领域是:机票,意图是:订机票,语义槽值有:到达地=北京。
流程处理到DM模块。关于DM的介绍以后再写。DM会做出决策:询问出发地。
流程处理到NLG模块。NLG模块的任务是用自然语言表达询问出发地这个请求。可以输出:请问您从哪里出发呢?
1.2 NLG的实现方式
1.2.1 基于模板
关于NLG其中一种实现方式是基于模板匹配。这种实现方式多用于任务型对话系统。这里也做一下介绍。例如根据不同的对话动作,配置该说的语言。需要变量替换的情况下,用变量表示。
| 对话动作 | 模板 | 自然语句 |
|---|---|---|
| 询问出发地 | 请问您从哪里出发? | 请问您从哪里出发? |
| 确认目的地 | 请问您的目的地是[des]吗? | 请问您的目的地是[北京]吗? |
其特点是简单、机械,需要人工。
1.2.2 检索式
NLG第二种实现方式是检索式。这种方式多用于闲聊型对话系统。实现原理是:将系统可以输出的句子都放在数据库中,将动作关键词、槽值等信息与库中所有句子做匹配,得到匹配度最高的句子作为NLG的输出。
其特点是:聊天机器人能输出的句子是预先收集好的。会体现收集很多问答对。数量级在几十亿,几百亿对。能输出的句子是有限的,也是确定的。
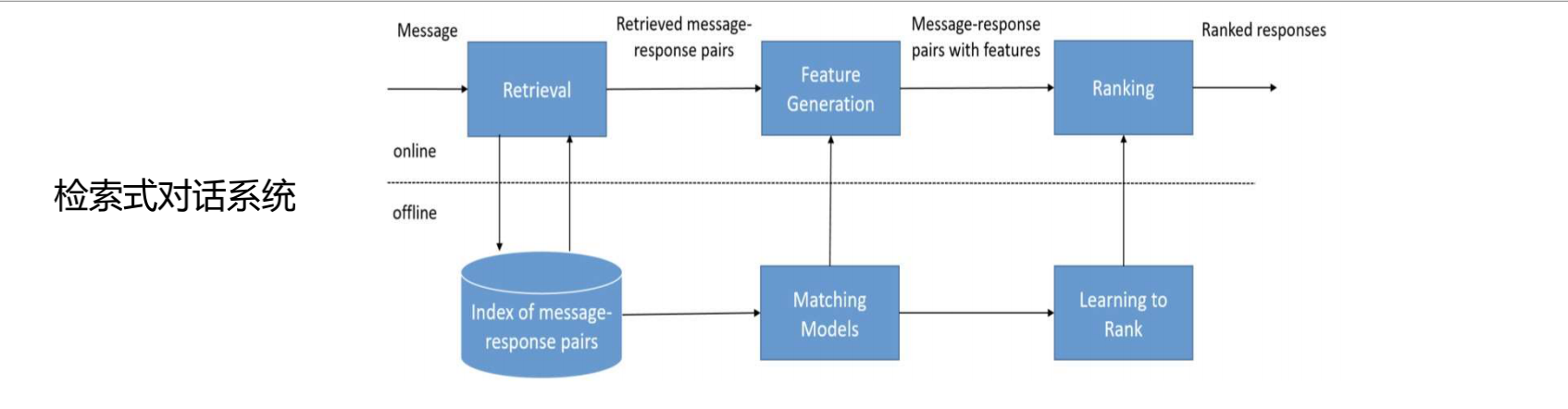
检索式对话系统的核心是核量两句话的语义相似度。
匹配套路1是将输入、和库中的句子都用“表示部件”representation function,将其表示为一个向量。之后使用“比对部件”matching function,计算两个向量之间的相似度。

representation function:有很多种选择,可以使用bert、RNN、CNN等。
matching function:可以是一个点乘。
这里会产生一个计算量大的问题。一个q向量与数据库中几十亿的句子向量做点乘,计算量太大。可以先做一个预处理。例如使用BM25先计算一遍相似度,从种选择1000条相似度高的句子,在做matching function。在预处理这一步重点关注其召回率。使用ES或者Solr可以解决预处理问题。
匹配套路2是用q和r中的词发生交互。

例如上图,q是有3个词的一句话。r是有4个词的一句话。发生交互之后得到一个3x4的矩阵。交互函数可以是点乘。
得到交互矩阵之后,将这个矩阵看成是一个图片。使用CNN,得到一个定长的表示向量。
之后过一个FC全连接层,得到一个得分。
因为BERT模型的强大,目前比较常用的做法是使用[CLS]q[SEP]r[SEP] 这样格式的输入,将数据放到bert模型中,得到的[CLS]的token表示就是句子的表示,可以用来计算相似度。这样效果很好。
该领域出名的数据集:Ubuntu数据集。
1.2.3 生成式
NLG第三种实现方式是seq2seq生成式对话系统。这种方式多用于闲聊型对话系统。将用户输入的句子作为X,利用P(Y|X),生成在X条件下会输出的Y。其特点是生成的句子是不可控的。一旦出现不适合的句子,后果非常严重。优点是能够回复的句子很自然,回复的内容会更广泛。
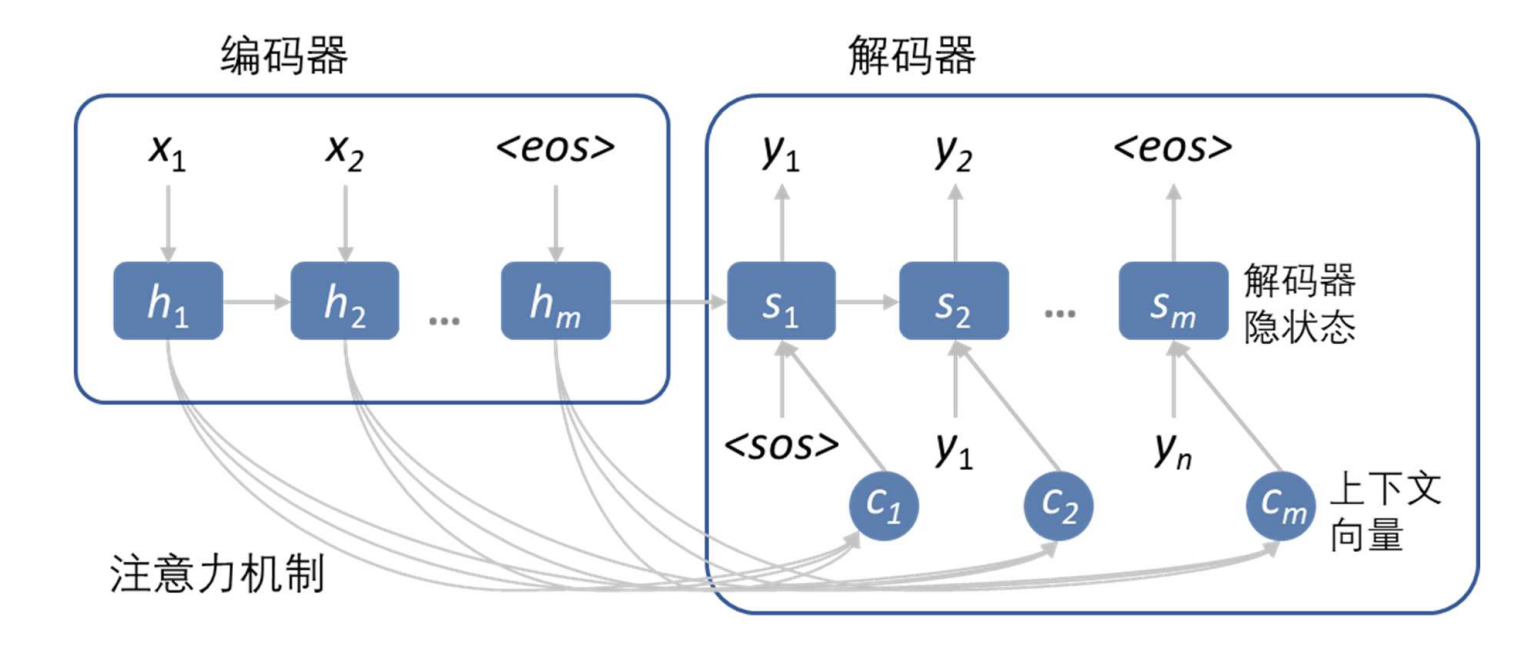
模型分为编码器和解码器2部分。
编码器的输入是问题X,输出是将X中的每个词用定长的向量表示。作为解码器的输入。
解码器的输入是编码器的输出,得到每一个时间步应该产生的输出。在处理第i步的过程中编码器的输出、前一步的输出都是输入,生成第i步的输出。
该模型解决的是P(Y|X)概率计算问题。
P
(
Y
∣
X
)
=
P
(
y
1
∣
X
)
P
(
y
2
∣
y
1
,
X
)
P
(
y
3
∣
y
2
,
y
1
,
X
)
.
.
.
P
(
y
n
∣
y
n
−
1
.
.
.
y
1
∣
X
)
P(Y|X)=P(y_1|X)P(y_2|y_1,X)P(y_3|y_2,y_1,X)...P(y_n|y_{n-1}...y_1|X)
P(Y∣X)=P(y1∣X)P(y2∣y1,X)P(y3∣y2,y1,X)...P(yn∣yn−1...y1∣X)
本项目采用的是生成式模型实现NLG部分。
1.3 数据集介绍
数据集 LCCC,是清华大学提供的一个大规模中文对话数据集。本次采用的数据集是其中的一部分。数据集中有1万2千条数据。我们对其数据做处理,其中训练集1万条,验证集2000条。每一条数据是单轮对话,或者多轮对话。
2 技术方案梳理
2.1 模型介绍
seq2seq模型学习到的是 P ( Y ∣ X ) = P ( y 1 ∣ X ) P ( y 2 ∣ y 1 , X ) P ( y 3 ∣ y 2 , y 1 , X ) . . . P ( y n ∣ y n − 1 . . . y 1 ∣ X ) P(Y|X)=P(y_1|X)P(y_2|y_1,X)P(y_3|y_2,y_1,X)...P(y_n|y_{n-1}...y_1|X) P(Y∣X)=P(y1∣X)P(y2∣y1,X)P(y3∣y2,y1,X)...P(yn∣yn−1...y1∣X)中的条件概率分布。在具体模型选择的时候选择表达能力更强的transformer模型。项目中使用的代码主要来自这里。作者是2018年ConvAI2比赛的冠军。

训练数据是问答对。我们将最后一个回答之前的内容作为问题和历史,最后一个句子作为回答。
例如原始句子:
[
"遭 淋 安 逸 了 ?",
"是 哈 , 你 没 遭 撒 ?",
"晚 班",
"那 起 来 这 么 早 , 这 天 气 多 适 合 睡 觉",
"睡 不 着 了"
]
在输入到模型中的时候:
X:遭 淋 安 逸 了 ?是 哈 , 你 没 遭 撒 ?晚 班 那 起 来 这 么 早 , 这 天 气 多 适 合 睡 觉
Y:睡 不 着 了
首先需要对X做word embedding和positional embedding。分词。分词是单字分词。预训练模型选择的是chinese_gpt_original。word embedding是用分词实现对词的编码。词向量维度768。
positional embedding也用维度768的向量表示。
两部分向量相加,作为encoder层的输入。
在encoder会首先做一个Masked Multi-head Attention。会首先将输入X分为多个head,本项目中是12个。对12个X分别做self-attention。然后再将12个部分合并。将结果作为输出
X
1
X_1
X1。这里实际做的是masked-self-attention。也就是说例如在第3个向量作为key的时候,只会使用第1个,第2个向量作为key和value。因为模型在这里还有一个LM(语言模型)的任务。因为加入LM任务,会在结果产生的时候能够增加多样性。
再下一层是残差链接。残差链接是用
X
+
X
1
X+X_1
X+X1作为输出
X
2
X_2
X2。残差链接这一层可以加快模型训练速度。
再下一层是层正则化。层正则化是对
X
2
X_2
X2中的各个向量,求方差,均值。输出
X
3
X_3
X3。这样做可以让每一个时间步的值更平均一些,差异不会特别大。
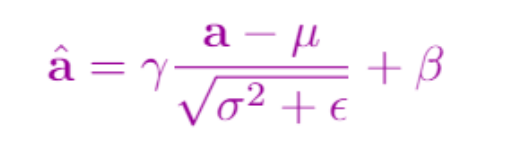
再下一层是前馈神经网络。这里包含两个全连接层。
X
4
=
L
i
n
e
a
r
(
R
e
l
u
(
L
i
n
e
a
r
(
X
3
)
)
)
X_4=Linear(Relu(Linear(X_3)))
X4=Linear(Relu(Linear(X3)))
再下一层是残差链接。
再下一层是层正则化。至此一个此时transformer block完成。此时的输出作为下一层的transformer block的输入。
经过12个transformer block之后的输出C作为decode的输入。
在本模型中encoder和decoder使用相同的参数。
在decoder的部分,第一层是多个部分组成。一个部分是decoder前i-1个的输出,做Masked Multi-head Attention得到输出
H
1
H_1
H1。一个部分是以前i-1个的输出作为query,encoder的输出作为key和value做Multi-head Attention得到输出
H
2
H_2
H2。然后将
H
1
H_1
H1,
H
2
H_2
H2求平均,作为第一层的输出。作为模型的扩展,我们还可以输入其他向量,例如用户的个人信息作为key和value,对Y做cross attention,得到结果,参数到加权平均中。
之后的每一层操作与encoder中一样。
经过12个transformer block之后,接入线性层,用
Y
i
Y_i
Yi向量预测
Y
i
+
1
Y_{i+1}
Yi+1的输出。
2.2 评价指标
模型评价指标使用损失做评价,选择损失最低的模型保存下来。
2.3 模型实现
2.3.1 数据处理
将json格式的数据处理为一行,第二部分是最后一句,作为回复。其余部分是第一部分。中间用tab键分割。

2.3.2 构建dataset
对每条数据的第一部分,第二部分首位分别加EOS标识。使用[pad]做batch对齐。
2.3.3 模型定义
模型使用transformer ,根据2.1模型介绍中部分定义。
MultiInputModel是总的模型。
TransformerModule定义了Transformer相关操作。
TransformerBlock定义了一个TransformerBlock的相关操作。
class MultiInputModel(nn.Module):
def __init__(self, config, vocab, n_segments=None):
super(MultiInputModel, self).__init__()
self.config = config
self.vocab = vocab
self.transformer_module = TransformerModule(
config.n_layers, len(vocab), config.n_pos_embeddings, config.embeddings_size, vocab.pad_id,
config.n_heads, config.dropout, config.embed_dropout, config.attn_dropout, config.ff_dropout, n_segments)
self.pre_softmax = nn.Linear(config.embeddings_size, len(vocab), bias=False)
self.pre_softmax.weight = self.transformer_module.embeddings.weight
class TransformerModule(nn.Module):
def __init__(self, n_layers, n_embeddings, n_pos_embeddings, embeddings_size,
padding_idx, n_heads, dropout, embed_dropout, attn_dropout, ff_dropout,
n_segments=None):
super(TransformerModule, self).__init__()
self.embeddings = nn.Embedding(n_embeddings, embeddings_size, padding_idx=padding_idx)
self.pos_embeddings = nn.Embedding(n_pos_embeddings + 1, embeddings_size, padding_idx=0)
self.embed_dropout = nn.Dropout(embed_dropout)
self.layers = nn.ModuleList(
[TransformerBlock(embeddings_size, n_heads, dropout, attn_dropout, ff_dropout) for _ in range(n_layers)])
self.n_segments = n_segments
self._init_weights()
class TransformerBlock(nn.Module):
def __init__(self, n_features, n_heads, dropout, attn_dropout, ff_dropout):
super(TransformerBlock, self).__init__()
self.attn = MultiheadAttention(n_features, n_heads, attn_dropout)
self.attn_norm = nn.LayerNorm(n_features)
self.ff = FeedForward(n_features, 4 * n_features, ff_dropout)
self.ff_norm = nn.LayerNorm(n_features)
self.dropout = nn.Dropout(dropout)
def forward(self, x, padding_mask, *contexts):
'''contexts = [(context1, padding_mask1), ...]'''
inputs = (x, padding_mask) + contexts
full_attn = 0
n_attn = len(inputs) // 2
for i in range(0, len(inputs), 2):
c, m = inputs[i], inputs[i + 1].bool()
a = self.attn(x, c, c, m)
full_attn += (a / n_attn)
full_attn = self.dropout(full_attn)
x = self.attn_norm(x + full_attn)
f = self.ff(x)
f = self.dropout(f)
x = self.ff_norm(x + f)
return (x, padding_mask) + contexts
2.3.4 训练相关参数
优化方式。优化方式使用Adm+warm up的方式。初始学习率6.25e-5,warmup=1000。
loss计算。使用交叉熵损失mean计算loss。所有计算损失要考虑mask。被masked的部分不参与计算。total loss = 0.02*lm loss + seq2seq loss。
使用batch_split,使用时间换空间策略。有时候我们的GPU内存不够大,每一个batch的数量不能很大(本项目中是24),这个时候可以多做几次前向传播,再做一次梯度更新。用更多的数据可以让梯度更新的值更准确,收敛得更快。
本项目中训练了17轮。每训练100步做一次验证。
2.3.5 训练结果
验证机上语言模型损失 3.9899, 验证集上seq2seq损失0.7731。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)