(P9-P23)Ceph安装方法
文章目录1.安装说明1.安装说明Ceph官方文档安装方法1:Nautilus 之前使用ceph-deploy安装方法2:Ceph release v15.2.0 (Octopus) 之后使用cephadm,未来推荐使用的安装方法,支持GUI和命令行进行安装安装方法3:手动安装安装方法4:安装到K8S的集群中,与K8S集成:使用Rook...
1.安装说明
-
安装方法1:Nautilus 之前使用ceph-deploy
-
安装方法2:Ceph release v15.2.0 (Octopus),CentOS8 之后使用cephadm,未来推荐使用的安装方法,支持GUI和命令行进行安装
-
安装方法3:手动安装
-
安装方法4:安装到K8S的集群中,与K8S集成:使用Rook
2.使用ceph-deploy进行安装
-
安装拓扑
(1)部署的Nautilus版本
(2)部署了3个节点,2个网段:10.211.55.0/24,10.211.56.0/24
(3)复用node1,他是deploy节点,也是monitor节点,后续node2,node4也有monitor
(4)node1和node2提供对象存储,需要部署rgw。因为是无状态化的,所以需要提供一个负载均衡器haproxy
(5)node1,node2,node3既是存储节点,也是管理节点
(6)每个node拥有2块盘,eg:osd.0对应盘1,osd.3对应盘2
(7)每个node还部署了mds服务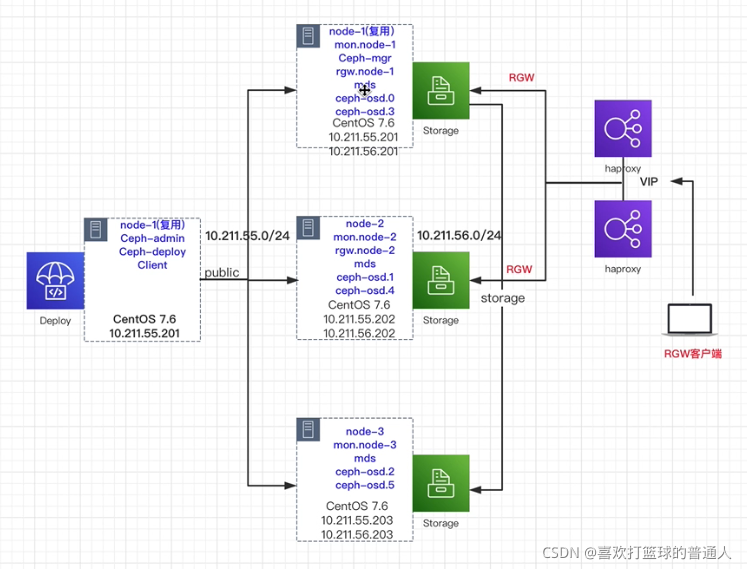
-
Ceph环境准备安装步骤
参考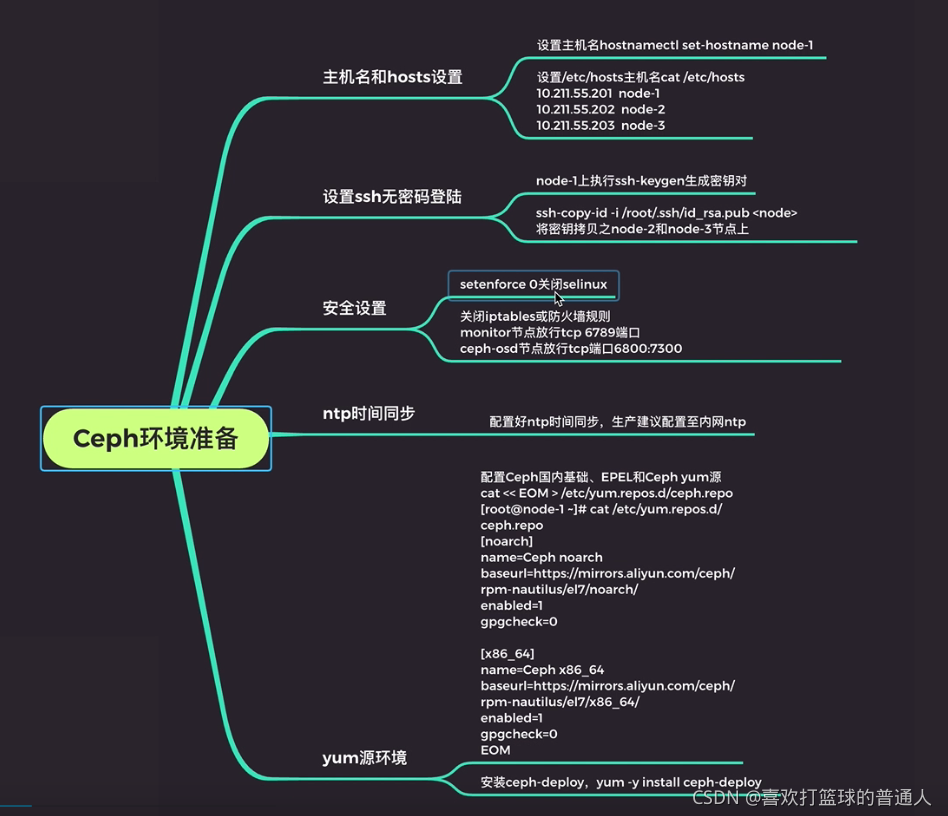
-
(1)设置主机名



-
(2)设置ssh无密码登录
node-1->node-1,node-2,node-3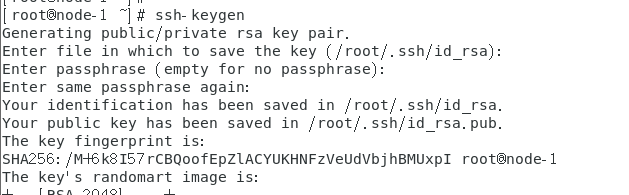

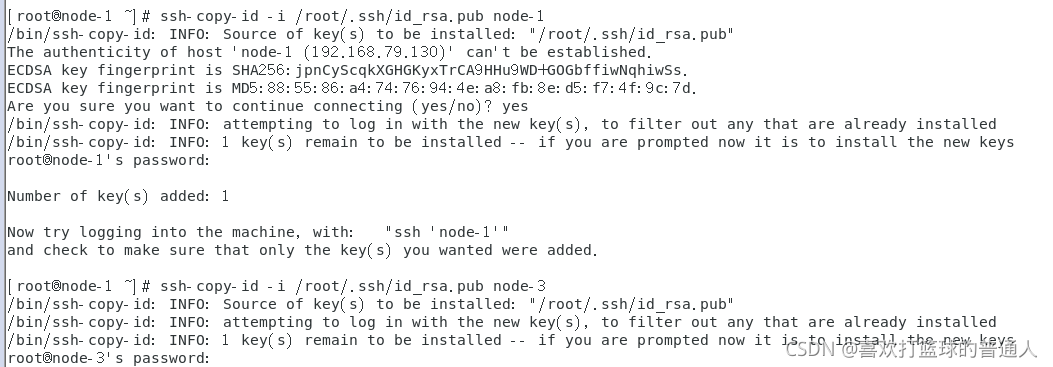
-
(3)安全设置
node-1,node-2,node-3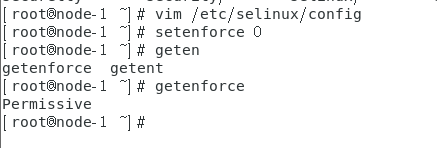
关闭防火墙
node-1,node-2,node-3
-
(4)ntp时间同步
node-1作为ntp的服务器;
node-2,node-3作为ntp服务器的客户端;
node-1的配置文件:/etc/ntp.conf默认指向外网ntp服务器,这里不做修改
node-1配置如下: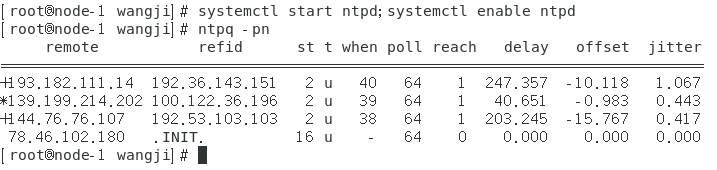
node-2配置如下,node-3类似
/etc/ntp.conf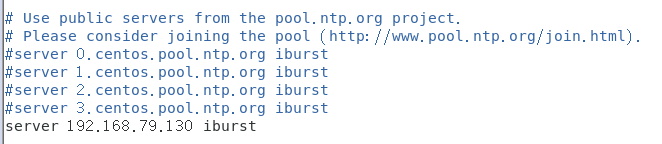

node-3配置如下:
-
(5)yum源配置
在三个node配置阿里CentOS7的镜像源;Epel 镜像源;Ceph镜像源
其他node-2,和node-3节点类似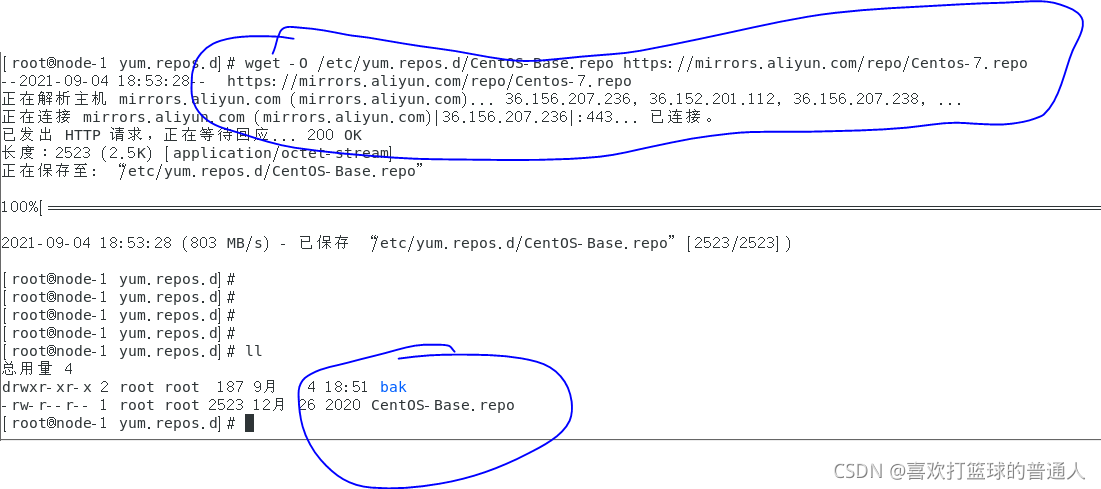
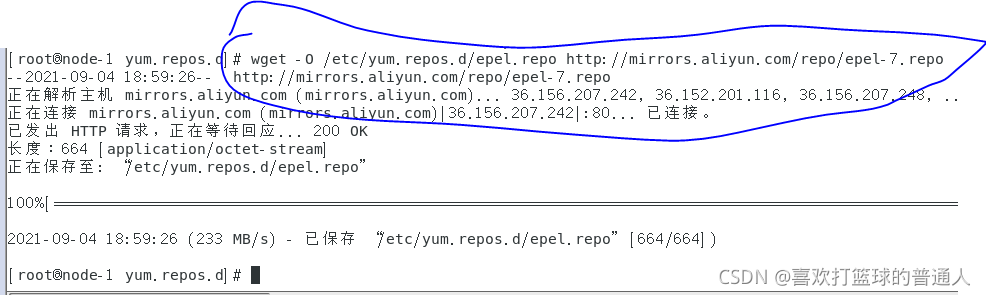
ceph源的选择是N版本(nautilus)的ceph,noarch/和x86_64/的yum源都配置好
baseurl可以直接从https://mirrors.aliyun.com/ceph/这里获取,不需要手动敲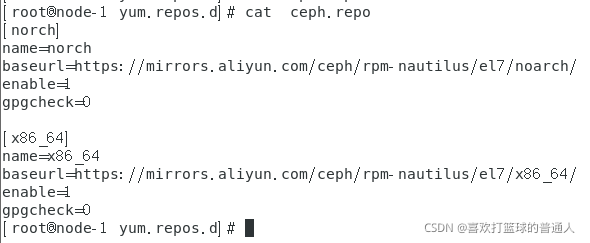
可以看到yum源的仓库都配置好了
生成下yum缓存
-
(6)仅在部署节点node-1安装python-setuptools ceph-deploy


补充:ubuntu 的apt源配置方法见:Ubuntu配置apt的国内源地址,网站见:阿里云ubuntu镜像源网站
- (7)创建集群
创建一个目录,在目录中操作
public网络是:外部访问Ceph的入口网络,网段:192.168.79.0/24;
cluster是用于内部通信网络,网段:192.168.80.0/24;
在node-1部署monitor
ceph-deploy new --public-network 192.168.79.0/24 --cluster-network 192.168.80.0/24 node-1
在node-1,node-2,node-3安装一些ceph相关的包(因为配置的是国内的yum源,所以手动安装包)
[root@node-1 ceph-deploy]# yum install -y ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds
若无法ping mirrors.aliyun.com,则在/etc/resolv.conf中添加:
nameserver 8.8.8.8
nameserver 8.8.8.4
手动安装ceph包,则不要执行:ceph-deploy insyall node-1 node-2 node-
在node-1初始化monitor
[root@node-1 ceph-deploy]# ceph-deploy mon create-initial
在node-1,将admin文件推送到所有的节点上
[root@node-1 ceph-deploy]# ceph-deploy admin node-2 node-3 node-1
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node-1 (age 4m)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
node-1作为管理节点
[root@node-1 ceph-deploy]# ceph-deploy mgr create node-1
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node-1 (age 8m)
mgr: node-1(active, since 16s)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
部署OSD节点,在node-1上进行操作
\-\-joural参数是用来加速的,数据写到journal,然后再写入data中
[root@node-1 ceph-deploy]# ceph-deploy osd create --help
usage: ceph-deploy osd create [-h] [--data DATA] [--journal JOURNAL]
[--zap-disk] [--fs-type FS_TYPE] [--dmcrypt]
[--dmcrypt-key-dir KEYDIR] [--filestore]
[--bluestore] [--block-db BLOCK_DB]
[--block-wal BLOCK_WAL] [--debug]
[HOST]
ceph-deploy osd create node-1 --data /dev/sdb
ceph-deploy osd create node-2 --data /dev/sdb
ceph-deploy osd create node-3 --data /dev/sdb
[root@node-1 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05846 root default
-3 0.01949 host node-1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
-5 0.01949 host node-2
1 hdd 0.01949 osd.1 up 1.00000 1.00000
-7 0.01949 host node-3
2 hdd 0.01949 osd.2 down 1.00000 1.00000
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
mon is allowing insecure global_id reclaim
services:
mon: 1 daemons, quorum node-1 (age 11m)
mgr: node-1(active, since 11m)
osd: 3 osds: 3 up (since 7s), 3 in (since 106s)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
扩展mon和mgr(默认是主备模式)到node-2,node-3,在node-1上操作
ceph-deploy mon add node-2 --address 192.168.79.131
ceph-deploy mon add node-3 --address 192.168.79.132
查看仲裁选举情况:
[root@node-1 ceph-deploy]# ceph quorum_status --format json-pretty
{
"election_epoch": 16,
"quorum": [
0,
1,
2
],
使用PAXOS(奇数个mon)当前有三个node仲裁
"quorum_names": [
"node-1",
"node-2",
"node-3"
],
leader是
"quorum_leader_name": "node-1",
查看mon状况
[root@node-1 ceph-deploy]# ceph mon stat
e3: 3 mons at {node-1=[v2:192.168.79.130:3300/0,v1:192.168.79.130:6789/0],node-2=[v2:192.168.79.131:3300/0,v1:192.168.79.131:6789/0],node-3=[v2:192.168.79.132:3300/0,v1:192.168.79.132:6789/0]}, election epoch 16, leader 0 node-1, quorum 0,1,2 node-1,node-2,node-3
[root@node-1 ceph-deploy]# ceph mon dump
epoch 3
fsid 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
last_changed 2021-09-05 21:55:42.456018
created 2021-09-04 23:56:14.784010
min_mon_release 14 (nautilus)
0: [v2:192.168.79.130:3300/0,v1:192.168.79.130:6789/0] mon.node-1
1: [v2:192.168.79.131:3300/0,v1:192.168.79.131:6789/0] mon.node-2
2: [v2:192.168.79.132:3300/0,v1:192.168.79.132:6789/0] mon.node-3
dumped monmap epoch 3
[root@node-1 ceph-deploy]#
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
1 slow ops, oldest one blocked for 39 sec, mon.node-1 has slow ops
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 6m)
mgr: node-1(active, since 25m)
osd: 3 osds: 2 up (since 11m), 2 in (since 78s)
task status:
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 2.0 GiB used, 38 GiB / 40 GiB avail
pgs:
在node-1,将mgr部署在node-2,node-3
[root@node-1 ceph-deploy]# ceph-deploy mgr create node-2 node-3
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
1 slow ops, oldest one blocked for 179 sec, mon.node-1 has slow ops
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 8m)
mgr: node-1(active, since 28m), standbys: node-2, node-3
osd: 3 osds: 2 up (since 13m), 2 in (since 3m)
重启ceph:
[root@node-2 wangji]# systemctl restart ceph.target
3.Pool含义与构建
-
无论是通过Ceph块设备、对象存储还是文件系统,Ceph存储群集都从Ceph客户端接收数据,并将其存储为对象。每个对象对应于文件系统中的一个文件,该文件存储在对象存储设备上。Ceph OSD守护程序处理存储磁盘上的读/写操作。
-
Ceph存储系统支持“池”的概念,“池”是用于存储对象的逻辑分区。
-
Ceph客户端从Ceph监控器检索集群映射,并将对象写入池中。池的size副本数或副本数,CRUSH规则和放置组的数量决定了Ceph将如何放置数据。
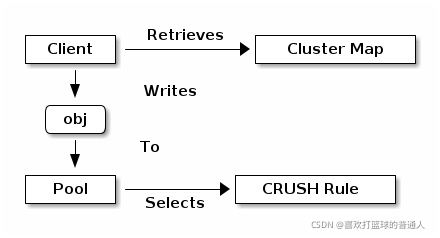
client从mon中拿到集群的状态表;
每个文件切割成多个对象obj;
CRUSH rule将Pool中的obj落入到对应的OSD上;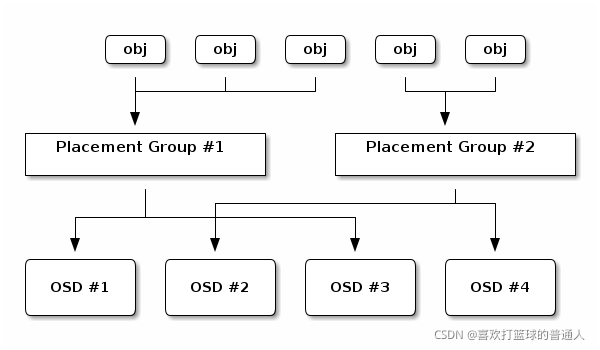
Pool与PGs(就是一些目录)有映射关系,相互关联;
obj写入PGs,接着PGs会通过Crush rule找到对应的OSD上; -
ceph中pg与pgp的关系
(1)pg是用来存放object的,pgp相当于是pg存放osd的一种排列组合!
(2)举例说明:比如有3个osd,osd1、osd2、osd3 ,副本数是2,如果pgp的数目是1,那么所有的pg存放的osd组合就只有一种,可能是[osd.1,osd.2],那么所有的pg主从副本分别存放到osd.1和osd.2,如果pgp设为2,那么其osd组合可以两种,可能是[osd.1,osd.2]和[osd.1,osd.3],是不是很像我们高中数学学过的排列组合,pgp就是代表这个意思。一般来说应该将pg和pgp的数量设置为相等。 -
在node-1上创建pool
[root@node-1 ceph-deploy]# ceph osd pool create
Invalid command: missing required parameter pool(<poolname>)
osd pool create <poolname> <int[0-]> {<int[0-]>} {replicated|erasure} {<erasure_code_profile>} {<rule>} {<int>} {<int>} {<int[0-]>} {<int[0-]>} {<float[0.0-1.0]>} : create pool
Error EINVAL: invalid command
该pool包含64个PG(前者),64个PGP
[root@node-1 ceph-deploy]# ceph osd pool create ceph-demo 64 64
pool 'ceph-demo' created
[root@node-1 ceph-deploy]# ceph osd lspools
1 ceph-demo
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo pg_num
pg_num: 64
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo pgp_num
pgp_num: 64
默认是三副本,写一份到pool,pool会找3份OSD写入磁盘
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo size
size: 3
其他使用方法:
[root@node-1 ceph-deploy]# ceph osd pool get --h
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo crush_rule
crush_rule: replicated_rule
[root@node-1 ceph-deploy]# ceph osd pool set ceph-demo size 2
set pool 1 size to 2
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo size
size: 2
[root@node-1 ceph-deploy]# ceph osd pool set ceph-demo pg_num 128
set pool 1 pg_num to 128
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo pg_num
pg_num: 128
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo pgp_num
pgp_num: 128
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: 9b6ddff3-f2da-41ea-93e4-a5470ffb6a3f
health: HEALTH_WARN
1 slow ops, oldest one blocked for 474 sec, mon.node-1 has slow ops
mons are allowing insecure global_id reclaim
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 34m)
mgr: node-1(active, since 54m), standbys: node-2, node-3
osd: 4 osds: 2 up (since 39m), 2 in (since 29m)
data:
pools: 1 pools, 128 pgs-----------------可以看到128个pg
objects: 0 objects, 0 B
usage: 2.0 GiB used, 38 GiB / 40 GiB avail
pgs: 128 active+clean
4.使用rbd创建块设备文件
- ceph集群搭建起来后,可以在ceph集群上进行块存储、对象存储以及文件系统存储。
- 从架构上来看,在ceph集群的上面是rados协议,该协议为使用ceph集群的用户提供必要的支持(ceph用户通过调用rados协议来使用ceph集群)。
- 对于块存储来说,可以通过内核模块的方式使用ceph集群也可以通过用户态调用librbd库来使用ceph集群。通过内核模块方式可以充分的利用内核的page cache机制,而通过用户态调用librbd也可以使用librbd在用户态提供的cache方式提高性能。
- 在node-1的任意目录下,因为默认会读取到ceph.client.admin.keyring这个文件
[root@node-2 ~]# rbd help create
[root@node-1 ceph-deploy]# rbd create -p ceph-demo --image rbd-demo.img --size 1G
-p指定pool名称,创建1G文件
[root@node-1 ceph-deploy]# rbd create -p ceph-demo/rbd-demo-1.img --size 1G
可以看到2个块设备文件
[root@node-1 wangji]# rbd -p ceph-demo ls
rbd-demo.img
rbd-demo-1.img
[root@node-1 wangji]# rbd info ceph-demo/rbd-demo.img
size 10 GiB in 2560 objects
order 22 (4 MiB objects)---每个obj是4MB
snapshot_count: 0
id: 11194f22705d---块文件的id号
block_name_prefix: rbd_data.11194f22705d---每个obj的前缀
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten--内核高级特性,后四者Centos7不支持
op_features:
flags:
create_timestamp: Sun Jun 13 17:13:51 2021
access_timestamp: Sun Jun 13 17:13:51 2021
modify_timestamp: Sun Jun 13 17:13:51 2021
- 删除块文件
$ rbd -p ceph-demo rm --image rbd-demo-1.img
Removing image: 100% complete...done.
$ rbd -p ceph-demo ls # 确认已删除
rbd-demo.img
- 删除块设备不支持的特性
$ rbd info ceph-demo/rbd-demo.img # 查看块设备特性
rbd image 'rbd-demo.img':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11194f22705d
block_name_prefix: rbd_data.11194f22705d
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sun Jun 13 17:13:51 2021
access_timestamp: Sun Jun 13 17:13:51 2021
modify_timestamp: Sun Jun 13 17:13:51 2021
# 删除不支持的特性
$ rbd feature disable ceph-demo/rbd-demo.img deep-flatten
$ rbd feature disable ceph-demo/rbd-demo.img fast-diff
# 删除上面两个后,就可以再次进行内核级别挂载了,如果还不行,再删除下面两个
$ rbd feature disable ceph-demo/rbd-demo.img object-map
$ rbd feature disable ceph-demo/rbd-demo.img exclusive-lock
$ rbd info ceph-demo/rbd-demo.img # 确认不支持的特性已删除
rbd image 'rbd-demo.img':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11194f22705d
block_name_prefix: rbd_data.11194f22705d
format: 2
features: layering # layering特性需要保持
op_features:
flags:
create_timestamp: Sun Jun 13 17:13:51 2021
access_timestamp: Sun Jun 13 17:13:51 2021
modify_timestamp: Sun Jun 13 17:13:51 2021
$ rbd map ceph-demo/rbd-demo.img # 再次映射块设备
/dev/rbd0
- 查看块设备,至此,就可以将/dev/rbd0当成我们一个本地的磁盘来使用了。
rbd-demo.img镜像挂载到块设备/dev/rbd0
$ rbd device list
id pool namespace image snap device
0 ceph-demo rbd-demo.img - /dev/rbd0
$ lsblk /dev/rbd0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
rbd0 252:0 0 10G 0 disk
- 格式化并使用块设备
如果将ceph对接云平台,当成云盘来使用,那么不建议对块设备进行分区,这样可以避免块设备扩容带来的麻烦。
$ mkfs.xfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=16, agsize=163840 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=2621440, imaxpct=25
= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
# 挂载并测试使用
$ mkdir /data && mount /dev/rbd0 /data/
$ echo 'test block' > /data/test.txt
5.RBD块存储扩容
- rdb块设备,支持扩缩容,但是对于缩容操作,强烈不建议,可能会造成数据丢失。
$ rbd -p ceph-demo info --image rbd-demo.img # 确认当前块设备大小
rbd image 'rbd-demo.img':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11194f22705d
block_name_prefix: rbd_data.11194f22705d
format: 2
features: layering
op_features:
flags:
create_timestamp: Sun Jun 13 17:13:51 2021
access_timestamp: Sun Jun 13 17:13:51 2021
modify_timestamp: Sun Jun 13 17:13:51 2021
$ rbd resize ceph-demo/rbd-demo.img --size 20G
# 从10G大小扩容到20G
Resizing image: 100% complete...done.
$ rbd -p ceph-demo info --image rbd-demo.img # 确认已扩容20G
rbd image 'rbd-demo.img':
size 20 GiB in 5120 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 11194f22705d
block_name_prefix: rbd_data.11194f22705d
format: 2
features: layering
op_features:
flags:
create_timestamp: Sun Jun 13 17:13:51 2021
access_timestamp: Sun Jun 13 17:13:51 2021
modify_timestamp: Sun Jun 13 17:13:51 2021
$ df -hT /data # 此时块设备已经扩容,但文件系统还未识别到,如下,还是原来的10G
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/rbd0 xfs 10G 33M 10G 1% /data
$ xfs_growfs /dev/rbd0
$ partprobe
# 扩容文件系统(原磁盘是xfs格式的,故需要使用xfs_growfs指令扩容,RBD底层已经识别,文件系统层面GPT,MBR分区还没识别到,所以也需要扩容)
$ resize2fs /dev/rbd0
# 如果你格式化为ext4的,请执行该命令
$ df -hT /data # 确认已扩容成功
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/rbd0 xfs 20G 34M 20G 1% /data
- 查询pool中所有的obj名字
[root@node-1 wangji]# rados -p ceph-demo ls|grep rbd_data.11194f22705d
查看每个obj的大小
[root@node-1 wangji]# rados -p ceph-demo stat grep rbd_data.11194f22705d.0000000000423
映射关系查看?
obj映射到PG,映射到OSD[1,2],OSD.1和OSD.2是在不同的宿主机上的
ceph osd map ceph-demo rbd_data.11194f22705d.0000000000423
ceph osd tree
6.Ceph告警排查
- 告警1
告警:
[ root@node-1 rbd-demo]# ceph -S
cluster :
id :
814347 79 - 5264-4f06- 8456- a891bc52ce79
health:
HEALTH WARN
application not enabled on 1 pool(s)
解决办法:
[ root@node-1 rbd-demo]# ceph health detail
[root@node-1 rbd-demo]#CJoseph健康详细信息
HEALTH_ WARN application not enabled on 1 pool(s); 2 daemons have recently crashed
use 'ceph osd pool application enable <pool-name> <app-name>' ,where <app-name> is ' cephfs','rbd', ' rgw',
use 'ceph osd pool application enable <pool-name> <app-name>' ,where <app-name> is ' cephfs','rbd', ' rgw',
[ root@node-1 rbd-demo]# ceph osd pool application enable ceph-demo rbd
设置成功
[ root@node-1 rbd-demo]# ceph osd pool application get ceph- demo
{
"rbd": {}
}
- 告警2
告警:
[ root@node-1 rbd-demo]# ceph -S
cluster :
id :
814347 79 - 5264-4f06- 8456- a891bc52ce79
health:
HEALTH WARN
2 daemons have recently crashed
解决办法
[ root@node-1 rbd-demo]# ceph health detail
HEALTH_ WARN 2 daemons have recently crashed
RECENT_ CRASH 2 daempns have recently crashed
mgr.node-1 crashed on host node-1 at 2020-03-21 15: 10: 34.8806597
mgr .node-1 crashed on host node-1 at 2020-03-21 15:09:17 .427005Z
查看告警内容
[ root@node-1 rbd-demo]# ceph crash ls
2020- 03-21_ 15:09:17.427005Z_ cbe7d9c6- 69e8 - 4d43- 8e75-3c55aebfbe27 mgr .node-1
2020- 03-21_ 15:10:34.880659Z_ _7c58f08d- 0859-491c- 8862-ef956d6f4bc3 mgr . node-1
[ root@node-1 rbd-demo]# ceph crash info 2020-03-21 15: 09: 17.427005Z_ cbe7d9c6- 69e8 - 4d43- 8e75 - 3c55aebfbe27
'os_ version_ id" :
"utsname_ release": "3.10. 0-957.el7. x86_ 64",
"os_ name": "Cent0S Linux",
"entity_ name": "mgr . node- 1
"timestamp": "2020-03-21 15: 09:17.427005Z" ,
" process_ name": " ceph- mgr'
"utsname_ machine": "x86_ 64",
"utsname sysname": "Linux" ,
"oS_ version": "7 (Core)",
"os id" . centos"
认为是误报,删除。*表示新的状态
|[ root@node-1 rbd-demo]# systemctl status ceph-mgr@node- 1
●ceph-mg r@node-1.service - Ceph cluster manager daemon
Loaded: loaded (/usr/ lib/ systemd/ system/ ceph-mgr@.service; enabled; vendor preset: disabled)
Active: active ( running) since 六2020-03-21 11:10:45 EDT; 1h 9min ago
Main PID: 17433 (ceph-mgr)
CGroup: /system. slice/ system- ceph\x2dmgr . slice/ ceph-mg r@node-1. service
L -17433 /us r/bin/ceph-mgr -f --cluster ceph --id node-1 --setuser ceph -- setgroup ceph
3月21 11:10:45 node-1 systemd[1]: Started Ceph cluster manager daemon.
|[ root@node-1 rbd-demo]# ceph -S
cluster: .
id:
81434779- 5264-4f06- 8456-a891bc52ce79
health: HEALTH_ WARN
2 daemons have recently crashed
[ root@node-1 rbd-demo]# ceph -h |grep crash
[ root@node-1 rbd-demo]# ceph crash ls
ID ENTITY NEW
2020-03-21 15: 09:17.427005Z_ cbe7d9c6- 69e8 - 4d43- 8e75-3c55aebfbe27 mgr. node-1 *
2020-03-21_ 15:10:34. 880659Z_ _7c58f08d- 0859-491c- 8862- ef956d6f4bc3 mgr .node-1 *
[ root@node-1 rbd-demo]# ceph crash archive 2020-03-21_ 15: 09:17.427005Z_ cbe7d9c6 - 69e8 - 4d43- 8e75 -3c55aebfbe27
[ root@node-1 rbd-demo]# ceph crash archive 2020-03-21 15: 10:34.880659Z 7 c58f08d- 0859 -491c- 8862-ef956d6f4bc3

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)