VOC格式数据分析统计和处理
文章目录1 检查数据集2 移动特定分类的数据3 从VOC中提取特定分类的数据4 提取特定分类并修改名称5 VOC数据集可视化无论是做检测还是分割,大多数数据集都会以VOC格式或COCO数据集来准备。本文将立足于目标检测,对VOC数据集进行分析。VOC数据集的格式为:$ tree -L 1 VOCdevkit/VOC2007VOCdevkit/VOC2007├── Annotations├── Im
文章目录
检测系列相关文章参考如下链接:
- VOC数据的结构介绍及自定义生成,用labelimg自已标注
- VOC标准数据的生成及分析,VOC易用labelimg生成,做为基础的检测数据类型
- VOC转YOLO,方便YOLO系列模型使用
- VOC转COCO,方便用于COCO map评估
- YOLO转VOC,方便使用我们的VOC相关分析和处理代码
- COCO转VOC,方便使用我们的VOC相关分析和处理代码
以上数据格式互转,方便我们处理各种收集的开源数据和自己标记的数据的整合。当然也不是特别的全面,但是工作中常用的主流的格式是包含的。
觉的有价值的小伙伴可以给点个赞。
无论是做检测还是分割,大多数数据集都会以VOC格式或COCO数据集来准备。本文将立足于目标检测,对VOC数据集进行分析,这样的好处是我们常见的代码都是关于VOC的,更重要的是VOC标注文件中有所有我们需要信息,而且是一个图片对应一个文件,我们可以直接用文本编辑器打开查看,很方便,想要看标注可视化效果,直接用labelimg标注工作打开就行;相对的coco缺点是所有标注都放到一个json中,文件很大,不好查看,也没现成的对应的标注工具能看;对于yolo格式,标注文件中只有标签和坐标的相以值,所以还需要拿到图片,来获取文件的原始长宽。
VOC数据集的格式为:
$ tree -L 1 VOCdevkit/VOC2007
VOCdevkit/VOC2007
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
5 directories, 0 files
对于多个来源或年份的VOC数据,更完整的是如下格式:
VOCdevkit/
├── d1
│ ├── Annotations
│ └── JPEGImages
├── l0
│ ├── Annotations
│ └── JPEGImages
├── l1
│ ├── Annotations
│ └── JPEGImages
├── l2
│ ├── Annotations
│ └── JPEGImages
├── l3
│ ├── Annotations
│ └── JPEGImages
└── l4
├── Annotations
└── JPEGImages
18 directories, 0 files
原始文档大概是2021年写的,在2023年初进行更新,主要是代码上的改进,功能上是相似的,可以使用新代码来完成相关工作。
1 数据格式转换
要注意两点,首先是图像文件名后缀,有时是jpg,有时是JPG;其次是有些灰度图混在数据集中,这时用OpenCV打开图片,可以查看图片Channel数或用PIL打开图片,查看img.mode,如果输出是L,那么则是灰度图;但有时候灰度图重复三次,伪装成RGB图,这时我们将不会发现。当然,对于灰度图,我们处理时可以直接移除,也可以伪装成RGB图,整体对检测性能影响不大。当图片是灰度图时,darknet 会报错错误Error in load_data_detection() - OpenCV,其它框架在使用时也会有问题,因为CNN模型输入要求固定,但彩图和灰度混在一起,通道数就会发生变化。
在做其它操作前,选对数据进行正确的转换有两部分第一部分是非RGB图转换成RGB(这部分相对耗时),另一个操作是对文件夹中文件名进行处理,中文及非法符号都去除,后缀整体变小写(去除jpg,JPG等,方便后续代码处理).代码如下:
1.1 旧版代码
import os
from PIL import Image
from tqdm import tqdm
import re
import copy
def convert(datapath,background=False):
imgpaths = os.path.join('VOCdevkit',datapath,'JPEGImages')
annpaths = os.path.join('VOCdevkit',datapath,'Annotations')
if not os.path.exists(imgpaths):
print("该数据集不存")
return
imgfiles = sorted(os.listdir(imgpaths))
if not len(imgfiles):
print("该数据集中无图片")
else:
#避免使用加号、减号或者"."作为普通文件的第一个字符,文件名避免使用下列特殊字符,包括制表符和退格符
#['/', '\t', '\b', '@', '#', '$', '%', '^', '&', '*', '(', ')', '[', ']'],最长不超过255
p = "^[^+-./\s\t\b@#$%*()\[\]][^/\s\t\b@#$%*()\[\]]{1,254}$"
for imgfile in tqdm(imgfiles):
#进行文件名检查
newimgfile = copy.deepcopy(imgfile)
if not re.match(p,imgfile):
#文件名不符合要求进行处理
if not re.match("[^+-./\s\t\b@#$%*()\[\]]",imgfile[0]):
newimgfile=newimgfile[1:]
p1 = "[/\s\t\b@#$%*()\[\]]"
b = set(re.findall(p1,newimgfile))
for i in b:
newimgfile=newimgfile.replace(i,'_')
file_name,file_extend = os.path.splitext(imgfile)
new_file_name,new_file_extend = os.path.splitext(newimgfile)
imgpath = os.path.join(imgpaths,imgfile)
annpath = os.path.join(annpaths,file_name+'.xml')
destimgpath = os.path.join(imgpaths,new_file_name+file_extend)
destannpath = os.path.join(annpaths,new_file_name+'.xml')
#对图片进行重命名
os.rename(imgpath,destimgpath)
#对标注文件进行重命名
if not background:
os.rename(annpath,destannpath)
else:
destimgpath=os.path.join(imgpaths,imgfile)
img = Image.open(destimgpath)
if img.mode !='RGB':
img = img.convert('RGB')
#删除原图,保存转换后的图
os.remove(destimgpath)
img.save(destimgpath,quality=95)
file_name,file_extend = os.path.splitext(imgfile)
if not file_extend=='.jpg':
file_extend = '.jpg'
os.rename(destimgpath,file_name+file_extend)
1.2 新版代码
2023年1月28日更新新代码:
'''
Author:
Date: 2023-01-28 16:48:18
LastEditors:
LastEditTime: 2023-01-28 16:48:22
FilePath: /checkvoc/conver.py
Description:
'''
import os
import os.path as osp
from PIL import Image
from tqdm import tqdm
import re
import string
import random
import copy
def convert(datapath,background=False):
"""修改图片格式及合法的文件名
Args:
datapath (string): 绝对或相对路径的 /path1/path2/VOCdevkit/VOC2007,这样可以把这份处理代码放到任何想放的位置来执行
dataname (string): 文件夹名称
background (bool, optional): 该文件夹是否是背景图片,如果是,那么标注文件夹Annotations下为空,JPEGImages下有图
"""
imgpaths = osp.join(datapath,"JPEGImages")
annpaths = osp.join(datapath,"Annotations")
if not os.path.exists(imgpaths):
raise Exception("数据集不存在,请检查!")
if not os.path.exists(annpaths) and not background:
raise Exceptin("图片文件存在,标注文件不存在,请检查!")
imgfiles = sorted(os.listdir(imgpaths))
if not len(imgfiles):
raise Exception("该数据集中无图片,请检查!")
for imgfile in tqdm(imgfiles):
#进行文件名检查
name,suffix = osp.splitext(imgfile)
annfile = name+'.xml'
imgpath = osp.join(imgpaths,imgfile)
annpath = osp.join(annpaths,annfile)
if not osp.exists(annpath) and not background: #对于非background的图片,如果不存在标注文件则打印出来,不做后续处理
print(f"图片{imgpath}存在,但标注文件{annpath}不存在,请查看")
continue
if len(re.findall('[\W\u4e00-\u9fa5]',name)): #查找中文及除数字字母下划线外的符号
if len(re.findall('[\W\u4e00-\u9fa5]',name)):#文件名有问题
newname = re.sub('[\W\u4e00-\u9fa5]','',name) #这些特殊符号全部删除
if len(newname)==0: #删除特殊符号的文件名可能不存了,那么就随机生成一个
length = random.randint(3,10)
letters = string.ascii_lowercase
newname = ''.join(random.choice(letters) for i in range(length))
newimgfile = newname+suffix
print(f"文件名修改前:{imgfile} 修改后:{newimgfile}")
newannfile = newname+'.xml'
newimgpath = osp.join(imgpaths,newimgfile)
newannpath = osp.join(annpaths,newannfile)
#对图片进行重命名
os.rename(imgpath,newimgpath)
#对标注文件进行重命名
if not background:
os.rename(annpath,newannpath)
imgpath=newimgpath
#接着判断图片的格式
img = Image.open(imgpath)
if img.mode !='RGB':
img = img.convert('RGB')
#删除原图,保存新图
os.remove(imgpath)
img.save(imgpath,quality=95)
name,suffix = osp.splitext(imgpath)
if not suffix=='.jpg':
suffix='.jpg'
print(f"文件名修改前:{imgfile} 修改后:{name+suffix}")
os.rename(imgpath,name+suffix)
print("Done.")
2 检查数据集
2.1 旧版代码
检查数据集的目地是对数据质量、数据的整体指标做一个分析。
主要检查有:
- 图片没有标注数文件及有标注文件没有图片的数据,不区分训练验证和测试。对于正确的直接跳过,对于错误的在对应文件夹下生成result文件,把有图没标注和有标注没图的文件合部保存进去
- 检查标注文件中没有图片尺寸的情况
- 检查标注文件中有框但没有类名称的情况
- 检查标注框有问题的比如是一个点或线的框
- 获取数据集的统计信息:
- 图片总数、标注框总数及每张图的平均框数
- 按类进行图片数和标注框数量的统计
- 统计标注文件中所有的标注类别(有错误类别如车标注成car和carr,不论对错全部统计)
- 单图标注框数量的分布(已画图)
- 图片高度分布(未画图)
- 图片宽度分布(未画图)
- 图片面积分布(未画图)
- 图片高宽比分布(已画图)
- 按类别进行框与图面积比
这些统计值的应用主要是加深对数据的理解,有助于针对性的提升检测精度.
import os
import shutil
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as plt
from collections import defaultdict
import xml.etree.ElementTree as ET
def check(year='VOC2007',show=False):
"""
输入数据文件名,返回有图没标注文件和有标注文件没图的数据路径
"""
######################################################################################################
##########################本节代码检查只有图或只有标注文件的情况##########################################
#######################################################################################################
data_path=os.path.join("VOCdevkit",year)
imgs_path = os.path.join(data_path,'JPEGImages')
anns_path = os.path.join(data_path,'Annotations')
#获取图片文件
img_names = set([os.path.splitext(i)[0] for i in os.listdir(imgs_path)])
ann_names = set([os.path.splitext(i)[0] for i in os.listdir(anns_path)])
print("########################################################################################数据集{}检验结果如下:######################################################################################################".format(year))
if not len(img_names):
print(' 该数据集没有图片')
return
img_ann = img_names-ann_names #有图没标注文件
ann_img = ann_names-img_names #有标注文件没有图
if len(img_ann):
print(" 有图片没标注文件的图片是:{} 等(只列前50个) 注意检查这些图片是否是背景图片".format({v for k,v in enumerate(img_ann) if k<50}))
else:
print(" 所有图片都有对应标注文件")
if len(ann_img):
print(" 有标注文件没有图片的标注文件是:{}(只列前50个)".format({v for k,v in enumerate(ann_img) if k<50}))
else:
print(" 所有标注文件都有对应图片")
#####################################################################################################
#######本节代码对于上节检查结果有问题的图片和标注文件统一移动到结果文件夹中进行下一步查看 ##################
#####################################################################################################
result_path = os.path.join(data_path,year+'_result')
if os.path.exists(result_path):
print(' 结果文件{}已经存在,请检查'.format(result_path))
else:
os.makedirs(result_path)
if len(ann_img)+len(img_ann):
# 把只有图或只有标注文件的数据集全部移出来
if (not os.path.exists(result_path)):
os.makedirs(result_path)
else:
print(' 存在有图无标注或有标注无图的文件,另结果文件{}已经存在,请检查'.format(result_path))
# return
img_anns = [os.path.join(imgs_path,i+'.jpg') for i in img_ann]
ann_imgs = [os.path.join(anns_path,i+'.xml') for i in ann_img]
if len(img_anns):
for img in img_anns:
shutil.move(img,result_path)
print(' 移动只有图无标注文件完成')
if len(ann_img):
for ann in ann_imgs:
shutil.move(ann,result_path)
print(' 移动只有标注文件无图完成')
###################################################################################################
##########本节内容提取分类文件夹标注文件夹中所有的分类类别,这个部分由于数据可能是#######################
##########多个人标的,所在对于使用数据的人还是要看一下分类的,很有必要 #######################
ann_names_new = [os.path.join(anns_path,i) for i in os.listdir(anns_path)]#得新获取经过检查处理的标注文件
total_images_num = len(ann_names_new)
classes=list() #用来存放所有的标注框的分类名称
img_boxes = list() #用来存放单张图片的框的个数
hw_percents = list() #用来存放图像的高宽比,因为图像是要进行resize的,所以可能会有resize和scaled resize区分
num_imgs = defaultdict(int) # 存放每个分类有多少张图片出现
num_boxes = dict() # 存放每个分类有多少个框出现
h_imgs = list() # 存放每张图的高
w_imgs = list() # 存放每张图的宽
area_imgs = list() #存放每张图的面积
h_boxes = defaultdict(list) #存放每个分类框的高
w_boxes = defaultdict(list) #存放每个分类框的宽
area_boxes = defaultdict(list) #存放每个分类框的面积
area_percents = defaultdict(list) #存放每个分类框与图像面积的百分比
for ann in tqdm(ann_names_new):
try:
in_file=open(ann)
tree=ET.parse(in_file)
except:
print(f"打开标注文件{ann}失败,文件将被处理")
shutil.move(ann,result_path)
im_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')
shutil.move(im_path,result_path)
continue
root =tree.getroot()
try:
size = root.find('size')
# print image_id
w = int(size.find('width').text)
h = int(size.find('height').text)
except:
print(f"取标注尺寸错误,标注文件{ann}将被处理")
shutil.move(ann,result_path)
im_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')
shutil.move(im_path,result_path)
continue
img_area = w * h
if img_area< 100:
print(f"有标注文件{ann}无图片尺寸,将被处理")
shutil.move(ann,result_path)
im_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')
shutil.move(im_path,result_path)
continue
img_boxes.append(len(root.findall('object')))
if not len(root.findall('object')):
print(f"有标注文件{ann}但没有标注物体,将被处理")
shutil.move(ann,result_path)
i_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')
shutil.move(i_path,result_path)
continue
img_classes=[]
ok_flag=True
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls_name = obj.find('name').text
if isinstance(cls_name,type(None)) :
print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}")
shutil.move(ann,result_path)
ok_flag=False
continue
elif isinstance(cls_name,str) and len(cls_name)<2:
ok_flag=False
print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}")
shutil.move(ann,result_path)
continue
else:
pass
# if int(difficult) == 1:
# continue
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) #左,右,上,下
if int(b[1]-b[0])==0 or int(b[3]-b[2])==0:
ok_flag=False
print(f"有零存在,框为点或直线,将被处理,边框:{b},标注文件:{ann},类名称:{cls_name},标注文件:{ann}")
shutil.move(ann,result_path)
box_area = (b[1]-b[0])*(b[3]-b[2])
area_percent = round(np.sqrt(box_area/float(img_area)),3)*100
hw_percents.append(float(h/w))
if not (cls_name in classes):
classes.append(cls_name)
img_classes.append(cls_name)
num_boxes[cls_name]= num_boxes.get(cls_name,0)+1
h_boxes[cls_name].append(int(b[3]-b[2]))
w_boxes[cls_name].append(int(b[1]-b[0]))
area_boxes[cls_name].append(int(box_area))
area_percents[cls_name].append(area_percent)
if ok_flag:
h_imgs.append(h)
w_imgs.append(w)
area_imgs.append(img_area)
for img_cls_name in set(img_classes):
num_imgs[img_cls_name] = num_imgs.get(img_cls_name,0)+1
classes=sorted(classes)
print(f"数据集{year}一共有{total_images_num}张合格的标注图片,{sum(img_boxes)}个标注框,平均每张图有{round(sum(img_boxes)/total_images_num,2)}个标注框;一共有{len(classes)}个分类,分别是{classes};图片中标注框个数最少是{min(img_boxes)}, \
最多是{max(img_boxes)}.图片高度最小值是{min(h_imgs)},最大值是{max(h_imgs)};图片宽度最小值是{min(w_imgs)},最大值是{max(w_imgs)}; \
图片面积最小值是{min(area_imgs)},最大值是{max(area_imgs)} ;图片高宽比最小值是{round(min(hw_percents),2)},图片高宽比最大值是{round(max(hw_percents),2)}")
num_imgs_class = [num_imgs[class_name] for class_name in classes]
num_boxes_class = [num_boxes[class_name] for class_name in classes] #各分类的标注框个数
min_h_boxes = [min(h_boxes[class_name]) for class_name in classes] #各分类标注框高度最小值
max_h_boxes = [max(h_boxes[class_name]) for class_name in classes] #各分类标注框高度最大值
min_w_boxes = [min(w_boxes[class_name]) for class_name in classes] #各分类标注框宽度最小值
max_w_boxes = [max(w_boxes[class_name]) for class_name in classes] #各分类标注框宽度最大值
min_area_boxes = [min(area_boxes[class_name]) for class_name in classes] #各分类标注框面积最小值
max_area_boxes = [max(area_boxes[class_name]) for class_name in classes] #各分类标注框面积最大值
min_area_percents = [min(area_percents[class_name]) for class_name in classes] #各分类标注框面积与图像面积比最小值
max_area_percents = [max(area_percents[class_name]) for class_name in classes] #各分类标注框面积与图像面积比最大值
result = {'cls_names':classes,'images':num_imgs_class,'objects':num_boxes_class,'min_h_bbox':min_h_boxes,'max_h_bbox':max_h_boxes,'min_w_bbox':min_w_boxes,
'max_w_bbox':max_w_boxes,'min_area_bbox':min_area_boxes,'max_area_bbox':max_area_boxes,'min_area_box/img':min_area_percents,'max_area_box/img':max_area_percents}
#显示所有列(参数设置为None代表显示所有行,也可以自行设置数字)
pd.set_option('display.max_columns',None)
#显示所有行
pd.set_option('display.max_rows',None)
#设置数据的显示长度,默认为50
pd.set_option('max_colwidth',50)
#禁止自动换行(设置为Flase不自动换行,True反之)
pd.set_option('expand_frame_repr', False)
result_df = pd.DataFrame(result)
print(result_df)
# plt.figure(figsize=(10.8,6.4))
# result_df.iloc[:,1:3].plot(kind='bar',)
if show:
##############################################画各个类别图片数与框数的直方图############################################################
plt.figure(figsize=(15,6.4))
x1 = [i+4*i for i in range(len(classes))]
x2 = [i+2 for i in x1]
y1= [int(num_boxes[cl]) for cl in classes]
y2 = [int(num_imgs[cl]) for cl in classes]
lb1=["" for i in x1]
lb2=classes
plt.bar(x1,y1,alpha=0.7,width=2,color='b',label='objects',tick_label=lb1)
plt.bar(x2,y2,alpha=0.7,width=2,color='r',label='images',tick_label=lb2)
plt.xticks(rotation=45)
# plt.axis('off')
plt.legend()
#plt.savefig
##############################################画单张图标注框数量的直方图################################################################
#接着用直方图把这些结果画出来
plt.figure(figsize=(15,6.4))
# 定义组数,默认60
# 定义一个间隔大小
a = 1
# 得出组数
group_num= int((max(img_boxes) - min(img_boxes)) / a)
n,bins,patches=plt.hist(x=img_boxes,bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance=int((max(img_boxes)-min(img_boxes)) /group_num)
if distance<1:
distance=1
plt.xticks(range(min(img_boxes),max(img_boxes)+2,distance),fontsize=8)
# 辅助显示设置
plt.xlabel('number of bbox in each image')
plt.ylabel('image numbers')
plt.xticks(rotation=45)
plt.title(f"The number of bbox min:{round(np.min(img_boxes),2)},max:{round(np.max(img_boxes),2)} \n mean:{round(np.mean(img_boxes),2)} std:{round(np.std(img_boxes),2)}")
plt.grid(True)
plt.tight_layout()
##############################################画单张图高宽比的直方图################################################################
plt.figure(figsize=(15,6.4))
# 定义组数,默认60
a = 0.1
# 得出组数
group_num= int((max(hw_percents) - min(hw_percents)) / a)
n,bins,patches=plt.hist(x=hw_percents,bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance=int((max(hw_percents)-min(hw_percents)) /group_num)
if distance<1:
distance=1
plt.xticks(range(int(min(hw_percents)),int(max(hw_percents))+2,distance),fontsize=8)
# 辅助显示设置
plt.xlabel('image height/width in each image')
plt.ylabel('image numbers')
plt.xticks(rotation=45)
plt.title(f"image height/width min:{round(np.min(hw_percents))},max:{round(np.max(hw_percents),2)} \n mean:{round(np.mean(hw_percents),2)} std:{round(np.std(hw_percents),2)}")
plt.grid(True)
plt.tight_layout()
##############################################画各个分类框图面积比直方图################################################################
plt.figure(figsize=(8*3,8*round(len(classes)/3)))
for i,name in enumerate(classes):
plt.subplot(int(np.ceil(len(classes)/3)),3,i+1)
# 定义组数,默认60
a = 5
# 得出组数
group_num= int((max(area_percents[name]) - min(area_percents[name])) / a)
n,bins,patches=plt.hist(x=area_percents[name],bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数
# 组距
distance=int((max(area_percents[name])-min(area_percents[name])) /group_num)
if distance<1:
distance=1
plt.xticks(range(int(min(area_percents[name])),int(max(area_percents[name]))+2,distance),fontsize=8)
# 辅助显示设置
plt.xlabel('area percent bbox/img')
plt.ylabel('boxes numbers')
plt.xticks(rotation=45)
plt.title(f"id {i+1} class {name} area percent min:{round(np.min(area_percents[name]),2)},max:{round(np.max(area_percents[name]),2)} \n mean:{round(np.mean(area_percents[name]),2)} std:{round(np.std(area_percents[name]),2)}")
plt.grid(True)
plt.tight_layout()
以VOC2007数据集为例,查看一下处理结果
check('VOC2007',True)
########################################################################################数据集VOC2007检验结果如下:######################################################################################################
所有图片都有对应标注文件
所有标注文件都有对应图片
100%|██████████| 9963/9963 [00:02<00:00, 4454.07it/s]
数据集VOC2007一共有9963张合格的标注图片,30638个标注框,平均每张图有3.08个标注框;一共有20个分类,分别是['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'];图片中标注框个数最少是1, 最多是42.图片高度最小值是96,最大值是500;图片宽度最小值是127,最大值是500; 图片面积最小值是43090,最大值是250000 ;图片高宽比最小值是0.19,图片高宽比最大值是3.21
cls_names images objects min_h_bbox max_h_bbox min_w_bbox max_w_bbox min_area_bbox max_area_bbox min_area_box/img max_area_box/img
0 aeroplane 445 642 13 465 14 499 208 213642 3.4 99.8
1 bicycle 505 807 9 499 10 499 110 186626 2.4 99.8
2 bird 622 1175 9 490 5 498 126 217070 2.6 99.5
3 boat 364 791 5 497 4 499 44 186127 1.6 99.6
4 bottle 502 1291 10 499 4 468 80 152195 2.1 99.7
5 bus 380 526 9 475 12 499 198 188325 3.2 99.7
6 car 1536 3185 4 497 6 499 48 196560 1.6 99.7
7 cat 676 759 22 499 25 499 625 241056 5.8 99.7
8 chair 1117 2806 5 499 4 499 78 212768 2.0 99.8
9 cow 273 685 7 490 7 499 56 179280 1.8 97.8
10 diningtable 510 609 10 476 21 499 567 185754 5.7 99.5
11 dog 863 1068 10 499 10 499 100 232035 2.3 99.7
12 horse 573 801 21 499 11 499 297 197691 4.0 99.3
13 motorbike 482 759 18 498 7 499 182 198000 3.1 99.4
14 person 4192 10674 8 499 4 499 48 248003 1.7 99.8
15 pottedplant 527 1217 6 499 6 498 84 226080 2.1 99.6
16 sheep 195 664 5 482 9 485 45 226980 1.5 96.2
17 sofa 727 821 31 499 24 499 1638 209237 9.4 99.8
18 train 522 630 20 499 20 499 725 186127 6.2 99.6
19 tvmonitor 534 728 11 498 11 499 176 185754 3.4 99.5
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lu2z2khu-1626945666909)(output_4_3.png)]](https://img-blog.csdnimg.cn/img_convert/b2b535a43fa019699b7ca31cea3597c7.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qFxaVR2v-1626945666913)(output_4_4.png)]](https://img-blog.csdnimg.cn/img_convert/910a1d031c27781798658323bd897e52.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ttxsPRaN-1626945666917)(output_4_5.png)]](https://img-blog.csdnimg.cn/img_convert/73b629376a23868f0d1552d1502a1cc5.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cwF5wFJ0-1626945666924)(output_4_6.png)]](https://img-blog.csdnimg.cn/img_convert/18bb6f85e32044dba2787cfd9d52ce15.png)
2.2 新版代码
类似旧版代码,会对数据的正确性和相关统计信息进行生成,并保存到相关文件中。
import os
import re
import os.path as osp
import shutil
import copy
import pandas as pd
import numpy as np
from glob import glob
from tqdm import tqdm
import matplotlib.pyplot as plt
from collections import defaultdict
import xml.etree.ElementTree as ET
def check_statistic(srcpath,savepath):
"""_summary_
对VOC数据集做正确性的检查及获得数据分析的结果,如目标大小,是否存在小目标,图片分辨率
标注框密度等
Args:
srcpath (str):VOC数据集路径,在JPEGImages和Annotations上一级
savepath (str): 保存统计结果的位置
"""
imgs = glob(osp.join(srcpath,"JPEGImages",'*.jpg'))
lbs = glob(osp.join(srcpath,"Annotations",'*.xml'))
total_imgs_num = len(imgs)
all_imgs_num = copy.deepcopy(total_imgs_num)
if osp.exists(savepath):
shutil.rmtree(savepath)
os.makedirs(savepath,exist_ok=False)
bad_lbs = [] #存放有标注问题的标注文件
bad_imgs = [] #宽或高小于32的图片
classes = [] #存放所有标注类别
imgs_h = [] #存放所有图片的高
imgs_w = [] #存放所有图片的宽
imgs_wh_percent = [] #存放所有图片的宽高比
box_num_per_img = [] #存图每张图中标注框的数量
num_boxes = defaultdict(int) #存放每个分类标注框的数量
num_imgs = defaultdict(int) # 存放每个分类标注框对应的图片数
boxes_h = defaultdict(list) # 存放每个分类标注框的高
boxes_w = defaultdict(list) # 存放每个分类标注框的宽
boxes_wh_percent = defaultdict(list) #存放每个分类标注框的宽高比
boxes_imgs_area_percent = defaultdict(list) #存放每个分类标注框与相应图片的面积比
for lb in tqdm(lbs,desc="Start deal xmls:"):
try:
tree = ET.parse(lb)
except:
bad_lbs.append(lb+'can not open\n')
total_imgs_num -= 1
continue
root = tree.getroot()
try:
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
except:
bad_lbs.append(lb+'no img size\n')
total_imgs_num -= 1
continue
if w<32 or h<32:
bad_imgs.append(lb+'to small img\n')
total_imgs_num -= 1
continue
#获取单张图标注框的数量
box_num = len(root.findall('object'))
if not box_num: #xml文件中一个标注框都没有
bad_lbs.append(lb+' no obj\n')
total_imgs_num -= 1
continue
okflag=True
clsname_areas = [] #暂存每个框的类别名称及面积
img_classes = [] # 用来暂时存放每张中出现框的类别
#对每个标注框进行编历
for obj in root.iter('object'):
clsname = obj.find('name').text
#如果没有类名称,则不对这个框进行处理
if clsname is None:
okflag=False
box_num -= 1
bad_lbs.append(lb+' no clsname\n')
continue
# 如果是字符串中发现非单词字符、中文、减号,则不对这个框进行处理
elif isinstance(clsname,str) and len(re.findall('[^A-Z,a-z,0-9,\u4e00-\u9fa5,-]',clsname)):
okflag=False
box_num -= 1
bad_lbs.append(lb+'wrong file name\n')
continue
# 剩余类型下说明object的name是合适的
xmlbox = obj.find('bndbox')
bx = [float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text)] # 框的左右
by = [float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text)] # 框的上下
# 内眼不可区分、点或线这类不合法框检测,则不对这个框进行处理
bw = int(bx[1]-bx[0])
bh = int(by[1]-by[0])
if bw<4 or bh<4:
okflag=False
box_num -= 1
bad_lbs.append(lb+' too small obj\n')
continue
#以下说明当前这个框是合格的
classes.append(clsname)
img_classes.append(clsname)
box_area = bw*bh
num_boxes[clsname] = num_boxes.get(clsname,0)+1
boxes_h[clsname].append(bh)
boxes_w[clsname].append(bw)
boxes_wh_percent[clsname].append(bw*1.0/bh)
clsname_areas.append((clsname,box_area))#由于之前不知道是否存在合格的标注框,之前没有计算图片面积所以完成计算
if okflag: #所有标注框都是合适的
imgs_h.append(h)
imgs_w.append(w)
imgs_wh_percent.append(w*1./h)
# 获取图片面积
img_area = h*w
# 生成框与图片面积比
for clsname,area in clsname_areas:
boxes_imgs_area_percent[clsname].append(area*1.0/img_area)
box_num_per_img.append(box_num)
#做一个每张图中类别的数量
for img_clsname in set(img_classes):
num_imgs[img_clsname] = num_imgs.get(img_clsname,0) + 1
# else:
# print("not ok:",lb)
#获取所有分类
classes = sorted(list(set(classes)))
#保存标注有问题的标注文件
if len(bad_lbs):
with open(osp.join(savepath,'bad_labels.txt'),'w') as f:
f.writelines(bad_lbs)
#保存有特别小尺寸图片
if len(bad_imgs):
with open(osp.join(savepath,'bad_images.txt'),'w') as f:
f.writelines(bad_imgs)
######################################### 以下开始做相关统计工作####################################################
result = f"数据集{srcpath}共有{all_imgs_num}张图片,其中{total_imgs_num}张合格的标注图,\
{len(bad_lbs)}张标注有问题,{len(bad_imgs)}图片太小。\
\n总共有{len(classes)}个分类,分别是:{classes} \
\n标注框总数是:{sum(box_num_per_img)}个,单图最多框数:{max(box_num_per_img)},单图最少框数:{min(box_num_per_img)}, \
单图平均框数:{round(np.mean(box_num_per_img),2)}; \
\n图片宽度最大值:{max(imgs_w)},图片宽度最小值:{min(imgs_w)},图片宽度平均值:{round(np.mean(imgs_w),2)}; \
\n图片高度最大值:{max(imgs_h)},图片高度最小值:{min(imgs_h)},图片高度平均值:{round(np.mean(imgs_h),2)}; \
\n图片宽高比最大值:{round(max(imgs_wh_percent),2)},图片宽高比最小值:{min(imgs_wh_percent)},图片宽高比平均值:{round(np.mean(imgs_wh_percent),2)};\n"
print(result)
num_imgs_per_class = [num_imgs[class_name] for class_name in classes] #统计每个分类占的图片数
num_boxes_per_class = [num_boxes[class_name] for class_name in classes]#统计每个分类占的标注框数
min_h_boxes_per_class = [min(boxes_h[class_name]) for class_name in classes]#统计每个分类标注框高度的最小值
max_h_boxes_per_class = [max(boxes_h[class_name]) for class_name in classes]#统计每个分类标注框高度的最大值
mean_h_boxes_per_class = [round(np.mean(boxes_h[class_name]),2) for class_name in classes]#统计每个分类标注框高度的平均值
min_w_boxes_per_class = [min(boxes_w[class_name]) for class_name in classes]#统计每个分类标注框高度的最小值
max_w_boxes_per_class = [max(boxes_w[class_name]) for class_name in classes]#统计每个分类标注框高度的最大值
mean_w_boxes_per_class = [round(np.mean(boxes_w[class_name]),2) for class_name in classes]#统计每个分类标注框高度的平均值
min_wh_percent_boxes_per_class = [min(boxes_wh_percent[class_name]) for class_name in classes]#统计每个分类标注框宽高比的最小值
max_wh_percent_boxes_per_class = [max(boxes_wh_percent[class_name]) for class_name in classes]#统计每个分类标注框宽高比的最大值
mean_wh_percent_boxes_per_class = [round(np.mean(boxes_wh_percent[class_name]),2) for class_name in classes]#统计每个分类标注框宽高比的平均值
min_boxearea_percent_per_class = [min(boxes_imgs_area_percent[class_name]) for class_name in classes]#统计每个分类标注框宽高比的最小值
max_boxearea_percent_per_class = [max(boxes_imgs_area_percent[class_name]) for class_name in classes]#统计每个分类标注框宽高比的最大值
mean_boxearea_percent_per_class = [round(np.mean(boxes_imgs_area_percent[class_name]),2) for class_name in classes]#统计每个分类标注框宽高比的平均值
# 以上统计结果生成到表格
pd.set_option('display.max_columns',None)#None代表显示所有列
pd.set_option('display.max_rows',None)#显示所有行
pd.set_option('max_colwidth',50)#设置数据显示长度,默认为50
pd.set_option('expand_frame_repr',False)#禁止自动换行
pd.set_option('display.unicode.ambiguous_as_wide',True)
pd.set_option('display.unicode.east_asian_width',True)
pd.set_option('display.colheader_justify','center') #列名居中
result_df={"clsname":classes,"img_num":num_imgs_per_class,"obj_num":num_boxes_per_class,"box_min_h":min_h_boxes_per_class,
"box_max_h":max_h_boxes_per_class,"box_mean_h":mean_h_boxes_per_class,"box_min_w":min_w_boxes_per_class,"box_max_w":max_w_boxes_per_class,
"box_mean_w":mean_w_boxes_per_class,"min_box_w/h":min_wh_percent_boxes_per_class,"max_box_w/h":max_wh_percent_boxes_per_class,
"mean_box_w/h":mean_wh_percent_boxes_per_class,"min_area_percent":min_boxearea_percent_per_class,
"max_area_percent":max_boxearea_percent_per_class,"mean_area_percent":mean_boxearea_percent_per_class}
result_df = pd.DataFrame(result_df)
print(result_df)
result_report=f"{result}\n{result_df}"
with open(osp.join(savepath,'statistics.txt'),'w') as f:
f.writelines(result_report)
##########################先画每个分类的图片数和标注框的数量##########################
plt.figure(figsize=(15,6.4))
x1 = [i+4*i for i in range(len(classes))]
x2 = [i+2 for i in x1]
y1 = num_boxes_per_class
y2 = num_imgs_per_class
lb1= ['']*len(classes)
lb2=classes
plt.bar(x1,y1,alpha=0.7,width=2,color='b',label='objects',tick_label=lb1)
plt.bar(x2,y2,alpha=0.7,width=2,color='r',label='images',tick_label=lb2)
plt.xticks(rotation=45)
plt.legend()
plt.savefig(osp.join(savepath,'image_objects_statistics_per_class.jpg'))
##########################单张图标注框数量的直方图##################################
plt.figure(figsize=(15,6.4))
#定义组数及组距
distance = 1
group_num = int((max(box_num_per_img)-min(box_num_per_img)) // distance)
if group_num<=0 or group_num>40:
group_num=40
n,bins,patches=plt.hist(x=box_num_per_img,bins=group_num,color="green",edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k],n[k]*1.02,int(n[k]),fontsize=12,horizontalalignment='center')
plt.xticks(range(min(box_num_per_img),max(box_num_per_img)+2,distance),fontsize=8)
plt.xlabel("Number of bounding box in each image")
plt.ylabel("Image numbers")
plt.xticks(rotation=45)
plt.title(f"The number of bbox min:{min(box_num_per_img)},max:{max(box_num_per_img)}\n \
mean:{round(np.mean(box_num_per_img),2)},std:{round(np.std(box_num_per_img),2)}")
plt.grid(True)
plt.tight_layout()
plt.savefig(osp.join(savepath,'bbox_distribution.jpg'))
##########################################画单张图宽高比直方图#######################################
plt.figure(figsize=(15,6.4))
#定义组数及组距
distance = 0.1
group_num = int((max(imgs_wh_percent)-min(imgs_wh_percent)) // distance)
if group_num<=0 or group_num>20:
group_num=20
n,bins,patches=plt.hist(x=imgs_wh_percent,bins=group_num,color="green",edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k],n[k]*1.02,int(n[k]),fontsize=12,horizontalalignment='center')
if distance<1:
distance=1
plt.xticks(np.linspace(min(imgs_wh_percent),max(imgs_wh_percent)+0.1,group_num),fontsize=8)
plt.xlabel("image width/height for each image")
plt.ylabel("Image numbers")
plt.xticks(rotation=45)
plt.title(f"Image width/height min:{round(min(imgs_wh_percent),2)},max:{round(max(imgs_wh_percent),2)}\n \
mean:{round(np.mean(imgs_wh_percent),2)},std:{round(np.std(imgs_wh_percent),2)}")
plt.grid(True)
plt.tight_layout()
plt.savefig(osp.join(savepath,'img_wh_percent_distribution.jpg'))
######################################画每个类别标注框高宽比分布##########################################
plt.figure(figsize=(10*2,8*int(np.ceil(len(classes)/2)))) #画图为2列n行
for i,name in enumerate(classes):
plt.subplot(int(np.ceil(len(classes)/2)),2,i+1)
distance = 0.1
boxes_wh_percent_class = boxes_wh_percent[name]
group_num = int((max(boxes_wh_percent_class)-min(boxes_wh_percent_class)) // distance)
n,bins,patches=plt.hist(x=boxes_wh_percent_class,bins=group_num,color="green",edgecolor='red',density=False,rwidth=0.8)
if group_num<=0 or group_num>20:
group_num=20
for k in range(len(n)):
plt.text(bins[k],n[k]*1.02,int(n[k]),fontsize=12,horizontalalignment='center')
plt.xticks(np.linspace(min(boxes_wh_percent_class),max(boxes_wh_percent_class)+0.1,group_num),fontsize=8)
plt.xlabel("Boxes width/height for each image")
plt.ylabel("Boxex numbers")
plt.xticks(rotation=45)
plt.title(f"Class:{name} bbox width/height min:{round(min(boxes_wh_percent_class),2)},max:{round(max(boxes_wh_percent_class),2)}\n \
mean:{round(np.mean(boxes_wh_percent_class),2)},std:{round(np.std(boxes_wh_percent_class),2)}")
plt.grid(True)
plt.tight_layout()
plt.savefig(osp.join(savepath,'bbox_wh_percent_distribution_for_each_class.jpg'))
######################################画每个类别标注框占图片面积比分布##########################################
plt.figure(figsize=(8*3,8*int(np.ceil(len(classes)/3))))#画图为3列n行
for i,name in enumerate(classes):
plt.subplot(int(np.ceil(len(classes)/3)),3,i+1)
distance = 0.1
boxes_imgs_area_percent_class = boxes_imgs_area_percent[name]
group_num = int((max(boxes_imgs_area_percent_class)-min(boxes_imgs_area_percent_class)) // distance)
if group_num<=0 or group_num>20:
group_num=20
n,bins,patches=plt.hist(x=boxes_imgs_area_percent_class,bins=group_num,color="green",edgecolor='red',density=False,rwidth=0.8)
for k in range(len(n)):
plt.text(bins[k],n[k]*1.02,int(n[k]),fontsize=12,horizontalalignment='center')
plt.xticks(np.linspace(min(boxes_imgs_area_percent_class),max(boxes_imgs_area_percent_class)+0.1,group_num),fontsize=8)
plt.xlabel("Boxes width/height for each image")
plt.ylabel("Boxex numbers")
plt.xticks(rotation=45)
plt.title(f"Class:{name} bbox/img area percent min:{round(min(boxes_imgs_area_percent_class),2)},max:{round(max(boxes_imgs_area_percent_class),2)}\n \
mean:{round(np.mean(boxes_imgs_area_percent_class),2)},std:{round(np.std(boxes_imgs_area_percent_class),2)}")
plt.grid(True)
plt.tight_layout()
plt.savefig(osp.join(savepath,'bbox_area_percent_distribution_for_each_class.jpg'))
check_statistic(srcpath="voc/VOCdevkit/VOC2007",savepath='test')
结果如下:
Start deal xmls:: 100%|██████████| 9963/9963 [00:00<00:00, 12954.22it/s]
数据集voc/VOCdevkit/VOC2007共有9963张图片,其中9963张合格的标注图,0张标注有问题,0图片太小。
总共有20个分类,分别是:['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
标注框总数是:30638个,单图最多框数:42,单图最少框数:1, 单图平均框数:3.08;
图片宽度最大值:500,图片宽度最小值:127,图片宽度平均值:471.98;
图片高度最大值:500,图片高度最小值:96,图片高度平均值:382.59;
图片宽高比最大值:5.21,图片宽高比最小值:0.312,图片宽高比平均值:1.28;
clsname img_num obj_num box_min_h box_max_h box_mean_h box_min_w box_max_w box_mean_w min_box_w/h max_box_w/h mean_box_w/h min_area_percent max_area_percent mean_area_percent
0 aeroplane 445 642 13 465 120.60 14 499 255.70 0.479675 5.750000 2.27 0.001143 0.995339 0.25
1 bicycle 505 807 9 499 150.90 10 499 164.31 0.196721 4.733333 1.13 0.000587 0.995339 0.19
2 bird 622 1175 9 490 139.62 5 498 139.63 0.185185 4.556818 1.11 0.000672 0.990688 0.16
3 boat 364 791 5 497 104.25 4 499 136.13 0.136929 9.700000 1.67 0.000246 0.992677 0.13
4 bottle 502 1291 10 499 106.62 4 468 46.87 0.086735 5.500000 0.49 0.000427 0.993661 0.05
5 bus 380 526 9 475 158.10 12 499 218.42 0.134771 5.867647 1.52 0.001056 0.995003 0.25
6 car 1536 3185 4 497 100.40 6 499 161.45 0.097744 8.481481 1.72 0.000256 0.995003 0.16
7 cat 676 759 22 499 240.31 25 499 270.09 0.244292 4.868421 1.23 0.003333 0.995003 0.41
8 chair 1117 2806 5 499 113.18 4 499 97.33 0.089041 6.906977 0.95 0.000416 0.995339 0.08
9 cow 273 685 7 490 125.88 7 499 131.55 0.130112 11.281250 1.17 0.000336 0.956160 0.14
10 diningtable 510 609 10 476 152.38 21 499 288.46 0.172131 10.944444 2.21 0.003281 0.990688 0.28
11 dog 863 1068 10 499 214.84 10 499 231.66 0.300699 4.333333 1.16 0.000533 0.995003 0.32
12 horse 573 801 21 499 198.73 11 499 191.13 0.204348 4.141414 1.01 0.001584 0.986024 0.27
13 motorbike 482 759 18 498 172.26 7 499 199.57 0.269231 6.326531 1.17 0.000971 0.988699 0.25
14 person 4192 10674 8 499 167.05 4 499 106.76 0.070769 6.750000 0.64 0.000277 0.995339 0.15
15 pottedplant 527 1217 6 499 124.47 6 498 93.81 0.058442 4.659091 0.82 0.000448 0.992935 0.10
16 sheep 195 664 5 482 99.98 9 485 105.30 0.255319 4.108108 1.16 0.000240 0.924890 0.10
17 sofa 727 821 31 499 190.53 24 499 291.95 0.266304 10.121951 1.63 0.008928 0.995339 0.36
18 train 522 630 20 499 180.40 20 499 285.89 0.120536 15.500000 1.96 0.003867 0.992677 0.34
19 tvmonitor 534 728 11 498 121.01 11 499 123.42 0.241379 7.466667 1.04 0.001159 0.990688 0.12

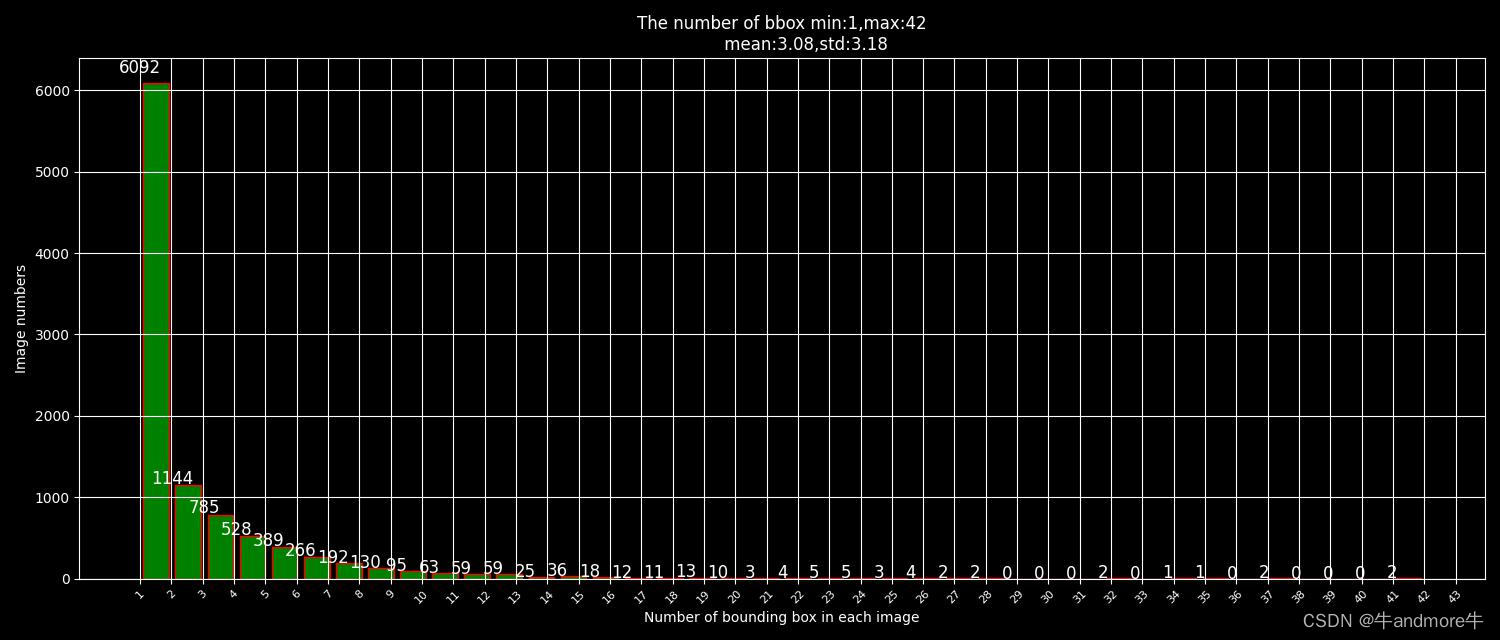
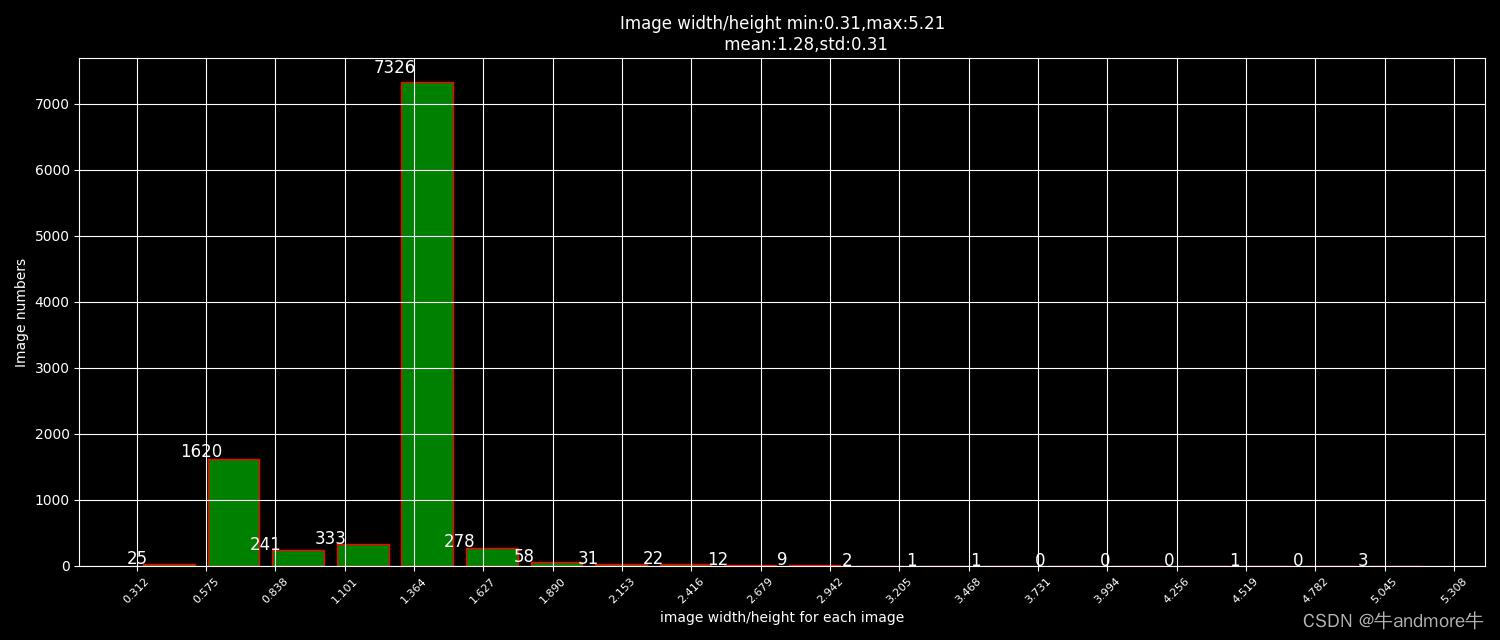
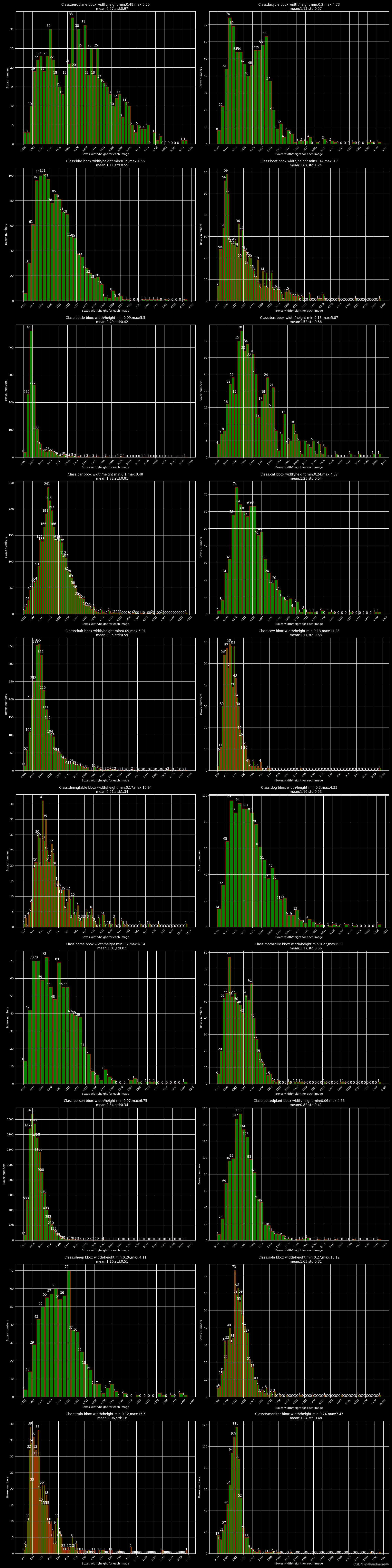
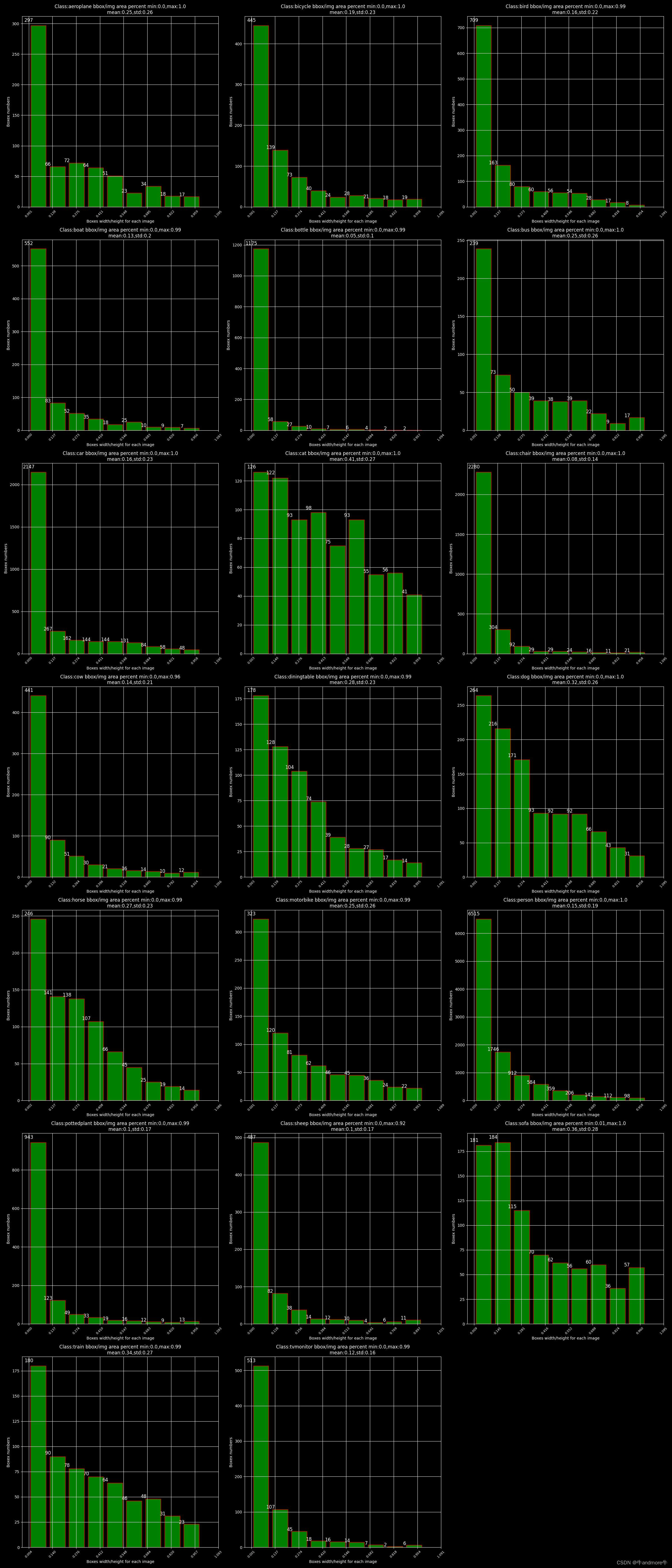
这些图片还有生成的统计信息都会保存到文件夹中,如下:
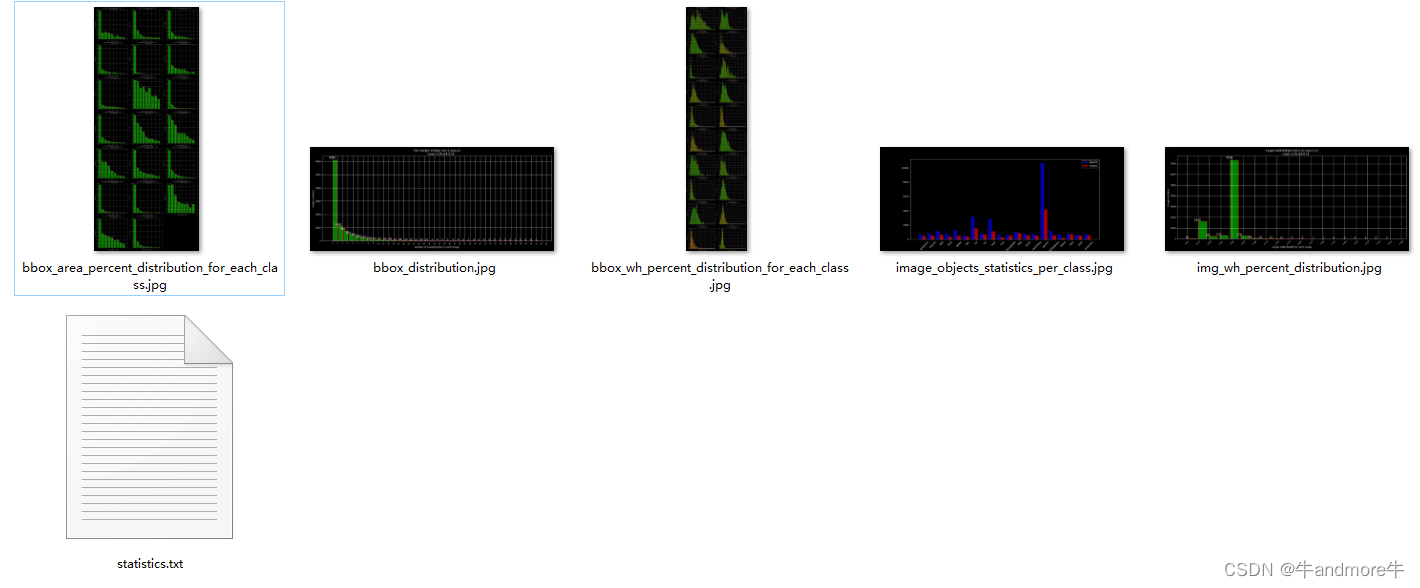
3 移除特定分类的数据
应用场景就是把某些分类数据从原始数据集中移出,比如人工标注的数据集有些标错了,如把car标成carr,那么我们需要把有carr这一类的图片和他对应的标注文件移出,然后对于移出后的数据,我们可以进行进行改正和其他进一步处理。
3.1 旧版代码
移出后保存但置对应数VOCdevkit/数据名/据集名_result
import os
import shutil
from tqdm import tqdm
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from collections import defaultdict
import xml.etree.ElementTree as ET
def remove_classes(year='VOC2007',classes=None):
"""
输入数据文件名,将指定分类数据移出
classes:如果是None,那么保持原数据集不变,否则是个列表,列出要移动的分类即可
"""
######################################################################################################
##########################本节代码检查只有图或只有标注文件的情况##########################################
#######################################################################################################
data_path=os.path.join("VOCdevkit",year)
imgs_path = os.path.join(data_path,'JPEGImages')
anns_path = os.path.join(data_path,'Annotations')
if not len(os.listdir(imgs_path)):
print(' 该数据集没有图片')
return
#####################################################################################################
###############################################################保存结果文件 ##########################
#####################################################################################################
result_path = os.path.join(data_path,year+'_result')
if os.path.exists(result_path):
print(' 结果文件{}已经存在,请检查'.format(result_path))
else:
os.makedirs(result_path)
if classes is not None:
source_anns=os.listdir(anns_path)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(anns_path,source_ann))
root = tree.getroot()
result = root.findall("object")
for obj in result:
if obj.find("name").text in classes:
shutil.move(os.path.join(anns_path,source_ann),result_path)
img_path = os.path.join(data_path,'JPEGImages',os.path.splitext(source_ann)[0])+'.jpg'
shutil.move(img_path,result_path)
break
else:
pass
比如数据集VOC2007,20个分类中车辆类有car,bicycle,motobike,bus四类,我们将其移出
remove_classes(year='VOC2007',classes=["bus",'bicycle','car','motorbike'])
100%|██████████| 9963/9963 [00:00<00:00, 19330.61it/s]
查看一下移出后结果:
$ tree -L 1 VOCdevkit/VOC2007
VOCdevkit/VOC2007
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
├── SegmentationObject
└── VOC2007_result #这是移出后数据的存放位置
6 directories, 0 files
看一下VOC2007_result中的结果:
$ tree -L 1 VOCdevkit/VOC2007/VOC2007_result/
VOCdevkit/VOC2007/VOC2007_result/
├── 000004.jpg
├── 000004.xml
├── 000007.jpg
├── 000007.xml
├── 000012.jpg
├── 000012.xml
......
├── 009959.xml
├── 009963.jpg
└── 009963.xml
0 directories, 4428 files
接着再看一下VOC2007数据集,移出4个分类以后,应该还有16个分类:
check('VOC2007')
########################################################################################数据集VOC2007检验结果如下:######################################################################################################
所有图片都有对应标注文件
所有标注文件都有对应图片
结果文件VOCdevkit/VOC2007/VOC2007_result已经存在,请检查
100%|██████████| 7362/7362 [00:00<00:00, 11036.42it/s]
数据集VOC2007一共有7362张合格的标注图片,21430个标注框,平均每张图有2.91个标注框;一共有16个分类,分别是['aeroplane', 'bird', 'boat', 'bottle', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'];图片中标注框个数最少是1, 最多是42.图片高度最小值是99,最大值是500;图片宽度最小值是127,最大值是500; 图片面积最小值是43750,最大值是250000 ;图片高宽比最小值是0.2,图片高宽比最大值是3.15
cls_names images objects min_h_bbox max_h_bbox min_w_bbox max_w_bbox min_area_bbox max_area_bbox min_area_box/img max_area_box/img
0 aeroplane 426 618 13 465 14 499 208 213642 3.4 99.8
1 bird 618 1171 9 490 5 498 126 217070 2.6 99.5
2 boat 342 743 5 497 4 499 44 186127 1.6 99.6
3 bottle 485 1264 10 499 4 468 80 152195 2.1 99.7
4 cat 668 751 22 499 25 499 625 241056 5.8 99.7
5 chair 1082 2740 5 499 4 499 78 212768 2.0 99.8
6 cow 264 652 8 490 7 499 56 179280 1.8 97.8
7 diningtable 506 605 10 476 21 499 567 185754 5.7 99.5
8 dog 841 1038 10 499 10 499 100 232035 2.3 99.7
9 horse 550 768 21 499 11 499 297 197691 4.0 99.3
10 person 2970 7185 8 499 6 499 48 248003 1.7 99.8
11 pottedplant 503 1153 6 499 6 498 84 226080 2.1 99.6
12 sheep 192 654 5 482 9 485 45 226980 1.5 96.2
13 sofa 703 791 33 499 24 499 1638 209237 10.0 99.8
14 train 491 594 20 499 20 499 725 185381 6.2 99.6
15 tvmonitor 516 703 11 498 13 499 176 185754 3.4 99.5
3.2 新版代码
import os
import os.path as osp
import shutil
from glob import glob
from tqdm import tqdm
import xml.etree.ElementTree as ET
def remove_classes(srcpath,savepath,classes=None):
"""移除含有我们选定类别的标注图片和标签文件,对原始数据集产生影响,我们要的是剩余部分
Args:
srcpath (str): VOC数据集路径,在JPEGImages和Annotations上一级
savepath (str): 保存移除数据的位置
classes (list, optional): _description_. Defaults to None.
Raises:
Exception: _description_
"""
lbs = glob(osp.join(srcpath,"Annotations",'*.xml'))
if classes is not None:
if osp.exists(savepath):
raise Exception("结果文件夹已经存在,请换一个")
os.makedirs(savepath,exist_ok=False)
savepath_img = osp.join(savepath,"JPEGImages")
savepath_xml = osp.join(savepath,"Annotations")
os.makedirs(savepath_img)
os.makedirs(savepath_xml)
for lb in tqdm(lbs):
tree = ET.parse(lb)
root = tree.getroot()
objs = root.findall("object")
for obj in objs:
if obj.find("name").text in classes:
shutil.move(lb,savepath_xml)
name = osp.splitext(osp.split(lb)[-1])[0]
img = osp.join(srcpath,"JPEGImages",name+'.jpg')
shutil.move(img,savepath_img)
break
print("Done")
else:
print("需要定义合理的classes")
remove_classes(srcpath="voc/VOCdevkit/VOC2007",savepath="test1",classes=['car'])
100%|██████████| 17125/17125 [00:01<00:00, 11421.64it/s]
Done
!ls test1
!ls test1/JPEGImages | wc -l
!ls test1/Annotations | wc -l
Annotations JPEGImages
1284
1284
check_statistic(srcpath="test1",savepath='test2')
Start deal xmls:: 100%|██████████| 1284/1284 [00:00<00:00, 11225.24it/s]
数据集test1共有1284张图片,其中1284张合格的标注图,2张标注有问题,0图片太小。
总共有20个分类,分别是:['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
标注框总数是:4968个,单图最多框数:30,单图最少框数:1, 单图平均框数:3.87;
图片宽度最大值:500,图片宽度最小值:240,图片宽度平均值:481.78;
图片高度最大值:500,图片高度最小值:112,图片高度平均值:372.46;
图片宽高比最大值:4.46,图片宽高比最小值:0.48,图片宽高比平均值:1.33;
clsname img_num obj_num box_min_h box_max_h box_mean_h box_min_w box_max_w box_mean_w min_box_w/h max_box_w/h mean_box_w/h min_area_percent max_area_percent mean_area_percent
0 aeroplane 43 64 15 374 125.48 20 499 295.23 0.632911 5.000000 2.56 0.003200 0.995003 0.28
1 bicycle 97 138 12 402 126.21 8 499 153.75 0.324786 4.581395 1.20 0.000576 0.992677 0.15
2 bird 5 6 20 204 90.50 28 73 49.33 0.357843 1.432432 0.83 0.002987 0.088907 0.03
3 boat 23 40 12 310 108.32 21 499 205.82 0.769759 10.500000 2.56 0.002540 0.809045 0.18
4 bottle 22 35 19 464 99.80 11 156 55.26 0.311258 2.346154 0.79 0.001115 0.366251 0.05
5 bus 181 254 12 499 160.32 10 476 207.30 0.156250 4.146067 1.39 0.001120 0.892536 0.24
6 car 1283 2492 4 499 94.76 6 499 146.27 0.102857 10.227273 1.69 0.000192 0.995811 0.14
7 cat 6 6 42 150 88.17 33 282 121.17 0.471429 1.880000 1.30 0.012138 0.254054 0.08
8 chair 25 54 21 323 101.65 16 267 81.30 0.336634 5.204082 0.94 0.002731 0.329029 0.05
9 cow 10 26 7 311 70.15 10 462 76.69 0.274809 3.571429 1.19 0.000892 0.718410 0.06
10 diningtable 7 14 25 274 110.36 27 499 175.00 0.450000 3.322581 1.68 0.003898 0.601749 0.17
11 dog 38 51 26 427 132.22 20 381 112.90 0.330435 2.076923 0.88 0.002773 0.778848 0.11
12 horse 24 46 22 393 166.02 40 449 183.24 0.310345 2.000000 1.12 0.005045 0.864985 0.21
13 motorbike 113 158 13 466 163.37 16 499 182.25 0.229508 3.212121 1.13 0.001451 0.995003 0.24
14 person 576 1493 8 499 110.02 4 499 56.69 0.071730 2.933333 0.55 0.000299 0.923483 0.06
15 pottedplant 24 54 8 374 64.44 7 374 56.37 0.212121 2.000000 0.92 0.000384 0.632309 0.05
16 sheep 5 11 34 230 94.09 35 178 78.00 0.513514 1.701754 0.90 0.007357 0.244418 0.05
17 sofa 2 2 233 267 250.00 422 429 425.50 1.606742 1.811159 1.71 0.524405 0.648462 0.59
18 train 23 25 47 407 186.76 26 499 324.96 0.553191 4.536364 1.96 0.006517 0.733546 0.35
19 tvmonitor 6 9 34 231 93.67 36 333 104.22 0.315789 1.558824 1.14 0.009611 0.410256 0.08
这部分的图片结果就不上传了。
可以看到包含我们指定类的图片全部移除,当标签文件中同时含有其它分类时也一同处理。
4 提取特定分类
应用场景是有的数据集比较大,但是我们需要的只是其中几个类别,此时要进行提取,不改变原始数据集,但会生成新的数据集。这种情况下,我们的主要目地是对提取的数据比较感兴趣。
4.1 旧版代码
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
def get_needed_classes(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=None):
"""
source_dataset:提取数据集位置
dest_daaset:提取后数据集存放位置
classes:列表,指定要提取的分类,所有出现在该参数中的类都会被提取,如果是None则复制整个数据集
"""
if os.path.exists(dest_dataset):
shutil.rmtree(dest_dataset)
os.mkdir(dest_dataset)
else:
os.mkdir(dest_dataset)
if classes is not None:
img_filepath=os.path.join(source_dataset,'JPEGImages')
ann_filepath=os.path.join(source_dataset,'Annotations')
img_savepath= os.path.join(dest_dataset,'JPEGImages')
ann_savepath=os.path.join(dest_dataset,'Annotations')
main_path = os.path.join(dest_dataset,"ImageSets/Main")
if not os.path.exists(img_savepath):
os.makedirs(img_savepath)
if not os.path.exists(ann_savepath):
os.makedirs(ann_savepath)
if not os.path.exists(main_path):
os.makedirs(main_path)
source_anns=os.listdir(ann_filepath)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(ann_filepath,source_ann))
root = tree.getroot()
result = root.findall("object")
bool_num=0
for obj in result:
if obj.find("name").text not in classes:
root.remove(obj)
else:
bool_num = 1
if bool_num:
tree.write(os.path.join(ann_savepath,source_ann))
name_img =os.path.splitext(source_ann)[0]+'.jpg'
shutil.copy(os.path.join(img_filepath,name_img),os.path.join(img_savepath,name_img))
else:
shutil.copytree(source_dataset,dest_dataset)
获取四个类别的车辆类数据
get_needed_classes(classes=['bicycle','car','motorbike','bus'])
100%|██████████| 9963/9963 [00:02<00:00, 4188.22it/s]
接着查看提取后数据集VOC2007_dest:
tl@aiot:~/VOC/VOCdevkit$ tree -L 1 VOC2007_dest/
VOC2007_dest/
├── Annotations
├── ImageSets
└── JPEGImages
3 directories, 0 files
check("VOC2007_dest")
########################################################################################数据集VOC2007_dest检验结果如下:######################################################################################################
所有图片都有对应标注文件
所有标注文件都有对应图片
100%|██████████| 2601/2601 [00:00<00:00, 13031.95it/s]
数据集VOC2007_dest一共有2601张合格的标注图片,5277个标注框,平均每张图有2.03个标注框;一共有4个分类,分别是['bicycle', 'bus', 'car', 'motorbike'];图片中标注框个数最少是1, 最多是15.图片高度最小值是96,最大值是500;图片宽度最小值是156,最大值是500; 图片面积最小值是43090,最大值是250000 ;图片高宽比最小值是0.19,图片高宽比最大值是3.21
cls_names images objects min_h_bbox max_h_bbox min_w_bbox max_w_bbox min_area_bbox max_area_bbox min_area_box/img max_area_box/img
0 bicycle 505 807 9 499 10 499 110 186626 2.4 99.8
1 bus 380 526 9 475 12 499 198 188325 3.2 99.7
2 car 1536 3185 4 497 6 499 48 196560 1.6 99.7
3 motorbike 482 759 18 498 7 499 182 198000 3.1 99.4
4.2 新版代码
import os
import os.path as osp
import shutil
from glob import glob
from tqdm import tqdm
import xml.etree.ElementTree as ET
def get_classes(srcpath,savepath,classes=None):
"""获取含有我们选定类别的标注图片和标签文件,原数据集不产生任何影响
Args:
srcpath (str): VOC数据集路径,在JPEGImages和Annotations上一级
savepath (str): 保存获取数据的位置
classes (list, optional): _description_. Defaults to None.用来指定我们要提取的分类
Raises:
Exception: _description_
"""
lbs = glob(osp.join(srcpath,"Annotations",'*.xml'))
if classes is not None:
if osp.exists(savepath):
shutil.rmtree(savepath) #因为不影响原始文件,所以可以直接删除
os.makedirs(savepath,exist_ok=False)
savepath_img = osp.join(savepath,"JPEGImages")
savepath_xml = osp.join(savepath,"Annotations")
os.makedirs(savepath_img)
os.makedirs(savepath_xml)
for lb in tqdm(lbs):
tree = ET.parse(lb)
root = tree.getroot()
objs = root.findall("object")
num=0
for obj in objs:
if obj.find("name").text not in classes:
root.remove(obj) #删除标注文件中所有不需要的标注框
else:
num+=1
if num>0: #删除完不需的框后任有剩余的框
name = osp.splitext(osp.split(lb)[-1])[0]
tree.write(osp.join(savepath_xml,name+'.xml'))
img = osp.join(srcpath,"JPEGImages",name+'.jpg')
shutil.copy(img,savepath_img)
print("Done")
else:
print("需要定义合理的classes")
get_classes(srcpath="voc/VOCdevkit/VOC2007",savepath='test3',classes=['bicycle','car','motorbike','bus'])
100%|██████████| 9963/9963 [00:01<00:00, 6878.84it/s]
Done
check_statistic(srcpath="test3",savepath='test4')
Start deal xmls:: 100%|██████████| 2601/2601 [00:00<00:00, 13447.21it/s]
数据集test3共有2601张图片,其中2601张合格的标注图,0张标注有问题,0图片太小。
总共有4个分类,分别是:['bicycle', 'bus', 'car', 'motorbike']
标注框总数是:5277个,单图最多框数:15,单图最少框数:1, 单图平均框数:2.03;
图片宽度最大值:500,图片宽度最小值:156,图片宽度平均值:478.77;
图片高度最大值:500,图片高度最小值:96,图片高度平均值:376.71;
图片宽高比最大值:5.21,图片宽高比最小值:0.312,图片宽高比平均值:1.32;
clsname img_num obj_num box_min_h box_max_h box_mean_h box_min_w box_max_w box_mean_w min_box_w/h max_box_w/h mean_box_w/h min_area_percent max_area_percent mean_area_percent
0 bicycle 505 807 9 499 150.90 10 499 164.31 0.196721 4.733333 1.13 0.000587 0.995339 0.19
1 bus 380 526 9 475 158.10 12 499 218.42 0.134771 5.867647 1.52 0.001056 0.995003 0.25
2 car 1536 3185 4 497 100.40 6 499 161.45 0.097744 8.481481 1.72 0.000256 0.995003 0.16
3 motorbike 482 759 18 498 172.26 7 499 199.57 0.269231 6.326531 1.17 0.000971 0.988699 0.25
这部分图片结果也不上传。
结果可以与VOC2007的统计结果做对比,是完全一样的。
5 提取特定分类并修改名称
应用场景是从多个原始数据集中提取特定分类,但同一个类别在不同数据集中使用不同的名称,这时需要统一名称,不改变原始数据集。比如VOC中叫motorbike,COCO数据集叫motorcycle
5.1 旧版代码
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
def get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=None,new_classes=None):
"""
source_dataset:提取数据集位置
dest_daaset:提取后数据集存放位置
classes:指定要提取的分类,所有出现在该参数中的类都会被提取,如果是None则复制整个数据集
new_classes: 在classes 提取的分类中选取部分或全部进行修改,如果是None则不需要进行修改这个是默认的
"""
if os.path.exists(dest_dataset):
shutil.rmtree(dest_dataset)
os.mkdir(dest_dataset)
else:
os.mkdir(dest_dataset)
if classes is not None:
img_filepath=os.path.join(source_dataset,'JPEGImages')
ann_filepath=os.path.join(source_dataset,'Annotations')
img_savepath= os.path.join(dest_dataset,'JPEGImages')
ann_savepath=os.path.join(dest_dataset,'Annotations')
main_path = os.path.join(dest_dataset,"ImageSets/Main")
if not os.path.exists(img_savepath):
os.makedirs(img_savepath)
if not os.path.exists(ann_savepath):
os.makedirs(ann_savepath)
if not os.path.exists(main_path):
os.makedirs(main_path)
change=False
if new_classes:
change=True
for name in new_classes.keys():
if not name in classes:
print("要改的名称必须要在所提取的类别中")
return
source_anns=os.listdir(ann_filepath)
for source_ann in tqdm(source_anns):
tree = ET.parse(os.path.join(ann_filepath,source_ann))
root = tree.getroot()
result = root.findall("object")
bool_num=0
for obj in result:
if obj.find("name").text not in classes:
root.remove(obj)
else:
if change and obj.find("name").text in new_classes.keys():
obj.find("name").text = new_classes[obj.find("name").text]
bool_num = 1
if bool_num:
tree.write(os.path.join(ann_savepath,source_ann),encoding='utf-8') #写进原始的xml文件中,防止中文乱码
name_img =os.path.splitext(source_ann)[0]+'.jpg'
shutil.copy(os.path.join(img_filepath,name_img),os.path.join(img_savepath,name_img))
else:
shutil.copytree(source_dataset,dest_dataset)
如我们提取VOC2007中机动车数据,但是要修改motorbike为motorcycle,car改为汽车的拼音
get_needed_classes_change_name(source_dataset="VOCdevkit/VOC2007",dest_dataset="VOCdevkit/VOC2007_dest",classes=['bicycle','car','motorbike','bus'],new_classes={"car":"qiche","motorbike":"motorcycle"})
100%|██████████| 9963/9963 [00:00<00:00, 10228.99it/s]
查看一下提取后的数据集
check("VOC2007_dest")
########################################################################################数据集VOC2007_dest检验结果如下:######################################################################################################
所有图片都有对应标注文件
所有标注文件都有对应图片
100%|██████████| 2601/2601 [00:00<00:00, 12146.91it/s]
数据集VOC2007_dest一共有2601张合格的标注图片,5277个标注框,平均每张图有2.03个标注框;一共有4个分类,分别是['bicycle', 'bus', 'motorcycle', 'qiche'];图片中标注框个数最少是1, 最多是15.图片高度最小值是96,最大值是500;图片宽度最小值是156,最大值是500; 图片面积最小值是43090,最大值是250000 ;图片高宽比最小值是0.19,图片高宽比最大值是3.21
cls_names images objects min_h_bbox max_h_bbox min_w_bbox max_w_bbox min_area_bbox max_area_bbox min_area_box/img max_area_box/img
0 bicycle 505 807 9 499 10 499 110 186626 2.4 99.8
1 bus 380 526 9 475 12 499 198 188325 3.2 99.7
2 motorcycle 482 759 18 498 7 499 182 198000 3.1 99.4
3 qiche 1536 3185 4 497 6 499 48 196560 1.6 99.7
5.2 新版代码
import os
import os.path as osp
import shutil
from glob import glob
from tqdm import tqdm
import xml.etree.ElementTree as ET
def get_classes_change_name(srcpath,savepath,classes=None,newname=None):
"""获取含有我们选定类别的标注图片和标签文件,原数据集不产生任何影响,提取这些类别后,可以同时做部分类别的修改名称
Args:
srcpath (str): VOC数据集路径,在JPEGImages和Annotations上一级
savepath (str): 保存获取数据的位置
classes (list): _description_. Defaults to None.,用来指定我们要提取的分类
newname (dict): _description_. Defaults to None.,用来指定要修改的类,key来自classes的子集,value是新的名称,如果是None则相当与直接提取需要的分类
Raises:
Exception: _description_
"""
lbs = glob(osp.join(srcpath,"Annotations",'*.xml'))
if classes is not None:
if osp.exists(savepath):
shutil.rmtree(savepath) #因为不影响原始文件,所以可以直接删除
os.makedirs(savepath,exist_ok=False)
savepath_img = osp.join(savepath,"JPEGImages")
savepath_xml = osp.join(savepath,"Annotations")
os.makedirs(savepath_img)
os.makedirs(savepath_xml)
change=False #默认是不做改名称的
if newname is not None:
change=True
for name in newname.keys():
if not name in classes:
assert Exception(f"要修改的类别{name}必须在提取的类别中,")
for lb in tqdm(lbs):
tree = ET.parse(lb)
root = tree.getroot()
objs = root.findall("object")
num=0
for obj in objs:
if obj.find("name").text not in classes:
root.remove(obj) #删除标注文件中所有不需要的标注框
else:
oldname=obj.find("name").text
if change and oldname in newname.keys():
obj.find("name").text = newname[oldname] #完成名称的修改,即使不
num+=1
if num>0: #删除完不需的框后任有剩余的框
name = osp.splitext(osp.split(lb)[-1])[0]
tree.write(osp.join(savepath_xml,name+'.xml'))
img = osp.join(srcpath,"JPEGImages",name+'.jpg')
shutil.copy(img,savepath_img)
print("Done")
else:
print("需要定义合理的classes")
get_classes_change_name(srcpath="voc/VOCdevkit/VOC2007",savepath='test5',classes=['bicycle','car','motorbike','bus'],newname={"motorbike":"motorcycle","car":"qiche"})
100%|██████████| 9963/9963 [00:01<00:00, 6900.83it/s]
Done
check_statistic(srcpath="test5",savepath='test6')
Start deal xmls:: 100%|██████████| 2601/2601 [00:00<00:00, 14928.90it/s]
数据集test5共有2601张图片,其中2601张合格的标注图,0张标注有问题,0图片太小。
总共有4个分类,分别是:['bicycle', 'bus', 'motorcycle', 'qiche']
标注框总数是:5277个,单图最多框数:15,单图最少框数:1, 单图平均框数:2.03;
图片宽度最大值:500,图片宽度最小值:156,图片宽度平均值:478.77;
图片高度最大值:500,图片高度最小值:96,图片高度平均值:376.71;
图片宽高比最大值:5.21,图片宽高比最小值:0.312,图片宽高比平均值:1.32;
clsname img_num obj_num box_min_h box_max_h box_mean_h box_min_w box_max_w box_mean_w min_box_w/h max_box_w/h mean_box_w/h min_area_percent max_area_percent mean_area_percent
0 bicycle 505 807 9 499 150.90 10 499 164.31 0.196721 4.733333 1.13 0.000587 0.995339 0.19
1 bus 380 526 9 475 158.10 12 499 218.42 0.134771 5.867647 1.52 0.001056 0.995003 0.25
2 motorcycle 482 759 18 498 172.26 7 499 199.57 0.269231 6.326531 1.17 0.000971 0.988699 0.25
3 qiche 1536 3185 4 497 100.40 6 499 161.45 0.097744 8.481481 1.72 0.000256 0.995003 0.16
从结果上看,这与上一步处理的结果是完全相同的,只是修改了名称。
6 VOC数据集可视化
将数据集画图后进行保存,可以进行查看,可视化主要是要将标注框画到图中,从而看训练数据的标注情况。
以下将提供两种画图方法,一种是对数据集整体画数据结果,另一种是对单张图片进行查看,结果自动保存在数据集所在文件夹下draw_result中
import os
import xml.etree.ElementTree as ET
import shutil
from tqdm import tqdm
import cv2
def draw(source_dataset="VOCdevkit/VOC2007_dest"):
#生成保存画图后结果的文件
draw_path = os.path.join(source_dataset,"draw_results")
if not os.path.exists(draw_path):
os.makedirs(draw_path)
else:
shutil.rmtree(draw_path)
os.makedirs(draw_path)
ann_filepath=os.path.join(source_dataset,'Annotations')
source_anns=os.listdir(ann_filepath)
for source_ann in tqdm(source_anns):
source_img = os.path.join(source_dataset,'JPEGImages',os.path.splitext(source_ann)[0]+'.jpg')
if not os.path.exists(source_img):
source_img = os.path.join(source_dataset,'JPEGImages',os.path.splitext(source_ann)[0]+'.JPG')
save_img = os.path.join(draw_path,os.path.splitext(source_ann)[0]+'.jpg')
img = cv2.imdecode(np.fromfile(source_img,dtype=np.uint8),-1)
if img is None or not img.any():
continue
tree = ET.parse(os.path.join(ann_filepath,source_ann))
root = tree.getroot()
result = root.findall("object")
for obj in result:
name = obj.find("name").text
x1=int(obj.find('bndbox').find('xmin').text)
y1=int(obj.find('bndbox').find('ymin').text)
x2=int(obj.find('bndbox').find('xmax').text)
y2=int(obj.find('bndbox').find('ymax').text)
cv2.rectangle(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.putText(img,name,(max(x1,15),max(y1,15)),cv2.FONT_ITALIC,1,(0,255,0,2))
cv2.imencode('.jpg',img)[1].tofile(save_img)
def draw_single_image(ann_path,img_path,save_path=None):
"""
ann_path:指定xml的绝对路径
img_path:指定xml的绝对路径
save_path:如果不是None,那么将是结果图的保存路径;反之则画出来
"""
img = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)
if img is None or not img.any():
raise '有空图'
tree = ET.parse(ann_path)
root = tree.getroot()
result = root.findall("object")
for obj in result:
name = obj.find("name").text
x1=int(obj.find('bndbox').find('xmin').text)
y1=int(obj.find('bndbox').find('ymin').text)
x2=int(obj.find('bndbox').find('xmax').text)
y2=int(obj.find('bndbox').find('ymax').text)
cv2.rectangle(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.putText(img,name,(max(x1,15),max(y1,15)),cv2.FONT_ITALIC,1,(0,255,0,2))
if save_path is None:
imgrgb = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.figure(figsize=(20,10))
plt.imshow(imgrgb)
else:
cv2.imencode('.jpg',img)[1].tofile(save_path)
draw(source_dataset="VOCdevkit/VOC2007_dest")
100%|██████████| 2601/2601 [00:12<00:00, 215.68it/s]
对于画好的多张图片,可以在本机直接查看,对于在jupyter中可以对于批量图(最少一张)来进行查看):
from IPython.display import clear_output, display, HTML
from PIL import Image
import matplotlib.pyplot as plt
import time
import cv2
import base64
import glob
current_time = 0
# 图像处理函数
def processImg(img):
# 画出一个框
# cv2.rectangle(img, (500, 300), (800, 400), (0, 0, 255), 5, 1, 0)
# 上下翻转
# img= cv2.flip(img, 0)
# 显示FPS
global current_time
if current_time == 0:
current_time = time.time()
else:
last_time = current_time
current_time = time.time()
fps = 1. / (current_time - last_time)
text = "FPS: %d" % int(fps)
cv2.putText(img, text , (0,100), cv2.FONT_HERSHEY_TRIPLEX, 3.65, (255, 0, 0), 2)
# img = cv2.resize(img,(1080,1080))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
def arrayShow(imageArray):
# ret, png = cv2.imencode('.png', imageArray)
# encoded = base64.b64encode(png)
# return Image(data=encoded.decode('ascii'))
return Image.fromarray(imageArray)
img_paths = glob.glob('VOCdevkit/VOC2007_dest/draw_results/*.jpg')
small=1
while(True):
try:
clear_output(wait=True)
ret, frame = video.read()
lines, columns, _ = frame.shape
frame = processImg(frame)
frame = cv2.resize(frame, (int(columns / small), int(lines / small)))
img = arrayShow(frame)
display(img)
# 控制帧率
time.sleep(0.02)
except KeyboardInterrupt:
video.release()
import os
import time
from tqdm import tqdm
from PIL import Image
import cv2
from IPython.display import clear_output, display, HTML
def show_images(images:list,small:int=1) -> str:
"""
images用来存放图片的绝对路径
small用来缩小图像大小,便于显示
"""
current_time = 0
for img_path in tqdm(images):
clear_output(wait=True)
img = cv2.imdecode(np.fromfile(img_path,dtype=np.uint8),-1)
if img is None or not img.any():
continue
h,w,_ = img.shape
##这里可以对图像进行处理操作
######################
if current_time==0:
current_time=time.time()
else:
last_time=current_time
current_time=time.time()
fps = 1. / (current_time - last_time)
text = "FPS: %d" % int(fps)
cv2.putText(img, text , (0,50), cv2.FONT_HERSHEY_TRIPLEX, 1, (255, 0, 0), 1)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (int(w / small), int(h / small)))
img = Image.fromarray(img)
display(img)
# 控制帧率
time.sleep(5)
import glob
img_paths = glob.glob('VOCdevkit/VOC2007_dest/draw_results/*.jpg')
show_images(img_paths)
对于单张图可以直接可视化,也可以保存到文件中
draw_single_image('VOCdevkit/VOC2007_dest/Annotations/000020.xml','VOCdevkit/VOC2007_dest/JPEGImages/000012.jpg')
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xUMzyHDf-1626945666927)(output_31_0.png)]](https://img-blog.csdnimg.cn/img_convert/cdaadc9c71092d48a78ab84ffbbbd272.png)
如果是保存成图片,想要显示在jupyter notebook中还可以这样
%%html
<img src="VOCdevkit/VOC2007_dest/JPEGImages/000012.jpg",width=400,height=200>
<img src=“VOCdevkit/VOC2007_dest/JPEGImages/000012.jpg”,width=400,height=200>

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)