
【CO003】操作系统笔记8 —— FAT32
笔者:YY同学生命不息,代码不止。好玩的项目尽在GitHub文章目录FAT32 Trial 1.0FAT32 Trial 2.0FAT32 Trial 2.1FAT32 Trial 2.2FAT32 Trial 3.0路径遍历实例FS 特定信息FAT 家族FAT32 和 Ext3 是两种不同的 FS。FAT32 属于 Windows,简单且便于学习;Ext3 属于 Linux。FAT32 Tria
笔者:YY同学
文章目录
FAT(File Allocation Table)是属于 Windows 的文件系统,简单且便于学习。FAT 家族包含 FAT12、FAT16、FAT32、NTFS等,接下来我们会以 FAT32 为例进行介绍。
FAT32 Trial 1.0
大型块状书本式架构,Filename 相当于书的章节,起始地址相当于书的起始页,结束地址相当于 NIL。目前第一版已经很少投入使用了,但会出现在一些 read-only 的情况下,例如 ISO9660 和 Juliet FS。
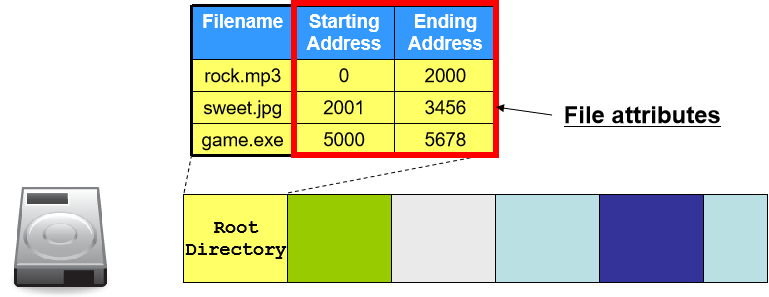
- 优点:块状内存,空间申请和销毁速度很快。
- 缺点:
- 因为是块状结构,存在空间销毁后原本的空间无法容纳更大的文件,造成外部片段溢出,需要额外花费代价来腾挪。
- 文件大小可能会变化,而块状内存大小固定,很难随着文件的大小扩大或缩小内存空间。
- 因为是块状结构,存在空间销毁后原本的空间无法容纳更大的文件,造成外部片段溢出,需要额外花费代价来腾挪。
FAT32 Trial 2.0
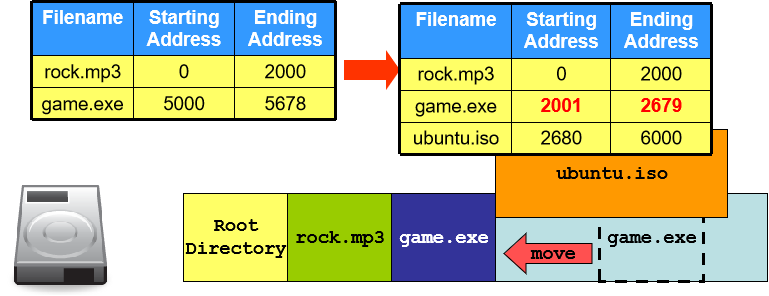
在第一版的基础上有所改进。首先将块状结构分割成很多更小的等大单位块(block,微软里叫 cluster),然后借用 VM 的知识,允许同一文件的块在物理地址上不连续。并且增设了根目录数组来记录各个文件包含的所有块位置信息。
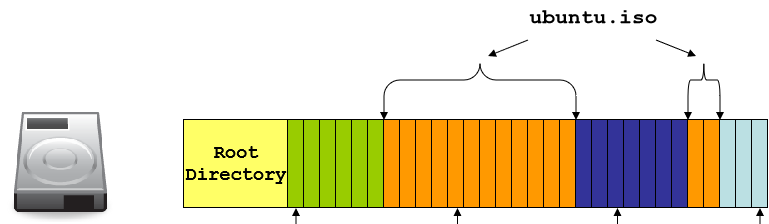
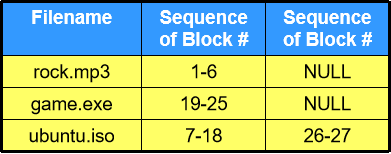
- 优点:非连续性内存设计解决了外部片段溢出的问题,同时也提供了内存扩大缩小的灵活性。
- 缺点:根目录是一个数组结构(array),因此无法链接到具体的块位置。
FAT32 Trial 2.1
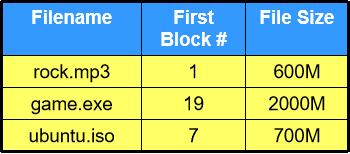
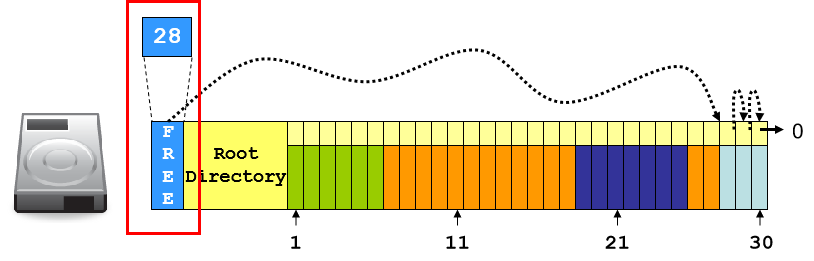
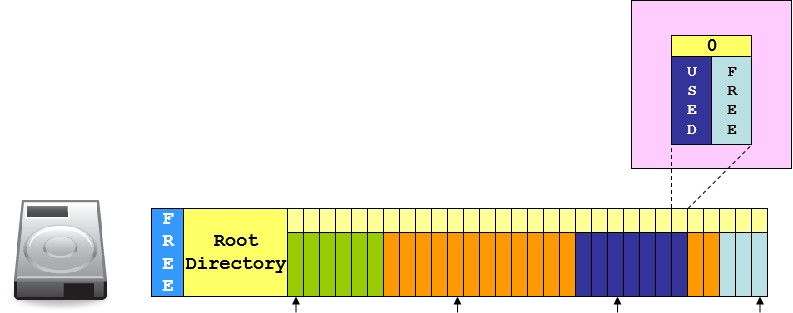
使用链表结构,借用每个块头部的一点空间,放入一个指向下一个块地址的指针,从而实现块的自动寻址。根目录数组用于记录文件块的起始位置信息和文件大小,同时在根目录前面增设未使用空间管理表,用于记录第一块未被使用的空间地址。
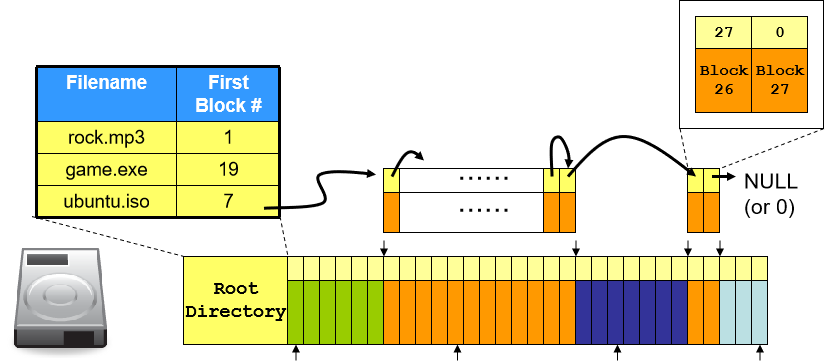
- 优点:
- 完美解决外部片段溢出问题。
- 实现文件大小的自由扩展和缩小。
- 未使用空间管理在技术上很容易实现。
- 缺点:
- 如果要访问某个文件内部某位置的信息,由于根目录只记录文件起始块的位置,因此访问目标文件存在随机访问问题(Random Access),最差情况下 I/O 复杂度 O(n)。
- 存在内部片段溢出问题。单位块是有大小的,很有可能内部无法完全占满,存在空间浪费(这个问题无法解决)。
FAT32 Trial 2.2
在 2.1 的基础上将节点链表中心化,放在 File Allocation Table(FAT)里。每次查找时,只需要通过 FAT 的顺序寻址就能直接找到需要文件内容对应的块节点,然后根据节点位置直接获取对应的文件内容,这样搜索指针的速度要比搜索文件内容的速度快。一般 FAT 会被安装进 kernel 里,为了更好地解决随机访问问题。
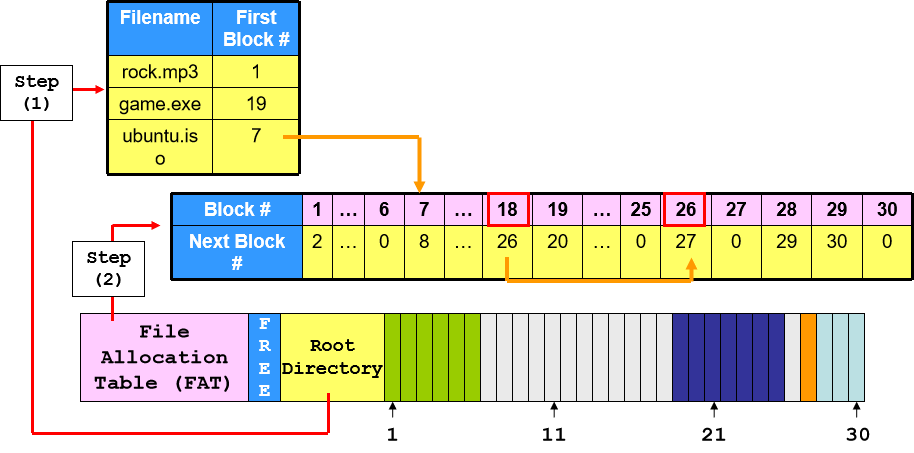
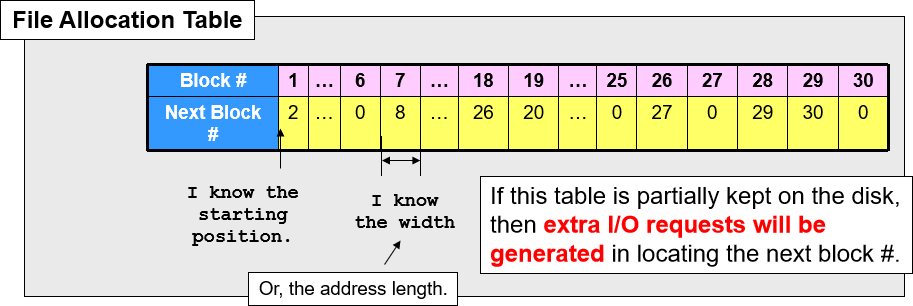
FAT32 Trial 3.0
采用 Index Node Structure,采用树状结构和指针存储数据,Linux 的 Ext 系列也普遍采用这种结构。
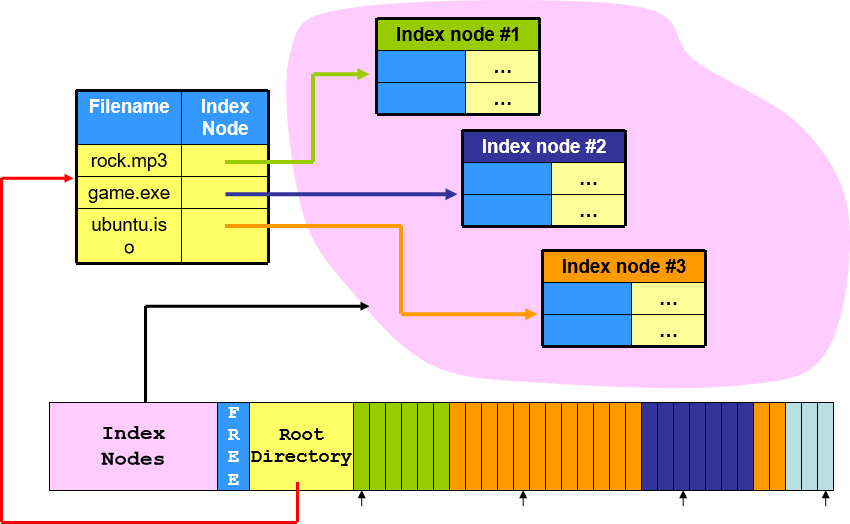
i-Node 内部结构:
- 数据块(Data Block):用于存储数据。
- 直接块(Direct Block):指向数据块的指针,可以直接访问。
- 非直接块(Indirect Block):指向非直接块或者存储数据块的地址块。非直接块有一级、二级、三级等,区别就是层级数不同。
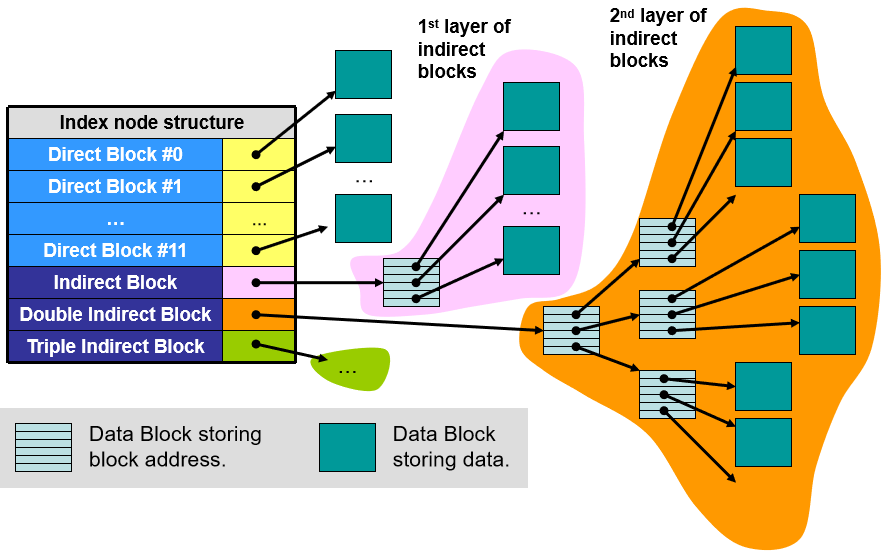
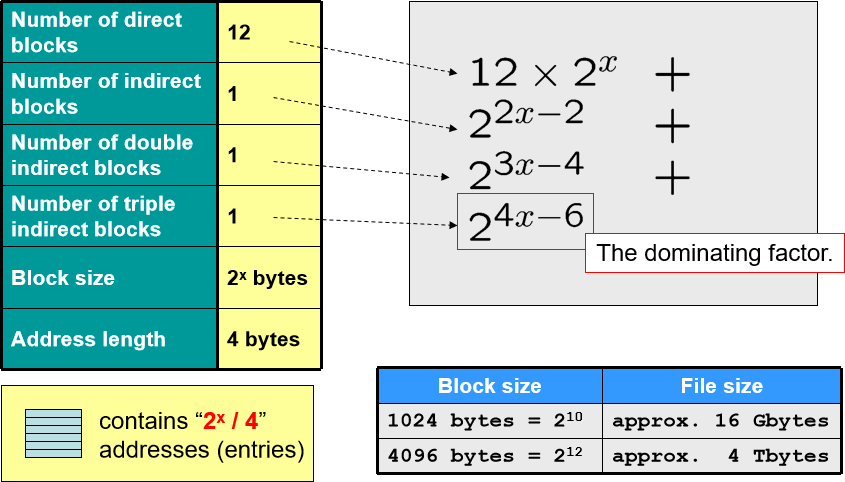
文件大小和非直接块数量:
- 每个块的大小固定,为 2 x 2^{x} 2x bytes。
- 数据块是直接存放数据,因此 12 个直接块指向 12 个数据块,总 size = 12 ∗ 2 x 12*2^x 12∗2x bytes。
- 如果是一级非直接块,内部存放的是地址的合集。一个地址 size 是 4 bytes,因此一个非直接块里就会有 2 x 4 \frac{2^x}{4} 42x 个地址,每个都指向一个数据块,因此数据块的总 size = 2 x 4 ∗ 2 x = 2 2 x − 2 \frac{2^x}{4}*2^{x}=2^{2x-2} 42x∗2x=22x−2 bytes。
- 在计算总文件大小的时候,要先数清楚有几个直接块,几个一级非直接块,几个二级非直接块,几个三级非直接块…把所有块指向的数据块总数相加即是文件大小。一般地,文件大小往往会取决于级数最高的那个非直接块的数量级,因为它的次方数是最高的。
- 计算非直接块数量的时候,要注意对于每种类的非直接块,都要把其包含的所有层级都考虑进去。例如,一个二级非直接块应该包含一个二级非直接块和
2
x
−
2
2^{x-2}
2x−2 个一级非直接块。

FAT32 路径遍历
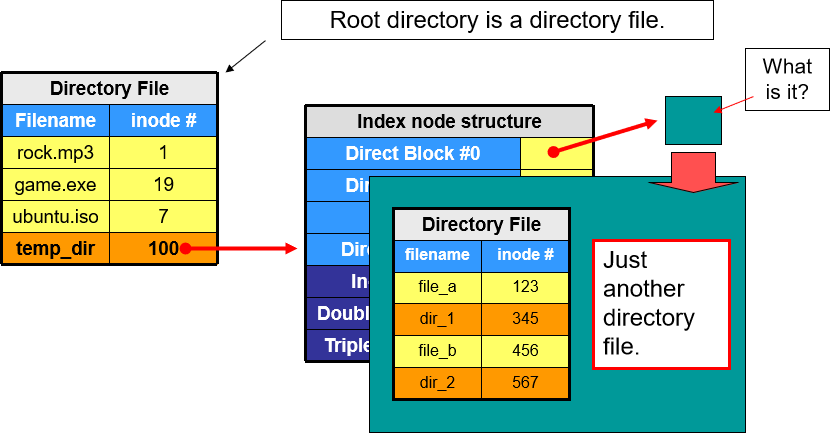
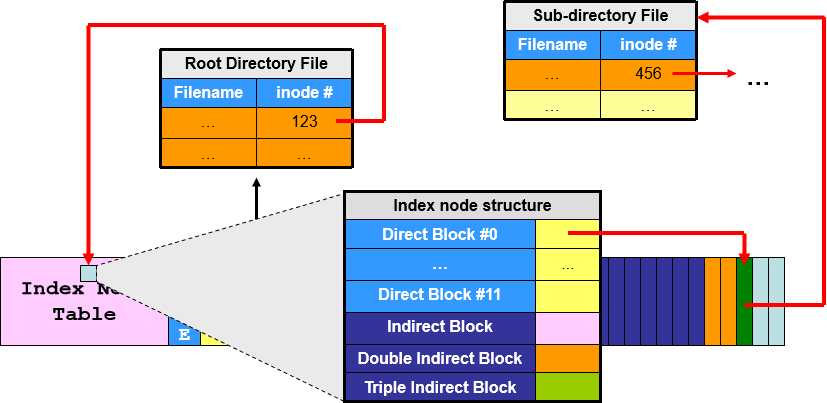
Root Directory 下的路径入口及属性值
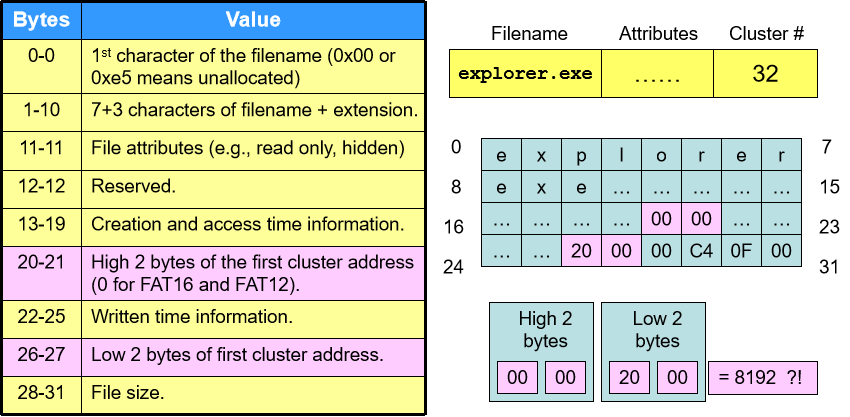
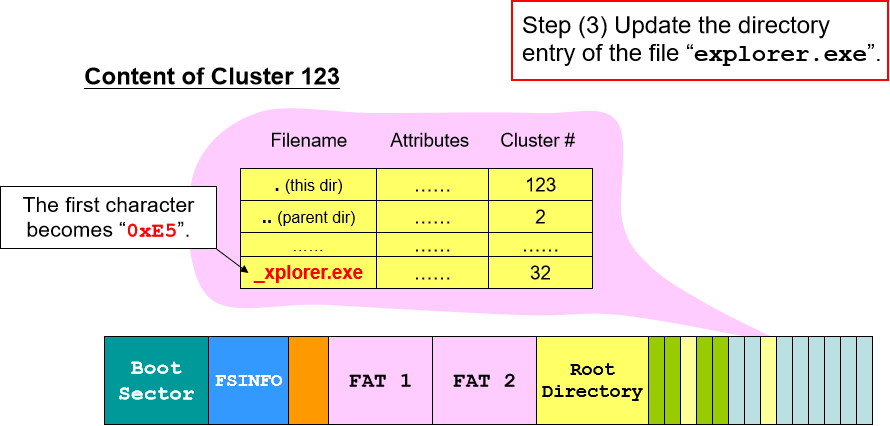
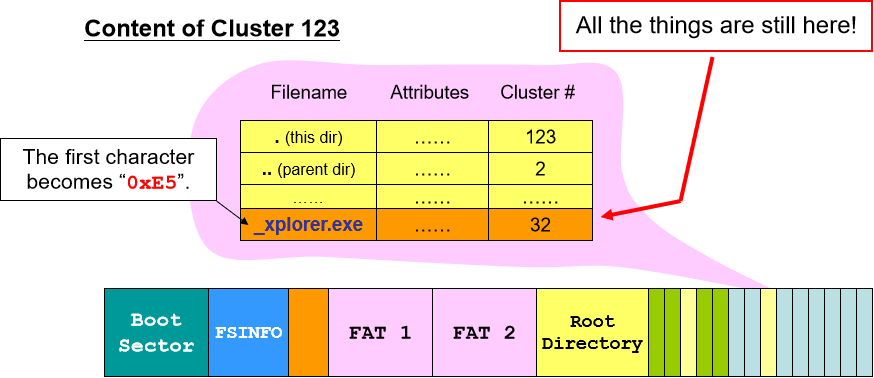
- 路径入口有 32 bytes,其中第 0 位表示文件名的首字符。如果该文件不存在则首字符为空(0x00),如果文件被删除则首字符为 “_”(0xe5,表示下划短线) 。
- 第 20、21 位表示首块地址的 MSB 两位,第 26、27 位则表示首块地址的 LSB 两位。但计算机内部存储的地址顺序会涉及到读取字节顺序问题,一般会有大端(Big-endian)和小端(Little-endian)两种。我们一般默认计算机从左到右是从低地址(0x000)到高地址(0xFFF)。大端是指在低地址存放 MSB,小端是指在低地址存放 LSB。正常情况下,大端存放更符合人们的思维。当然两种方式都是存在的,这取决于不同的 CPU 架构。Motorola 的 PowerPC 系列采用大端设计,而 Intel 的 x86 系列则采用小端设计。
- 28~31 位表示文件大小,4 bytes 可以表示 32 bits 的文件大小,保留 1 byte,因此文件最大是 2 32 − 1 2^{32}-1 232−1 bytes = 4 G − 1 4G-1 4G−1 bytes。
FAT32 特定文件系统信息
特定文件系统信息是一组 MBR code,在 FAT 和 NTFS 中存储在 Boot Sector,在 Ext2 和 Ext3 中存储在超级块(Superblock)。在电脑开机时,计算机会读取 FS 特定信息来启动(boot)不同的 OS 和分区。
典型的 FAT32 整体设计结构

FAT32 文件的读写、删除及复原
- 文件读取:在 FAT 中找到起始 cluster 位置,读取下一个 cluster 的地址直至出现 EOF,表示这是该文件的最后一块数据。
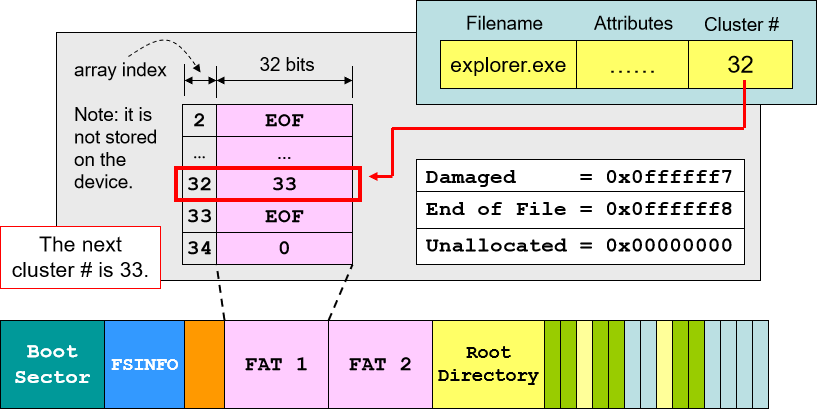
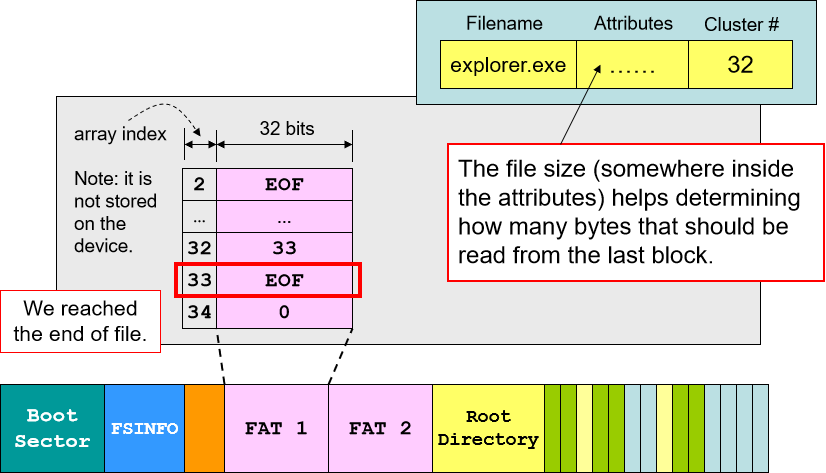
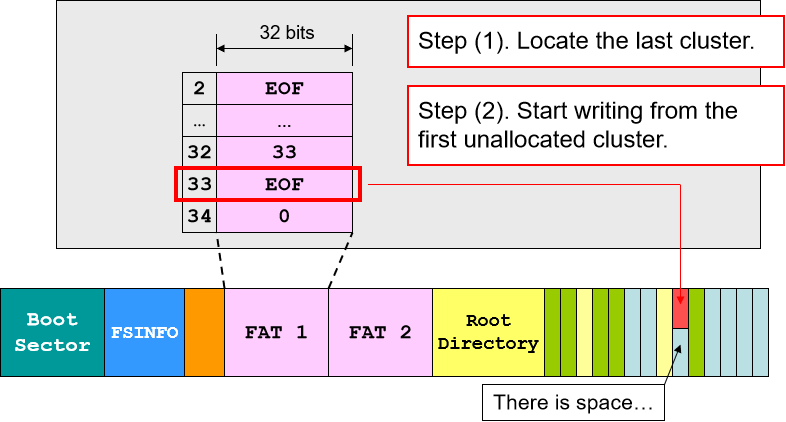
- 文件写入:先找到最后一块 cluster,在空白部分继续写。写满之后找到下一块空余的 cluster 分配空间并继续写入,最后用链表将新分配的 cluster 的节点加入 FAT,将 EOF 移至该 cluster 的下一个节点(类似链表的建立)。
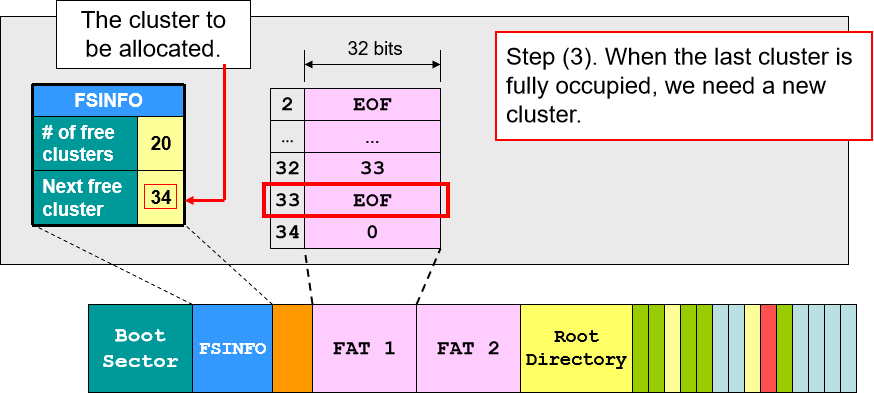
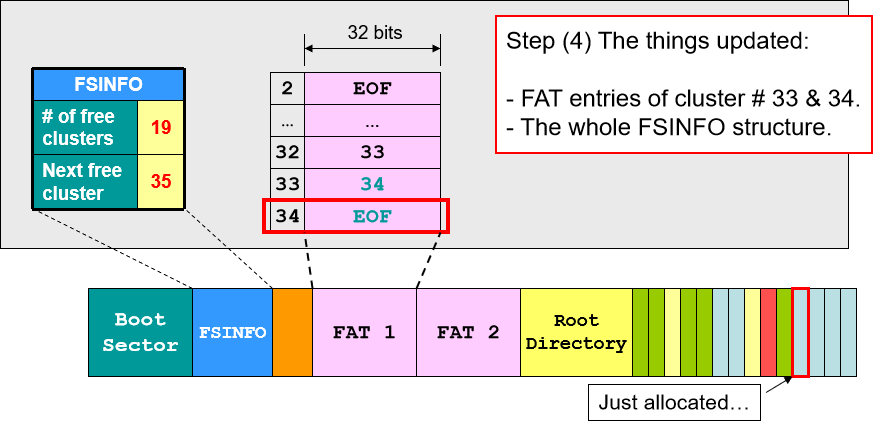
- 文件删除:在 FAT 中找到该文件的所有块然后释放空间(注意只是释放指针空间,让指针不指向数据,数据块并未删除),更新文件信息(空余块的数量和下一个空余块的位置),最后在路径入口将文件名首字符改为 “_”,下一次 FAT 就无法根据路径名查找到该文件。
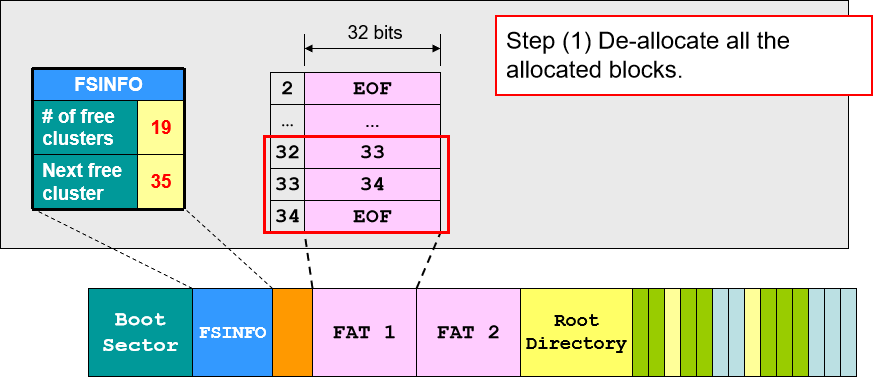
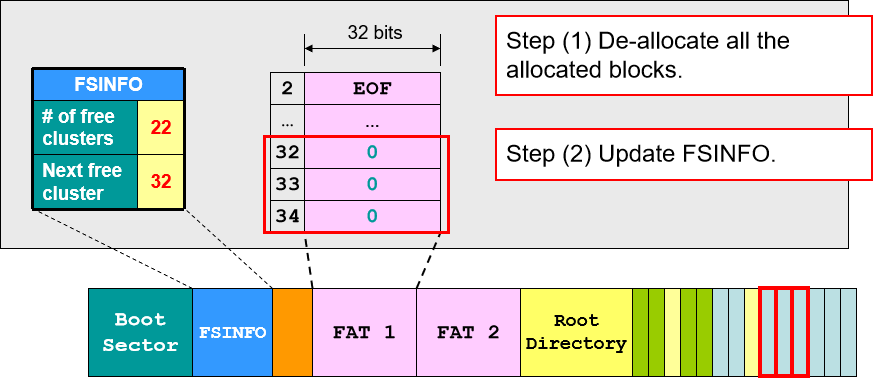
- 文件复原:如果发现误删文件需要第一时间给电脑关机断电,有可能可以终止文件删除的进程然后使电脑自动回档。如果已经删除了也是有机会抢救回来的,因为我们知道删除文件只是更改 FAT 里的指针,而首块地址和所有的数据都是没有被改过的。因此如果文件大小只为 1 个 cluster,大概率可以通过首块地址找回数据;如果文件大小大于 1 cluster,我们也可以通过校验和以及原文件的大小暴力找回。
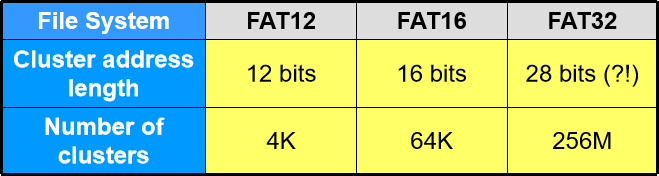
FAT 家族成员
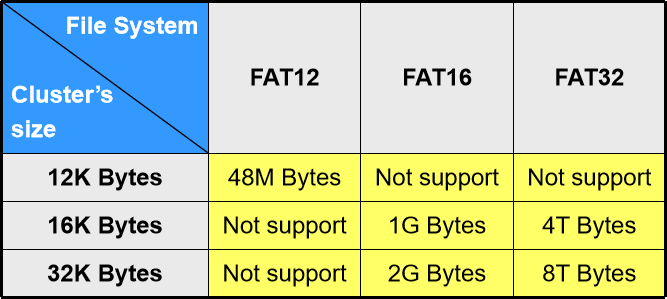
记住两条公式:
- c l u s t e r 总 数 = 2 c l u s t e r 地 址 位 数 cluster 总数 = 2^{cluster 地址位数} cluster总数=2cluster地址位数
- D i s k 大 小 = F S 大 小 = c l u s t e r 总 数 ∗ 单 位 c l u s t e r 大 小 Disk 大小 = FS 大小 = cluster 总数 * 单位 cluster 大小 Disk大小=FS大小=cluster总数∗单位cluster大小

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)