胶囊网络CapsNet--dynamic routing between capsules
1 简介本文根据2017年Hinton的《dynamic routing between capsules》翻译总结。近30年,语音识别主要使用高斯混合隐马尔可夫模型(HMM)作为输出分布。这些模型容易在小的计算机上训练学习,但他们有模型表达限制:one-of- n 表达存在指数性无效率。为了使HMM记忆的信息翻倍,我们需要使隐藏节点的数量取平方(2次方)。而对于循环神经网络,只需要相应翻倍增加隐
1 简介
本文根据2017年Hinton的《dynamic routing between capsules》翻译总结。
近30年,语音识别主要使用高斯混合隐马尔可夫模型(HMM)作为输出分布。这些模型容易在小的计算机上训练学习,但他们有模型表达限制:one-of- n 表达存在指数性无效率。为了使HMM记忆的信息翻倍,我们需要使隐藏节点的数量取平方(2次方)。而对于循环神经网络,只需要相应翻倍增加隐藏神经元的数量,不是指数性增加。
现在卷积网络在物体识别领域占据了主导地位,其是否也存在指数性无效率。卷积网络不能很好的处理仿射变换,比如我们可能需要指数级的增加训练样本。
而本文说的胶囊网络(capsule)可以避免指数性无效率,其将像素强度转换成识别片段的实例参数的向量,然后应用转换矩阵来预测更大片段的实例化参数。转换矩阵是学习部分和整体间的内在关系。
胶囊网络(capsule)可以同时处理不同物体的不同仿射变换,也擅长处理分割。
在一个活跃胶囊中的神经元活跃部分代表一张图片中一个特别实体的各种不同属性,这些属性可能包含许多不同种类的实例参数,如位置、大小、方向、变形、速度、反射率、色彩、质地等等。本文,我们采用实例参数的向量总长度表示实体的存在概率,而向量的方向表示实体的属性。我们采用非线性变换将胶囊的向量输出的长度不超过1,同时保证向量的方向没有改变,但缩小其量级。
上面这段话是我感觉到胶囊网络有点像人类神经网络了,我们的视神经也是有很多不同的神经单元,有的对速度敏感,有的对竖轴方向敏感,有的对横轴方向敏感等等。
2 一个胶囊的向量输入和输出如何计算
我们想用胶囊输出向量的长度表示实体在当前输入存在的概率。我们采用一个非线性挤压函数,可以使短向量压缩到几乎0长度,而长向量压缩到长度稍许小于1.


整个路由算法如下:

3 胶囊网络CapsNet
下图是一个简单的CapsNet,有两个卷积层和一个全连接层。卷积层Conv1有256,9*9个卷积核,步长为1,以及ReLU激活函数。该层将像素强度转换成本地特征检测者的活跃者,然后作为初级胶囊(primary capsules)的输入。
第2层(PrimaryCapsules)是卷积胶囊层,是32channels,8D胶囊 。每个8D胶囊(primary capsule)包括8个9*9的卷积核(步长2)的卷积单元。将 primary capsules可以看作章节2公式1的一个卷积层。
最后一个层DigitCaps:每个数字分类(digit class)有一个16D 胶囊。
我们在两个相连的胶囊层间路由,如PrimaryCapsules 和 DigitCaps。因为Conv1的输出是1D,所以其空间上没有方向,这样在Conv1和PrimaryCapsules间没有路由。所有路由变量b_ij初始化为0.

4 实验结果
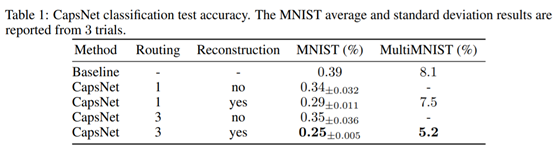
在重叠数字识别上效果也很好


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)