
一篇入门深度学习OCR:数据集和算法合集
转载自CSDN博客:一篇入门深度学习OCR:数据集和算法合集
请去原博点赞!
当前OCR领域基本上已经是深度学习的天下了,近5年,在算法和数据集的双重加持下,OCR已经成为一个解决的问题,要做一个适合于自己的OCR系统,关键在于选择适合于自己场景的数据集和算法。
本文主要记录OCR领域常用的数据集和算法,以及相关的开源项目和博客。
💞1. OCR数据集和数据集生成工具
在任何领域,深度学习成为主流意味着数据集是其中的关键,即使是相同的OCR模型,大规模数据集的训练能带来识别效果上质的提升。
深度学习OCR处理主要分成两步走:
(1)图片中的文本检测,即通过文本框框出图片中的文本。
(2)识别出文本框中的文本。
对应的,公开的数据集也分成这两类。
💘1.1 文本检测数据集
1.1.1 SynthText (ST)
文本检测数据集使用最为广泛的是SynthText (ST),可以说是OCR领域的 ImageNet,该数据集由牛津大学工程科学系视觉几何组的 Gupta, A. and Vedaldi, A. and Zisserman, A. 于 2016 年在 IEEE 计算机视觉 和模式识别会议 (CVPR) 上发布。
数据集采用合成的方式生成,在80万张图片中人工加入了800万个文本,而且这种合成并不是很生硬的叠加,而是作了一些处理,使文字在图片中看起来比较自然。一些案例如下:

此外,数据集合成的方法也在github上开源了,目前对这个项目的中文支持也已经实现:https://github.com/JarveeLee/SynthText_Chinese_version
1.1.2 IC03 IC13 IC15
ICDAR2003/2013/2015 Robust Reading Challenge 比赛用数据集,数据集的每一张图片都来自真实的场景,并且做好了标注。但是样本比较少,合起来只有几千张。一些样例如下图所示:

1.1.3 COCO-Text
ICDAR2017 Robust Reading Challenge 的数据集,和上面两个数据集类似,是实景采集的图片,但是规模要大不少,有63686个样本。一些样本示例如下图所示:

1.1.4 IIIT
IIIT 5k words 数据集是从谷歌图像搜索中获得的。主要包括广告牌,招牌,门牌号,门牌,电影海报被用来收集图像。数据集包含5000个样本,一些示例如下图所示:

1.1.5 SVT
SVT(Street View Text)为街景中含文本的图片数据集,2012年发布,和 IC13/15/17类似,总共包含350张图片,一些样例如下图所示:

1.1.6 CUTE
CUTE(Curve Text )包含80张含弯曲文本的图像及标注。一些样例如下图所示:

1.1.7 ICDAR 2017 RCTW
ICDAR 大赛中文识别数据集RCTW(Reading Chinese Text in the Wild),包含一万多张含中文文本的自然场景图片。一些样例如下图所示:

1.2 数据集总结
上文还有很多数据集没有覆盖到,除了第一个SynthText (ST)规模较大,其他的数据集大多不足以训练一个模型。通常的做法是,根据具体的识别场景(中文/英文,街景/文档等),先用SynthText (ST)训练,然后再用小规模数据集调优。
可以参考:https://github.com/HCIILAB/Scene-Text-Recognition
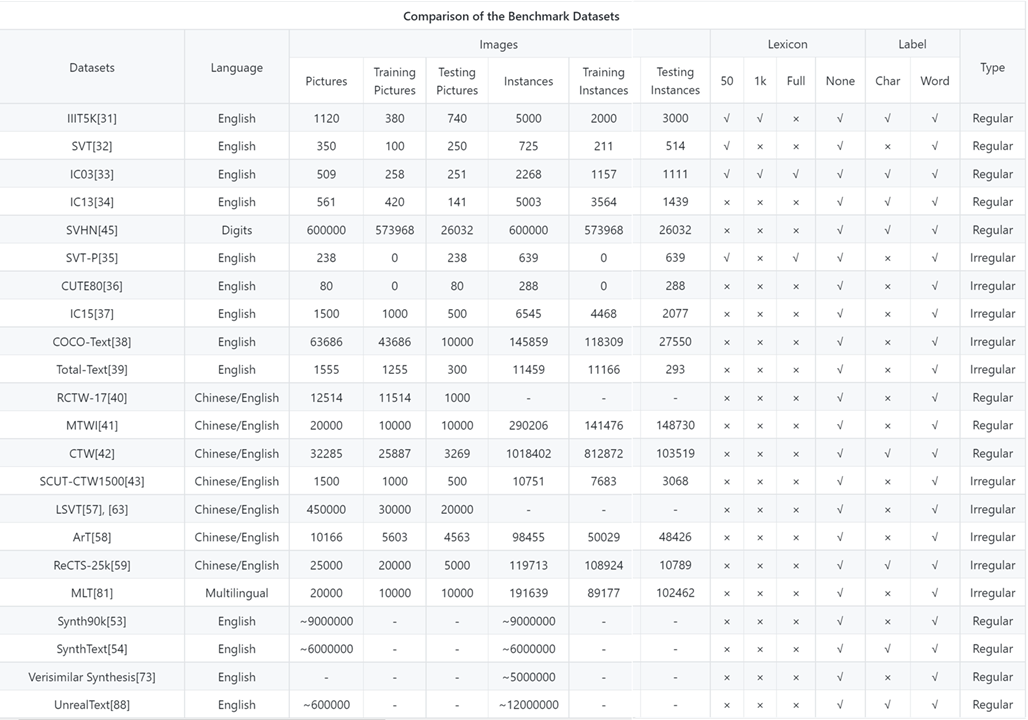
💓1.2 文本识别数据集
文本识别数据集和文本检测数据集的区别在于,文本识别数据集中的图片主体是文本,而没有大量的背景。
文本识别数据集的获取方法有两种,一种是通过文本检测数据集的标注信息,从文本检测数据集中截取含文本的部分,作为文本识别数据集。
第二种方式是人工合成数据集,其中最经典的数据集是 Synthetic Word Dataset,包含800万张合成图片,同样由牛津大学工程科学系视觉几何组合成,一些图片样例如下: 
此外,可以利用开源项目:https://github.com/Belval/TextRecognitionDataGenerator
来合成自己想要的数据集。还有很多其它的文本合成开源项目,但是方法大同小异,只要熟悉其中一个,即可通过自己的修改达到自己想要的效果。
💌2. 深度学习OCR算法
当前深度学习OCR算法均采用上述的两阶段模式:文本检测+文本识别,端到端的方式虽有研究,但是效果不佳。
💟2.1 文本检测
其中文本检测是目标检测算法中的一种,由于目标检测算法发展比较快,所以文本检测算法的发展也比较快。早期,文本检测借鉴目标检测的思想,采用 YOLO V3 和 faster-RCNN 取得了一定的效果,但是由于文本的以下特点:
(1)文字和文字之前存在空隙
(2)文字可能和背景的区分度不够大
(3)文本检测要求极高的精度,否则会对后面的识别带来很大的困难。
所以现在这些常规的目标检测算法基本上在文本检测领域被淘汰,取而代之的是专用的文本检测算法。
2.1.1 CTPN
CTPN的核心思想是将图片按宽度为16像素分成很多个小格,检测每一个小格中是否包含文本,同时预测文本的高度和宽度。最后将多个检测结果融合,形成最终的文本框。
原理可以参考:
自然场景文本检测技术综述(CTPN, SegLink, EAST)
场景文字检测—CTPN原理与实现
实现可以参考:
文本检测CTPN的实现可以参考博客:
- 【OCR技术系列之六】文本检测CTPN的代码实现,对应的github地址为:https://github.com/AstarLight/Lets_OCR/tree/master/detector/ctpn,该实现基于pytorch框架。
- tensorflow的实现:https://github.com/eragonruan/text-detection-ctpn
后一个项目的检测效果如下(提供的训练好的模型),可以看到对于水平的文本,检测效果相当不错,我也试了一些模糊的照片,可以说,对于水平文本来说,很少有模型的文本检测效果超过CTPN。

但是CTPN有一个致命的缺点,就是对于倾斜和弯曲的文本检测效果很差,这个是因为模型自身的原理决定,很难通过训练解决。
2.1.2 CRAFT
韩国人工智能公司CLOVA AI 公司2019年提出的算法,可以识别任意角度的文本,而且可以给出图片中每一个像素为文本的置信分。一个识别样例如下图所示:

CRAFT 模型的原理可以参考:
-
Character Region Awareness for Text Detection解读
-
CRAFT:基于字符区域感知的文本检测
实现可以参考:
- 官方实现:pytorch :https://github.com/clovaai/CRAFT-pytorch
由于该模型已经商用,所以官方实现只提供了推理部分,没有提供训练部分,没有办法后续优化。
- pytorch 复现:https://github.com/backtime92/CRAFT-Reimplementation 包括训练和推理
- keras实现:https://github.com/RubanSeven/CRAFT_keras
2.1.3 Seglink
在CTPN基础上进行改进,利用开源项目测试了PAN卡和A卡,由于效果不佳,暂时没有深入研究,从论文的结果来看,在复杂场景下的识别效果要好于CTPN。
原理参考:
- 自然场景文本检测技术综述(CTPN, SegLink, EAST)
github 开源实现:
- tensorflow 实现 https://github.com/bgshih/seglink
2.1.4 EAST
在Seglink基础上的改进算法,在识别倾斜和弯曲文本的效果上比较好,同样利用开源项目进行了测试,但是项目不是很理想,有待深入研究。从当前的趋势来看,EAST将成为主流的文本检测算法之一。
原理参考:
-
自然场景文本检测技术综述(CTPN, SegLink, EAST)
-
文本检测之EAST
开源实现:
- tensorflow实现:https://github.com/argman/EAST
2.1 总结
当前文本检测算法还在高速发展当中,比如PixelLink、RRPN和TextBoxes等,从论文的对比结果来看都取得了相当不错的结果,后续可以深入研究。
目前来看,CTPN是应用最为广泛的检测算法,但是由于在倾斜文本上检测的不足,所以使用场景受到一定的限制。
另外,从CRAFT的测试来看,是一种极为高效的算法(计算耗时也不高),并且由于可以得到每一个像素属于文字的置信分,在不同的场景下可以针对信的调优,所以值得重点研究。
💝2.2 文本识别
相对文本检测而言,文本识别的算法比较有限,主要有两种思路:
(1)CRNN:CNN+RNN+CTC
(2)CNN+Seq2Seq+Attention
2.2.1 CRNN:CNN+RNN+CTC
当前应用最为广泛的模型为 CNN+RNN+CTC,其中CNN用于提取图像特征,RNN在CNN提取特征的基础上,通过双向LSTM提取相邻下像素之间的特征,最后CTC用于计算损失函数。
其中CTC实现不定长输入问题的损失函数计算,在语音识别领域应用广泛。
原理参考:
-
一文读懂CRNN+CTC文字识别
-
端到端不定长文字识别CRNN算法详解
开源实现:
官方开源:
-
tensorflow实现 https://github.com/bgshih/crnn
-
pytorch 实现:端到端不定长文本识别CRNN代码实现 对应代码:https://github.com/AstarLight/Lets_OCR/tree/master/recognizer/crnn
2.2.2 CNN+Seq2Seq+Attention
引入了attention机制,有待研究,但是通过开源项目的测试,效果相当好,应该会逐渐替代CRNN成为主流。
开源实现:
另外韩国公司CLOVA AI文字识别项目中也实现了这个方法,且用预训练的模型效果非常好:
这个项目了不起的地方还在于把文本识别模块化(特征提取-序列特征提取-特征转换-预测),使每一个模块可以单独优化,从而量化不同模块的贡献。
🥪2.3 现成可用的库
在英文OCR方面,keras开源库实现了文字检测和文字识别的整合,其中文字检测用的事CRAFT,文字识别用的是CRNN。
而且安装非常方便:pip install keras-ocr
然后就可以通过以下代码进行测试:
import matplotlib.pyplot as plt
import keras_ocr
# keras-ocr will automatically download pretrained
# weights for the detector and recognizer.
pipeline = keras_ocr.pipeline.Pipeline()
# Get a set of three example images
images = [
keras_ocr.tools.read(url) for url in [
'test.jpg'
]
]
# Each list of predictions in prediction_groups is a list of
# (word, box) tuples.
prediction_groups = pipeline.recognize(images)
# Plot the predictions
fig, axs = plt.subplots(nrows=len(images), figsize=(20, 20))
for ax, image, predictions in zip(axs, images, prediction_groups):
keras_ocr.tools.drawAnnotations(image=image, predictions=predictions, ax=ax)
通过简单的几段代码就可以实现完整的OCR识别!识别效果看下图:

英文的识别效果还是相当ok的,中文的话还需要额外训练。
开源地址为:https://github.com/faustomorales/keras-ocr
在中文OCR方面,百度开源中英文识别模型,试用下来效果还是不错的:
https://github.com/paddlepaddle/paddlehub
在文本检测上用了DBnet:https://github.com/MhLiao/DB,文本识别上用了CRNN。

在中文OCR需要快速上线的时候可以使用,paddlepaddle的性能也是有保障的。
3. 深度学习相关博客
1、博客园:冠军的试炼 博客介绍了很多跟OCR相关的预处理方法(openCV),以及介绍了很多深度学习OCR相关的算法原理和实现。
2、知乎:白裳 知乎介绍了很多深度学习相关的OCR算法,原理介绍比较清楚,同时有对应的github开源项目,
3、知乎:燕小花 介绍了很多最新的文本检测成果,偏原理介绍
3、Pyimagesearch,微软图像大牛做的一个博客,里面有很多openCV和OCR相关的文章,新手友好。
4、openCV 入门:OpenCV Python中文教程 + 代码
4. 相关书籍
1、深度实践OCR:基于深度学习的文字识别
阿里团队出版的一本图书,介绍了经典的OCR算法,广度够,深度不够,适合建立一个算法体系。

5.识别加速
OCR 因为用到了两阶段的识别方式,用到的模型也比较复杂,所以在识别速度上有一定欠缺。识别一张复杂图片在不做优化的情况下通常都要 1s 以上,对于追求机智性能的场景需要对模型的推理速度进行优化,目前,模型推理速度优化用得比较多的工具主要有腾讯家的ncnn 和阿里的mnn。
腾讯ncnn: https://github.com/Tencent/ncnn

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 14
14 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)