COCO数据集介绍
文章目录1、COCO数据集的介绍2、COCO数据集结构及组成介绍本文主要是为了熟悉COCO数据集。1、COCO数据集的介绍首先上两个链接,第一个,第二个有以上两个链接足够了解COCO2、COCO数据集结构及组成介绍本部分主要是参考https://zhuanlan.zhihu.com/p/70878433,这个链接进行同步整理的,直接看原文也可以,只是觉的原文有点乱,不便于整体掌据该数据集。...
文章目录
本文主要是为了熟悉COCO数据集。
1、COCO数据集的介绍
首先上两个链接,第一个 ,第二个
有以上两个链接足够了解COCO
整个数据集的分布如下
#step1: 下载数据集
2017 Train images [118K/18GB]
2017 Val images [5K/1GB]
2017 Test images [41K/6GB]
2017 Train/Val annotations [241MB]
#step2: 按照下面结构存放文件夹
coco
├── annotations
│ ├── instances_train2014.json
│ ├── instances_train2017.json
│ ├── instances_val2014.json
│ ├── instances_val2017.json
│ | ...
├── train2017
│ ├── 000000000009.jpg
│ ├── 000000580008.jpg
│ | ...
├── val2017
│ ├── 000000000139.jpg
│ ├── 000000000285.jpg
│ | ...
| ...
2、COCO数据集标注格式
本部分主要是参考https://zhuanlan.zhihu.com/p/70878433,这个链接进行同步整理的,直接看原文也可以,只是觉的原文有点乱,不便于整体掌据该数据集。
COCO数据集大量使用Amazon Mechanical Turk来收集数据。COCO数据集现主要有三种标注类型:
- object instance 目标实例
- object keypoints 目标关键点
- image captions 看图说话。
标注文件使用JSON文件进行存储。如下为COCO2017数据集中train,val的标注文件:
原文件是annotations_trainval2017.zip,解压后是annotations文件夹。可以看到一共有三种类型,每种类型包含训练和验证,共有6个JSON文件。
2.1实例分割Object Instance文件格式
以instance_val2017.json为例(验证集文件软小,打开较快),总体格式如下:
{
"info": info,
"licenses": [license],
"images":[image],
"annotations":[annotation],
"categories":[category]
}
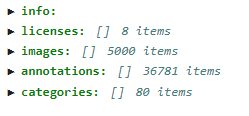
- images字段下是一个列表,列表长度等同于划入训练集(或验证集)的图片数量
- annotatons字段下也是一个列表,列表长度等同地训练集(或验证集)中bounding box 的数量
- categories字段下也是一个列表,列表长度等同于数据集类别的数,coco2017分类数是80,用VScode打开看:

可以看到整个JSON文件是一个大的数字典。
通过jupyterlab打开看:

2.1.1 info中的内容
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
},

info中包括一些基本信息,时间,版本,贡献者等,没什么太大价值,可以忽略。
2.1.2 licenses中的内容
内容较少,这里全部列出:
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nc/2.0/",
"id": 2,
"name": "Attribution-NonCommercial License"
},
{
"url": "http://creativecommons.org/licenses/by-nc-nd/2.0/",
"id": 3,
"name": "Attribution-NonCommercial-NoDerivs License"
},
{
"url": "http://creativecommons.org/licenses/by/2.0/",
"id": 4,
"name": "Attribution License"
},
{
"url": "http://creativecommons.org/licenses/by-sa/2.0/",
"id": 5,
"name": "Attribution-ShareAlike License"
},
{
"url": "http://creativecommons.org/licenses/by-nd/2.0/",
"id": 6,
"name": "Attribution-NoDerivs License"
},
{
"url": "http://flickr.com/commons/usage/",
"id": 7,
"name": "No known copyright restrictions"
},
{
"url": "http://www.usa.gov/copyright.shtml",
"id": 8,
"name": "United States Government Work"
}
],

一共有8条,也没什么价值,可以忽略。
2.1.3 images中的内容
内容较多,列几条:
"images": [
{
"license": 4,
"file_name": "000000397133.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000397133.jpg",
"height": 427,
"width": 640,
"date_captured": "2013-11-14 17:02:52",
"flickr_url": "http://farm7.staticflickr.com/6116/6255196340_da26cf2c9e_z.jpg",
"id": 397133
},
{
"license": 1,
"file_name": "000000037777.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000037777.jpg",
"height": 230,
"width": 352,
"date_captured": "2013-11-14 20:55:31",
"flickr_url": "http://farm9.staticflickr.com/8429/7839199426_f6d48aa585_z.jpg",
"id": 37777
},
{
"license": 4,
"file_name": "000000252219.jpg",
"coco_url": "http://images.cocodataset.org/val2017/000000252219.jpg",
"height": 428,
"width": 640,
"date_captured": "2013-11-14 22:32:02",
"flickr_url": "http://farm4.staticflickr.com/3446/3232237447_13d84bd0a1_z.jpg",
"id": 252219
},

jupyter中看的效果:
images是一个列表,列表中每一个元素是一个字典,存储一张图片中的信息。分别就图片信息做出说明:
- license: 没用
- file_name:图片文件名
- coco_url:没用
- height:图片高
- width:图片宽
- date_captured:没用
- flickr_url没用
- id:图片的身份ID,每个图片特有的
在以上信息中,height,width,file_name,id这四个值非常重要。
2.1.4 annotations中的内容
该内容较多,列几条:
"annotations": [
{
"segmentation": [
[
510.66,
423.01,
511.72,
...
423.01,
510.45,
423.01
]
],
"area": 702.1057499999998,
"iscrowd": 0,
"image_id": 289343,
"bbox": [
473.07,
395.93,
38.65,
28.67
],
"category_id": 18,
"id": 1768
},
{
"segmentation": [
[
289.74,
443.39,
302.29,
...
444.27,
291.88,
443.74
]
],
"area": 27718.476299999995,
"iscrowd": 0,
"image_id": 61471,
"bbox": [
272.1,
200.23,
151.97,
279.77
],
"category_id": 18,
"id": 1773
},
......
"segmentation": {
"counts": [
272,
2,
4,
4,
...
16,
228,
8,
10250
],
"size": [
240,
320
]
},
"area": 18419,
"iscrowd": 1,
"image_id": 448263,
"bbox": [
1,
0,
276,
122
],
"category_id": 1,
"id": 900100448263
},

jupyter中效果:
annotations是该JSON文件中最重要的。annotations是包含多个annotation实例的数组,annotation类型本身又包含一系列的字段:
- segmentation:分割标签
- area:面积
- iscrowd: 是否多个目标
- image_id:与images中的id对应
- bbox:目标框
- category_id:类别
- id:标注框的一个序号
整体来说annotation的格式如下:
annotation{
"segmentation": RLE or [polygon],
"area" :float,
"iscrowd": 0 or 1,
"imgae_id": int,
"bbox": [x,y,width,height],
"category_id": int,
"id": int
注意,单个对像(iscrowd=0)可能需要多个polygon来表示,比如这个对像在图像中被挡住;而iscrow=1时(将标注一组对像,比如一群人),segmentation的格式是RLE格式。也就是说,只要iscrowd=0,那么segmentation格式就是polygon; 而iscrowd=1,则segmentation格式是RLE。另外不论iscrowd是0还是1,每个对像都会有一个矩型框bbox,提供框的左上角坐标以及矩形框的高和宽。
segmentation polygon格式,可以看到,是一个二维的列表,里面的一堆数字是像素级分割得到的物体边缘坐标,从上文中也能看到,坐标是成对出现的;RLE格式如下:
segmentation :
{
'counts': [272, 2, 4, 4, 4, 4, 2, 9, 1, 2, 16, 43, 143, 24......],
'size': [240, 320]
}
COCO数据集的RLE都是uncompressed RLE格式(与之相对的是compact RLE)。 RLE所占字节的大小和边界上的像素数量是正相关的。RLE格式带来的好处就是当基于RLE去计算目标区域的面积以及两个目标之间的unoin和intersection时会非常有效率。 上面的segmentation中的counts数组和size数组共同组成了这幅图片中的分割 mask。其中size是这幅图片的宽高,然后在这幅图像中,每一个像素点要么在被分割(标注)的目标区域中,要么在背景中。很明显这是一个bool量:如果该像素在目标区域中为true那么在背景中就是False;如果该像素在目标区域中为1那么在背景中就是0。对于一个240x320的图片来说,一共有76800个像素点,根据每一个像素点在不在目标区域中,我们就有了76800个bit,比如像这样(随便写的例子,和上文的数组没关系):00000111100111110…;但是这样写很明显浪费空间,我们直接写上0或者1的个数不就行了嘛(Run-length encoding),于是就成了54251…,这就是上文中的counts数组。
area指向该segmentation的面积,iscrowd=0表示没有重叠,iscrowd=1表示有重叠;image_id就是前面images中存储的id.bbox指向的是物体的标注框;category_id指向的数字代表分类,共有80个分类;id不同于images中的id,这里的id只是每个框的身份编号。
2.1.4 categories中的内容
如下:
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person"
},
{
"supercategory": "vehicle",
"id": 2,
"name": "bicycle"
},
{
"supercategory": "vehicle",
"id": 3,
"name": "car"
},
{
"supercategory": "vehicle",
"id": 4,
"name": "motorcycle"
},
{
"supercategory": "vehicle",
"id": 5,
"name": "airplane"
},
{
"supercategory": "vehicle",
"id": 6,
"name": "bus"
},
{
"supercategory": "vehicle",
"id": 7,
"name": "train"
},
{
"supercategory": "vehicle",
"id": 8,
"name": "truck"
},
{
"supercategory": "vehicle",
"id": 9,
"name": "boat"
},
{
"supercategory": "outdoor",
"id": 10,
"name": "traffic light"
},
{
"supercategory": "outdoor",
"id": 11,
"name": "fire hydrant"
},
{
"supercategory": "outdoor",
"id": 13,
"name": "stop sign"
},
{
"supercategory": "outdoor",
"id": 14,
"name": "parking meter"
},
{
"supercategory": "outdoor",
"id": 15,
"name": "bench"
},
{
"supercategory": "animal",
"id": 16,
"name": "bird"
},
{
"supercategory": "animal",
"id": 17,
"name": "cat"
},
{
"supercategory": "animal",
"id": 18,
"name": "dog"
},
{
"supercategory": "animal",
"id": 19,
"name": "horse"
},
{
"supercategory": "animal",
"id": 20,
"name": "sheep"
},
{
"supercategory": "animal",
"id": 21,
"name": "cow"
},
{
"supercategory": "animal",
"id": 22,
"name": "elephant"
},
{
"supercategory": "animal",
"id": 23,
"name": "bear"
},
{
"supercategory": "animal",
"id": 24,
"name": "zebra"
},
{
"supercategory": "animal",
"id": 25,
"name": "giraffe"
},
{
"supercategory": "accessory",
"id": 27,
"name": "backpack"
},
{
"supercategory": "accessory",
"id": 28,
"name": "umbrella"
},
{
"supercategory": "accessory",
"id": 31,
"name": "handbag"
},
{
"supercategory": "accessory",
"id": 32,
"name": "tie"
},
{
"supercategory": "accessory",
"id": 33,
"name": "suitcase"
},
{
"supercategory": "sports",
"id": 34,
"name": "frisbee"
},
{
"supercategory": "sports",
"id": 35,
"name": "skis"
},
{
"supercategory": "sports",
"id": 36,
"name": "snowboard"
},
{
"supercategory": "sports",
"id": 37,
"name": "sports ball"
},
{
"supercategory": "sports",
"id": 38,
"name": "kite"
},
{
"supercategory": "sports",
"id": 39,
"name": "baseball bat"
},
{
"supercategory": "sports",
"id": 40,
"name": "baseball glove"
},
{
"supercategory": "sports",
"id": 41,
"name": "skateboard"
},
{
"supercategory": "sports",
"id": 42,
"name": "surfboard"
},
{
"supercategory": "sports",
"id": 43,
"name": "tennis racket"
},
{
"supercategory": "kitchen",
"id": 44,
"name": "bottle"
},
{
"supercategory": "kitchen",
"id": 46,
"name": "wine glass"
},
{
"supercategory": "kitchen",
"id": 47,
"name": "cup"
},
{
"supercategory": "kitchen",
"id": 48,
"name": "fork"
},
{
"supercategory": "kitchen",
"id": 49,
"name": "knife"
},
{
"supercategory": "kitchen",
"id": 50,
"name": "spoon"
},
{
"supercategory": "kitchen",
"id": 51,
"name": "bowl"
},
{
"supercategory": "food",
"id": 52,
"name": "banana"
},
{
"supercategory": "food",
"id": 53,
"name": "apple"
},
{
"supercategory": "food",
"id": 54,
"name": "sandwich"
},
{
"supercategory": "food",
"id": 55,
"name": "orange"
},
{
"supercategory": "food",
"id": 56,
"name": "broccoli"
},
{
"supercategory": "food",
"id": 57,
"name": "carrot"
},
{
"supercategory": "food",
"id": 58,
"name": "hot dog"
},
{
"supercategory": "food",
"id": 59,
"name": "pizza"
},
{
"supercategory": "food",
"id": 60,
"name": "donut"
},
{
"supercategory": "food",
"id": 61,
"name": "cake"
},
{
"supercategory": "furniture",
"id": 62,
"name": "chair"
},
{
"supercategory": "furniture",
"id": 63,
"name": "couch"
},
{
"supercategory": "furniture",
"id": 64,
"name": "potted plant"
},
{
"supercategory": "furniture",
"id": 65,
"name": "bed"
},
{
"supercategory": "furniture",
"id": 67,
"name": "dining table"
},
{
"supercategory": "furniture",
"id": 70,
"name": "toilet"
},
{
"supercategory": "electronic",
"id": 72,
"name": "tv"
},
{
"supercategory": "electronic",
"id": 73,
"name": "laptop"
},
{
"supercategory": "electronic",
"id": 74,
"name": "mouse"
},
{
"supercategory": "electronic",
"id": 75,
"name": "remote"
},
{
"supercategory": "electronic",
"id": 76,
"name": "keyboard"
},
{
"supercategory": "electronic",
"id": 77,
"name": "cell phone"
},
{
"supercategory": "appliance",
"id": 78,
"name": "microwave"
},
{
"supercategory": "appliance",
"id": 79,
"name": "oven"
},
{
"supercategory": "appliance",
"id": 80,
"name": "toaster"
},
{
"supercategory": "appliance",
"id": 81,
"name": "sink"
},
{
"supercategory": "appliance",
"id": 82,
"name": "refrigerator"
},
{
"supercategory": "indoor",
"id": 84,
"name": "book"
},
{
"supercategory": "indoor",
"id": 85,
"name": "clock"
},
{
"supercategory": "indoor",
"id": 86,
"name": "vase"
},
{
"supercategory": "indoor",
"id": 87,
"name": "scissors"
},
{
"supercategory": "indoor",
"id": 88,
"name": "teddy bear"
},
{
"supercategory": "indoor",
"id": 89,
"name": "hair drier"
},
{
"supercategory": "indoor",
"id": 90,
"name": "toothbrush"
}
]
分类从1到90,但有些数字是跳过的,所以只有80个分类。
2.2 关键点检测Object Keypoint文件格式
COCO数据集中person_keypoints_train2017.json、person_keypoints_val2017.json这两个文件就是这种格式。文件整体格式是:
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
"categories": [category]
}

与instance_val2017.json相同。其中,info、licenses、images这三部分在不同的JSON文件中是相同的,定义是共享的,不共享的是annotations和category这两种在不同类型的JSON文件中是不一样的。
- images字段下是一个列表,列表长度等同于划入训练集(或验证集)的图片数量
- annotatons字段下也是一个列表,列表长度等同地训练集(或验证集)中bounding box 的数量,这里只有人这个类别的bounding box
- categories字段下也是一个列表,列表长度等同于数据集类别的数,这里是1,只有person这一个类。
相同内容这里就不再列了,只列不同的。
2.2.1 annotations中的内容
这个类型中的annotation结构中包含 object instance中annotation所有的字段,再加上两个额外的字段。新增的keypoints是一个长度为3*k的数组,第一个和第二个元素分别是x和y坐标值,第三个是标志位v,v为0时表示这个关键点没有标注(这种情况下x=y=v=0),v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时也可见。num_keypoints表示这个目标上被标注的关键点的数量(v>0),比较小的目标上可能就无法标注关键点。
annotation{
"segmentation": RLE or [polygon],
"num_keypoints": int,
"area": float,
"iscrowd": 0 or 1,
"keypoints": [x1,y1,v1,...],
"image_id": int,
"bbox": [x,y,width,height],
"category_id": int,
"id": int
}
列举一个:
{
"segmentation": [
[
492.38,
238.33,
491.91,
234.15,
494.47,
227.65,
495.17,
215.1,
497.02,
199.54,
503.53,
197.22,
503.3,
194.43,
503.3,
190.95,
506.08,
183.51,
511.89,
185.84,
514.21,
187,
514.21,
196.29,
521.88,
200.7,
526.76,
216.03,
520.25,
227.65,
519.56,
234.38,
519.09,
239.49,
519.09,
244.84,
519.56,
246.93,
518.16,
248.32,
516.3,
256.91,
510.03,
256.45,
513.28,
240.89
]
],
"num_keypoints": 13,
"area": 1394.7431,
"iscrowd": 0,
"keypoints": [
508,
192,
2,
510,
191,
2,
506,
191,
2,
512,
192,
2,
503,
192,
1,
515,
202,
2,
499,
202,
2,
524,
214,
2,
497,
215,
2,
516,
226,
2,
496,
224,
2,
511,
232,
2,
497,
230,
2,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0
],
"image_id": 440475,
"bbox": [
491.91,
183.51,
34.85,
73.4
],
"category_id": 1,
"id": 183302
}
可以看到一共有17个关键点。

2.2.2 categories中的内容
对于category,相比object instance中的category,新增了两个字段,keypoints是一个长度为k的数组,包含每个关键点的名称;skeleton定义各关键点的连接性(比如人的左手腕和左肘就是连接的,但是左手腕和右手腕就不是)。目前,COCO的keypoints只标注了person category (分类为人)。定义如下:
{
"supercategory": str,
"id": int,
"name": str,
"keypoints": [str],
"skeleton": [edge]
}
具体的:
"categories": [
{
"supercategory": "person",
"id": 1,
"name": "person",
"keypoints": [
"nose",
"left_eye",
"right_eye",
"left_ear",
"right_ear",
"left_shoulder",
"right_shoulder",
"left_elbow",
"right_elbow",
"left_wrist",
"right_wrist",
"left_hip",
"right_hip",
"left_knee",
"right_knee",
"left_ankle",
"right_ankle"
],
"skeleton": [
[
16,
14
],
[
14,
12
],
[
17,
15
],
[
15,
13
],
[
12,
13
],
[
6,
12
],
[
7,
13
],
[
6,
7
],
[
6,
8
],
[
7,
9
],
[
8,
10
],
[
9,
11
],
[
2,
3
],
[
1,
2
],
[
1,
3
],
[
2,
4
],
[
3,
5
],
[
4,
6
],
[
5,
7
]
]
}
]

2.3 看图说话Image Caption文件格式
captions_train2017.json、captions_val2017.json这两个文件就是这种格式。Image Caption这种格式的文件从头至尾按照顺序分为以下段落,看起来和Object Instance一样,不过没有最后的categories字段:
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation]
}
其中,info、licenses、images这三个结构体/类型 ,在不同的JSON文件中这三个类型是一样的,定义是共享的。不共享的是annotations这种结构体,它在不同类型的JSON文件中是不一样的。
- annotations: 数量要多于图片的数量,这是因为一个图片可以有多个场景描述;
2.3.1 annotation中的内容
这个类型中的annotation用来存储描述图片的语句。每个语句描述了对应图片的内容,而每个图片至少有5个描述语句(有的图片更多)。annotation定义如下:
annotation{
"image_id": int,
"id": int,
"caption": str
}
取一个具体片段:
{
"image_id": 546219,
"id": 396378,
"caption": "A large group is sitting together and eating at a restaurant."
},
{
"image_id": 546219,
"id": 397413,
"caption": "The people are gathered at the table for dinner."
},
{
"image_id": 146155,
"id": 397604,
"caption": "Two men standing near a bar drinking together"
},
{
"image_id": 546219,
"id": 399732,
"caption": "A large group of people pose for a photo at dinner."
},
{
"image_id": 546219,
"id": 400023,
"caption": "The diners are enjoying their various beverages with their meals.."
}
这里的image_id对应images中的Id.
本文参考
- https://zhuanlan.zhihu.com/p/70878433
- https://blog.csdn.net/weixin_38293440/article/details/81196428

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)