基于机器学习的新冠疫情预测模型
预测确诊患者数量的机器学习算法最小二乘准则(LSE)预测可以利用回归算法对确诊患者进行预测,有线性回归和非线性回归,根据SIR模型等一般的疫情传播模型。S 类,易感者,指未得病者;I 类,感病者,指染上传染病的人;R 类,康复者,指被隔离或因病愈而具有免疫力的人。线性回归明显是不符合整体疫情的走势,这里不做讨论。同时SIR模型对人群的分类不够细致,没有考虑政府等人为干预的情况,且模型中未引入反馈机
目录
一、预测确诊患者数量的机器学习算法
1. 最小二乘准则(LSE)预测
可以利用回归算法对确诊患者进行预测,有线性回归和非线性回归,根据SIR模型等一般的疫情传播模型。S 类,易感者,指未得病者;I 类,感病者,指染上传染病的人;R 类,康复者,指被隔离或因病愈而具有免疫力的人。
线性回归明显是不符合整体疫情的走势,这里不做讨论。同时SIR模型对人群的分类不够细致,没有考虑政府等人为干预的情况,且模型中未引入反馈机制,所以需要对SIR模型进行改进来进行预测。因此在这里先利用最小二乘准测(least square error, LSE)和梯度下降算法对数据进行非线性回归,预测天数和患者数量的非线性关系[1]。最小二乘准则的基本思路是使得所有样本点到曲线或者面的距离最小。梯度下降主要是通过迭代找到最小二乘准则的损失函数的极小值。
根据疫情传播和发现疫情后的干预,可以将疫情分为两个阶段:
第一阶段就是疫情的自然传播阶段,增长接近指数增长,假设第一天患者数量为n基本再生数为k,则第二天新增感染患者数量为nk ,第三天为
,依次类推,第t天的感染患者数量为:
,k作为基本再生数,n为初始感染人数,t为天数。
第二阶段,疫情传播的渠道被逐渐切断,传染源被逐渐控制,易感人群得到保护,这些措施干预了自然传播,降低了基本再生数k。对疫情的管控力度越大,基本再生数k就越小。根据SIR模型,当k小于1时,传染病才可被控制住。假设在第 天,开始实现严格管控,再生数k小于1,则可以得出:
其中, 为管控后的再生数,是关于时间和政府干预强度的变量。
由上述疫情的模型,利用最小二乘准则,可得目标函数,即损失函数:,其中
为观测样本。
对参数 求偏导,通过迭代求
极小值,完成对参数
的估计。用给定数据进行梯度下降训练,得到极小值后观察预测数据和真实数据的拟合程度,调整学习率等超参数,来实现更好的非线性拟合。
2. 长短期记忆神经网络(LSTM)预测
考虑到新冠疫情有接近14天的潜伏期,所以随着疫情发展研究人员对新冠疫情采取的传染病模型也在不断适合新冠疫情的传播情况,因此选择SEIR模型,增加的E表示暴露者,即染上传染病的人,只是还处于潜伏期状态。
涉及到潜伏期,就需要记住时间较长的历史信息,然后通过学习新的数据同时结合历史信息更新迭代,来使得预测情况能够较好地拟合真实数据。而在机器学习中长短期记忆神经网络(LSTM)模型就可以处理和预测各种时间序列问题,可以用来预测随着时间的推移新感染的人数[2]。LSTM结构如下图1。
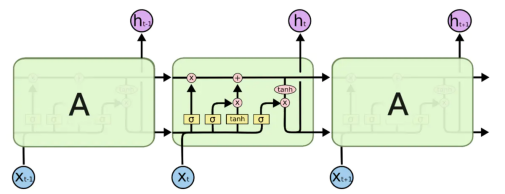
图1. LSTM结构
LSTM具备的功能就是能够保持和编辑细胞的状态。A代表神经网络中的细胞,黄色框表示学习神经网络层,线的的合并表示连接,线的分叉表示传输内容复制到不同的位置。表示表示sigmoid函数,与向量加法或者点乘一起构成LSTM的门(gate),可以看到LSTM神经网络中一个细胞A中具有三个门(gate),正是这三个门,使得LSTM具有删除或者添加信息到细胞状态的能力。
表示当前输入,
表示前一个输入。Tanh作用是细胞状态的值规范化到-1和1之间。
LSTM流程:
第一步,是要从细胞状态中丢弃什么信息,第一个sigmoid函数的输出 。
第二步,是要在细胞状态中存储什么信息。第二个sigmoid函数决定将更新当前数据和前一个输入数据的哪些值 ,接下来 tanh层创建候选向量Ct,该向量将被加入到细胞状态中
,然后结合
和
两个向量来创建更新值
。
最后,需要决定输出内容。sigmoid决定输出细胞状态的哪些状态 , tanh规范化
。
建立好上述模型后,还需要根据COVID-19流行病学参数,将传播概率、潜伏期、恢复率等参数在训练过程中适当调整,以达到缩小误差的目的。
二、基于机器学习的新冠肺炎与流感鉴别
机器学习可以在一定程度上对新冠疫情确诊人数等参考数据进行预测,来预测疫情的拐点和规模,能够为疫情防控争取大量时间。除了对确诊人数等数据的预测,机器学习还可以在医疗诊断上为医生进行初步疾病鉴别和筛选,节约医疗卫生资源,也能为更好更快地防控疫情起到作用。下面要介绍的就是机器学习在进行新冠肺炎与流感鉴别上的可行性与评估[3]。
首先是数据来源和预处理。数据来源可以从三甲医院的门急诊、住院等确诊的流感病例和新冠肺炎确诊患者的病原学或免疫学检测的数据,如血常规、PCT、CRP、核酸检测等检验指标。然后进行预处理,抽取患者的可以用来鉴别的数据建立原始特征库并进行初步筛选。还需要根据具体情况对采集并初步筛选之后的数据进行异常值与噪声处理。
其次是特征选择。采用独立样本t检验的方法对流感与新冠肺炎各项指标进行差异性分析,选取差异性大的指标作为特征指标。
对机器学习算法的鉴别的评估。采取数据特征直方图、密集分布图对数据进行分析,如果大部分数据存在一定程度的偏态分布,则需要对数据进行正态化处理,通过Box-Cox转换提高模型准确度。接下来对线性和非线性算法进行评估。对逻辑回归算法(LR)、线性判别分析(LDA)、分类与回归算法(CART)、支持向量机(SVM)、贝叶斯分类器(NB)和K近邻算法采用10折交叉验证来分离数据。在不同的算法进行流感鉴别分类训练时,可能需要根据具体进行参数调整,逼图SVM算法调参时,惩罚系数C的调整,核函数的选择都会对预测鉴别结果产生影响。
确定预测模型。根据对算法的评估结果,选择一个最优的预测模型,达到较高准确率的预测。
机器学习的相关模型算法有很多,有些模型需要根据特定的情况来进行选择。而在选择之前需要对数据集特征、维度、数据类型、分布状态等进行处理,降低数据的噪声和冗余,有的数据可能还需要对数据集进行特征差异性分析,达到更好鉴别分类的效果。最后利用不同的机器学习方法对数据进行训练和评估,选取最优的分类算法。
三、总结
本文介绍了机器学习算法对新冠疫情的确诊人数的预测和医学检测鉴别。新冠病毒疫情的预测,除了运用机器学习的算法模型本身,更多地需要考虑防控措施,人员流动,不同地区、不同国家等的具体情况,同时传统模型与机器学习模型的结合也具有更重要的现实意义。机器学习应用范围可以比较广泛,除了本文提到的预测和鉴别内容,还有对病情的预测评估、对疫情传播地区的人流预测和管控等方面都可以得到运用。
参考文献
[1] 王志心,刘治,刘兆军. 基于机器学习的新型冠状病毒(COVID-19)疫情分析及预测[J]. 生物医学工程研究,2020,39(1):1-5. DOI:10.19529/j.cnki.1672-6278.2020.01.01.
[2] 宁晴,鲍泓,徐成. 新冠病毒疫情预测模型研究方法评述[C]// 中国计算机用户协会网络应用分会2020年第二十四届网络新技术与应用年会. 2020.
[3] 葛晓伟, 梁盼, 马晓旭,等. 基于机器学习的新冠肺炎与流感快速鉴别方法的研究[J]. 中国数字医学 2020年15卷9期, 21-23

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)