
最短路径问题(更新)
转载自:最短路径问题问题介绍简单地说,就是给定一组点,给定每个点间的距离,求出点之间的最短路径。路径问题大概有以下几种:确定起点的最短路径问题:已知起始点,求起点到其他任意点最短路径的问题。即单源最短路径问题。确定终点的最短路径问题:与确定起点的问题相反,该问题是已知终点,求最短路径的问题。在无向图(即点之间的路径没有方向的区别)中该问题与确定起点的问题完全等同,在有向图(路径间有确定的方向)中该
转载自:最短路径问题
问题介绍
简单地说,就是给定一组点,给定每个点间的距离,求出点之间的最短路径。
路径问题大概有以下几种:
-
确定起点的最短路径问题:已知起始点,求起点到其他任意点最短路径的问题。即单源最短路径问题。
-
确定终点的最短路径问题:与确定起点的问题相反,该问题是已知终点,求最短路径的问题。在无向图(即点之间的路径没有方向的区别)中该问题与确定起点的问题完全等同,在有向图(路径间有确定的方向)中该问题等同于把所有路径方向反转的确定起点的问题。
-
确定起点终点的最短路径问题:已知起点和终点,求任意两点之间的最短路径。即多源最短路径问题。
我们先说明如何输入一个图,并以此为例:
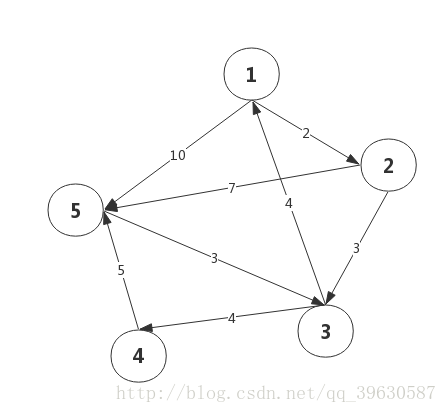
我们通过这样的形式输入数据:
5 8
1 2 2
1 5 10
2 3 3
2 5 7
3 1 4
3 4 4
4 5 5
5 3 3
其中,第一行表示共有5个点(可以理解为城市),8条边(理解为路)。
注意,这里一行的三个数据分别表示i点,j点,和从i到j的单向距离!单向!单向!
我们直接输出最短路程。(也可以加上标记输出路径)
在具体解决问题之前,我们先要把这些数据存储起来,方便调用。这里我们直接用一个二维数组来模拟这个图(它的名字叫邻接矩阵):

在图中,第i列第j行表示的是i到j的距离。其中,将到自己的距离定义为0,用无穷定义没有路径连通。存储到数组中,可以通过二维数组表示。
下面我们就开始分别讲解几种解决最短路径问题的经典算法。
1、深度优先遍历(DFS)
我们知道,深度优先搜索常用于走迷宫,是一种遍历全图的暴力方法。同理,我们利用深度优先遍历,也是通过暴力遍历全图的方法来找到最短路径。因为我们可以在输入数据时对城市进行编号,所以我们将问题的描述改为求从1号城市到5号城市的最短路径长度 。(即初始城市到最后的城市)
我们通过DFS递归函数,从起始1号城市起,不断地判断是否可以通过一个城市到达最后的5号城市(在回溯中判断),然后记录最小路程,不断更新。
//DFS解最短路径问题
#include <iostream>
using namespace std;
const int INF=99999999;//正无穷
int minn=INF;
int n,dist[105][105],book[105];
void dfs(int cur,int dis)
{
int j;
//一点点优化:如果本次查找的路径到此已经超过前面查找的最短路径总长,就不需要再继续了
if(dis>minn)
return;
if(cur==n)//到达要查的城市
{
minn=min(dis,minn);
return;
}
for(j=1;j<=n;j++)//从1号城市到n号城市依次尝试看是否能通过j到达n
{
if(dist[cur][j]!=INF&&book[j]==0)//判断当前城市cur到城市j是否有路,并判断城市j是否已经走过
{
book[j]=1;//标记已经走过
dfs(j,dis+dist[cur][j]);//从城市j再出发,继续寻找
book[j]=0;
}
}
return;
}
int main()
{
int i,j,m,a,b,c;
cin>>n>>m;
//初始化二维矩阵
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(i==j) dist[i][j]=0; //到自己的距离为0
else dist[i][j]=INF; //距离为无限,默认到不了
//读入城市之间的距离
for(i=1;i<=m;i++)
{
cin>>a>>b>>c;
dist[a][b]=c;
}
//从1号城市出发,接下来就交给函数dfs了~
book[1]=1;
dfs(1,0);
cout<<minn;
return 0;
}
事实上,基于广度优先遍历依照节点到初始点的节点数遍历全图的特点,它能解决没有权值(也就是默认每条路程一样长)的图的最小路径问题,但对有权值的图,BFS很难解决(即使加上minn指标,我们也无法处理“回头”的路径)。我们就不在此讲解了。
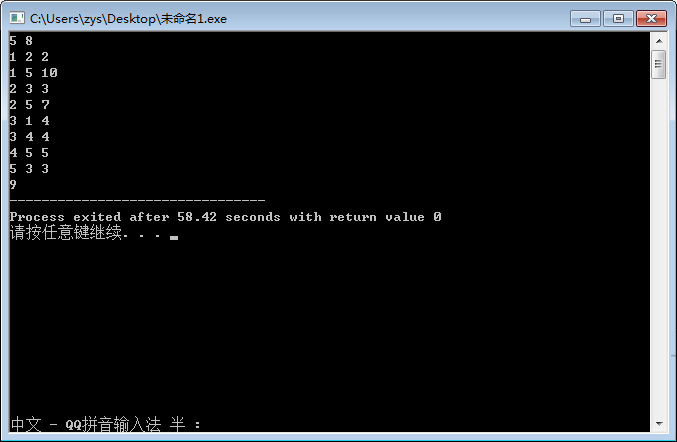
运行结果:
2、Floyd算法
Floyd它可以方便地求出任意两点间的距离,求的是多源最短路径。最大的优点就是容易理解和编写,算法的核心代码只有5行:
//核心代码
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(dist[i][k]+dist[k][j]<dist[i][j])
dist[i][j]=dist[i][k]+dist[k][j]; 我们可以把Floyd算法理解为“如果两点间的路径长度,大于这两点通通过第三点连接的路径长度,那么就修正这两点的最短路径”。
下面我们来具体讲解一下算法的思路:
在代码中,i,j表示的是我们当前循环中所求的起点、终点。k则是我们引入的“中转点”。为什么要引入中转点呢?因为当我们寻找i、j之间的最短路径时,要么是i、j间的距离,要么就是经过其他点中转:i→k→j。
为了方便讲解,我们给出一个概念“松弛”:如果dist【i】【j】>dist【i】【k】+dist【k】【j】(e表示两点间的距离),我们把dist【i】【j】更新为dist【i】【k】+dist【k】【j】,达到“经过中转点k后距离缩短,并记录”的目的。
在第1轮循环中,我们以1为中转点,把任意两条边的距离松弛一遍,更新数组数据。
在第2轮循环中,我们以2为中转点,再松弛一遍。这时,对第1轮松弛更新过的数据,如果继续更新,相当于中转到1,2后取得当前最短路径。
。。。。。。
最后得到的数组就是任意两点间的最短路径。
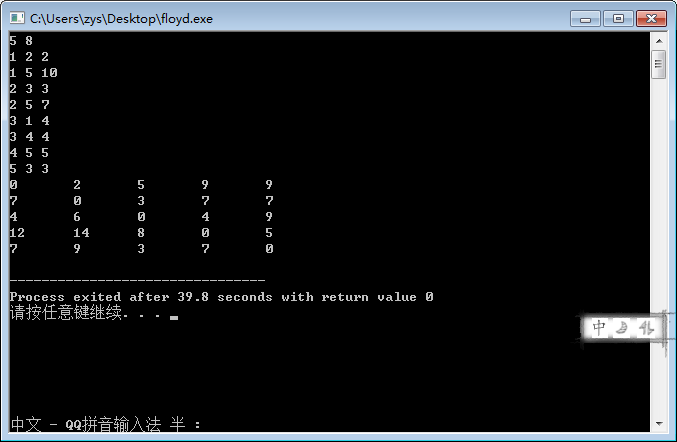
下面放码。
//Floyd算法解最短路径问题
#include <iostream>
using namespace std;
const int INF=99999;
int main()
{
//读入数据的过程和dfs没什么区别,就不讲解了
int i,j,n,m,k,a,b,c;
int dist[105][105];
cin>>n>>m;
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(i==j) dist[i][j]=0;
else dist[i][j]=INF;
for(i=1;i<=m;i++)
{
cin>>a>>b>>c;
dist[a][b]=c;
}
//核心代码
for(k=1;k<=n;k++)
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(dist[i][k]+dist[k][j]<dist[i][j])
dist[i][j]=dist[i][k]+dist[k][j];
for (i=1;i<=n;i++){
for(j=1;j<=n;j++){
cout<<dist[i][j]<<"\t";
}
cout<<endl;
}
return 0;
}
3、Dijkstra算法
Dijkstra 算法主要解决的是单源最短路径问题。它的时间复杂度一般是o(n^2) ,因此相对于Floyd算法速度上有极大的优势,可以处理更多的数据。
算法的核心依旧是上文讲到的“松弛”。只不过松弛的方式略有不同:它通过不断选择距离起点最近的顶点作为新的起点,再利用这些新的起点来松弛其他较远的点,最终计算出所有点到起点最短路径。
我们把点i到起点1的距离定义为dis【i】(现在知道我上面为什么用dist了吧!),用一个book来标记该点是否已经为最短状况,初始化为0(否)
核心代码分为两部分:第一部分判断最小,第二部分进行松弛。
以原题为例:
第一次循环,我们先进入第一部分判断较短距离。第一次到起点1只有2号,5号点有最短距离,分别为2,10。
下一步,我们找到2,5号中到起点1距离较短的点u(这里是2号)。
进入第二部分松弛。对点v,如果v到起点1的距离大于u(即2)到1的距离加上2到v的距离,更新v到原点的距离dis【v】。
开始循环。
在下一次循环中,相当于把点2当作新的起点代替点1,进行上述操作。
可以看出,Dijkstra是一种基于贪心策略的算法,也是一种以DFS为思路的算法。
#贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,贪心算法所做出的是在某种意义上的局部最优解。#
为什么下一条次较短路径要这样选择?(贪心准则的正确性)
因为我们算的是到起点的距离,所以所有路径必然要经过与起点最近的2(或不经过任何别的中转点),而相对于2点,5号点距离更远,还有通过2点松弛之后缩短路径的可能性,所以我们直接选择2为新的起点进行下一步松弛。那么,第k次循环就表示松弛了k次,即经过 了k-1个中转点(或k-1条边)才到达起点1,留在dis()数组中的距离就是经过中转点个数<=k-1(可能无需经过这么多个点就达到)的最短路径。
Dijkstra算法主要特点是以起始点为中心向外层层扩展,从一个顶点到其余各顶点的最短路径算法,直到扩展到最远点(指经过的中转点最多,)为止。(这里就是类似BFS的地方)
选择最短路径顶点的时候依照的是实现定义好的贪心准则,所以该算法也是贪心算法的一种。
下面给出代码。
//Dijkstra算法解最短路径问题
#include<iostream>
using namespace std;
const int INF=99999;
int main()
{
int dist[105][105] ;
int dis[105] ;
int book[105] ;
int i,j,n,m,a,b,c,u,v,Min;
cin>>n>>m;
//开始了!!!
for(i = 1;i <= n;i++) //每轮循环计算的是中转点为n-1时的最小点。
for(j = 1;j <= n;j++)
if(i == j) dist[i][j] = 0;
else dist[i][j] = INF;
for(i = 1;i <= m;i++)
{
cin>>a>>b>>c;
dist[a][b] = c;
}
for(i = 1;i <= n;i++)
dis[i] = dist[1][i];
for(i = 1;i<=n;i++) //初始化标记book
book[i] = 0;
book[1] = 1;
for(i = 1;i <= n-1;i++) //筛出当前没有访问的并且与上一点直接相连的距离最小的点。
{
Min = INF;
for(j = 1;j <= n;j++)
{
if(book[j] == 0&& dis[j] < Min)
{
Min = dis[j];
u = j;
}
}
book[u] = 1;
for(v = 1;v <= n;v++) //松弛
{
if(dist[u][v] < INF)
{
if(dis[v] > dis[u] + dist[u][v])
dis[v] = dis[u] + dist[u][v];
}
}
}
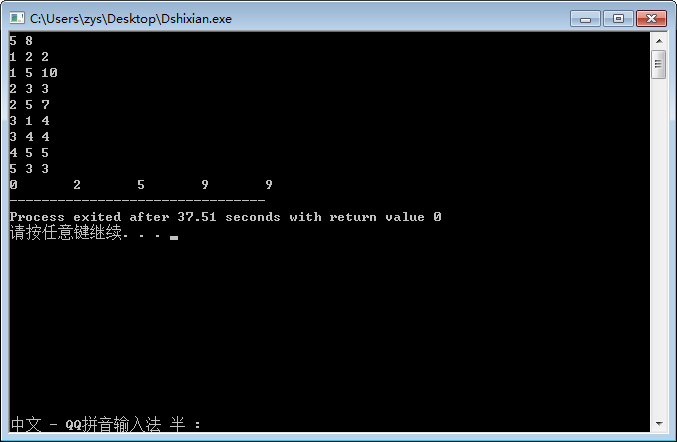
for(i = 1;i <= n;i++)
cout<<dis[i]<<"\t";
return 0;
} 
4、Bellman-Ford算法
与Floyd算法一样,Dijkstra也有自己的问题,那就是无法处理“路径长度”为负的情况。(当然,城市间的距离不可能为负,但在一些特殊的问题中,路径的长度也可以为负)
为什么呢?以第一次循环为例,我们在第一次判断选择了点2为“新起点”,而没有考虑别的点经过点5达到起点1松弛的可能性。假设,点3到点2的距离为1,点3到点5的距离为-100,那点3经过点5松弛的路径实际上更短,而在Dijkstra中,却被我们忽视了。
所以,我们介绍Bellman-Ford算法来解决这种问题。
//Bellman-Ford算法核心部分
for(k = 1;k <= n;k++)
for(i = 1;i <= m;i++)
if(dis[v[i]]>dis[u[i]]+w[i])
dis[v[i]] = dis[u[i]] + w[i];
for(i = 1;i <= m;i++)
if(dis[v[i]]>dis[u[i]]+w[i])可以从代码中看到Bellman-ford与Dijkstra有相似的地方,都是通过松弛操作来达到最短路径。不同的是,Dijkstra是通过从近到远的顺序来按点的顺序松弛,Bellman-ford则是按输入时对每一条边的顺序来松弛。
代码中的数组u(),v(),w()分别存储一行输入的三个数据(i点,j点,i到j的单向距离),这意味着在前文提到的邻接矩阵被我们弃用了,dist()数组不会在这里出现了。
最外轮的k循环表示每次通过k个中转点(这里与Dijkstra相同,同样我们可以理解为经过的边的条数),i循环表示枚举m条边。
看过前面对Dijkstra的讲解,这里应该不难理解了:对每一条编号为i的边,我们比较边i的起点v[i]到起点1的距离dis[v[i]]与边i的另一点u[i]到起点1的距离+ v[i],u[i]的间距dis[u[i]] + w[i],更新dis(j)。那么,第k次循环就表示松弛了k次,即经过 了k-1个中转点(或k-1条边)才到达起点1,留在dis()数组中的距离就是经过中转点个数<=k-1(可能无需经过这么多个点就达到)的最短路径。(细心的朋友可以发现这句话在前文中出现过)
下面回到负值路径的问题上。因为我们是通过边为顺序松弛的,在这个过程中没有放弃对任何一条边(在Dijkstra中,我们放弃了部分数据,比如点5到点3的路径),所以不会有忽视的情况,自然也就能处理负值边了~
我们甚至还能判断负权回路(指一个回路的路径总和为负)。
等等,我们是不是还没提过为什么松弛n-1次后一定能得到最短路径?
-
当没有负权回路时,对于超过n-1条边而到达起点1的路径,一定存在正值回路,肯定可以去掉;
-
当有负权回路时,我们可以无限次地在回路里循环,让路径无限小,也就没有“最短路径了”。
因此,n-1次的松弛必然得到最短路径。
我们就基于2来判断负权回路。在循环n-1次后再对每一条边松弛一次,如果有还能继续松弛的边,则存在负权回路。
我们来看看完整版代码:
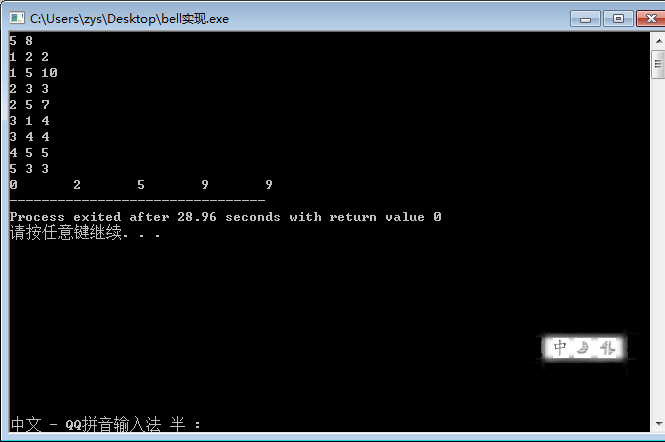
//Bellman-Ford算法解最短路径问题
#include<iostream>
using namespace std;
const int INF=99999;
int main()
{
int dis[105] , i , k , n , m , u[105] , v[105] , w[105];
bool flag=false;
cin>>n>>m;
for(i = 1;i <= m;i++)
cin>>u[i]>>v[i]>>w[i];
for(i = 1;i <= n;i++)
dis[i] = INF;
dis[1] = 0;
//Bellman-Ford算法核心部分
for(k = 1;k <= n;k++)
for(i = 1;i <= m;i++)
if(dis[v[i]]>dis[u[i]]+w[i])
dis[v[i]] = dis[u[i]] + w[i];
for(i = 1;i <= m;i++)
if(dis[v[i]]>dis[u[i]]+w[i])
flag=true;
if (!flag)
for(i = 1;i <= n;i++)
cout<<dis[i]<<"\t";
else
cout<<"存在负权回路!!";
} 
5、SPFA算法
之前我们在谈到Bellman-ford能处理负值路径是提到,Bellman-ford没有放弃对任何一条边的松弛。这虽然不错,但也会是我们优化的一个方向。
我们可以加入一个判断,判断某一条边是否被别的点帮助松弛过,因为只有被松弛过的点才能松弛别的点(被起点松弛也是松弛)。当一个点无法被松弛时,在本次经过k-1条边,它还无法接触到起点1(或者在更早的时候就已经被判断过了),也就没有帮助他人的能力。这是一个递推的过程,需要想明白。如果存在有一个点压根就没能力支援,也就是它本身已经没有存在的价值了,那么我们下次就不用再考虑它了。
注意,在这里我们依然我们始终保留了对负权路径、回路的判断。
我们可以利用队列来存放可以继续帮助松弛的点,舍弃没有利用价值的点。这和BFS是一个道理,一边要保证有k-1轮大循环来控制,一方面又要舍弃旧点增加新点,队列就可以有这个作用。所以当代码写出来是你会惊讶地发现,它和BFS的形式是那么地相似。
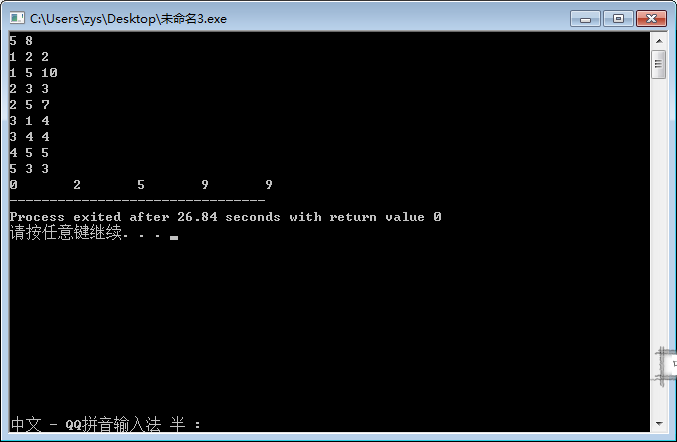
//SPFA解最短路径问题
#include <iostream>
using namespace std;
int main(){
int n,m,i,j,k;
int dis[105]={0},book[105]={0};
//book数组用来记录哪些顶点已经在队列中
int que[1000]={0},head=1,tail=1;//定义一个队列,并初始化队列
int dist[105][105];
int INF = 99999999;
int a,b,c;
cin>>n>>m;
//初始化
for(i=1;i<=n;i++)
dis[i]=INF;
dis[1]=0;
for(i=1;i<=n;i++)
book[i] = 0; //初始化为0,刚开始都不在队列中
//初始化二维矩阵
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(i==j) dist[i][j]=0; //到自己的距离为0
else dist[i][j]=INF; //距离为无限,默认到不了
//读入城市之间的距离
for(i=1;i<=m;i++)
{
cin>>a>>b>>c;
dist[a][b]=c;
}
//1号顶点入队
que[tail]=1; tail++;
book[1]=1;//标记1号顶点已经入队
while(head<tail){//队列不为空的时候循环
for (i=1;i<=n;i++)
if (dist[que[head]][i]!=INF && i!=que[head])
{
k=i; // k表示每一条边的对应顶点
if(dis[k]>dist[que[head]][k]+dis[que[head]] ) //判断是否松弛成功
{
dis[k]=dist[que[head]][k]+dis[que[head]];
//这的book数组用来判断顶点v[k]是否在队列中
/*如果不使用一个数组来标记的话,判断一个顶点是否在队列中每次
都 需要从队列的head到tail扫一遍,很浪费时间*/
if(book[k]==0)//0表示不在队列中,将顶点v[k]加入队列中
//下面两句为入队操作
{
que[tail] = k;
tail++;
//同时标记顶点v[k]已经入队
book[k] =1;
}
}
}
//出队
book[que[head]] = 0;
head++;
}
for(i=1;i<=n;i++)
cout<<dis[i]<<"\t";
return 0;
} 
注:
#网上很多资料提到SPFA都会提到邻接表,这里我为了偷懒就随便讲下啦~~代码中我用的是邻接矩阵存储的,请放心食用。
大致是因为,当图的边数较少时(相对于顶点而言,边数M<顶点数N^2)(我们称为稀疏图,对应稠密图),用这样的方法来存储可以极大地降低时间复杂度。
大致是利用了链表的原理实现的。有兴趣可以自己搜索。#
算法总结
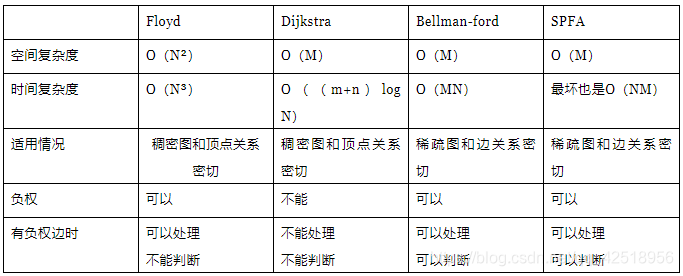

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 59
59 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)