Learning Structured Representation for Text Classification via Reinforcement Learning
前言:对于自然语言处理文本分类来说,相信大家都不陌生,而如何提高文本分类的准确性,这就是一个非常有趣的问题。一直以来,可能大家都觉得强化学习在游戏领域的应用比较广泛,而对于如何应用至文本分类感到陌生,而本文将以AAAI2018一篇论文作为引子,介绍文本分类任务中如何利用强化学习去增强模型,让模型在环境状态从错误中学习到更好的分类结果。文章:Learning Structured Represent
关注微信公众号:NLP分享汇。【喜欢的扫波关注,每天都在更新自己之前的积累】

文章链接:https://mp.weixin.qq.com/s/CvpuCZQIBEPnvdyjtKv1nA
《 Learning Structured Representation for Text Classification via Reinforcement Learning 》
前言:对于自然语言处理文本分类来说,相信大家都不陌生,而如何提高文本分类的准确性,这就是一个非常有趣的问题。一直以来,可能大家都觉得强化学习在游戏领域的应用比较广泛,而对于如何应用至文本分类感到陌生,而本文将以AAAI2018一篇论文作为引子,介绍文本分类任务中如何利用强化学习去增强模型,让模型在环境状态从错误中学习到更好的分类结果。
链接:http://coai.cs.tsinghua.edu.cn/hml/media/files/aaai2018-structured-rep.pdf
理解难度:★★★★★

◆ 论文动机
如果做一个句子分类,首先要给句子做一个表示,经过sentence representation得到句子表示,把“表示”输入分类器中,最终就会得到这个句子属于哪一类。
-
传统的sentence representation 有以下几个经典模型:
-
bag-of-words;
-
CNN;
-
RNN;
-
加入注意力机制的方法。
-
-
以上几种方法有一个共同的不足之处,完全没有考虑句子的结构信息。所有就有第五种 tree-structured LSTM。不过这种方法也有一定的不足,虽然用到了结构信息,但是用到的是需要预处理才能得到的语法树结构。并且在不同的任务中可能都是同样的结构,因为语法都是一样的。
◆ 方法(模型结构)
所以我们希望能够学到和任务相关的结构,并且基于学到的结构给句子做表示,从而希望能得到更好的分类结构。但面临的挑战是我们并不知道什么样的结构对于这个任务是好的,我们并没有一个结构标注能够指导我们去学这个结构。但我们可以根据新的结构做出的分类结果好不好从而判断这个结构好不好。
那么,其实可以使用强化学习来对该问题进行建模,使用策略网络来对文本从前往后扫描,得到action(删除,切开)的序列,action的序列即为该文本的表示,利用该表示再输入分类的网络进行分类。在该应用中,强化学习的reward信号来自于文本分类的准确度。【图1 策略网络PNet】
本文提出模型架构【模型是由一个policy network和一个classification network构成的,其中policy network对应核心部分“强化学习”】

图1 策略网络PNet
🦉Policy Network ( PNet )
-
目的:为每个状态采样一个action
-
模型架构
-
Information Distilled LSTM (ID-LSTM) :选择重要的,与任务相关的词来构建结构表示。【图2上半部分】
-
Hierarchical Structured LSTM (HS-LSTM) :可以发掘短语结构,使用两层信息去构建句子表示。先把字符切开连接得到短语,层层往上,所以是一种层次化的结构,其中action是(Inside,End),状态就是当前的词与上一个词的组合,奖励就是当前类别的似然概率和结构化参数。【图2下半部分】
-
🦉Structured Representation Model
-
迁移action(动作)序列到sentence representation(句子表示)中。
🦉Classification Network ( CNet )
-
提供一个reward(回报),以分类准确率的形式。
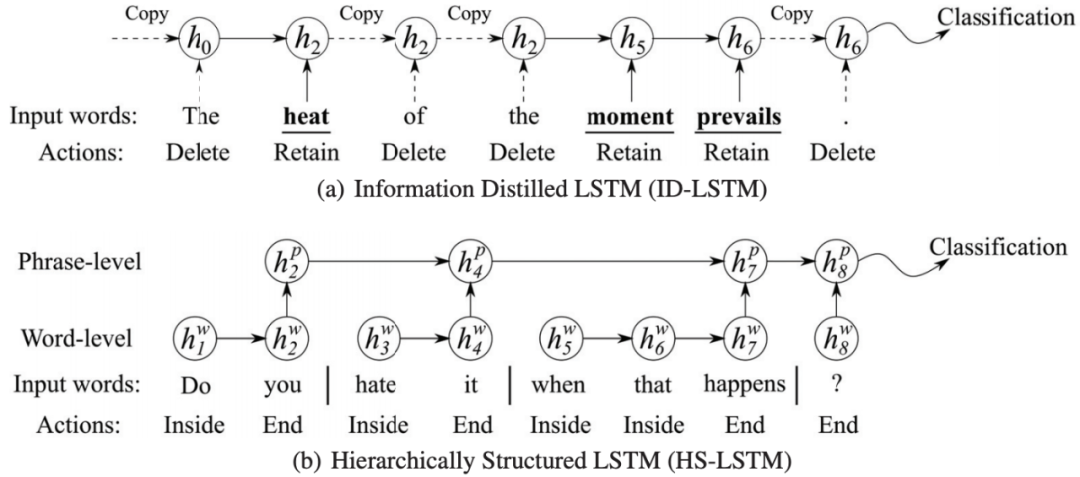
图2 ID- LSTM & HS- LSTM
◆ 总结
该工作学习了跟任务相关的句子结构,基于句子结构得到了不同的句子表示,并且得到更好的文本分类方法,提出了两种不同的表示方法:ID-LSTM和HS-LSTM。这两个表示也得到了很好的分类结果,得到了非常有意思的和任务相关的表示。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)