
TimeGAN_Time-series generative adversarial networks
论文:Time-series generative adversarial networks代码:https://github.com/jsyoon0823/TimeGAN现有的时间序列研究中,自回归模型明确地将时间序列模型分解为条件分布的乘积。这种方法在预测中表现优秀,但是无需添加外部条件就能获得新序列信息,作者考虑到这并不是一种“生成”方法。另一方面的研究是使用GAN,这种方法简单地应用标准的
论文:Time-series generative adversarial networks
代码:https://github.com/jsyoon0823/TimeGAN
现有的时间序列研究中,自回归模型明确地将时间序列模型分解为条件分布的乘积。这种方法在预测中表现优秀,但是无需添加外部条件就能获得新序列信息,作者考虑到这并不是一种“生成”方法。另一方面的研究是使用GAN,这种方法简单地应用标准的loss函数,可能不能捕捉序列之间的逐步依赖关系。
因此作者将上述两种不同实现机制的方法结合在一起——时间序列生成对抗网络(TimeGAN)。首先,除了真实序列和合成序列上的无监督对抗损失之外,还使用原始数据作为监督引入了逐步监督损失。其次,引入了一个嵌入网络以提供特征和潜在表示之间的可逆映射,从而减少了对抗性学习空间的高维性。这利用了这样一个事实。通过联合训练嵌入网络和生成器网络,可以将监督损失最小化。最后,将框架通用化以处理混合数据设置,在该设置中可以同时生成静态数据和时间序列数据。
1. Model
S为静态特征向量,
χ
\chi
χ表示时序特征。目标:
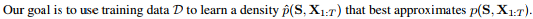

TimeGAN由四个网络组件组成:嵌入功能,恢复功能,序列生成器和序列鉴别器。 an embedding function, recovery function, sequence generator, and sequence discriminator. 自动编码组件(前两个)与对抗组件(后两个)一起训练,从而使TimeGAN同时学习了编码特征、生成表示形态并随时间迭代。嵌入网络提供了潜在的空间,对抗网络在该空间内运行,并且真实数据和合成数据的潜在动态通过监督的loss实现同步。
1.1 Embedding and Recovery Functions
H
s
H_s
Hs和
H
χ
H_\chi
Hχ表示S和
χ
\chi
χ的潜在向量空间。在模型中,实现静态和时间特征到他们的潜在编码的方法是:

在这里,编码过程是指静态和时序特征往潜在向量空间过渡的过程,而恢复过程是指从潜在向量往特征恢复的过程。构建这个绕圈圈的过程的目的可能是为了构建可训练的模型。
1.2 Sequence Generator and Discriminator
Z s Z_s Zs和 Z χ Z_\chi Zχ表示随机向量,以生成 H s H_s Hs和 H χ H_\chi Hχ。y表示分类信息,即标签。


在这部分中,生成器负责通过已定义的向量计算出潜在向量,判别器通过潜在向量计算出静态和动态数据对应的类别信息。
1.3 模型总图
上述四个组件构成如下模型图:

这里涉及到三类loss计算,详见论文。而loss在训练中发挥作用的部分如下图:

最优化目标作者在论文中详细地说明了。在最优化过程中,作者引入了超参数来平衡这几个loss。
1.4 实验评估
实验评估中,作者依据原则为:
(1)多样性-应该分发样本以覆盖真实数据;
(2)保真度-样本应与真实数据没有区别;
(3)实用性-当样本用于相同的预测目的(即综合训练,实测)时,样本应与真实数据一样有用。
作者提出两类score(Lower the Better):
- Discriminative Score :为了量化相似性,我们训练了 post-hoc 序列分类模型来区分原始数据集和生成的数据集。首先,每个原始序列都标记为真实,而每个生成的序列都标记为非真实。然后,训练一个现成的分类器以区分这两个类,以此作为标准的监督任务。然后,在保留的测试集上报告分类错误,从而对保真度进行定量评估。
- Predictive Score :为了保证实用性,采样数据应继承原始数据的预测特征。此外,作者希望TimeGAN在捕获随时间变化的条件分布方面表现出色。因此,使用合成数据集,作者训练了事后序列预测模型来预测每个输入序列上的下一步时间向量。然后,在原始数据集上评估训练后的模型。性能是根据MAE来衡量的;对于基于事件的数据,将MAE计算为|1-事件发生的估计概率|。
2. 总结
TimeGAN将无监督GAN方法的多功能性与对有监督的自回归模型提供的条件概率原理结合。本论文无论是在模型训练还是模型评测中都大量使用RNN/LSTM模型,但是作者并没有解释为什么。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)