VCIP2020:基于深度学习的HEVC帧内预测的非线性变换
本文来自VCIP2020文章《Deep Learning-Based Nonlinear Transform for HEVC Intra Coding》文章针对帧内编码块提出了基于深度学习的非线性变换方法,可以达到1.79%的BD-rate增益。在帧内编码过程中,信号间的线性依赖可以通过线性预测和线性变换来消除。但是由于预测往往不够完美,导致一些依赖信息不能完全消除,结果在帧内预测后的残差中依然
本文来自VCIP2020文章《Deep Learning-Based Nonlinear Transform for HEVC Intra Coding》

文章针对帧内编码块提出了基于深度学习的非线性变换方法,可以达到1.79%的BD-rate增益。
在帧内编码过程中,信号间的线性依赖可以通过线性预测和线性变换来消除。但是由于预测往往不够完美,导致一些依赖信息不能完全消除,结果在帧内预测后的残差中依然存在方向信息,传统的线性变换很难去除这些方向信息。进一步,线性变换更难去除信号中的非线性依赖。因此,文中提出基于深度学习的变换(DLT)来解决这个问题。

文中提出的变换编码方法如Fig.1所示,其中仅可以对8x8的亮度残差块进行DLT变换。编码器可以根据RDO结果决定8x8的亮度残差块是使用DCT II变换还是DLT变换。对每个8x8TU需要传输一个标志位DLT_Flag表示该TU是否使用DLT变换。
文中方法
原始信号域和残差信号域的统计特性不同,文中方法是基于残差空间进行。
网络结构
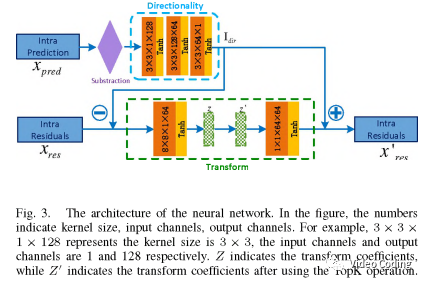
文字的网络模型包括两个模块:方向模块和变换模块。方向模块利用预测像素去除残差中的方向信息。变换模块进行正变换和逆变换。
方向模块:
由于预定义的方向模式可能和真实世界的纹理方向不一致,帧内预测后残差中仍可能保留方向信息。
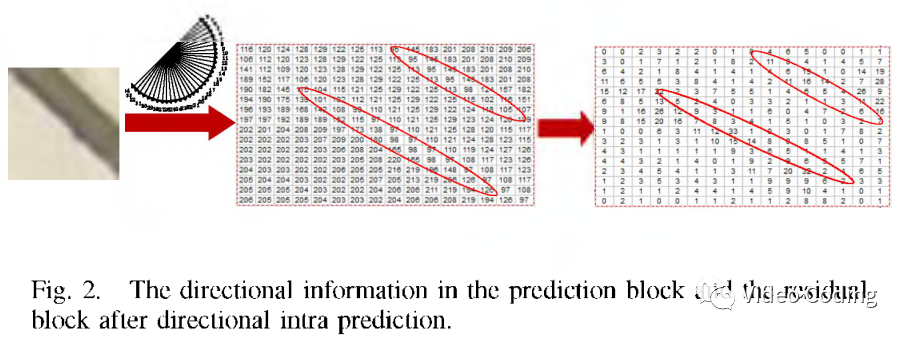
如Fig.2所示,残差中的方向模式通常和预测中的模式相关。因此可以利用预测数据消除方向信息。
为了捕获方向信息构建一个含3个卷积层的CNN,stride为1,kernel size为3x3,输出通道数分别为128,64,1,激活函数都采用tanh。在将预测数据传入网络之前,将其减去均值。然后使用上述网络提取方向信息I_dir,
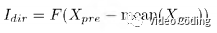
上式中I_dir代表提取的方向信息,X_pre表示预测信息,F表示CNN。
变换模块:
自编码器是经典的网络结构,它由编码器和解码器两部分组成。本文的自编码器模型中编码器和解码器都由1个卷积层组成。
编码器部分进行正变换,输入为残差X_res和方向信息I_dir的差值,

上式中enc表示自编码器的编码器部分,Z表示变换系数。
正变换后变换系数Z的尺寸和X_res相同。对于逆变换,自编码器的解码器部分将Z作为输入。为了将信号能量集中在少数几个系数中,在逆变换中只使用Z中的K个绝对值最大的系数,本文中K=8,
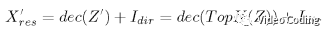
整个网络结构如Fig.3所示。
损失函数
文中使用原始信号域中像素级损失函数和变换域中新训练的损失函数来优化模型。
(1)L2损失:基于深度学习的正变换和逆变换,可以求得变换前后的L2损失,
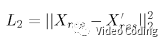
(2)能量压缩损失:变换的效率可以通过变换对能量压缩的效果来度量。可以通过变换系数方差的算术平均和几何平均的比值来计算,
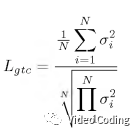
最终优化的损失函数为,
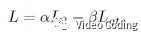
其中alpha=1.0,beta=0.2。
实验结果
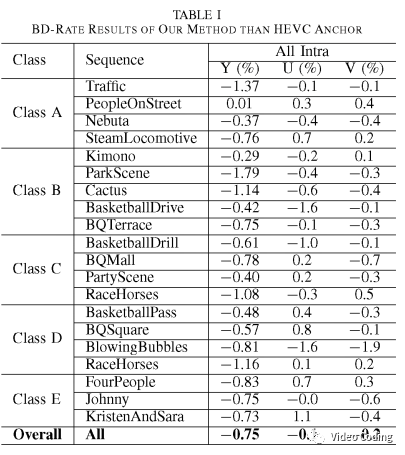
从结果可以看到本文算法在YUV分量上分别取得0.75%, 0.1%, 0.2%的BD-rate增益。尤其在纹理丰富的序列如 ParkScene, RaceHorses效果更好。
感兴趣的请关注微信公众号Video Coding


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)