
python数据清洗---实战案例(清洗csv文件)
我也是最近才开始这方面的学习,这篇就当作学习的笔记,记录一下学习的过程所要处理的数据数据中主要存在的问题主要包括:1.列名中存在空格2.存在重复数据3.存在缺失数据下面开始对数据进行清洗导入pandas模块,打开数据文件import pandas as pddf = pd.read_csv("ResourceFile.csv")我们输出指定列名print(df.名称)但此时会报错,因为列名"名称"
我也是最近才开始这方面的学习,这篇就当作学习的笔记,记录一下学习的过程
所要处理的数据
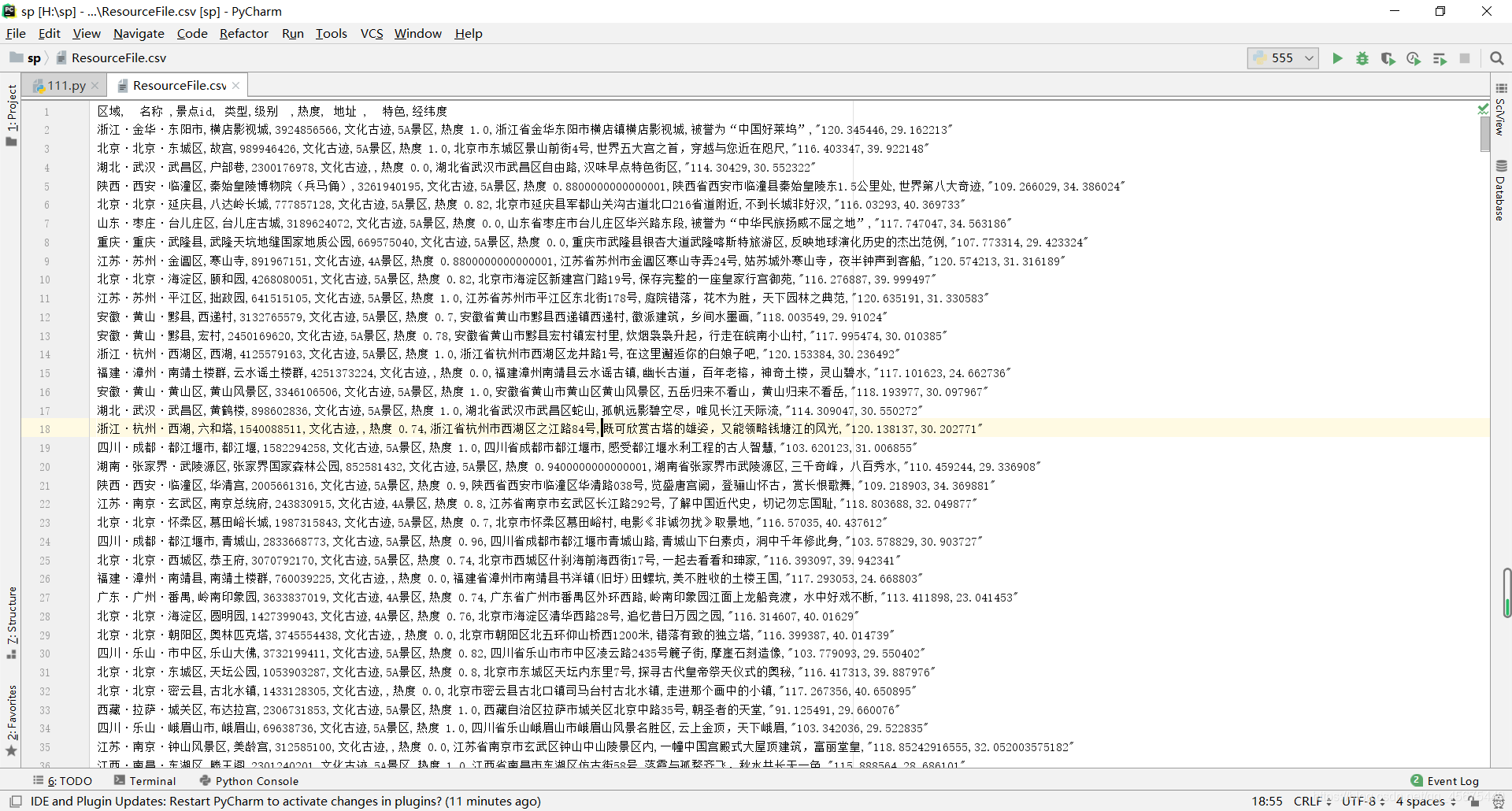
数据中主要存在的问题包括:
1.列名中存在空格
2.存在重复数据
3.存在缺失数据
导入pandas模块,打开数据文件
import pandas as pd
df = pd.read_csv("ResourceFile.csv")
当我们想要输出指定列名的时候,却报错了
print(df.名称)

但我们的列名中的确是有"名称"这一列的,为什么会显示没有"名称"这一列呢?我们输出列名看一下
方法一:
print(df.describe())
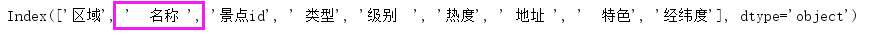
方法二:
# 只输出列名
print(df.columns.values)

我们可以看到,列名"名称"是带有空格的,那如果我们这样写
print(df[' 名称 '])

就可以输出这一列的数据了
所以我们现在要解决的问题就是删除列名中的空格
使用比较简单的一种方法:列表推导式去空格
ClName = df.columns.values
# 使用列表推导式
df.columns = [x.strip() for x in ClName]
print(df.columns.values)
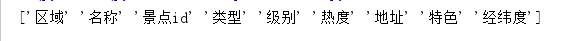
成功删除空格
接下来要解决的问题就是处理文件中的重复数据
我们先来查看下一共有多少行数据,三种方法
方法一:
# 结果 (行数,列数)
print(df.shape)
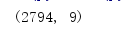
方法二:
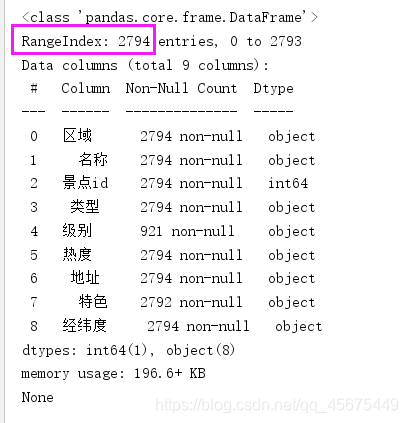
print(df.info())
方法三:
# 查看索引信息
print(df.index)

我们可以看到,通过三种方法得到的结果是一共有2794行数据
那我们现在来查看重复的数据
这里说的重复是指两行数据完全相同,如果只有部分数据相同,那不是重复
# 判断重复值 返回值类型为 Boolean
print(df.duplicated())
false表示没有重复,true表示有重复,默认从上到下比较,若上一行的数据和下一行的数据重复,则下一行标记为true

如果这样不太直观,我们可以直接查看有多少行重复的数据
# 返回重复的行数
print(df.duplicated().sum())
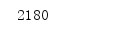
还可以查看重复的数据行
# 布尔索引 显示重复数据
print(df[df.duplicated()])

接下来就要删除这些重复的数据,两种方法
方法一:
这种方法不会对数据文件直接进行修改,而是生成一个临时表
# 删除重复值 不改变源数据 临时生成的表
print(df.drop_duplicates())
输出的临时表是删除重复数据之后的表,我们可以看到,现在的数据只有614行

而此时如果再查看源数据文件的信息,可以看到,源数据文件中的数据并没有减少
print(df.info())

方法二:
这种方法会直接对源数据文件进行修改
# 删除重复值 修改源数据
df.drop_duplicates(inplace=True)
查看源数据文件信息
print(df.info())

删除重复数据之后,我们要重置文件的索引
# 重置索引
df.index = range(df.shape[0])
查看索引信息
print(df.index)

接下来要处理的问题就是补全数据中的缺失值
第一步,查看缺失值
方法一:
# 查看缺失值
print(df.isnull())
没有缺失值标记为false,有缺失值标记为true

方法二:
# 查看没有缺失值
print(df.notnull())
没有缺失值标记为true,有缺失值标记为false

方法三:
显示每一列中的缺失值数量
# 显示每一列中的缺失值数量
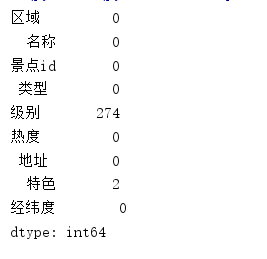
print(df.isnull().sum())
方法四:
显示有缺失值的数据
# 显示'特色'列中有缺失值的数据
print(df[df.特色.isnull()])

第二步,填补缺失值
# 提取'特色'列有缺失值的数据的'区域'列的值
print(df.loc[df.特色.isnull(),'区域'])

填补"级别"列有缺失值的数据,填补内容为"无级别"
# 填补"级别"列有缺失值的数据,填补内容为"无级别"
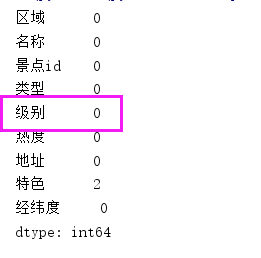
df.loc[df.级别.isnull(),'级别'] = "无级别"
查看’级别’列中缺失值的数量
print(df.isnull().sum())
填补"特色"列有缺失值的数据,填补内容为"未知"
# 填补"特色"列有缺失值的数据,填补内容为"未知"
df.loc[df.特色.isnull(),'特色'] = "未知"
查看’特色’列中缺失值的数量
print(df.isnull().sum())

数据处理完成,保存文件
df.to_csv("ResourceFile.csv")
查看数据文件
全部代码
import pandas as pd
df = pd.read_csv("ResourceFile.csv")
# 列名列表
ClName = df.columns.values
# 使用列表推导式
# 列名去空格
df.columns = [x.strip() for x in ClName]
# 删除重复值 修改源数据
df.drop_duplicates(inplace=True)
# 重置索引
df.index = range(df.shape[0])
# 填补"级别"列有缺失值的数据,填补内容为"无级别"
df.loc[df.级别.isnull(),'级别'] = "无级别"
# 填补"特色"列有缺失值的数据,填补内容为"未知"
df.loc[df.特色.isnull(),'特色'] = "未知"
# 保存文件
df.to_csv("ResourceFile.csv")

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 93
93 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)